
CUDA[2] Hello,World
Section 0:Hello,World
这次我们亲自尝试一下如何用粗(CU)大(DA)写程序
CUDA最新版本是7.5,然而即使是最新版本也不兼容VS2015 。。。推荐使用VS2012
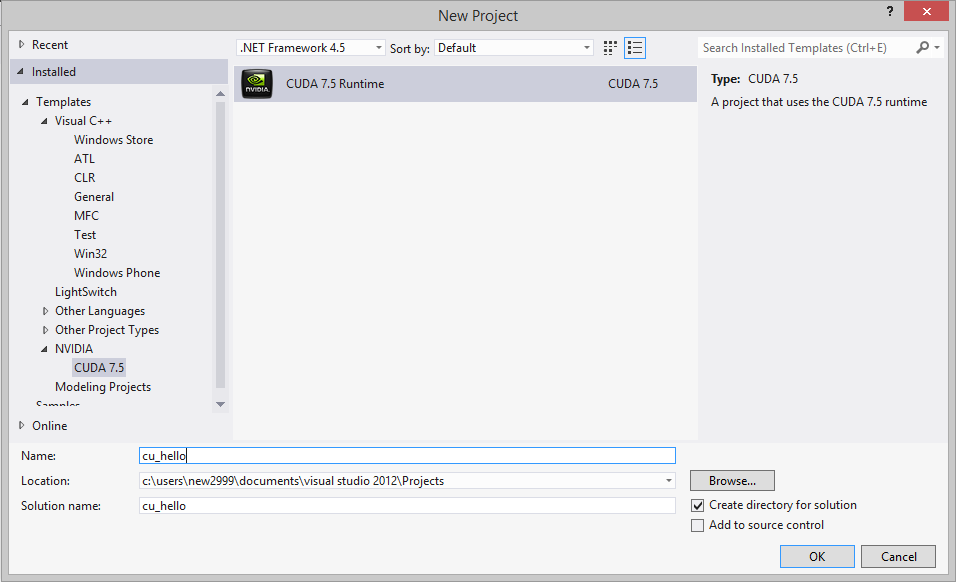
进入VS2012,新建工程,选择NVIDIA--CUDA Runtime
我们来写一个简单的向量加法程序:[Reference]
1 #include <stdio.h> 2 3 __global__ void saxpy(int n, float a, float *x, float *y) 4 //__global__关键字,表示是将要在GPU里并行运行的核函数 5 { 6 int i = blockIdx.x*blockDim.x + threadIdx.x; 7 if (i < n) 8 y[i] = a*x[i] + y[i]; 9 } 10 11 int main() 12 { 13 int N = 10; 14 float *x, *y, *d_x, *d_y; //都是指针,指向数组所在的内存/显存空间 15 x = (float*)malloc(N*sizeof(float)); //在内存中为x,y分配空间 16 y = (float*)malloc(N*sizeof(float)); 17 18 cudaMalloc(&d_x, N*sizeof(float)); //在显存中为d_x,d_y分配空间 19 cudaMalloc(&d_y, N*sizeof(float)); 20 21 for (int i = 0; i < N; i++) 22 { 23 x[i] = (float)i; 24 y[i] = 2.0f; 25 } 26 27 cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice); 28 cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice); 29 //将内存中x,y指向的数组空间拷贝到显存中d_x,d_y指向的数组空间 30 31 saxpy<<<1,N>>>(N, 10.0f, d_x, d_y); 32 //1个block,每个block里N个thread 33 34 cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost); 35 //将显存中计算好的d_y指向的数组空间拷贝到内存中y指向的数组空间 36 37 for (int i = 0; i < N; i++) 38 printf("%d %.3f\n",i,y[i]); 39 40 getchar(); 41 }
运行后就会出结果啦~
Section 1:一个好一点的代码风格
虽然刚才的程序已经能运行了,但是讲道理的话把所有的代码都写到cu文件里是很屎的风格。。。
下面再来写一个向量加法的程序:[Ref]
1 /* kernel.cu */ 2 //cuda系函数必须放在cu文件里 3 #include "cuda_runtime.h" 4 #include "device_launch_parameters.h" 5 6 #include <stdio.h> 7 8 __global__ void addKernel(int *c, const int *a, const int *b) 9 { 10 int i = threadIdx.x; 11 c[i] = a[i] + b[i]; 12 } 13 14 //cpp中不能直接调用核函数,所以在cu文件中还得写一个接口,负责分配内存等 15 void addWithCuda(int *c, const int *a, const int *b, unsigned int size) 16 { 17 int *dev_a = 0; 18 int *dev_b = 0; 19 int *dev_c = 0; 20 21 // Choose which GPU to run on, change this on a multi-GPU system. 22 cudaSetDevice(0); 23 24 // Allocate GPU buffers for three vectors (two input, one output) . 25 cudaMalloc((void**)&dev_c, size * sizeof(int)); 26 cudaMalloc((void**)&dev_a, size * sizeof(int)); 27 cudaMalloc((void**)&dev_b, size * sizeof(int)); 28 29 // Copy input vectors from host memory to GPU buffers. 30 cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); 31 cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); 32 33 // Launch a kernel on the GPU with one thread for each element. 34 addKernel<<<1, size>>>(dev_c, dev_a, dev_b); 35 36 // Copy output vector from GPU buffer to host memory. 37 cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); 38 39 cudaFree(dev_c); 40 cudaFree(dev_a); 41 cudaFree(dev_b); 42 cudaDeviceReset(); 43 } 44 45 //------------------------------------------------------------------------------- 46 /* Source.cpp */ 47 #include"cstdio" 48 #include"cstring" 49 50 extern void addWithCuda(int *c, const int *a, const int *b, unsigned int size); 51 //.cpp是由C编译器来编译的。C编译器里不允许#include一个cu文件(不资词) 52 //若要引用cu里的函数,在main.cpp里外部extern声明一下,让VS转为NVCC编译器处理。 53 54 int main() 55 { 56 const int arraySize = 5; 57 const int a[arraySize] = { 1, 2, 3, 4, 5 }; 58 const int b[arraySize] = { 10, 20, 30, 40, 50 }; 59 int c[arraySize] = { 0 }; 60 61 addWithCuda(c, a, b, arraySize); 62 63 printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n", 64 c[0], c[1], c[2], c[3], c[4]); 65 66 getchar(); 67 68 return 0; 69 }
补充:对于一些计算量较大(GPU计算时间较长)的程序,有可能运行很短时间之后就崩溃掉,并出现“显卡驱动已停止”的提示。
这是因为驱动程序默认认为GPU只负责图形计算任务,如果有任务长时间占用GPU就会自动terminate掉。
解决方法如下:[Ref]
进入注册表->HKEY_LOCAL_MACHINE->System->CurrentControlSet->Control->GraphicsDrivers
新建DWORD键TdrLevel,键值为0。保存重启即可。
Section 2:还是要学习一个
下面系统介绍一下粗大里的关键字和规则:
[Ref]
__global__:kernel函数。在device(GPU)里运行。可以在host(CPU处的主程序)调用
__device__:只允许在device运行,在device调用
__constant__:constant memory,表示常量
__shared__:shared memory,block内共享的变量
posted on 2016-04-14 13:41 Pentium.Labs 阅读(405) 评论(0) 编辑 收藏 举报



