
特来电监控引擎流计算应用实践
随着云计算的深入落地,大数据技术有了坚实的底层支撑,不断向前发展并日趋成熟,无论是传统企业还是互联网公司,都不再满足于离线批处理计算,而是更倾向于应用实时流计算,要想在残酷的企业竞争中立于不败之地,企业数据必须被快速处理并输出结果,流计算无疑将是企业Must Have的大杀器。作为充电生态网的领军企业,特来电在流计算方面很早便开始布局,下面笔者抛砖引玉的谈一下流计算及在特来电监控引擎中的应用实践。
一、由Bit说开去

作为计算机信息中的最小单位,Bit就像工蚁一样忙碌,任一时刻都只能处于以下三种状态中的一种:计算、存储、传输,要么在参与计算,要么在去计算的路上,要么等候计算。见微知著,云计算架构图中,底层IAAS必然有三个模块:计算、存储、网络,因为微观的Bit状态本质,决定了宏观的架构行为。无论微观还是宏观,不难发现计算是永恒的主题,一切都围绕着计算进行,计算的结果,便会产生数据。
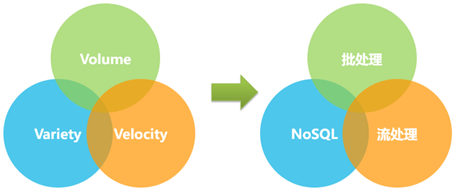
今天如火如荼的大数据,本质也是数据,但是又多了一些新的特征,比如老生常谈的“4V”:Volume(数据量大,至少是TB级,甚至是PB级)、Velocity(数据增长速度快)、Variety(数据格式多样,结构化、半结构化、非结构化)、Value(数据价值大)。大数据之所以能落地,不是依靠表面的“V”,而是“V”后强有力的支撑工具,比如用批处理工具高吞吐的支撑“Volume”,用流计算工具低延迟的支撑“Velocity”,用NoSQL工具高效存储支撑“Variety”等。针对这几个“V”,笔者总结了两个共识:1. 大数据的发展,将逐渐从Volume之大,转向Velocity之大;2.数据的价值(Value)随着时间流逝而急剧下降。这就要求必须快速处理数据,所以我们应该专注流计算。
流计算(Streaming Computing)是一种被设计来处理无穷数据集的数据处理系统引擎,流计算面向的对象是无穷数据(一种持续生成,本质上是无穷尽的数据集),与之相对的批处理面对的是有限固定的数据集。子在川上曰:逝者如斯夫!面对滚滚的无穷数据集,流计算该怎样处理它们呢?答案便是使用窗口,就是对一个无限的流设置一个有限的元素集合,在有界的数据集上进行操作的一种机制,可以分为基于时间(Time-based,比如1分钟一个窗口进行计算)以及基于数量(Count-based,比如100个数一个窗口进行计算)。
流计算早期是不成熟的,因为在实现上存在一些技术难点:如何保证强一致性、如何做到精确一次(Exactly-Once)的处理数据、如何应对网络抖动时数据的乱序与延迟到达,如何按数据的发生时间(Event Time)进行计算而不是数据被处理的时间(Processing Time)、如何在流数据上执行Streaming SQL、如何解决数据接收速度大于数据处理速度时带来的背压问题等。令人欣慰的是,随着技术的不断发展,以上问题都被逐步解决,流计算已经可以媲美并超越传统批处理计算,总结起来,流计算发展经历了三个阶段:
1.Lambda架构(一套数据、两个处理引擎、两套代码);
2.Kappa架构(一套数据、一个处理引擎、一套代码,当需要全量计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个结果存储中);
3.真正流计算,典型特性有:事件驱动、Exactly-Once、以流计算为主、流计算与批处理完全统一。
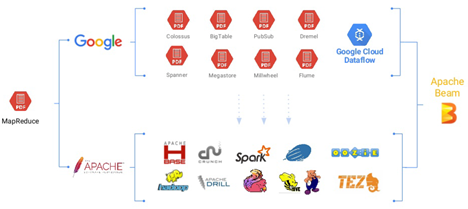
大数据是从批处理开始的, MapReduce花开两枝,一枝是闭源的Google,一枝是开源的Apache,基本上谷歌内部有的大数据工具,都有对应的开源实现,Apache Beam则希望做救世主,让闭源和开源大数据工具有一个统一的开发界面,为上层应用开发做透明代理,屏蔽底层的各种实现方式。在乱花渐欲迷人眼的各种大数据工具中,我们必须保持一种技术定力,否则很容易陷入技术虚无主义。基于前面分析的原则:要快速处理数据、要专注流计算、要基于真正流计算工具等,我们最终选定了老当益壮的Flink,这也是目前在Apache Beam上运行的最好的开源Runner。
二、老当益壮的Flink
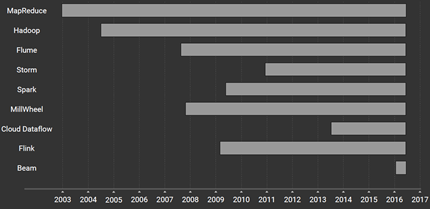
上图是一些主流开源及闭源大数据工具的起源时间,可以看到Flink(欧洲)和Spark(美国)虽然都发轫于2009年,但Flink其实是比Spark稍早一点的,不过从当前发展形势看,Spark意欲一统大数据天下,已经对Flink以及其他大数据工具形成了碾压态势,Flink可谓“起个大早赶个晚集”,这很大程度上也和欧洲及美国的商业化环境有关。尽管如此,Flink仍能够倔强成长,一方面是大家不希望看到Spark一家独大,需要保持平衡;另一方面则是Flink着实有自己的独门绝技,否则早被Spark拍死了。

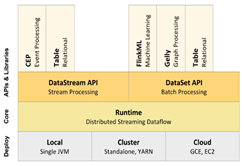
上图左边是Spark技术栈,右边是Flink技术栈,不难发现,二者使命相同,都是要提供“One Stack To Rule Them All”的一站式大数据分析解决方案(涵盖批处理、流计算、机器学习、图计算等)。除了开源社区,Spark背后有DataBricks商业公司在运作,Flink背后有DataArtisans商业公司在运作,由于生态环境不同,因此愿景稍有差异。不过最大的差异在于二者的价值观:Spark以批处理为主,认为流计算是批处理的特例,使用微批处理(Micro-Batch)来应对流计算;Flink以流计算为主,认为批处理是流计算的特例,使用一段时间内的有限数据集来应对批处理。打个比方,Spark和Flink一起吃面包,Spark正常情况下是一口一个面包的吃,遇到流计算时,把面包切片了,一口一个面包片的吃;Flink正常情况下一口一个面包片的吃,遇到批处理时,几个面包片一起吃,也能一口吃一个面包了。从长远来看,Flink的设计理念更契合流计算的标准模型及本质特征,除Google闭源工具外,它是第一个真正实现乱序数据处理的开源流计算引擎,下面简要看一下Flink的关键技术点。
- Exactly-Once
Exactly-Once是流处理系统核心特性之一,它保证每一条消息只被流处理系统处理一次,通过借鉴Chandy和Lamport在1985年发表的一篇关于分布式快照的论文,Flink实现了Exactly-Once特性。它根据用户自定义的Checkpoint间隔时间,定时在所有数据源中插入一种特殊的快照标记消息(Barrier),这些快照标记消息和其他数据消息一起在DAG(有向无环图)中流动,但不会被用户定义的业务逻辑所处理,快照的存储是异步和增量操作,不会阻塞数据消息的处理。若发生节点挂掉等异常情况时,只需要恢复之前成功存储的分布式快照状态,并从数据源重发该快照以后的消息即可,当然这也要求数据输出端持久化时支持幂等操作。
- 三个时间域
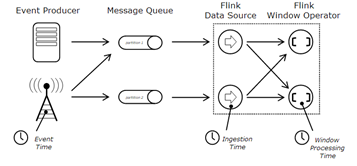
如上图所示,Flink支持三个时间域:
a) Event Time:事件时间
每个数据都要携带一个时间戳,用于标记数据产生时间。
b) Ingestion Time:摄取时间
数据被从消息队列(比如Kafka),提取到Flink时的时间。
c) Processing Time:处理时间
数据真正被处理时所在机器的时间。
打个比方,笔者在网上订了一本关于Flink的书(迄今没有Flink相关的中文书籍出版),这本书的出版日期是Event Time,从快递员手里接过书的当天日期是Ingestion Time,真正看这本书的当天日期是Processing Time。
一般的流计算系统进行数据处理时,都是基于Processing Time的,这相对来说比较简单,即不管数据是什么时间产生的,都以数据实际被处理时所在机器的时间为准,这在计数类应用或者计时不敏感类应用中可能没啥影响,但是如果要严格按照数据实际产生时间进行计算的计时类应用,则当数据乱序产生或者延迟到达时,计算结果将会大相径庭,令人赞叹的是,Flink能够轻松应对上述三种时间域的计算。
- 四种窗口
时间域确定了计算数据时的时间类型,而窗口则要确定对多长时间内或多少个数据进行计算,Flink支持四种内置窗口:
a) Tumbling Window:翻滚窗口、固定窗口
每个窗口的大小是固定的(比如1分钟),各个窗口内的数据互不重叠。
b) Sliding Window:滑动窗口
每个窗口由两个时间构成,一个是窗口大小时间(比如1分钟),一个是窗口滑动时间(比如30秒),各个窗口内数据有重叠,比如要每隔30秒统计过去1分钟的数据。
c) Session Window:会话窗口
用于标记一段用户持续活跃的周期,由非活跃的间隙分隔开。各个窗口内数据互不重叠,没有固定的开始时间和结束时间,当它在一个固定的时间周期内不再收到数据,即非活动间隔产生,这个会话窗口就会关闭,后续的数据将被分配到新的窗口中去。
d) Global Window:全局窗口
将所有具有相同Key的元素分配到同一个全局窗口中,该窗口模式仅适用于用户还需自定义触发器的情况。
- Watermark:水位
流处理从事件产生,到最终输出计算结果,中间有一个过程和时间,大部分情况下,流数据都是按照事件产生的时间顺序来的,但不排除由于网络、背压等原因,导致数据乱序或延迟到达,对于延迟数据,又不能无限期的等下去,必须有个机制来保证一个特定的时间后,触发window去进行计算,这个机制就是Watermark。
Watermark是数据本身的一个隐藏属性,通常基于Event Time的数据,自身都包含一个Timestamp,比如1320981071111(2011-11-11 11:11:11.111),则这条数据的Watermark时间可能是:
Watermark(1320981071111)= 1320981068111(2011-11-11 11:11:08.111)
即Timestamp小于1320981068111(2011-11-11 11:11:08.111)的数据,都已经到达了,可以对窗口内数据进行计算了。
三、特来电监控引擎
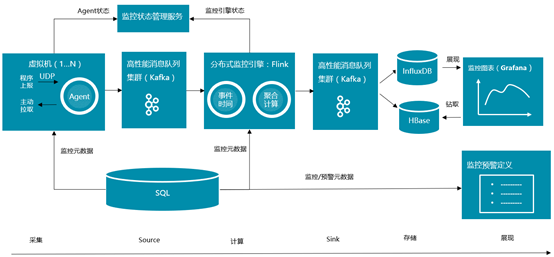
上图是特来电监控平台整体架构图,和一般的大数据分析处理流程类似,主要由以下几部分组成:
- 数据采集
由部署在各个机器上的监控Agent组成,职责是收集监控数据。收集方式既支持业务通过程序埋点方式主动上报数据,也支持通过监控插件方式,由监控Agent定时主动拉取数据(如性能计数器数据、Windows日志数据、网络端口连通性数据、Kafka运行数据、RabbitMQ运行数据、Redis运行数据、关系数据库运行数据、大数据组件运行数据等)。
- 数据输入缓存(Source)
基于开源的Kafka缓存监控上报的数据,Kafka是流计算的标配,可以说“无Kafka,不流计算”,Kafka最近刚发布了1.0版本,无论是稳定性,还是性能方面,Kafka都是不可替代的消息队列技术栈。
- 数据计算
监控引擎是监控平台的核心组件,主要做两件事:一是一定要基于监控数据的Event Time进行计算,并能处理乱序数据以及延迟到达数据;二是要对监控数据做各种维度的聚合计算。利用Flink,基于Event Time进行聚合计算,计算时间可以控制在秒级,是计算密集型场景。
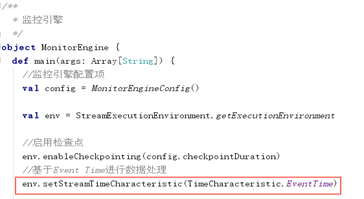
如上所示,使用Flink进行计算时,可以很容易设置计算数据的时间类型,针对监控数据,必须用Event Time,才能保证指定时间的数据都落在同一个窗口。
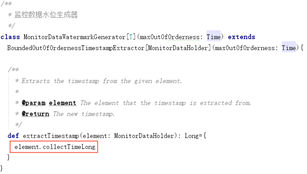
为了应对数据乱序以及延迟,还需要设置水位,因为每个监控数据自身都携带了数据产生的时间戳,所以设置起来也很自然:
监控引擎核心功能在做各种维度的聚合计算,如下所示,如果一分钟内上报的监控数据如下所示:

则进行维度计算时,主要有如下四种维度计算方式,分别计算出相应维度数据的最大值、最小值、平均值、最后值、求和值以及数据个数:
a) 全部数据维度

将所有数据进行累加求值
b) 指定集群维度

将所有数据按不同集群进行累加求值
c) 指定应用节点维度

将所有数据按不同节点进行累加求值
d) 自定义维度

前面三种维度相当于固定维度,监控数据还支持用户自定义维度,如果上报数据有自定义的维度,则将自定义维度Key以及Value取出后进行flatMap,和前面三种固定维度进行并列计算。
基于Flink进行聚合计算时,需要先根据监控元数据进行分组,然后计算指定时间窗口内的数据,如下所示:

监控引擎运行时,可以通过Flink的Job Graph,实时查看每个Operator的执行链,如下所示:
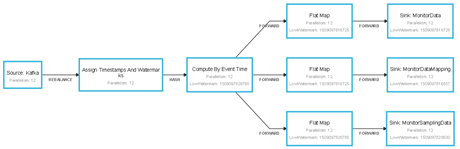
- 数据输出缓存(Sink)
监控数据进行聚合计算完毕后,不是立即持久化到存储,还是先Sink到Kafka,一是让监控引擎工作更纯粹,面对的Source和Sink都是Kafka;二是通过Kafka对数据落盘进行缓冲,减少直接写存储可能带来的监控引擎阻塞,让流计算更流畅,降低背压的产生概率。
- 数据存储
特来电监控平台和其他互联网监控平台最大的不同,也是特来电监控平台最大亮点,是支持从计算后的聚合数据,钻取联查到监控Agent上报的原始数据,这要求既要存储计算后的聚合数据,也要存储原始数据,还要存储聚合数据与原始数据的关联关系。因为监控数据最大的特点是时间相关性的,因此使用时间序列数据库InfluxDB存储计算后的聚合数据,使用HBase存储原始数据以及原始数据与聚合数据的关联关系。
- 数据展现
监控数据最终通过Grafana进行展现,可以实时监控云平台系统层面以及业务层面的运行状态,为故障检测、诊断及定位打下了坚实基础。如前所述,通过Grafana不仅可以查看存储在InfluxDB中计算完毕的聚合数据,还可以通过Grafana钻取功能,联查到存在HBase中的原始数据。
四、技术不止、坑坑不息
技术研究、探索以及应用,总是会伴随着很多坑,踩坑填坑的过程,就是技术积累的过程,技术人要感谢这些坑,因为它们加深了对技术的认识。
1. 时间戳与Decimal
由于监控Agent是基于C#开发的,监控引擎是基于Scala开发的,DateTime作为C#中内置的数据类型,在Scala中没有可直接对应的数据类型。考虑到监控Agent上报到Kafka中的数据是Protobuf格式,因此需要根据C#中DateTime对应的.proto文件,生成对应的Java代码,然后在Scala中反序列化时,调用Protobuf时间类,转换成可识别的时间戳。
另一个在跨语言时没有直接对应的数据类型是C#中的Decimal,处理方式和DateTime类似,也是需要定义中间转换的.proto文件,生成对应语言的类,反序列化时进行调用处理即可。
【注】在处理Protobuf类时,专业的做法是只定义.proto文件,使用gRPC插件动态生成对应的Java类。
2. 从Spark Streaming到Flink
特来电监控引擎的前一版本是基于Spark Streaming实现的,但是在解决乱序数据及延迟到达数据时,遇到了很大的技术障碍,因为Spark Streaming是根据Processing Time进行计算的,如果要基于Event Time进行计算,技术实现难度很大,先后尝试过Alluxio、Ignite、Structured Streaming,都没能很好解决该问题。直到尝试使用Flink,发现这是其内置特性,可以轻松解决以前遇到的问题,后面便果断放弃Spark Streaming,坚定选择Flink作为监控引擎的实现工具。
3. 其他经常会遇到的坑还有:应用程序使用的jar包,比Flink自身提供的jar包新,可以通过maven-shade-plugin进行打包;查看Flink的Job Graph时,需要使用Chrome浏览器,微软的IE浏览器没法显示完整执行链;Map作为Protobuf中的特殊集合,不能被Flink直接序列化,需要自定义序列化类或者将类封装后,实现Serializable Trait;Checkponit时间不要设置的太短,否则会导致频繁创建快照;生产环境不要把执行链断开,否则会有一些性能问题等等。
五、All In Flink
笔者认为,“老当益壮”的Flink作为“新一代”冉冉升起的真正流计算引擎,将会长期与Spark并驾齐驱,并逐步扩大其应用范围。我们也会将其逐步应用到实时预警、实时全链路分析、风控管理、用户行为分析,并逐步探索基于Flink的机器学习、监控数据突变分析,希望能在监控预警方面取得进一步突破,为云平台的稳定运行保驾护航。
六、特来电云计算与大数据微信公众号
1.微信公众号名称:特来电云计算与大数据
2.二维码:


