
一个完整的大作业--广州市社会保障(市民)卡服务网
1.选一个自己感兴趣的主题。
广州市社会保障(市民)卡服务网,网页网址为http://card.gz.gov.cn/gzshbzk/xwgg/list.shtml
2.网络上爬取相关的数据。
import requests from bs4 import BeautifulSoup from datetime import datetime import re # 爬取单条资讯的信息 def getTheContent(url1): res = requests.get(url1) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') item = {} item['url'] = url1 # 链接 resd = requests.get(item['url']) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') item['title'] = soupd.select('.content_title')[0].text.strip() # 标题 item['time'] = soupd.select('.content_subtitle')[0].text.strip() # items['dt'] = datetime.strptime(info.lstrip('发布时间:')[6:25], '%Y/%m/%d %H:%M:%S') #时间 # !!!!!!!问题未解决:取出class_='.content'里的span标签的text!!!!!!!! #taglist = soupd.find_all('span', attrs={'class': re.compile(".content")}) #con1=soup.find('div',id='content') #item[con2]=con1.span.get_text() item['content'] = soupd.select('.content')[0].text.strip() return (item) #print(getTheContent('http://card.gz.gov.cn/gzshbzk/tzgg/201709/7e02bd9aa4674173aed4dc6b658c0849.shtml')) # 爬取一个列表页面内的所有咨询链接,并将链接返回到getTheContent(url1)中 def getOnePage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') lilist = soup.find('div', class_='lilist') # 指定class位置 list = lilist.findAll(name='li') itemls = [] for item in list: if len(item.select('a')[0]['title']) > 0: url= item.select('a')[0]['href'] # 由于提取到的href是简略版(<li href="../../gzshbzk/dtxw/201707/b5f3ca9365954121a995bd5284bed095.shtml">)所以要替换一下 url1 = re.compile('../../') url2= url1.sub('http://card.gz.gov.cn/', url) itemls.append(getTheContent(url2)) else: print ("错误!") return (itemls) print(getOnePage('http://card.gz.gov.cn/gzshbzk/xwgg/list_2.shtml'))



[{'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201708/835eb3fc6df848189775ec12e7f96188.shtml', 'title': '您知道您未领取的社保卡在哪里吗?', 'time': '2017-08-02', 'content': '您知道您未领取的社保卡在哪里吗?\n\n最近广州的三伏天气温实在是厉害,小卡君天天都想躺在沙发上吹着空调吃着西瓜。\n\n\xa0\n但是,\n在这样的天气里,有不少小伙伴办了社保卡之后还未未领取,既不想知道社保卡办的怎么样了,或是在哪领取又不想顶着烈日跑窗口去询问。\n\xa0\n\n别急!\n今天小编就来告诉你您:如您的社保卡尚未领取,怎样才有什么办法能了解到进度呢?需查询社保卡的申领进度,要想查询社保卡的申领进度,总共分两步:\n共两步:\n一、先查询社保卡的状态;\n1.电话查询:拨打广州市社会保障(市民)卡服务热线:12343、12345\n2.网站查询:登录广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n从“社保(市民)卡网上服务大厅”进入“自助查询”栏目\n3.网点咨询:可到广州市社保卡中心任一驻任一区级服务网点查询社保卡的状态\n4.通过“广州社保卡_市民卡”或者“广州人社”微信服务公众号查询。\n⑴进入通过“广州社保卡_市民卡”或者“广州人社”微信服务公众号;进入服务号后,分别进入选择相应的栏目,详情操作如下:\n可以进入进入“广州社保卡_市民卡”微信服务公众号:\n打开【自助查询】栏目,点击“自助查询”子链接选项。\n\n“广州社保卡_市民卡”微信服务公众号示意图截屏\n也可以进入“广州人社”微信服务公众号:\n打开【社保通】栏目,点击“社保卡查询”子链接选项。\n\n“广州人社”微信服务公众号手机截屏示意图\n⑵输入查询条件,\n输入“身份证号码”、“姓名”和“随机码”,点击【查询】按钮。\n\n\n手机界面截屏示意图\n⑶只要信息输入正确,\n就可以轻松查到社保卡的申领进度和持卡信息啦!\n\n\n手机界面截屏示意图\n二、然后根据查询结果提示领取社保卡。对应的银行服务网站或者微信服务号查询和预约申领。\n从今以后,\n小伙伴们就可以更方便地在微信号中,\n查询到自己未领取的社保卡状态啦。\n多了这样的查询利器,\n小伙伴们查询社保卡状态是不是更加省心了,\n如果觉得实用,\n请给我们一个赞哦~\n\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡'}, {'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201708/9c8a6e20460441bcb2b41895eb24a7df.shtml', 'title': '全国4055家定点医疗机构开通跨省异地就医住院费用直接结算', 'time': '2017-08-02', 'content': '全国4055家定点医疗机构开通跨省异地就医住院费用直接结算\n \n\n\n目前全国跨省异地就医住院医疗费用直接结算联网接入工作顺利推进。\n\n全国31省份和新疆生产建设兵团均接入国家异地就医结算系统,\n开通390个地区,占97.5%。\n\n开通4055家跨省异地就医住院医疗费用直接结算定点医疗机构,现予发布。\n\xa0\n\n参保人员可以登录以下网址,实时在线查询\n最新地区及定点医疗机构开通情况:\nhttp://si.12333.gov.cn\n\n\xa0\n\n\n开通地区的参保人员按参保地相关规定进行跨省异地就医登记备案及就医时,\n可从以下公布的名单中选择定点医疗机构,\n以便实现跨省异地就医住院医疗费用直接结算。\n\n\n\n内容来源:人力资源和社会保障部\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡'}, {'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201707/b5f3ca9365954121a995bd5284bed095.shtml', 'title': '一图看懂社保卡怎么用', 'time': '2017-07-19', 'content': '一图看懂社保卡怎么用\n \n\xa0\xa0\xa0 社保卡是持卡人享受人力资源和社会保障权益的信息载体。今年5月,全国统一标准的社保卡持卡人数已迈过10亿门槛。这张与我们的生活息息相关的卡有什么功能和特点?已经实现了哪些应用?看图了解——'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201707/0b627782d2044dd68fcc497c0df7e75e.shtml', 'title': '涨姿势!这才是医保个人账户的正确打开方式!', 'time': '2017-07-17', 'content': '涨姿势!这才是医保个人账户的正确打开方式! \n\xa0\n说起医保个人账户(简称医保个账),\n很多市民估计还不清楚是个什么东东。\n换个说法\n医保个账其实就是大家常说的社(医)保卡里有钱,\n这样就容易理解了~~\n\xa0\n\n但\n重点是...\n\xa0\n内容来自:广州医保\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201707/22ba59387d5c4c869ecf485013d8a3c9.shtml', 'title': '异地就医直接结算只要准备这些资料,按这样办理,就这么简单!', 'time': '2017-07-17', 'content': '异地就医直接结算只要准备这些资料,按这样办理,就这么简单!\xa0\n看到跨省就医直接结算\n这个好消息\n异地就医广州市接入省外1000多家直接结算医院\n\xa0迫不及待想要办理了\n但是,问题来了\n该怎么办理异地就医\n需要准备哪些资料\n\n贴心的小编\n已经为你准备了满满的干货\n不同的人员请对号入座哦\n\xa0\n\n\n\n看完了满满的干货,\n还是没搞懂跨省就医该怎么办理?\n\n别急~\n你想了解的问题,\n小编一一给你解答!\n\xa0▼▼▼▼▼\n\n\xa0\n\xa0 ▼第二代社保卡示例图 \n\xa0\n\n\xa0\n\xa0\n\xa0\n\n\xa0觉得这样的流程有点麻烦?\n小编教你一个更简单易办的方法!\n\xa0\n\n\xa0\n广州市社会医疗保险异地就医记录册下载地址:http://www.hrssgz.gov.cn/bgxz/bgxzylbx/201507/P020160919633708288002.doc\n\xa0\n内容来自:广州人社\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201706/c20353a078fe427ba69f546481e62626.shtml', 'title': '关于广州市金融IC卡移动支付应用试点测试人员名单的公示', 'time': '2017-06-19', 'content': '关于广州市金融IC卡移动支付应用试点\n测试人员名单的公示\n根据广州市社会保障卡服务中心2017年6月15日发布的《关于招募广州市金融IC卡移动支付应用试点测试人员的公告》规定,现对符合测试条件的前10名社会公开招募测试人员名单公示如下:\n\xa0\r\n\n\n\n序号\n姓名\n身份证号码\n联系电话\n社会保障卡服务银行\n\n\n1\n王*妤\n4401***********637\n133*****018\n广州银行\n\n\n2\n王*\n1304***********439\n139*****850\n广州银行\n\n\n3\n朱*珊\n3623***********044\n136*****500\n广州银行\n\n\n4\n陆*清\n4418***********510\n137*****002\n广州银行\n\n\n5\n张*林\n4402***********911\n189*****505\n广州银行\n\n\n6\n王*福\n4127***********319\n139*****571\n广州银行\n\n\n7\n李*\n4452***********717\n134*****654\n广州银行\n\n\n8\n李*元\n4127***********557\n188*****015\n广州银行\n\n\n9\n张*\n4414***********657\n138*****950\n广州银行\n\n\n10\n吕*君\n4401***********226\n137*****363\n广州银行\n\n\n\n\n公示期自2017年6月19日至2017年6月21日, 如有异议,请在公示期内通过来电、来信、来访向我中心反映,并写清或讲明异议事由,署(报)真实姓名和联系方式,以便查证核实。\n如未能如期确认的,本中心将按顺序顺延其他符合测试条件的人员进行补充。\n感谢各位的踊跃参与!\n工作时间: 8:30—12:00,14:00—17:30\n联 系 人:黄小珊 \n联系电话: 38828400\n\xa0\n\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0 \xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0广州市社会保障卡服务中心\n\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0 2017年6月19日'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201706/48044e9beae04dbabe1dbfccc5d337d5.shtml', 'title': '关于招募广州市金融IC卡移动支付应用试点测试人员的公告', 'time': '2017-06-12', 'content': '关于招募广州市金融IC卡移动支付应用试点测试人员的公告'}, {'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201706/41bfb3b26c584879bbb7b8f5db743831.shtml', 'title': '我国社会保障卡持卡人数突破10亿', 'time': '2017-06-05', 'content': '我国社会保障卡持卡人数突破10亿\n\n\n社保卡:1,000,000,000张\xa0\n\xa05月25日,人社部副部长游钧将第10亿张社保卡亲手交到了河北省邯郸市馆陶县寿东村16岁女学生宁洁手中。这意味着,历经18年,全国统一标准的社保卡持卡人数已迈过10亿门槛。\xa0\n\xa0人社部信息中心负责同志介绍,第一张社保卡是1999年在上海发出的。目前社保卡已覆盖全国超过72%人口,向国家“十三五”规划“覆盖90%人口”的目标又迈进了坚实的一步,最终目标实现人手一卡。\n\n\xa0近年来,社保卡在电子凭证、信息记录、自助查询、就医结算、缴费和待遇领取、以及金融支付等6类功能方面不断普及,用卡范围不断拓展。在梳理出来人社业务领域102项用卡典型应用中,全国平均已经开通80%,预计今年底将全部开通。目前全国超过九成的地市实现医疗费用持卡即时结算,人力资源社会保障部正在稳步推进跨省异地住院费用的即时结算。越来越多的地区还将民政、卫生计生、公积金、残疾人服务、涉农补贴等服务事项搭载在社保卡上,实现了一卡多用。\n\xa0社保卡在设计之初就是一张开放的卡,希望将社保卡打造成各类政府公共服务的载体,真正成为一张便民卡。今年人力资源社会保障部还将联合人民银行开展试点,在部分地区试点第三代社保卡,主要是增加“一晃而过”的非接触功能,届时,社保卡的功能更加强大,应用场景更加广泛,可进一步方便持卡人,增强人民群众的获得感、幸福感。\n\n\xa0接过第10亿张社保卡的宁洁及家人再三表示感谢。据了解,宁洁家中有父母和一个妹妹共4口人,过去家庭曾因病致贫。人社部门积极开展精准扶贫工作,2016年城乡居民医疗保险报销其母亲住院花费近万元,报销比例达到90%(贫困人员比常人高20%),同时还享受医疗救助一次,大病报销736元。宁洁的父亲经过职业培训后到南京打工,现年收入3.5万元;经县就业局协调,母亲在本村摆摊卖玩具,年收入1.5万元。家人参加了城乡居民养老保险,2012年起每年缴100元。此外家里还有种粮补贴等收入,目前已经脱贫。一家人都表示,今后有了社保卡,全家生活就更方便、更有保障了。\n\xa0\n\xa0按照人社部“互联网+人社”2020行动计划,传统以线下应用为主的社保卡还将插上互联网和大数据的翅膀,通过搭建社保卡线上服务平台,对接更多的社会服务渠道,使老百姓通过手机就可以快速完成社保缴费、医保结算等事项,切实解决诸如看病“三长一短”(挂号排长队、就诊排长队、缴费排长队,看病时间短)等生活中的痛点和堵点,通过社保卡为群众“记录一生、保障一生、服务一生”。\n\xa0\n内容来自:人社部\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡(>长按下图二维码关注)'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201705/be44e1b8b9964ad8a1999ea2ca0d7c6e.shtml', 'title': '2017年端午节放假安排的通知', 'time': '2017-05-26', 'content': '广州市社会保障卡服务中心关于2017年端午节放假安排的通知\n\n各位市民:\n根据《国务院办公厅关于2017年部分节假日安排的通知》(国办发明电〔2016〕17号),现将我中心各区级对外服务窗口(详见网站公布http://card.gz.gov.cn)有关放假安排通知如下:\n2017年5月28日至5月30日(星期日至星期二)放假,共3天。5月27日(星期六)上班。\n特此通知。\n\xa0\n\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0 广州市社会保障卡服务中心\n\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0 2017年5月26日'}, {'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201705/8007ba78e5044657854ac34732ac1fe5.shtml', 'title': '自助激活!社保卡金融功能开通智慧之选!', 'time': '2017-05-19', 'content': '大明: 小卡,你的广州社保_市民卡拿到了吗?\n小卡: 拿到了,\n而且听说社保卡有个金融功能很重要,\n还得自己去银行网点开通\n大明: 没错,社保卡金融功能开通后,\n简单说相当于一张银行借记卡,\n具有现金存取、转账、消费等金融服务。\n而且养老金、失业保险金、医疗医保报销返还等,\n都可以通过社保卡的金融账户发放,\n其中医保零星医疗费还必须使用社保卡的金融账户发放!\n小卡: 那我可得赶紧开通。\n可是要去银行排队,\n会不会很耽误时间啊 \n大明: 金融功能开通非常方便,\n而且现在有了智慧柜员机,\n社保卡激活更加快捷啦。\n小卡: 智慧柜员机?\n太好了,快教教我怎么用的?'}, {'url': 'http://card.gz.gov.cn/gzshbzk/dtxw/201705/cf333a87f3de4a1680fb345bb506a7c9.shtml', 'title': '社保卡查询领取怎么做?教你一招更方便哦!', 'time': '2017-05-19', 'content': '最近有很多市民朋友问小卡君这样的问题:\n\n\xa0\n\xa0\n小卡君,我的社保卡什么时候能发下来啊?\n小卡君,我的社保卡制出了吗?\n小卡君,社保卡申请之后到哪里领啊?\n\xa0\n\n\xa0\n在这里,小卡君就集中解答下这些市民朋友的疑惑\n\xa0\n\xa0\xa0\n\xa0\n根据《广州市社会保障卡管理办法》规定,\n申领人初次申领社会保障卡的,\n社会保障卡经办机构应当在受理申请后\n30日向符合条件的申请人发放社会保障卡。\n\xa0\n如果您还未领到卡片,\n请及时通过以下渠道联系我们,\n了解具体问题。\n\xa0\n社保卡如何查询\n\n拨打广州市社会保障(市民)卡服务热线:12343、12345\n\xa0\n\n登录广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn,点击【自助查询】\n\xa0\n\n\xa0\n\n在广州市社保卡中心任一区级服务专窗查询办卡信息\n\xa0\n\n各位市民朋友们都GET到了吗?\n\n\xa0\n学会这些就足够了吗?\n还想有更便捷更省力的方式来搞定吗?\n那咱就接着往下看\n小卡君再教你一招\n\xa0\n\xa0\n关注 广州社保_市民卡 官方微信后\n\n进入自定义菜单下的【自助查询】栏目,\n点击“自助查询”子链接\n\n跳转到如下界面:\n\n输入身份证号码、姓名、随机码便可直接查询啦\n\xa0\n\xa0\n\n\xa0\n还等什么?\n赶紧把您的社保卡领回家吧~~\n\n\xa0\n\xa0\n广州市社会保障(市民)卡服务网站:http://card.gz.gov.cn\n广州市社会保障(市民)卡服务热线:12343、12345\n广州市社会保障(市民)卡微信公众号:广州社保卡_市民卡(>长按下图二维码关注)'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201705/40b43384475a4908928a29cdc9854ab7.shtml', 'title': '广州市社会保障卡服务中心2017年招聘合同制人员公告', 'time': '2017-05-17', 'content': '广州市社会保障卡服务中心是市人力资源和社会保障局管理的正处级公益一类事业单位,主要职责是贯彻落实国家、省、市关于社会保障卡管理的政策规定;提出社会保障卡管理办法、业务操作规程、建设方案及规则的建议;制定社会保障卡工作的技术标准规范;负责社会保障卡的信息采集、制作、发行、安全管理等工作;承担人力资源和社会保障业务应用、政府公共服务、异地业务等“一卡通”应用推广的任务;负责对合作银行、制卡商、信息系统运维商的业务协调工作;指导协调我市各社会保障卡服务网点的经办服务工作;组织开展社会保障卡的宣传及业务经办培训等。因工作需要,现公开招聘合同制人员4名,有关事项公告如下:\n一、招聘岗位和相关要求\n招聘岗位为业务服务岗。应聘人员应具备以下资格条件:\n\n\n\n\n\n序号\n\n\n岗位名称\n\n\n招聘人数\n\n\n年龄要求\n\n\n专业要求\n\n\n学历要求\n\n\n其他要求\n\n\n\n\n1\n\n\n业务服务岗一\n\n\n1\n\n\n35周岁以下\n\n\n中国语言文学、汉语言文学、行政管理等相关专业\n\n\n全日制本科或以上\n\n\n1、中共正式党员;2、具有从事文秘相关工作经验者优先。\n\n\n\n\n2\n\n\n业务服务岗二\n\n\n1\n\n\n35周岁以下\n\n\n文科类专业\n\n\n全日制本科或以上\n\n\n1、中共正式党员;2、有较高的政治理论水平和文字写作水平;3、有较强的沟通协调能力;4、熟悉党团工青妇工作流程,有相关工作经验者优先。\n\n\n\n\n3\n\n\n业务服务岗三\n\n\n1\n\n\n40周岁以下\n\n\n不限\n\n\n大专或以上\n\n\n1、有3年以上消防管理工作经验;2、持有《安全生产管理人员安全资格证书》;3、有良好的沟通能力及处理突发事件应变能力;4、工作责任心强,有敬业精神;5、持有建(构)筑物消防员资格证者优先,持有汽车驾驶证者优先。\n\n\n\n\n4\n\n\n业务服务岗四\n\n\n1\n\n\n35周岁以下\n\n\n规划设计类专业\n\n\n全日制本科或以上\n\n\n1、有3年以上相关工作经验;2、能熟练使用Word、Excel、PowerPoint、Photoshop、Visio;3、有良好的沟通能力,独立工作能力强,工作责任心强,可承受较大工作压力。\n\n\n\n\n\n二、招聘的程序和步骤\n(一)报名\n1、报名办法:应聘者在网页上下载填写《广州市社会保障卡服务中心2017年公开招聘报名表》连同个人简历一并发邮件至sbkhrzp@163.com。邮件标题请写明应聘职位,如“姓名+业务服务岗一”。敬请勿访。\n2、报名要求:应聘者提供的资料应当真实有效,如发现弄虚作假者,一切后果由应聘者自行承担。\n(二)资格审查和筛选\n报名截止后,我中心组织对收集到的报名材料进行审查,通过筛选后,电话通知应聘人员前来参加考试,一并通知考试形式、时间、地点。\n(三)考试\n根据报名筛选结果决定采取单一面试或笔试和面试相结合的方式进行考试。笔试主要测试履行岗位职责所必需的专业知识和技能(闭卷);面试采取面谈方式。参加考试时请携带身份证、学历证、学位证等相关证件的原件以便核对。\n(四)体检\n\xa0通过面试者请自费前往广州南方人才资源租赁中心指定的医院进行体检。体检不合格的,按面试成绩由高到低依次替补人选。\n(五)聘用和管理\n体检合格人员与广州南方人才资源租赁中心签订劳动合同并办理有关劳动用工手续,派遣到我中心工作。试用期为2个月。\n三、福利待遇\n按照市社会保障卡服务中心合同制人员工资薪酬标准执行,按国家规定缴纳社保和公积金;享受国家规定法定节假日及年休假。\n\xa0有关招聘内容由广州市社会保障卡服务中心综合部人事负责解释,联系人:彭小姐,联系电话:13005150960。\n\xa0\n\xa0广州市社会保障卡服务中心2017年公开招聘报名表.docx'}, {'url': 'http://card.gz.gov.cn/gzshbzk/tzgg/201704/83c08c36f5484309aca10b3c1cecaddb.shtml', 'title': '2017年劳动节放假通知', 'time': '2017-04-27', 'content': '各位市民:\n\u3000\u3000根据《国务院办公厅关于2017年部分节假日安排的通知》(国办发明电〔2016〕17号),现将我中心各对外服务窗口(详见网站公布http://card.gz.gov.cn)有关放假安排通知如下:\n\u3000\u30002017年4月29日至5月1日(星期六至星期一)放假,与周末连休,共3天。\n\u3000\u3000特此通知。\n\u3000\u3000\n广州市社会保障卡服务中心\n\u3000\u30002017年4月27日'}]
3.进行文本分析,生成词云。
# 制作词云 def showordcloud(cy): words = jieba.lcut(cy) counts = {} for word in words: # 统计词语出现次数 if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) cloudlist = '' for i in range(20): for j in range(items[i][1]): cloudlist += ' ' + items[i][0] cl_split = ''.join(cloudlist) # print(cl_split) mywc = WordCloud(font_path='msyh.ttc').generate(cl_split) plt.imshow(mywc) plt.axis("off") plt.show() #合并所有content文本 def detailwc(totallist): detailall='' for a in range(len(totallist)): detailall += itemtotal[a]['content'] + "\n" detailall=detailall.replace("\n",'') detailall=detailall.replace(" ",'') return(detailall) itemtotal=[] listurl = 'http://card.gz.gov.cn/gzshbzk/xwgg/list.shtml'#首页新闻列表 itemtotal.extend(getOnePage(listurl)) for i in range(2,10):#第二页至尾页 listurl = 'http://card.gz.gov.cn/gzshbzk/xwgg/list_{}.shtml'.format(i) itemtotal.extend(getOnePage(listurl)) df = pandas.DataFrame(itemtotal) df.to_excel('gzsbk.xlsx') # excel导出 #print(len(itemtotal))#114 showordcloud(detailwc(itemtotal))
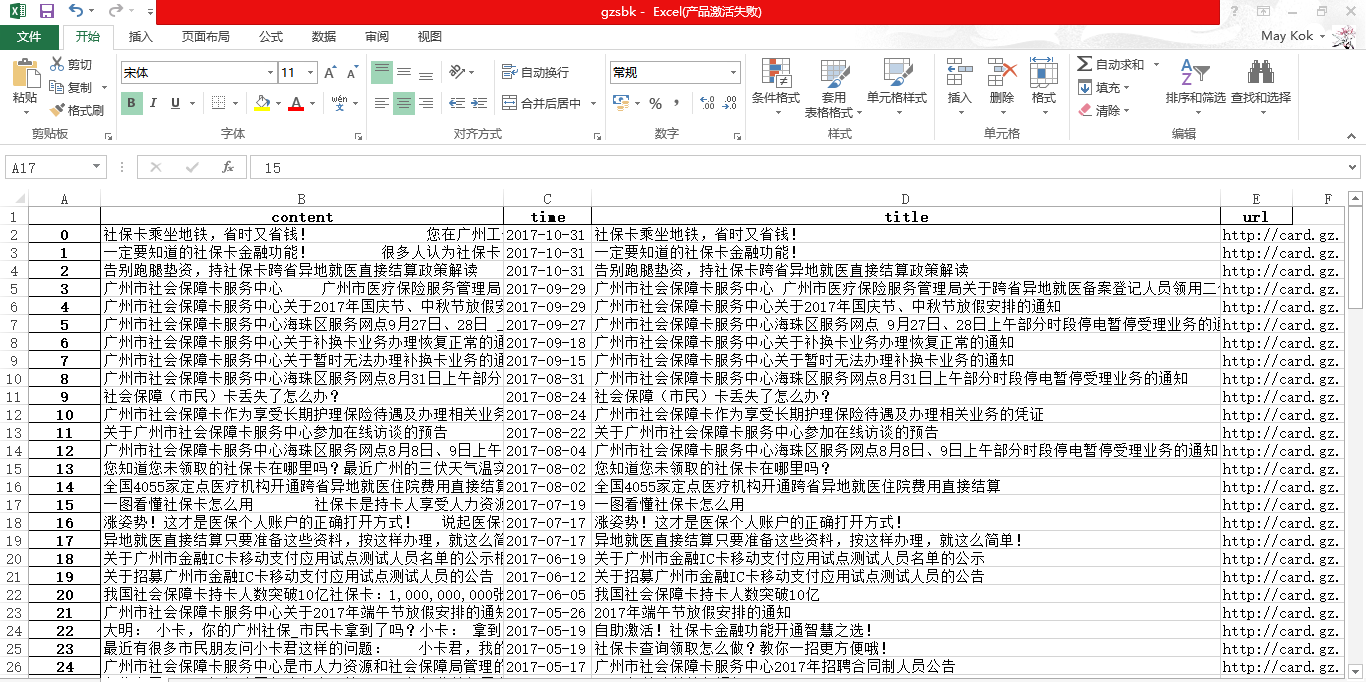

程序源代码:
import requests from bs4 import BeautifulSoup import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from datetime import datetime import re import pandas # 爬取单条资讯的信息 def getTheContent(url1): res = requests.get(url1) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') item = {} item['url'] = url1 # 链接 resd = requests.get(item['url']) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') item['title'] = soupd.select('.content_title')[0].text.strip() # 标题 item['time'] = soupd.select('.content_subtitle')[0].text.strip() # items['dt'] = datetime.strptime(info.lstrip('发布时间:')[6:25], '%Y/%m/%d %H:%M:%S') #时间 item['content'] = soupd.select('.content')[0].text.strip() return (item) #print(getTheContent('http://card.gz.gov.cn/gzshbzk/tzgg/201709/7e02bd9aa4674173aed4dc6b658c0849.shtml')) # 爬取一个列表页面内的所有咨询链接,并将链接返回到getTheContent(url1)中 def getOnePage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') lilist = soup.find('div', class_='lilist') # 指定class位置 list = lilist.findAll(name='li') itemls = [] for item in list: if len(item.select('a')[0]['title']) > 0: url= item.select('a')[0]['href'] # 由于提取到的href是简略版(<li href="../../gzshbzk/dtxw/201707/b5f3ca9365954121a995bd5284bed095.shtml">)所以要替换一下 url1 = re.compile('../../') url2= url1.sub('http://card.gz.gov.cn/', url) itemls.append(getTheContent(url2)) else: print ("错误!") return (itemls) #print(getOnePage('http://card.gz.gov.cn/gzshbzk/xwgg/list_2.shtml')) # 制作词云 def showwordcloud(cy): words = jieba.lcut(cy) counts = {} for word in words: # 统计词语出现次数 if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) #划分为元组 items.sort(key=lambda x: x[1], reverse=True) cloudlist = '' for i in range(20): for j in range(items[i][1]): cloudlist += ' ' + items[i][0] cl_split = ''.join(cloudlist) # print(cl_split) mywc = WordCloud(font_path='msyh.ttc').generate(cl_split) plt.imshow(mywc) plt.axis("off") plt.show() #合并所有content文本 def dealcontent(totallist): allcontent='' #来个空字符串 for a in range(len(totallist)):#len(itemtotal)=114 allcontent += itemtotal[a]['content'] + "\n" allcontent=allcontent.replace("\n",'') allcontent=allcontent.replace(" ",'') return(allcontent) itemtotal=[] listurl = 'http://card.gz.gov.cn/gzshbzk/xwgg/list.shtml'#首页新闻列表 itemtotal.extend(getOnePage(listurl)) for i in range(2,10):#第二页至尾页 listurl = 'http://card.gz.gov.cn/gzshbzk/xwgg/list_{}.shtml'.format(i) itemtotal.extend(getOnePage(listurl)) df = pandas.DataFrame(itemtotal) df.to_excel('gzsbk.xlsx') # excel导出 #print(len(itemtotal))#114 showwordcloud(dealcontent(itemtotal))
另外这是爬的问答页面http://card.gz.gov.cn/gzshbzk/bmwd/list_bmxx.shtml

该页源代码:
import requests from bs4 import BeautifulSoup import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from datetime import datetime import re import pandas import sqlite3 # 爬取单条资讯的信息 def getTheContent(url1): res = requests.get(url1) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') item = {} item['url'] = url1 # 链接 resd = requests.get(item['url']) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') item['title'] = soupd.select('.content_title')[0].text.strip() # 标题 item['time'] = soupd.select('.content_subtitle')[0].text.strip() # items['dt'] = datetime.strptime(info.lstrip('发布时间:')[6:25], '%Y/%m/%d %H:%M:%S') #时间 item['content'] = soupd.select('.content')[0].text.strip() return (item) # print(getTheContent('http://card.gz.gov.cn/gzshbzk/bmwd/201708/508e252a9d1c4edcb123c7f93204be5c.shtml')) # 爬取一个列表页面内的所有咨询链接,并将链接返回到getTheContent(url1)中 def getOnePage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') lilist = soup.find('div', class_='lilist') # 指定class位置 list = lilist.findAll(class_='bmwd_wt') itemls = [] for item in list: if len(item.select('a')[0]['title']) > 0: url = item.select('a')[0]['href'] # 由于提取到的href是简略版(<li href="../../gzshbzk/dtxw/201707/b5f3ca9365954121a995bd5284bed095.shtml">)所以要替换一下 url1 = re.compile('../../') url2 = url1.sub('http://card.gz.gov.cn/', url) itemls.append(getTheContent(url2)) return (itemls) #print(getOnePage('http://card.gz.gov.cn/gzshbzk/bmwd/list_bmxx.shtml')) # 制作词云 def showwordcloud(cy): words = jieba.lcut(cy) counts = {} for word in words: # 统计词语出现次数 if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) # 划分为元组 items.sort(key=lambda x: x[1], reverse=True) cloudlist = '' for i in range(20): for j in range(items[i][1]): cloudlist += ' ' + items[i][0] cl_split = ''.join(cloudlist) # print(cl_split) mywc = WordCloud(font_path='msyh.ttc').generate(cl_split) plt.imshow(mywc) plt.axis("off") plt.show() # 合并所有content文本 def dealcontent(totallist): allcontent = '' # 来个空字符串 for a in range(len(totallist)): # len(itemtotal)=114 allcontent += itemtotal[a]['content'] + "\n" allcontent = allcontent.replace("\n", '') allcontent = allcontent.replace(" ", '') return (allcontent) itemtotal = [] listurl = 'http://card.gz.gov.cn/gzshbzk/bmwd/list_bmxx.shtml' # 首页新闻列表 itemtotal.extend(getOnePage(listurl)) for i in range(2, 7): # 第二页至尾页 listurl = 'http://card.gz.gov.cn/gzshbzk/bmwd/list_bmxx_{}.shtml'.format(i) itemtotal.extend(getOnePage(listurl)) df = pandas.DataFrame(itemtotal) df.to_excel('ansgzsbk.xlsx') # excel导出 print(len(itemtotal)) # 114 showwordcloud(dealcontent(itemtotal))
 结论:总的来说,人们对于广州市社保卡的关注点还是在于如何办理和申领,即使社保卡的功能多样,但其中的医保功能还是更为众所周知。
结论:总的来说,人们对于广州市社保卡的关注点还是在于如何办理和申领,即使社保卡的功能多样,但其中的医保功能还是更为众所周知。

