机器学习之文本特征提取
机器学习算法往往无法直接处理文本数据,需要把文本数据转换为数值型数据,One-Hot表示把文本转换为数值的一种方法。
一,One-Hot表示
One-Hot表示是把语料库中的所有文本进行分词,把所有单词(词汇)收集起来,并对单词进行编号,构建一个词汇表(vocabulary),词汇表是一个字典结构,key是单词,value是单词的索引
vocabulary = { 'one':0,'hot':1, ...'term':n-1}
如果词汇表有n个单词构成,那么单词的索引从0开始,到n-1结束。
有了词汇表之后,就可以使用向量来表示单个词汇。每一个词汇都表示为一个由n列构成的向量,称作词向量,词向量的第0列对应词汇表(vocabulary)中的第0号索引,词向量的第1列对应词汇表(vocabulary)中的第1号索引,依次类推。
词汇向量有n列,但是只有一列的值为1,把值为1的列的索引带入到词汇表(vocabulary)中,就可以查找到该词向量表示的词汇,也就是说,对于某个单词 term,如果它出现在词汇序列中的位置为 k,那么它的向量表示就是“第 k 位为1,其他位置都为0 ”,这就是One-Hot(独热)名称的由来。
1,用One-Hot表示单词
例如,有语料库(corpus)如下:
John likes to watch movies. Mary likes movies too.
John also likes to watch football games.
把上述语料中的词汇整理出来并进行排序(具体的排序原则可以有很多,例如可以根据字母表顺序,也可以根据出现在语料库中的先后顺序),假设我们的词汇表排序结果如下:
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also":6, "football": 7, "games": 8, "Mary": 9, "too": 10}
那么,得出如下词向量表示:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
……
2,文档向量
文档向量的表示方法是直接把各词的词向量表示加和,那么原来的两句话的向量表示如下:
[1, 2, 1, 1, 2, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
文档向量中,列的值表示词在文档中出现的次数。
3,One-Hot表示的缺点
One-Hot方法很简单,但是它的问题也很明显:
- 没有考虑单词之间的相对位置,任意两个词之间都是孤立的;
- 如果文档中有很多词,词向量会有很多列,但是只有一个列的值是1;
4,One-Hot表示的应用
sklearn使用词袋(Bag of Words)和TF-IDF模型来表示文本数据,这两个模型都是One-Hot表示的应用,其中,词袋模型对应的就是文档向量。
二,词袋模型
词袋模型(BoW)是用于文本表示的最简单的方法, BoW把文本转换为文档中单词出现次数的矩阵,该模型只关注文档中是否出现给定的单词和单词出现频率,而舍弃文本的结构、单词出现的顺序和位置。
1,构建词袋模型的步骤
对于一个文本语料库,构建词袋模型有三个步骤:
- 文本分词:把每个文档中的文本进行分词
- 构建词汇表:把文本分词得到的单词构建为一个词汇表,包含文本语料库中的所有单词,并对单词进行编号,假设词汇表有n个单词,单词编号从0开始,到n-1结束,可以把单词编号看作是单词的索引,通过单词编号可以唯一定位到该单词。
- 词向量表示:每个单词都表示为一个n列的向量,在单词编号(词汇索引)位置上的列值为1,其他列的值为0
- 统计频次:统计每个文档中每个单词出现的频次。
举个例子,有如下包含三个文档(doc)的语料库,每个文档是一行文本:
Doc 1: I love dogs.
Doc 2: I hate dogs and knitting.
Doc 3: Knitting is my hobby and passion.
根据语料库,对文本进行分词,创建词汇表。根据词汇表计算每个文档中的单词出现的次数,这个矩阵叫做文档-词矩阵(DTM,Document-Term Matrix)。
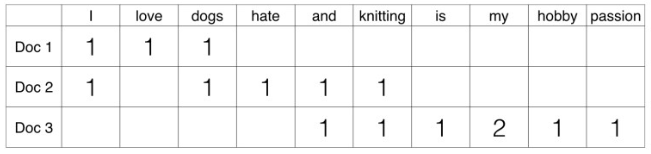
这个矩阵使用的是单个词,也可以使用两个或多个词的组合,叫做bi-gram模型或tri-gram模型,统称n-gram模型。
使用sklearn构建词袋模型:
CountVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern=’(?u)\b\w\w+\b’, ngram_range=(1, 1), analyzer=’word’, max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class ‘numpy.int64’>)
常用参数注释:
- input:默认值是content,表示输入的是顺序的字符文本
- decode_error:默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误
- lowercase:默认值是True,在分词(Tokenize)之前把文本中的所有字符转换为小写。
- preprocessor:预处理器,在分词之前对文本进行预处理,默认值是None
- tokenizer:分词器,把文本字符串拆分成各个单词(token),默认值是None
- analyzer:用于预处理和分词,可设置为string类型,如’word’, ‘char’, ‘char_wb’,默认值是word
- stop_words:停用词表,如果值是english,使用内置的英语停用词列表;如果是一个列表,那么使用该列表作为停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表
- ngram_range:tuple(min_n,max_n),表示ngram模型的范围
- max_df:可以设置为范围在[0.0 1.0]的浮点数,也可以设置为没有范围限制的整数,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的词汇表时,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效
- min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词
- max_features:对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
- vocabulary:默认为None,自动从输入文档中构建关键词集,也可以是一个字典或可迭代对象。
- binary:默认为False,一个关键词在一篇文档中可能出现n次;如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的
- dtype :用于设置fit_transform() 或 transform()函数返回的矩阵元素的数据类型
模型的属性和方法:
- vocabulary_:词汇表,字典类型
- get_feature_names():所有文本的词汇,列表型
- stop_words_:停用词列表
模型的主要方法:
- fit(raw_document):拟合模型,对文本分词,并构建词汇表等
- transform(raw_documents):把文档转换为文档-词矩阵
- fit_transform(raw_documents):拟合文档,并返回该文档的文档-词矩阵
2,单个词的词袋模型
使用CounterVectorizer()函数构建单个词的词袋模型:
>>> from sklearn.feature_extraction.text import CountVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = CountVectorizer() >>> dt = vectorizer.fit_transform(corpus) >>> print(vectorizer.get_feature_names()) ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'] >>> print(dt.toarray()) [[0 1 1 1 0 0 1 0 1] [0 2 0 1 0 1 1 0 1] [1 0 0 1 1 0 1 1 1] [0 1 1 1 0 0 1 0 1]]
三,TF-IDF模型
TF-IDF模型用于对特征信息量进行缩放,当一个词在特定的文档中经常出现,而在其他文档中出现的频次很低,那么给予该词较高的权重;当一次词在多个文档中出现的频次都很高,那么给予该词较低的权重。如果一次单词在特定的文档中出现的频次很高,而在其他文档中出现的频次很低,那么这个单词很可能是该文档独有的词,能够很好地描述该文档。
1,TF-IDF模型计算原理
TF( Term Frequency)是词频,表示每个单词在文档中的数量(频数),TF依赖于BoW模型的输出。
IDF(Inverse Document Frequency)是逆文档频率,代表一个单词的普遍成都,当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。IDF是包含该单词的文档数量和文档总数的对数缩放比例

TF-IDF(术语频率 - 逆文档频率)模型是TF和IDF相乘的结果:TF-IDF=TF*IDF。
在文档中具有高tf-idf的单词,大多数情况下,只发生在给定的文档中,并且在其他文档中不存在,所以这些词是该文档的特征词汇。
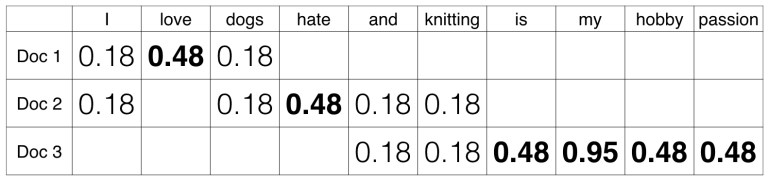
2,构建TF-IDF模型
使用TfidfVectorizer()函数构建TF-IDF模型
TfidfVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern=’(?u)\b\w\w+\b’, ngram_range=(1, 1), analyzer=’word’, max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=dtype=<class ‘numpy.float64’>, norm=’l2’, use_idf=True, smooth_idf=True, sublinear_tf=False)
大部分参数和CountVectorizer相同,TfidfVectorizer独有的参数注释:
- norm=’l2’:每个输出行具备单位规范,当引用'l2'范式时,所有向量元素的平方和为1;当应用l2范数时,两个向量之间的余弦相似度是它们的点积。 *'l1':向量元素的绝对值之和为1。
- use_idf=True:启用IDF来重新加权
- smooth_idf=True:平滑idf权重,向文档-词频矩阵的所有位置加1,就像存在一个额外的文档,只包含词汇表中的每个术语一次,目的是为了防止零分裂。
- sublinear_tf=False:应用次线性tf缩放,默认值是False。
举个例子,使用TfidfVectorizer()函数构建以下四个句子的TF-IDF模型:
>>> from sklearn.feature_extraction.text import TfidfVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = TfidfVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> print(vectorizer.get_feature_names()) ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'] >>> print(X.toarray()) [[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524] [0. 0.6876236 0. 0.28108867 0. 0.53864762 0.28108867 0. 0.28108867] [0.51184851 0. 0. 0.26710379 0.51184851 0. 0.26710379 0.51184851 0.26710379] [0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]]
四,查看文档的特征
对Bow和TF-IDF算法生成的模型进行操作
1,查看文本特征
从原始文档列表(语料)中获取特征列表:
>>> print(vectorizer.get_feature_names()) ['adr', 'authorized', 'contact', 'device', 'distributor', 'hub', 'information', 'installer', 'interested', 'microsoft', 'partner', 'program', 'receive', 'reseller', 'sign', 'surface', 'updates', 'website']
2,查看词汇表
查看词汇表中的词汇和其对应的索引:
>>> items=vectorizer.vocabulary_.items() >>> print(items) dict_items([('information', 6), ('surface', 15), ('hub', 5), ('microsoft', 9), ('authorized', 1), ('device', 3), ('reseller', 13), ('adr', 0), ('interested', 8), ('contact', 2), ('distributor', 4), ('sign', 14), ('receive', 12), ('updates', 16), ('program', 11), ('partner', 10), ('website', 17), ('installer', 7)])
把dict_items结构转换为Python的字典结构,key是索引,value是词汇:
>>> feature_dict = {v: k for k, v in vectorizer.vocabulary_.items()}
3,查看词-文档矩阵
模型的fit_transform()或tranform()函数返回的是词-文档矩阵,在词-文档矩阵中列代表的是特征,行代表的原始文档的数量,列代表该文档包含的特征(即词汇),列值是特征的TD-IDF值,范围从0-1。
>>> print(X.toarray()) [[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524] [0. 0.6876236 0. 0.28108867 0. 0.53864762 0.28108867 0. 0.28108867] [0.51184851 0. 0. 0.26710379 0.51184851 0. 0.26710379 0.51184851 0.26710379] [0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]]
参考文档:
sklearn.feature_extraction.text.TfidfVectorizer

