


python3 爬去QQ音乐
1 import requests 2 import re 3 import json 4 import os 5 6 7 8 def get_name(singer): 9 url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp' 10 params = { 11 'catZhida': '1', 12 'w': singer, 13 } 14 headers = { 15 'referer': 'https://y.qq.com/portal/search.html', 16 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' 17 } 18 html = requests.get(url,headers=headers,params=params).text 19 content = re.compile('callback\((.*)\)').findall(html)[0] 20 content = json.loads(content) 21 data = content.get('data') 22 song = data.get('song') 23 lists = song.get('list') 24 name = [] 25 for list in lists: 26 singer = list.get('singer')[0].get('mid') 27 name.append(singer) 28 name = name[0] 29 return name 30 31 def get_html(name,singer): 32 url = 'https://c.y.qq.com/v8/fcg-bin/fcg_v8_singer_track_cp.fcg' 33 params = { 34 'singermid': name, 35 'order': 'listen', 36 'begin': '0', 37 'num': '30', 38 } 39 headers = { 40 'referer': 'https://y.qq.com/n/yqq/singer/003aQYLo2x8izP.html', 41 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' 42 } 43 html = requests.get(url,headers=headers,params=params).text 44 return html 45 46 47 def get_music(vkey,songname,filename,singer): 48 if vkey and songname: 49 url3 = 'http://dl.stream.qqmusic.qq.com/' + filename + '?vkey=' + vkey + '&guid=7133372870&uin=0&fromtag=66' 50 51 headers = { 52 'referer': 'https://y.qq.com/n/yqq/singer/003aQYLo2x8izP.html', 53 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' 54 } 55 music = requests.get(url3,headers=headers).content 56 dir = singer 57 if not os.path.exists(dir): 58 os.mkdir(dir) 59 with open(dir+'/'+songname+'.m4a','wb') as f: 60 f.write(music) 61 print(songname,'__',singer) 62 63 def get_vkey(strMediaMid,songmid,songname,singer): 64 if strMediaMid and songmid and songname : 65 url2 = 'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg' 66 params = { 67 'g_tk': '5381', 68 'jsonpCallback': 'MusicJsonCallback8571665793949388', 69 'loginUin': '0', 70 'hostUin': '0', 71 'format': 'json', 72 'inCharset': 'utf8', 73 'outCharset': 'utf-8', 74 'notice': '0', 75 'platform': 'yqq', 76 'needNewCode': '0', 77 'cid': '205361747', 78 'callback': 'MusicJsonCallback8571665793949388', 79 'uin': '0', 80 'songmid': songmid, 81 'filename': 'C400'+ strMediaMid + '.m4a', 82 'guid': '7133372870' 83 } 84 headers = { 85 'referer': 'https://y.qq.com/portal/player.html', 86 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' 87 } 88 detail_html = requests.get(url2,headers=headers,params=params).text 89 vkey_disc = re.compile('MusicJsonCallback8571665793949388\((.*?)\)').findall(detail_html)[0] 90 vkey_disc = json.loads(vkey_disc) 91 92 data = vkey_disc['data'] 93 items = data.get('items')[0] 94 vkey = items.get('vkey') 95 get_music(vkey,songname,'C400'+ strMediaMid + '.m4a',singer) 96 97 98 def get_list(detail_html,singer): 99 if detail_html: 100 lists = re.compile('data\":{\"list\":(.*?),\"singer_id',re.S).findall(detail_html)[0] 101 datas = json.loads(lists) 102 for data in datas: 103 musicData = data.get('musicData') 104 strMediaMid = musicData.get('strMediaMid') 105 songmid = musicData.get('songmid') 106 songname = musicData.get('songname') 107 get_vkey(strMediaMid,songmid,songname,singer) 108 109 110 111 def main(): 112 singer = input('请输入您想要下载的歌手:') 113 name = get_name(singer) 114 detail_html = get_html(name,singer) 115 get_list(detail_html,singer) 116 117 if __name__ == '__main__': 118 main()
有些地方代码有些冗余,还可以再改进 但是费了些功夫终于爬出的效果 确实想要快点编辑出来 按耐不住小激动 这应该就是敲代码的乐趣
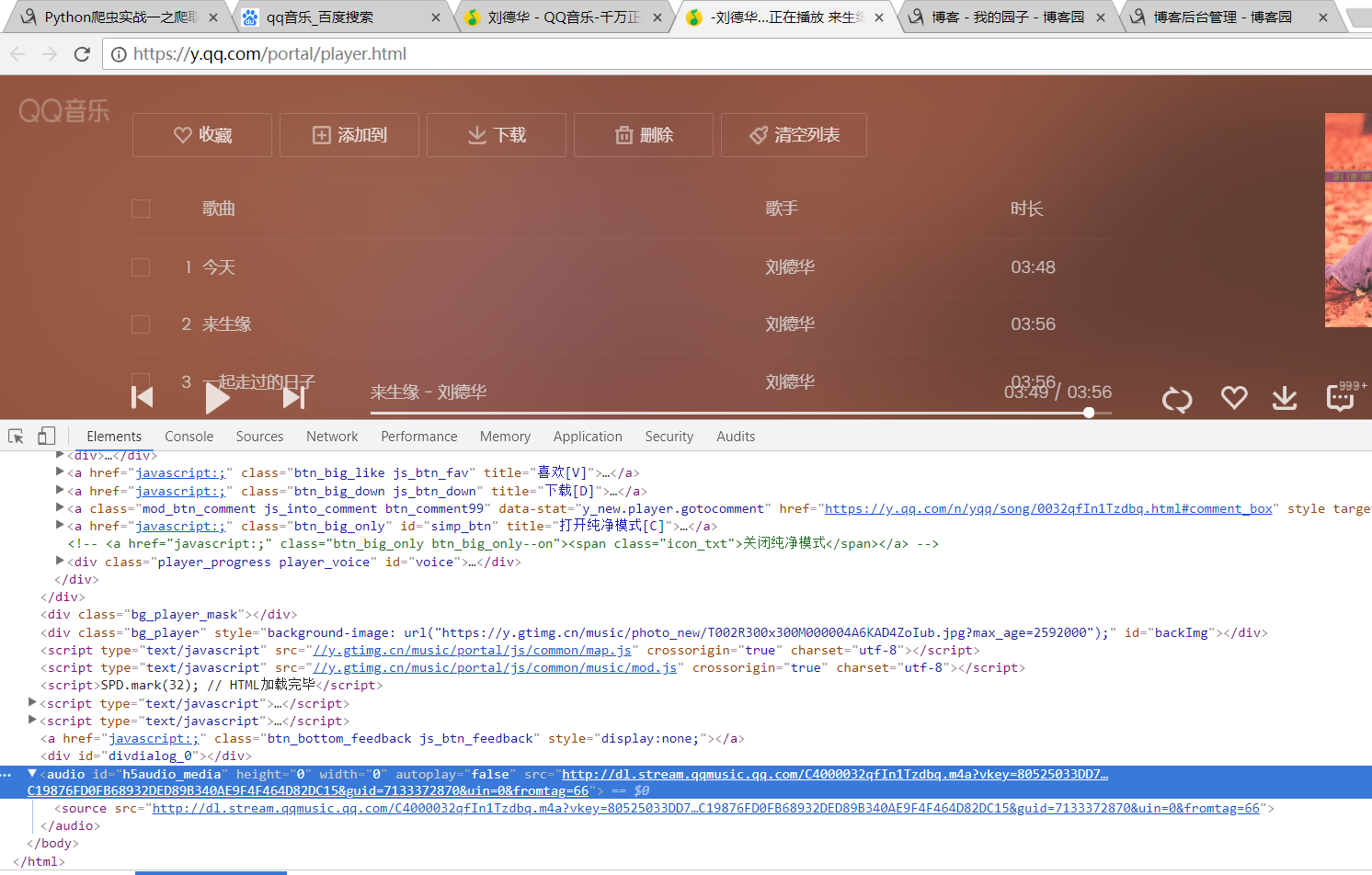
当播放一个音乐的时候 在Elements中 可以看到音乐的链接 当然是通过js 和 css 加载过的 但是 可以用逆向思维进行参数的找寻
http://dl.stream.qqmusic.qq.com/C4000032qfIn1Tzdbq.m4a?vkey=80525033DD719DAB87C0CEC7B4F9F40D8755982D3A495E3BA0810E50A89668A2AFD61C4C19876FD0FB68932DED89B340AE9F4F464D82DC15&guid=7133372870&uin=0&fromtag=66
发现 vkey 是一个很重要的参数 所以就先去翻一翻网页查一下vkey在哪
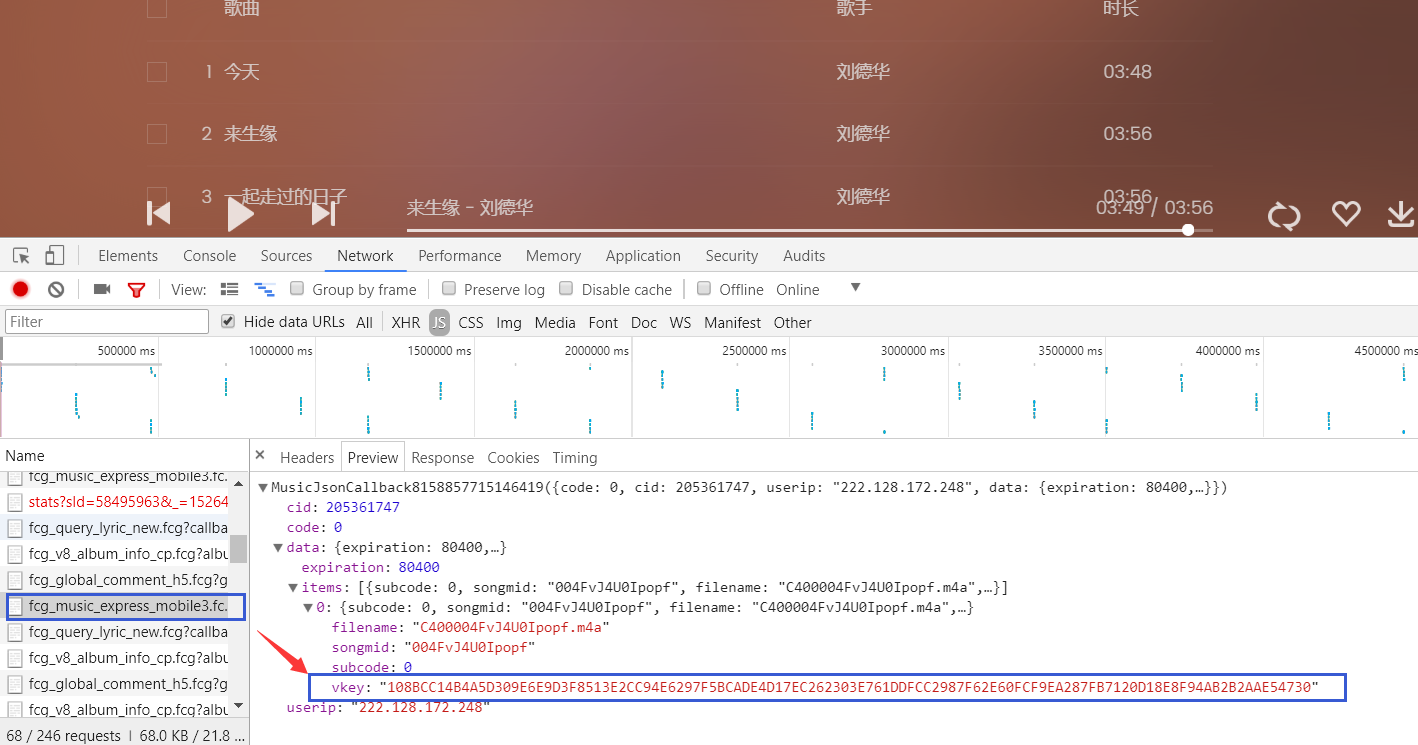
经发现 在同播放页面的JS中 但是如果想获得vkey 就需要访问这个对应的URL 也要找到相应的参数
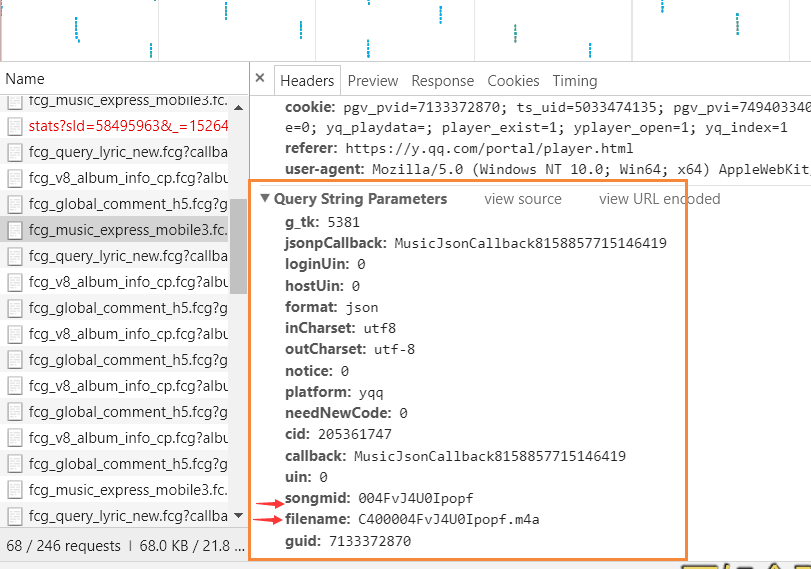
标红箭头的是一直在变化而且没有不行的参数
所以将继续往里使劲挖!
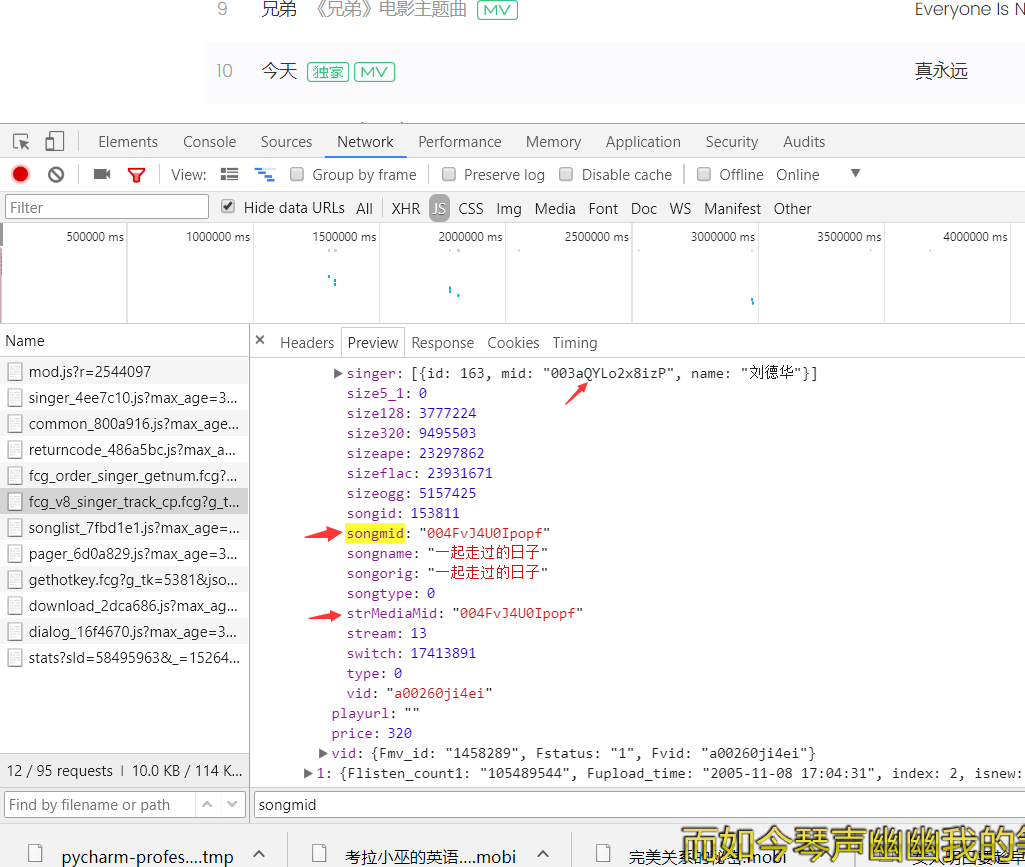
目前处于列表页 发现参数已经浮现
但发现第一个红箭头是歌手的意思 被不知道用了什么样的格式换了一种形式 因为后续还想通过段小乱码找到每个歌手所对应的歌曲 所以 还是找到每个歌手所对应的小乱码比较好
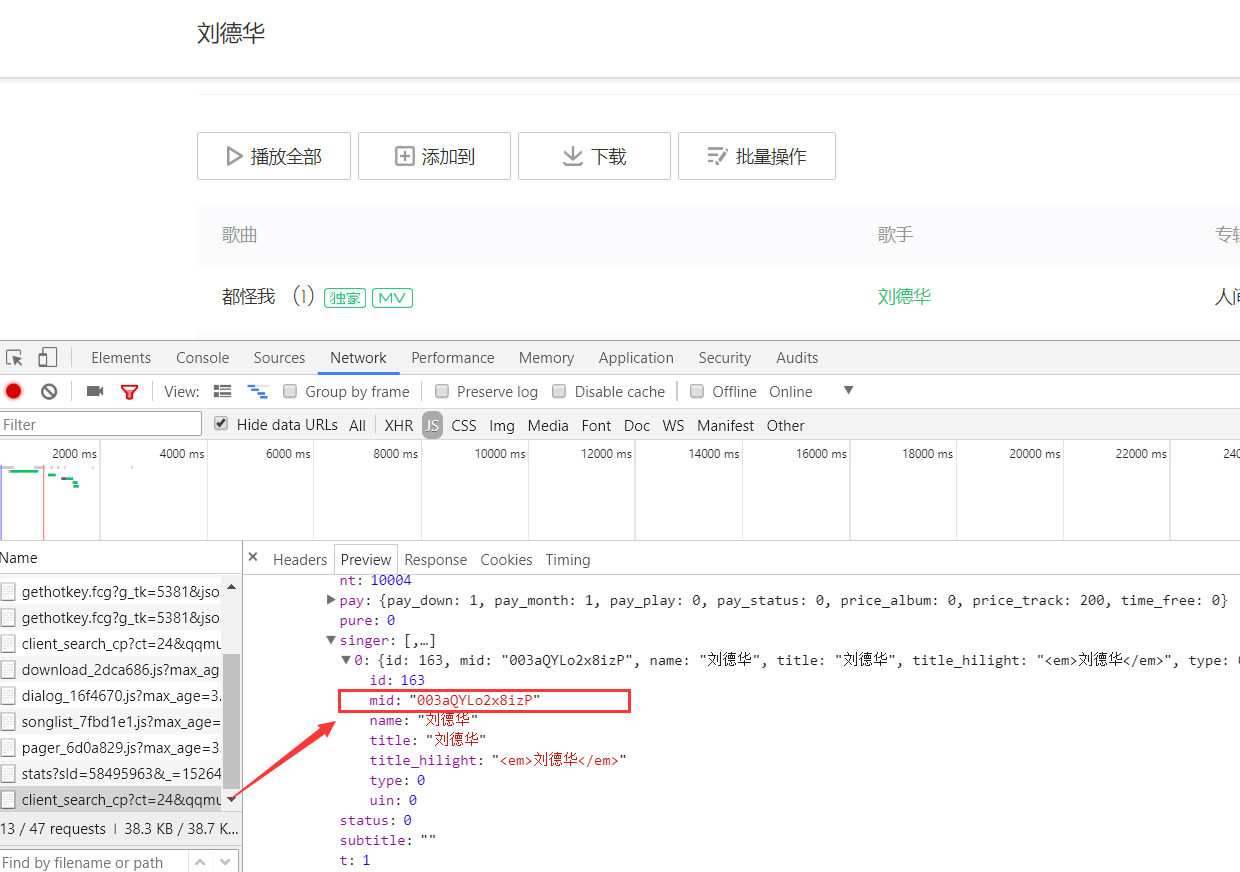
找到了!!!
但是 写代码的话 要用正向思维来写 Year!

