摘要:
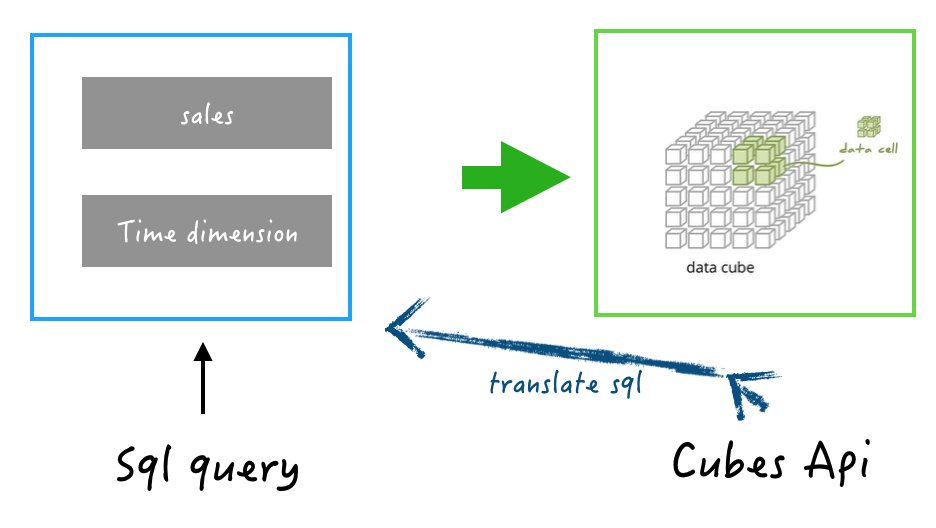 Cubes可以作为Kylin多维数据查询服务:
例如对0-4这几个销售点,我们要统计2012年每个季度的结果:
http://localhost:5000/cube/KYLIN_SALES/aggregate?drilldown=year.QUATER|site&cut=year.YEAR_BEG_DT:date'2012\-01\-01'|site:0-4
阅读全文
Cubes可以作为Kylin多维数据查询服务:
例如对0-4这几个销售点,我们要统计2012年每个季度的结果:
http://localhost:5000/cube/KYLIN_SALES/aggregate?drilldown=year.QUATER|site&cut=year.YEAR_BEG_DT:date'2012\-01\-01'|site:0-4
阅读全文
Cubes可以作为Kylin多维数据查询服务:
例如对0-4这几个销售点,我们要统计2012年每个季度的结果:
http://localhost:5000/cube/KYLIN_SALES/aggregate?drilldown=year.QUATER|site&cut=year.YEAR_BEG_DT:date'2012\-01\-01'|site:0-4
阅读全文
 Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高;
Superset提供了Presto连接,方便数据可视化和dashboard生成。
基于Presto和superset搭建数据分析平台。
Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高;
Superset提供了Presto连接,方便数据可视化和dashboard生成。
基于Presto和superset搭建数据分析平台。 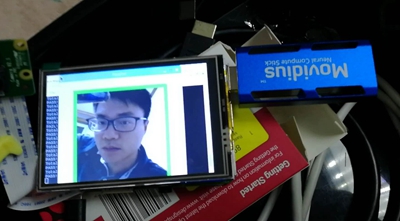 本文将描述基于raspberry 3B + movidius作为硬件平台,TensorFlow facenet作为模型实现人脸识别。
本文将描述基于raspberry 3B + movidius作为硬件平台,TensorFlow facenet作为模型实现人脸识别。