

ElasticSearch简介和快速实战
ElasticSearch与Lucene
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)
但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Lucene缺点:
1)只能在Java项目中使用,并且要以jar包的方式直接集成项目中.
2)使用非常复杂-创建索引和搜索索引代码繁杂
3)不支持集群环境-索引数据不同步(不支持大型项目)
4)索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘.共用空间少.
上述Lucene框架中的缺点,ES全部都能解决.
ES vs Solr比较
当单纯的对已有数据进行搜索时,Solr更快。当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。二者安装都很简单。
1、Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
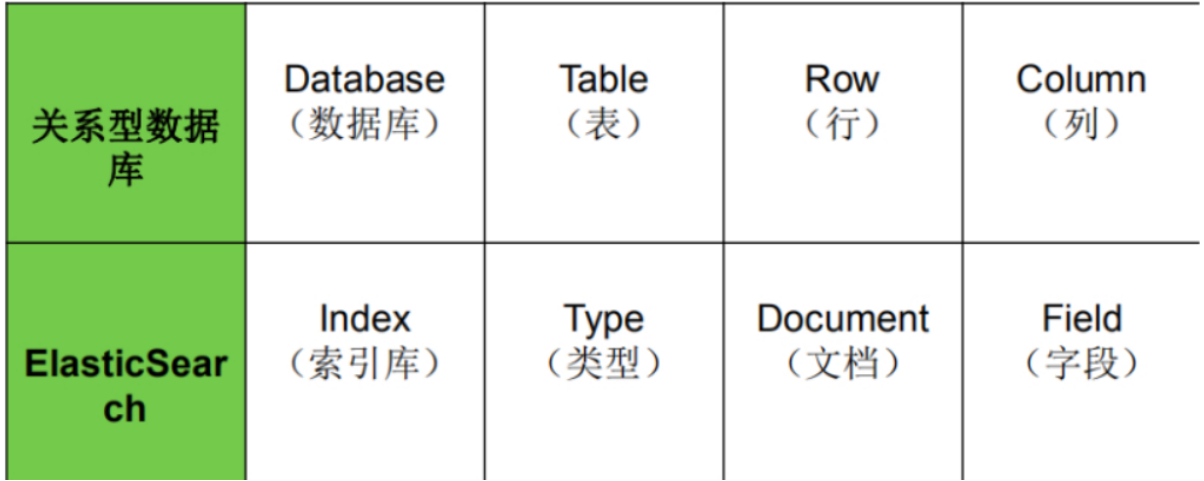
ES vs 关系型数据库
什么是全文检索
全文检索是指:
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
分词原理之倒排索引
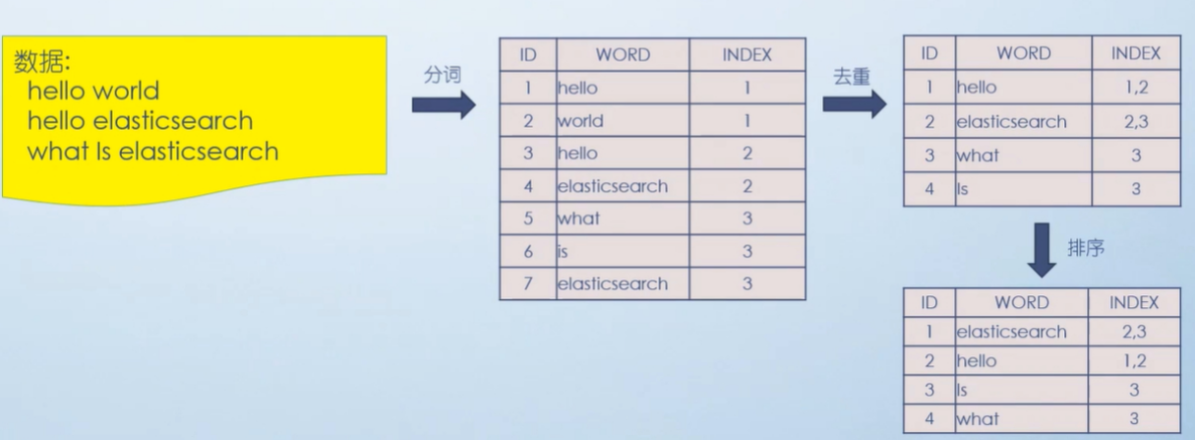

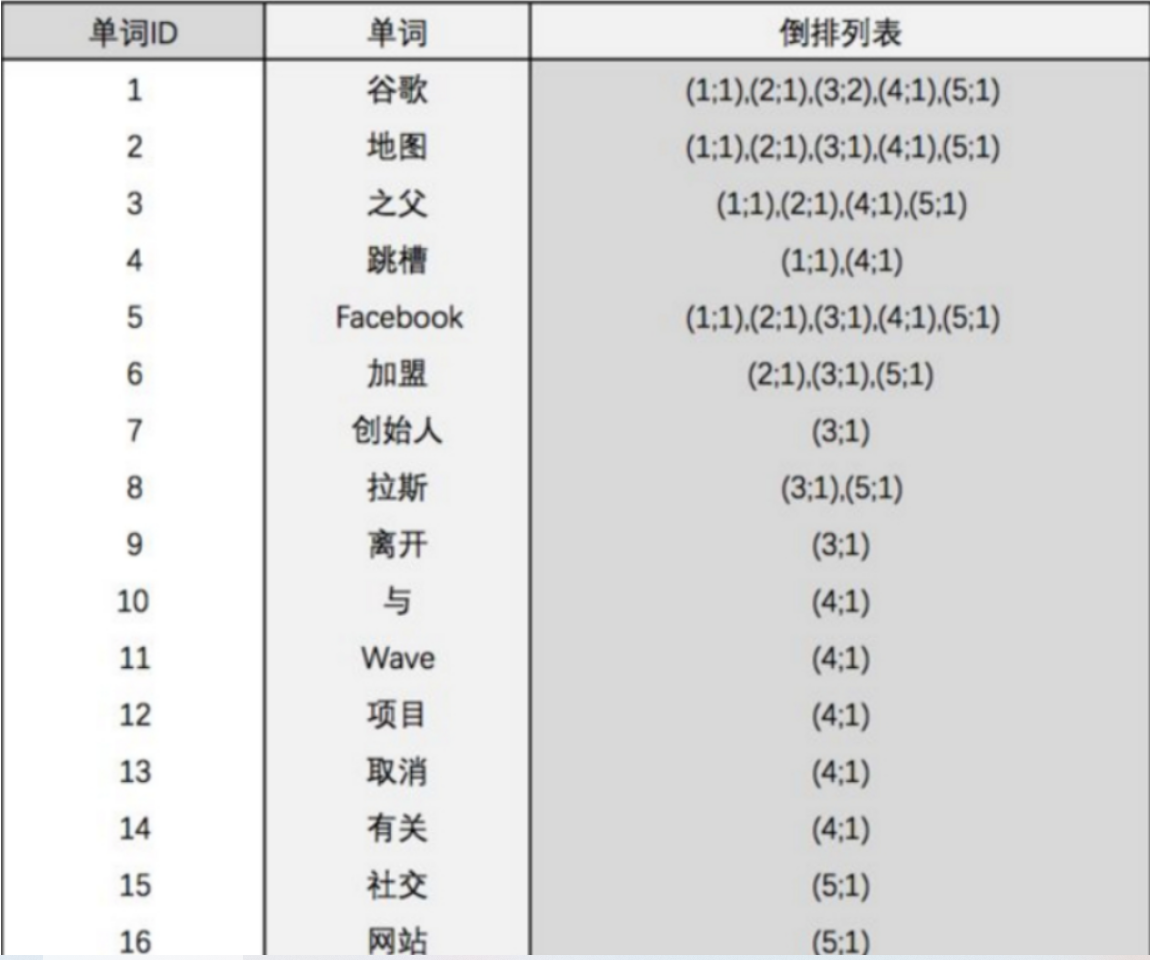
倒排索引总结:
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键.这里以一个博客文章的内容为例:
1.索引
| 文章ID | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 浅析JAVA设计模式 | JAVA设计模式是每一个JAVA程序员都应该掌握的进阶知识 |
| 2 | JAVA多线程设计模式 | JAVA多线程与设计模式结合 |
2.倒排索引
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引,因此倒排索引,也可称之为反向索引.如:
| 关键词 | 文章ID |
|---|---|
| JAVA | 1 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
注:这里涉及中文分词的问题
Elasticsearch中的核心概念
1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
2 映射 mapping
ElasticSearch中的映射(Mapping)用来定义一个文档
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的
3 字段Field
相当于是数据表的字段|列
4 字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
5 文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示;
6 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
7 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.8 分片和副本 shards&replicas
3.8.1 分片
-
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢
-
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
-
当创建一个索引的时候,可以指定你想要的分片的数量
-
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
-
分片很重要,主要有两方面的原因
允许水平分割/扩展你的内容容量
允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
3.8.2 副本
-
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本
-
副本之所以重要,有两个主要原因
1) 在分片/节点失败的情况下,提供了高可用性。
注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的
2) 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
每个索引可以被分成多个分片。一个索引有0个或者多个副本
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引
创建的时候指定
在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
测试分词效果
单字分词器
POST _analyze
{
"analyzer":"standard",
"text":"我爱你中国"
}
ik分词器
最粗力度拆分
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国人民大会堂"
}
最细力度拆分
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国人民大会堂"
}
指定IK分词器作为默认分词器
修改默认分词方法(这里修改school_index索引的默认分词为:ik_max_word):
PUT /school_index
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
ES数据管理
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用JSON作为文档序列化格式。
JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
ES存储的一个员工文档的格式示例:
{
"email": "584614151@qq.com",
"name": "张三",
"age": 30,
"interests": [ "篮球", "健身" ]
}
基本操作
1) 创建索引
格式: PUT /索引名称
PUT /es_db
2) 查询索引
格式: GET /索引名称
GET /es_db
3) 删除索引
格式: DELETE /索引名称
DELETE /es_db
4) 添加文档
格式: PUT /索引名称/类型/id
PUT /es_db/_doc/1{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"}PUT /es_db/_doc/2{"name": "李四","sex": 1,"age": 28,"address": "广州荔湾大厦","remark": "java assistant"}PUT /es_db/_doc/3{"name": "rod","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"}PUT /es_db/_doc/4{"name": "admin","sex": 0,"age": 22,"address": "长沙橘子洲头","remark": "python assistant"}PUT /es_db/_doc/5{"name": "小明","sex": 0,"age": 19,"address": "长沙岳麓山","remark": "java architect assistant"}
5) 修改文档
格式: PUT /索引名称/类型/id
PUT /es_db/_doc/1{"name": "白起老师","sex": 1,"age": 25,"address": "张家界森林公园","remark": "php developer assistant" }
注意:
POST和PUT都能起到创建/更新的作用
1、需要注意的是PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新
2、PUT只会将json数据都进行替换, POST只会更新相同字段的值
3、PUT与DELETE都是幂等性操作, 即不论操作多少次, 结果都一样
6) 查询文档
格式: GET /索引名称/类型/id
GET /es_db/_doc/1
7) 删除文档
格式: DELETE /索引名称/类型/id
DELETE /es_db/_doc/1
Restful风格
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。 基于Restful API ES和所有客户端的交互都是使用JSON格式的数据.
其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信
GET查询
PUT添加
POST修改
DELE删除
使用Restful的好处:
透明性,暴露资源存在。
充分利用 HTTP 协议本身语义,不同请求方式进行不同的操作
查询操作
1 查询当前类型中的所有文档
格式: GET /索引名称/类型/_search
GET /es_db/_doc/_search
SQL: select * from student
2 条件查询
如要查询age等于28岁的
格式: GET /索引名称/类型/_search?q=age:28
GET /es_db/_doc/_search?q=age:28
SQL: select * from student where age = 28
3 范围查询
如要查询age在25至26岁之间的
格式: GET /索引名称/类型/_search?q=age[25 TO 26] 注意: TO 必须为大写
GET /es_db/_doc/_search?q=age[25 TO 26]
SQL: select * from student where age between 25 and 26
4 根据多个ID进行批量查询 _mget
格式: GET /索引名称/类型/_mget
GET /es_db/_doc/_mget{ "ids":["2","3"] }
select * from student where id in (2,3)
5 查询年龄小于等于28岁的 :<=
格式: GET /索引名称/类型/_search?q=age:<=28
GET /es_db/_doc/_search?q=age:<=28
SQL: select * from student where age <= 28
6 查询年龄大于28前的 :>
格式: GET /索引名称/类型/_search?q=age:>26
GET /es_db/_doc/_search?q=age:>26
SQL: select * from student where age > 28
7 分页查询
格式: GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1
SQL: select * from student where age between 25 and 26 limit 0, 1
8 对查询结果只输出某些字段**
格式: GET /索引名称/类型/_search?__source=字段,字段
GET /es_db/_doc/_search?_source=name,age
SQL: select name,age from student
9 对查询结果排序**
格式: GET /索引名称/类型/_search?sort=字段 desc
GET /es_db/_doc/_search?sort=age:desc
SQL: select * from student order by age desc
文档批量操作
1.批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
(1)在URL中不指定index和type
-
请求方式:GET
-
请求地址:_mget
-
功能说明 : 可以通过ID批量获取不同index和type的数据
-
请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET _mget{ "docs": [ { "_index": "es_db", "_id": 3 }, { "_index": "es_db", "_id": 2 } ]}
(2)在URL中指定index
-
请求方式:GET
-
请求地址:/{{indexName}}/_mget
-
功能说明 : 可以通过ID批量获取不同index和type的数据
-
请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET /es_db/_mget{ "docs": [ { "_type":"_doc", "_id": 3 }, { "_type":"_doc", "_id": 4 } ]}
(3)在URL中指定index和type
-
请求方式:GET
-
请求地址:/{{indexName}}/{{typeName}}/_mget
-
功能说明 : 可以通过ID批量获取不同index和type的数据
-
请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET /es_db/_doc/_mget{ "docs": [ { "_id": 3 }, { "_id": 2 } ]}
2.批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
-
请求方式:POST
-
请求地址:_bulk
-
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
-
- 第一行参数为指定操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}{"field1":"value1", "field2":"value2"}
- actionName:表示操作类型,主要有create,index,delete和update
(1)批量创建文档create
POST _bulk{"create":{"_index":"article", "_id":3}}{"id":3,"title":"白起老师1","content":"白起老师666","tags":["java", "面向对象"],"create_time":1554015482530}{"create":{"_index":"article", "_id":4}}{"id":4,"title":"白起老师2","content":"白起老师NB","tags":["java", "面向对象"],"create_time":1554015482530}
(2)普通创建或全量替换index
POST _bulk{"index":{"_index":"article", "_id":3}}{"id":3,"title":"图灵徐庶老师(一)","content":"图灵学院徐庶老师666","tags":["java", "面向对象"],"create_time":1554015482530}{"index":{"_index":"article", "_id":4}}{"id":4,"title":"图灵诸葛老师(二)","content":"图灵学院诸葛老师NB","tags":["java", "面向对象"],"create_time":1554015482530}
(3)批量删除delete
POST _bulk{"delete":{"_index":"article", "_id":3}}{"delete":{"_index":"article", "_id":4}}
(4)批量修改update
POST _bulk{"update":{"_index":"article", "_id":3}}{"doc":{"title":"ES大法必修内功"}}{"update":{"_index":"article", "_id":4}}{"doc":{"create_time":1554018421008}}

