使用Python脚本批量裁切栅格
对栅格的裁切,我们通常使用裁切(数据管理-栅格-栅格处理)或按掩膜提取(空间分析-提取分析)来裁切,裁切的矢量要素通常是一个要素图层或Shape文件。如果要进行批量处理,可以使用ToolBox中的批量处理工具。但是,有时我们选择的裁切矢量要素不是一个要素图层,而是要素图层中的一个要素,如按标准图幅裁切栅格影像,以前的做法是将要素一个一个的导出来,再进行批量处理。快速导出方法:ArcGIS按字段属性分割文件。
现在,可以使用Python脚本来批量裁切,在网上找了位大神的原始代码学习一下:
#-*- encoding:UTF-8 -*-
# Tool Name: 遍历要素裁剪栅格
# Source Name: extractByMask.py
# Version: ArcGIS 10.1
# Author: GIScloud
# Created: 2012/11/1
import arcpy
import string
from arcpy.sa import *
try:
raster = arcpy.GetParameterAsText(0) #要裁剪的栅格
clip_feat = arcpy.GetParameterAsText(1) #裁剪要素类
field = arcpy.GetParameterAsText(2) #命名字段
outworkspace = arcpy.GetParameterAsText(3) #命名字段裁剪后输出目录
for row in arcpy.SearchCursor(clip_feat):
mask=row.getValue("Shape")
outPath=outworkspace+"\\"+str(row.getValue(field))
outExtractByMask = ExtractByMask(raster,mask)
outExtractByMask.save(outPath)
except arcpy.ExecuteError:
print arcpy.GetMessages()
将脚本导入ToolBox中(导入方法:ArcGIS使用Python脚本工具),执行报错:UnicodeEncodeError: 'ascii' codec can't encode characters in position 32-34: ordinal not in range(128)问题,使用的是ulipad编译器。
看样子是编码的问题,查了一下解决方案:在开头加上代码设置默认编辑
import sys reload(sys) sys.setdefaultencoding( "utf-8" )
-
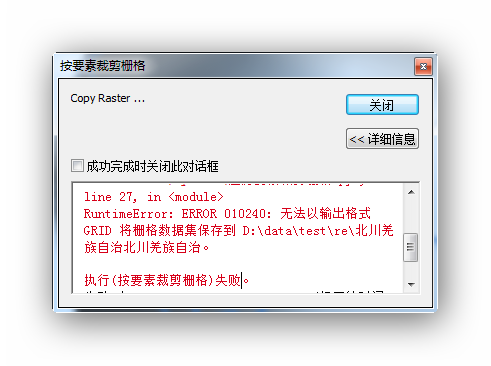
能够实现部分裁切了,但最后一个出了问题,看消息输出的文件名中怎么多了一个句号?
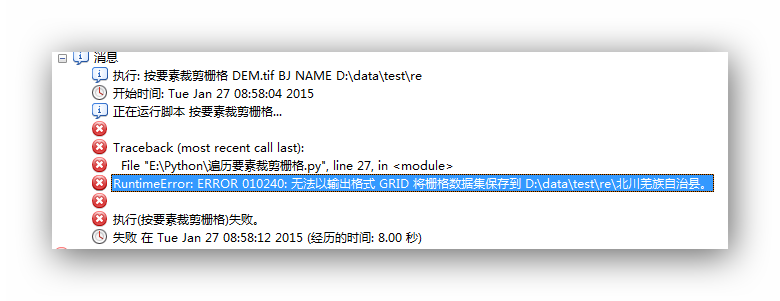
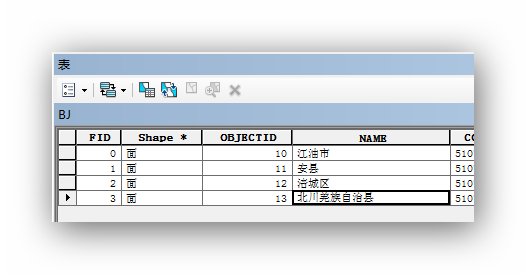
查看属性表,没有问题。将输出字段"北川羌族自治县"改为"北川羌族自治"能够正确输出,如果改成"北川羌族自治北川羌族自治",又报相同的错误。说明应该就是输出名称长度的问题。
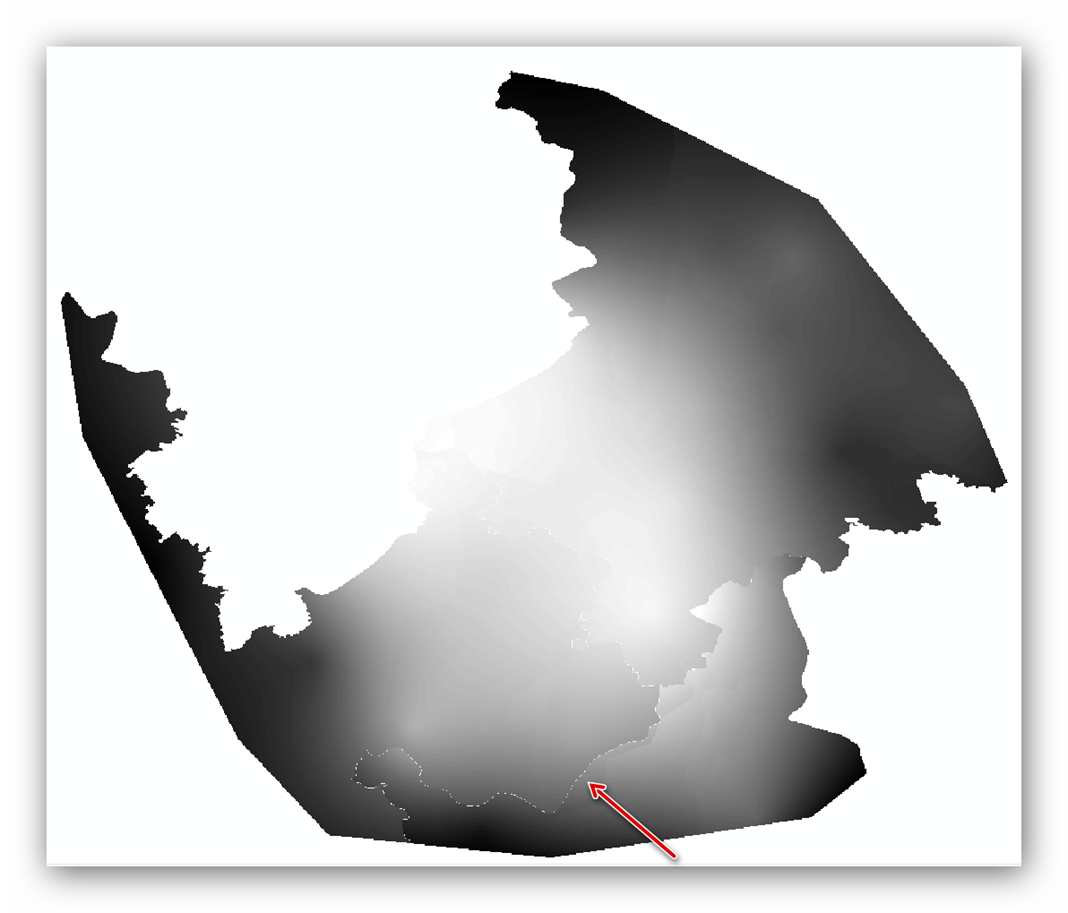
还有一个问题,输出的不同栅格边界接连有点小问题,如果避免这种情况,只能更改系统变量,输出更小的单元格大小。
参考:http://bbs.esrichina-bj.cn/ESRI/viewthread.php?tid=121642
http://blog.sina.com.cn/s/blog_64a3795a01018vyp.html
作者:我也是个傻瓜
出处:http://www.cnblogs.com/liweis/
签名:成熟是一种明亮而不刺眼的光辉。


