
搭建hadoop2.2.0 HDFS,HA / Federation 和 HA&Federation
在虚拟机上安装Hadoop 2环境,版本使用Hadoop2.2.0。 Hadoop2 HDFS 的具有HA和Federation两种形式,配置上略有不同。以下把过程记录下来,留待以后查阅,也希望给人以便利。
- 准备工作
下载
http://mirrors.cnnic.cn/apache/hadoop/common/stable/hadoop-2.2.0.tar.gz
操作系统
ubuntu12.04
虚拟机
Vmware
安装操作系统, 此步骤略
本次测试安装四台虚拟机
| hostname | IP | |
| 1 | hw-0100 | 192.168.1.100 |
| 2 | hw-0101 | 192.168.1.101 |
| 3 | hw-0102 | 192.168.1.102 |
| 4 | hw-0150 | 192.168.1.150 |
安装JAVA,此步骤略
- 创建用户
#useradd hadoop
#passwd hadoop
使用sudo操作。编辑/etc/sudoers编辑文件,在root ALL=(ALL)ALL行下添加hadoop ALL=(ALL)ALL
- 配置ssh免密码
$ssh-keygen -t rsa
$cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
ssh localhost 测试通过后,把authorized_keys拷贝到其他节点的~/.ssh目录即可
准备工作完毕
配置HA
先看一下简单的架构图
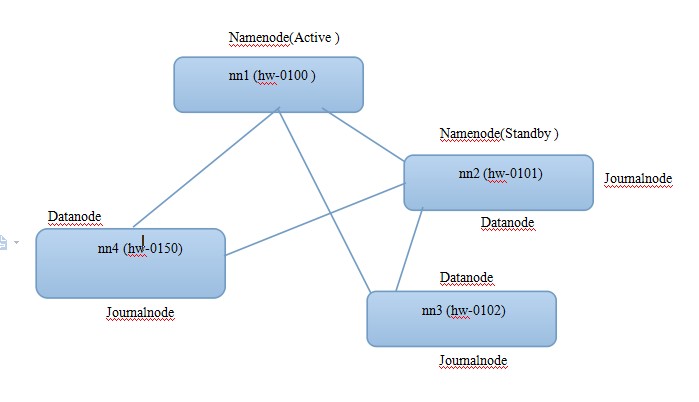
- JAVA_HOME
配置$HADOOP_HOME/etc/hadoop/hadoop-env.sh中JAVA_HOME
...
export JAVA_HOME = [java_local_dir]
...
- 配置core-site.xml, slaves, hdfs-site.xml
slaves
hw-0101 hw-0102 hw-0150
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-cluster1</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-cluster1</value> </property> <property> <name>dfs.ha.namenodes.hadoop-cluster1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster1.nn1</name> <value>hw-0100:9000</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster1.nn2</name> <value>hw-0101:9000</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster1.nn1</name> <value>hw-0100:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster1.nn2</name> <value>hw-0101:50070</value> </property> <property> <name>dfs.client.failover.proxy.provider.hadoop-cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/name</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hadoop-cluster1</name> <value>qjournal://hw-0101:8485;hw-0102:8485;hw-0150:8485/hadoop-cluster1</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>false</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hadoop-hdfs3/hdfs/journal</value> </property> </configuration>
把以上三个文件分别拷贝到所有节点的etc/hadoop/里。
- 启动namenode, datanode(本文hadoop的命令均在$HADOOP_HOME目录下运行)
配置HA,需要保证ActiveNN与StandByNN有相同的NameSpace ID,在format一台机器之后,让另外一台NN同步目录下的数据。
在hw-0100节点上执行:
如果使用HQJM,需要先启动jouranlnode
$sbin/hadoop-daemons.sh start journalnode
$bin/hdfs namenode -format
$sbin/hadoop-daemon.sh start namenode
在hw-0101节点上执行:
$bin/hdfs namenode -bootstrapStandby
$sbin/hadoop-daemon.sh start namenode
此时hw-0100,hw-0101均处于standby状态
切换hw-0100节点为Active状态
在hw-0100节点上执行:
$bin/hdfs haadmin -transitionToActive nn1
启动所有datanode节点
$sbin/hadoop-daemons.sh start datanode
- 验证
访问http://192.168.1.100:50070查看监控页面
访问HDFS,命令如下:
创建目录
$bin/hadoop fs -mkdir /tmp
查看目录
$bin/hadoop fs -ls /tmp
配置Federation
先看看简单架构图
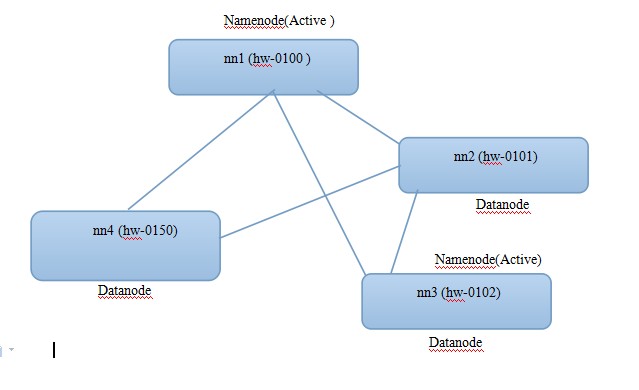
- 配置core-site.xml, slaves, hdfs-site.xml
slaves
hw-0101 hw-0102 hw-0150
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>viewfs:///</value> </property>
<property> <name>fs.viewfs.mounttable.default.link./tmp</name> <value>hdfs://hw-0100:9000/tmp</value> </property> <property> <name>fs.viewfs.mounttable.default.link./tmp1</name> <value>hdfs://hw-0102:9000/tmp2</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.federation.nameservices</name> <value>hadoop-cluster1,hadoop-cluster2</value> </property> <!--cluster1--> <property> <name>dfs.namenode.rpc-address.hadoop-cluster1</name> <value>hw-0100:9000</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster1</name> <value>hw-0100:50070</value> </property> <!--cluster1--> <!--cluster2--> <property> <name>dfs.namenode.rpc-address.hadoop-cluster2</name> <value>hw-0102:9000</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster2</name> <value>hw-0102:50070</value> </property> <!--cluster2--> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/data</value> </property> </configuration>
把以上三个文件分别拷贝到所有节点的etc/hadoop/里。
- 启动namenode, datanode(本文hadoop的命令均在$HADOOP_HOME目录下运行)
配置Federation,需要在启动多个NameNode上format时,指定clusterid,从而保证2个NameService可以共享所有的DataNodes,否则两个NameService在format之后,生成的clusterid不一致,DataNode会随机注册到不同的NameNode上。
在hw-0100节点上执行:
$bin/hdfs namenode -format –clusterId hadoop-cluster
$sbin/hadoop-daemon.sh start namenode
在hw-0102节点上执行:
$bin/hdfs namenode -format –clusterId hadoop-cluster
$sbin/hadoop-daemon.sh start namenode
启动所有datanode节点
$sbin/hadoop-daemons.sh start datanode
- 验证
访问http://192.168.1.100:50070查看监控页面
访问HDFS,命令如下:
查看目录
$bin/hadoop fs -ls /
可以查看到 /tmp /tmp1的两个目录。
HA&Federation
先看看简单架构图
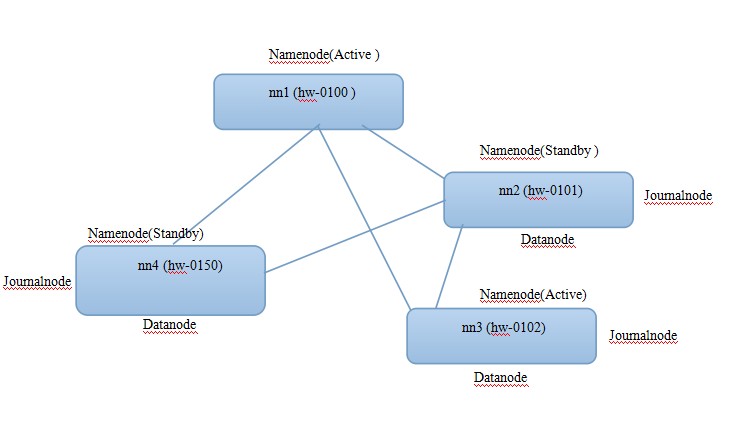
- 配置core-site.xml, slaves, hdfs-site.xml
slaves
hw-0101 hw-0102 hw-0150
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>viewfs:///</value> </property> <property> <name>fs.viewfs.mounttable.default.link./tmp</name> <value>hdfs://hadoop-cluster1/tmp</value> </property> <property> <name>fs.viewfs.mounttable.default.link./tmp1</name> <value>hdfs://hadoop-cluster2/tmp2</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-cluster1,hadoop-cluster2</value> </property> <property> <name>dfs.ha.namenodes.hadoop-cluster1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster1.nn1</name> <value>hw-0100:9000</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster1.nn2</name> <value>hw-0101:9000</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster1.nn1</name> <value>hw-0100:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster1.nn2</name> <value>hw-0101:50070</value> </property> <property> <name>dfs.client.failover.proxy.provider.hadoop-cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--cluster2--> <property> <name>dfs.ha.namenodes.hadoop-cluster2</name> <value>nn3,nn4</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster2.nn3</name> <value>hw-0102:9000</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster2.nn4</name> <value>hw-0150:9000</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster2.nn3</name> <value>hw-0102:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster2.nn4</name> <value>hw-0150:50070</value> </property> <property> <name>dfs.client.failover.proxy.provider.hadoop-cluster2</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--cluster2--> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/name</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hadoop-cluster1.nn1</name> <value>qjournal://hw-0101:8485;hw-0102:8485;hw-0150:8485/hadoop-cluster1</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hadoop-cluster1.nn2</name> <value>qjournal://hw-0101:8485;hw-0102:8485;hw-0150:8485/hadoop-cluster1</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hadoop-cluster2.nn3</name> <value>qjournal://hw-0101:8485;hw-0102:8485;hw-0150:8485/hadoop-cluster2</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hadoop-cluster2.nn4</name> <value>qjournal://hw-0101:8485;hw-0102:8485;hw-0150:8485/hadoop-cluster2</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoop-hdfs3/hdfs/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>false</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hadoop-hdfs3/hdfs/journal</value> </property> </configuration>
把以上三个文件分别拷贝到所有节点的etc/hadoop/里。
- 启动namenode, datanode(本文hadoop的命令均在$HADOOP_HOME目录下运行)
在hw-0100节点上执行:
如果使用HQJM,需要先启动jouranlnode
$sbin/hadoop-daemons.sh start journalnode
$bin/hdfs namenode -format –clusterId hadoop-cluster-new
$sbin/hadoop-daemon.sh start namenode
在hw-0101节点上执行:
$bin/hdfs namenode -bootstrapStandby
$sbin/hadoop-daemon.sh start namenode
此时hw-0100,hw-0101均处于standby状态
切换hw-0100节点为Active状态
在hw-0100节点上执行:
$bin/hdfs haadmin -ns hadoop-cluster1 -transitionToActive nn1
在hw-0102节点上执行:
$bin/hdfs namenode -format –clusterId hadoop-cluster-new $sbin/hadoop-daemon.sh start namenode
在hw-0150节点上执行:
$bin/hdfs namenode -bootstrapStandby $sbin/hadoop-daemon.sh start namenode
此时hw-0102,hw-0150均处于standby状态
切换hw-0102节点为Active状态
在hw-0100节点上执行:
$bin/hdfs haadmin -ns hadoop-cluster2 -transitionToActive nn3
在hw-0100节点上,启动所有datanode节点
$sbin/hadoop-daemons.sh start datanode
- 验证
访问http://192.168.1.100:50070查看监控页面
访问HDFS,命令如下:
查看目录
$bin/hadoop fs -ls /
显示在不同namenode中的目录 /tmp /tmp1
参考:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Federation.html
http://www.binospace.com/index.php/hdfs-ha-quorum-journal-manager/
知识源于网络 转载请注明出处 http://www.cnblogs.com/nb591/p/3535662.html
posted on 2014-01-29 11:10 Maxwell-HE 阅读(1699) 评论(0) 编辑 收藏 举报

