

数论基础原理总结
UPD:2018.4.25 更新了快速求原根的啰嗦的证明
一、整除的性质
1,如果a|b,且b|c,则a|c
2,a|b且b|c,那么a|c
3,设m!=0,那么a|b等价于(m*a)|(m*b)
4,设整数x和y满足下式,a*x+b*y=1,且a|n,b|n,那么(a*b)|n
根据性质3可得,(a*b)|(n*b),(a*b)|(n*a),
根据性质4可得,(a*b)|x*(n*a)+y*(n*b)
化简上式,(a*b)|n*(a*x+b*y)=>(a*b)|n*(1),证毕
5,若b=q*d+c,那么d|b的充要条件是d|c
其他
约定0可以被任何数整除
若2能整除a的最末位,则2|a
若4能整除a的后两位,则4|a
若8能整除a的后三位,则8|a.以此类推不再赘述
若3能整除a的各位数字之和,则3|a
若9能整除a的各位数字之和,则9|a
若11能整除a的偶数位数字之和与奇数位数字之和的差,则11|a
同时能被7,11,13整除的数的特征是,这个数的末三位与末三位以前的数字所组成的数能被7,11,13整除,则这个数就能被7,11,13整除
显然成立容易忽略的细节?
若a|b,则a是b的一个因子,
若a|b,则a<=b
二、GCD
GCD据我的理解可以形象化的理解为,数字的最长公共子结构
所以不仅仅是两个数之间的
一堆数的GCD,显然可以先从某两个数的GCD开始,因为答案必定比这个还要小
一堆定序数的GCD有一个性质那就是非严格单调递减,某一段的GCD可能不变,但是其终归是递减
这里有一个偏哲学的解释,人越多则人们的共性就越少,共性越少则最大共性也越少
GCD正确性的证明需要知道几点
若a|b则a<=b
另外一个是显然但容易忽略的事实,a<=b,b<=a,显然当且仅当a=b时成立
对于a=q*d+r,q|a当且仅当q|r
正确性的证明:
辗转相除法的正确性可以分成两步来证明。
在第一步,我们会证明算法的最终结果rN−1同时整除a和b。因为它是一个公约数,所以必然小于或者等于最大公约数g。
在第二步,我们证明g能整除rN−1。所以g一定小于或等于rN−1。两个不等式只在rN−1 = g是同时成立。具体证明如下:
- 证明rN−1同时整除a和b:
- 因为余数rN是0,rN−1能够整除rN−2:
- rN−2 = qN rN−1
- 因为rN−1能够整除rN−2,所以也能够整除rN−3:
- rN−3 = qN−1 rN−2 + rN−1
- 同理可证rN−1可以整除所有之前步骤的余数,包括a和b,即rN−1是a和b的公约数,rN−1 ≤ g。
- 因为余数rN是0,rN−1能够整除rN−2:
- 证明最大公约数g能整除rN-1:
- 根据定义,a和b可以写成g的倍数:a = mg、b = ng,其中m和n是自然数。因为r0 = a − q0b = mg − q0ng = (m − q0n)g,所以g整除r0。同理可证g整除每个余数r1, r2, ..., rN-1。因为最大公约数g整除rN−1,因而g ≤ rN−1。
因为第一步的证明告诉我们rN−1 ≤ g,所以g = rN−1。即:
- g = GCD(a, b) = GCD(b, r0) = GCD(r0, r1) = … = GCD(rN−2, rN−1) = rN−1
- GCD还有一个性质那就是 a*b=GCD(a,b)*LCM(a,b)
- LCM的意思就是最小公倍数
- GCD还有一个显然但容易忽略的事实,GCD(a,b)=GCD(b,a)
- 但是对于我们后面讲的EXGCD来讲,EXGCD(a,b,x,y)=EXGCD(b,a,x,y)虽然其结果一致
- 但是x,y的值却交换了,因为x与第一个参数对应,而y则与第二个参数对应
- 如果y<x,则GCD(x,y)<x,如果我们设了x为最小正整数则得出一个矛盾
- 最小正整数有一个显然的性质,它>0并且所处集合应当是良序的
- 显然>0意味着不等于0
- 一个显然但是容易忽略的事实是a*(-b)+(-b)*a=0
- 也可以写成a*(x0-b)-b*(y0+a)=a*x0+b*y0
- 在了解EXGCD之前我们需要先了解一个基本的事实
-
整数中的裴蜀定理
对于任意两个整数,a,b,设d是他们的最大公约数
裴蜀等式有解时必然有无穷多个解。
通常谈到最大公约数时,我们都会提到这个非常基本的事实:给予二整数a、b,必存在有整数x、y使得ax + by = gcd(a,b)

理解要点

因为r也是A中的元素,且r>=0&&r<d0,如果r>0则说明存在比d0还小的“正”元素,这与假设矛盾
因此r只能取<=0的整数,r可以取0
理解要点2

首先我们知道ax0+by0=d0
而且我们知道d0能整除a,b
那么a*(x0+kb/d0)+b*(y0-ka/d0)=d0
然后我们显然可以得到
a*(m0x0+m0kb/d0)+b*(m0y0-m0ka/d0)=m0d0
后面我好像不太会了,但是我们知道m0x0+kb,m0y0-ka由于k是整数,所以比起上面那个形式
会漏解。。但是由于整数集是无穷数级,所以即使漏解它仍然有无穷多解(它真的会漏解吗,至少现在我看来会的)
(更新补充:
但是我们会看到上面的证明中,标准的通解(也许叫这个名字吧)形式是,m0x0+kb/d,m0y0-ka/d
这里我又发现了一个坑。。那就是我写的是d0,但是他这里是d,我的d0就是A集合中最小的正整数,也就是gcd(a,b)
但是他这里是d...
奥我发现。。他上面说了。。这个d的意思就是a,b的任意正公约数,那么d就能整除a和b了
并且d0是最大公约数,那么d<=d0,那么b/d>=b/d0,那么对于同一个整数k,kb/d>=kb/d0
======================================================
但是这里我真正想说的是,由于(d表示任意公约数)kb/d,ka/d,最后互相乘以一个系数被约掉。。所以我们并不关心这个系数是多少
这里t*b/d0一定能转化到k*b/d为什么呢,
因为,,d=z*d0..,t*b/d0和k*b/z*d0,我们必定有办法将1/z消去,然后规约到t的情况里。。所以我认为(t为任意整数)t*b/d0就能代表所有解
奥这下我又知道了。。因为任意正约数d的情况是包含d0的啊!MDZZ)
那么其实我们通过这个基本事实的证明得到了合理的解释
二、EXGCD
EXGCD其实是基于对以上事实的观察以及对GCD迭代求解过程的观察
其实我们知道GCD基于一个事实,假设第一个参数小于第二个参数GCD(a,b)=GCD(a,b-a)
(此处不妨设a<b,如果a>b那么GCD(b%a,a)=GCD(b,a)则仅仅相当于交换了a,b的位置)
但是我们知道通常我们写的GCD第一个参数总是大于第二个参数,这也是不同于平常的另外一种写法
这里有一个显然的事实a%b<b
我们知道GCD的每一步迭代都对应着一个带余除法式子
因为我们要知道余数是多少,因为我们知道一旦求出了余数我们为了保证参数顺序就要交换
继续用大数减去小数,所以GCD的所有迭代的过程都对应着带余除法式子,
这就是我们要写一堆求余数式子的原因,这样才能找到最大公约数和最初的参数有什么关系
数学推导可以有两种一种是从前往后,另外一种是从后往前,首先我们要写出来最基本的一堆求余数式子
(b<a)
a=q1*b+r1(r1<b)
b=q2*r1+r2(r2<r1)
r1=q3*r2+r3(r3<r2)
r2=q4*r3+r4(r4<r3)
r3=q5*r4+r5(设r5=0,r5<r4)
r4=q6*r5+r6(因为r5=0,所以r6=r4)这里返回GCD的答案r4,算法终止
那么都说那这些式子回带就可以得解
怎么回带呢,其中一种错误的回带是a-q1*b=r1
把r1回带,我们看看有没有办法算出r1和最大公约数g的关系反解g,此处的g就是r4
(Tip:化简式子时要观察式子的结构,一个简单的想法是观察目标式子中的元素然后将多余的元素反解成目标式子中的元素)
r2=q4*(q5*r4)+r4=(1+q4*q5)*r4
r1=q3*(1+q4*q5)*r4+(q5*r4)=(q3+q3*q4*q5+q5)*r4
a-q1*b=(q3+q3*q4*q5+q5)*r4
此时我们令a=p1*r4,b=p2*r4,因为我们早已知道r4|a,b
p1*r4-q1*p2*r4=(q3+q3*q4*q5+q5)*r4
设存在x,y使得,x*p1*r4+y*p2*r4=r4
则r4*(x*p1+y*p2-1)=0
而式也能化解为,r4(p1*r4-q1*p2*r4-q3-q3*q4*q5-q5)=0
证明到这里我们必须要找到(q3+q3*q4*q5+q5+1)分解成a和b的分量
由于都是商数所以,这令我感到证明困难,这种证明的主要困难是选择了a的系数固定为一,需要找到a的其他分解
这个先放在这里。。闲的时候可以强行刚一波
(b<a)gcd(a,b)
a=q1*b+r1(r1<b) gcd(b,r1)
b=q2*r1+r2(r2<r1) gcd(r1,r2)
r1=q3*r2+r3(r3<r2)gcd(r2,r3)
r2=q4*r3+r4(r4<r3)gcd(r3,r4)==>
r3=q5*r4+r5(设r5=0,r5<r4)gcd(r4,r5) r5==0 return r4 ==>1*r4+0*r5=gcd(r4,r5)=r4
r4=q6*r5+r6(因为r5=0,所以r6=r4)这里返回GCD的答案r4,算法终止
对于这堆式子。。我们可以将r4的系数固定为1,然后从下往上迭代
首先我们将余数全部挪到左边
r1=a-q1*b
r2=b-q1*r1
r3=r1-q3*r2
r4=r2-q4*r3
r5=r3-q5*r4
r6=r4-q6*r5
因为我们总能迭代到r1,所以r4总能表示成(a-q1*b)的线性组合,也就是a,b的线性组合
下面开始实际证明
r4=r2-q4*(r1-q3*r2)=(1+q4*q3)r2-q4*r1(带入r3)
r4=(1+q4*q3)*(b-q1*r1)-q4*r1=(1+q4*q3)*b-r1(q1+q1*q4*q3+q4)(带入r2)
r4=(1+q4*q3)*b-(a-q1*b)(q1+q1*q4*q3+q4)(带入r1)
r4=(1+q4*q3-q1*q1-q1*q1*q4*q3-q4*q1)b-a*(q1+q1*q4*q3+q4)
r4=p1*b-p2*a=xa+yb
然后我们也可以先把r2带入r1,依次,最后r4里面把r2和r3带入
这个证明的核心就是发现了一个事实,比r1小的余数都能表示成r1的线性组合,而比r1小的余数里面
必定有一个余数是最大公约数,最大公约数也可表示成r1的线性组合,而r1又是a,b的线性组合,所以最大公约数也是a,b的线性组合
并且我们知道一旦知道了每一步的商和余数我们就能算出最终最大公约数中a,b的某一个线性组合
但是我们的程序应该怎么写呢。。
由于这是一个递归的过程,如果我们要采用回溯迭代而不是递归生成目标多项式也就是从上往下一步带入
所以我们要知道前一步和后一步存在什么关系,首先我们求的是一个a,b的系数,那么我们通过上述步骤回带,
我们知道GCD(a,b)=GCD(b,a%b),于是我们根据上面讲的性质之一就可以发现
存在事实,ax1+by1=bx2+(a%b)y2
在下取整乘法里我们可以写成,ax1+by1=bx2+(a-b*a/b)y2
要想得到x1,x2,y1,y2的关系一个简单的想法,两边都整理成a*p1+b*q1=a*p2+b*q2
所以这里有一个显然但是容易忽略的事实,a*p1+b*q1=a*p2+b*q2
的一组解必定有,p1=p2,q1=q2
但是别忘了,p1!=p2,q1!=q2的情况,此时设k1,k2为整数集合中的数
则p2=p1+k1,q2=q1+k2,则a*p1+b*q1=a*(p1+k1)+b*(q1+k2)
整理可得ak1+bk2=0,我们可以得出k1=b/d0,k2=-a/d0,如果d0|a,b
可以知道d0一定存在,因为可以取0,1等等值
根据其中一组解的思路,两边整理成同样形式的
ax1+by1=ay2+b(x2-a/b*y2)
则x1=y2,y1=(x2-a/b*y2),所以其实我们按照这个式子回带答案就行,因为我们知道递归的最后一步一定有解
代码实现有一点,当前x的值是x2,y的值是y2,仍然用x存x1则x=y=y2;但是y=x-a/b*y就会变成y2-a/b*y2
因为x2被覆盖,所以呢,这里需要临时变量保存x2的值
然后令我困惑的是不断迭代的这个过程其实没有用到上面推导的结论我们只是
一味的迭代。。
当我们想要真正模拟迭代求解的过程时
在此之前还需要强调之前的性质那就是函数定义的参数顺序,定义gcd(a,b,x,y)可以顺便求出x*a+y*b=gcd(a,b)中x,y的一组特解
所以我们知道x对应于a,y对应于b,x,y并不满足交换的性质
这里参考上面的式子就行,假设的话,截断式子就可以
譬如设d是最大公约数,d=r3=r1-q3*r2,此时A=r1,B=r2,x1=1,y1=-q3
然后我们将r2带入,d=r1-q3*(b-q2r1)=(-q3)*b+(1+q2q3)r1,此时A=b,B=r1,x2=-q3=y1,y2=x1-y1*b/r1(实际上b/r1就是q2)
然后其实从这里我们就足以发现事实(其实不严谨,但是往后推导显然可以规约到这两步上面)。。那就是x2=y1,y2=x1-y1*b/r1,也就是说其实这个过程本质和上面的事实还是一样的
所以我们就不必顾虑这个过程和上面的事实没有联系。。他们只是从不同角度观察而已
所以反向带入和我们反解系数gcd(a,b)=gcd(b,a%b)其实是一样的啦!
用exgcd求逆元怎么求呢,求k*M=1(mod N)M<N,那么其实这个问题相当于k*M+p*N=1,而我们知道M,N互质则有,k*M+p*N=gcd(M,N)必定有解
所以利用exgcd即可求出满足等式的一个k,(其实exgcd还满足一个性质,那就是求出来的|k|+|p|是最小的,这个用归纳法容易正,因为每一步都是最小的
但是k可能会小于零,比如7,8会求得,7*-1+8=1,等式里没什么问题,但是我们求的是逆元,那个式子还可以写成,(7*-1)%8=1,也就是说只要在等式里找到了
一个k,那么这个k必定对应一个0~N-1大小的逆元,因为和(7*-1+p*8)%8=1是等价的,p是多大并不重要,模意义下跟没有一样,
其实和,(7*(p*8-1))%8=1一样,展开可得,-7+7*p*8=1(mod 8),那么我们可以让p=7p嘛。。那么就变成了上面的(7*-1+p*8)%8=1,这样就等价了
所以由于乘法逆元的意义,他就是一个0~N-1的数,假如k<0,则我们需要求p*8+k>0最小的数,那么我们可以先k%8,将大于8的部分的负数都搞掉
然后k是一个在0~N-1下的负数,此时我们再给他加上N就得到答案,但是对于正数,虽然加上N没影响,但是会大于N,所以我们最后在模一个N
那么这个逆元就会被表示成(k%n+n)%n,正负数通用
那么还有一个理解是,什么时候返回答案呢,那就是,右边的大的数,被左边%成了0,那么这不就说明左边才是最终的答案嘛,返回左边
也就是if(b==0) return a;这里约定右边比左边大
为什么普通线性同余方程x解的最小距离为b/gcd
往往我们需要求解的方程并不是a*x+b*y=gcd(a,b)而是更常规的a*x+b*y=n
然后可以通过对a*x+b*y=gcd(a,b)方程的求解,转化成为求二元一次不定方程a*x+b*y=n
若gcd(a,b)不能整除n,这个方程无整数解,反之,若解得a*x+b*y=gcd(a,b)的解为x0,y0,
则方程两边同乘n再除以gcd(a,b)得a*(n/gcd(a,b)*x0)+b*(n/gcd(a,b)*y0)=n
所以方程解为x=n/gcd(a,b)*x0,y=n/gcd(a,b)*y0。
更通常的是:我们需要求解方程的最小整数解
若我们已经求得x0,y0为方程中x的一组特解,那么
x=x0+b/gcd(a,b)*t,y=y0-a/gcd(a,b)*t(t为任意整数)也为方程的解
且b/gcd(a,b),a/gcd(a,b)分别为x,y的解的最小间距,所以x在0~b/gcd(a,b)区间有且仅有一个解,
同理y在0~a/gcd(a,b)同样有且仅有一个解,这个解即为我们所需求的最小正整数解。
为什么b/gcd(a,b),a/gcd(a,b)分别为x,y的解的最小间距?
解:假设c为x的解的最小间距,此时d为y的解的间距,所以x=x0+c*t,y=y0-d*t(x0,y0为一组特解,t为任意整数)
带入方程得:a*x0+a*c*t+b*y0-b*d*t=n,因为a*x0+b*y0=n,所以a*c*t-b*d*t=0,t不等于0时,a*c=b*d
因为a,b,c,d都为正整数,所以用最小的c,d,使得等式成立,ac,bd就应该等于a,b的最小公倍数a*b/gcd(a,b),
所以c=b/gcd(a,b),d就等于a/gcd(a,b)。
所以,若最后所求解要求x为最小整数,那么x=(x0%(b/gcd(a,b))+b/gcd(a,b))%(b/gcd(a,b))即为x的最小整数解。
x0%(b/gcd(a,b))使解落到区间-b/gcd(a,b)~b/gcd(a,b),再加上b/gcd(a,b)使解在区间0~2*b/gcd(a,b),
再模上b/gcd(a,b),则得到最小整数解(注意b/gcd(a,b)为解的最小距离,重要)
摘自:http://blog.csdn.net/non_cease/article/details/7364092
三、同余理论
若a,b为两个整数,且它们的差a-b能被某个自然数m所整除,则称a就模m来说同余于b,或者说a和b关于模m同余
记为a=b(mod m)(同余符号懒得弄了,暂时就拿等号代替)
它意味着,a-b=m*k(k为某一个整数),例如32=2(mod5) k=6
还有一种理解同余的说法,那就是两个数把多余的部分(大于模数的部分)砍掉,剩下的数值一样,那么我们就说这两个数同余
对于整数a,b,c和自然数m,n, 对模m同余具有以下一些性质
1,自反性,a=a(mod m)
2,对称性,若a=b(mod m) 则 b=a(mod m)
3,传递性,若a=b(mod m),b=c(mod m),则a=c(mod m)
4,同加性,若a=b(mod m),则a+c=b+c(mod m)
5,同乘性,若a=b(mod m),则a*c=b*c(mod m)
若a=b(mod m) c=d(mod m) 则 a*c=b*d(mod m)
6,同幂性,若a=b(mod m),则an=bn(mod m)
7,推论1,a*b mod k=(a mod k)*(b mod k) mod k
8,推论2,若a mod p=x, a mod q=x,p、q互质,则a mod p*q=x
证明,p,q互质则一定 存在整数s,t使得 a=sp+x,a=tq+x
那么显然我们可以得到,sp=tq,因为p,q互质,所以一定存在s=kq
所以a=(kq)p+x=kqp+x,因此 a=x(mod p*q)
但是同余不满足同除性,即不满足a div n = b div n (mod m)
我们知道如果div n是逆元的话,设L=inv(n,m),则a*L=b*L(mod m)是满足同乘性质
但是此处却说不满足,可见并不是逆元乘法当除法?
所以这里是一个有疑惑的地方
关于同余这里有一个快速的指数取余的算法那就是快速幂,快速幂基于两个事实,我们可以在log的时间把一个数分解成2进制
ab=ab0*ab1....*abn,然后我们知道b0到bn的和就是b,但是我们不必求出具体数值
例如11011=1+10+1000+1000,我们能在对数时间内求得,a,a*a,a*a*a*a,我们知道
对于二进制的偶数次幂,我们可以直接利用结果,奇数次幂可以用a*偶数次幂,也就是基于偶数加一等于奇数这一基本事实
所以我们可以组装成任意的幂次,注意特判b=0的情况
求解线性同余方程
定理1:对于方程a*x+b*y=c,该方程等价于a*x=c(mod b),有整数解的充分必要条件是:c%GCD(a,b)=0
根据定理1,对于方程a*x+b*y=c,我们可以先用扩展欧几里得算法(EXGCD)求出一组x0,y0,
也就是ax0+by0=GCD(a,b),然后两边同时除以GCD(a,b),再乘以c
这样就得到了,a/GCD(a,b)*c*x0+b/GCD(a,b)*c*y0=c,我们也就找到了方程的一个解
定理2:若GCD(a,b)=1,且x0,y0为a*x+b*y=c的一组解,
则该方程的任一解可表示为,x=x0+b*t,y=y0-at
这里有一个显然但容易忽略的事实,GCD(a/GCD(a,b),b/GCD(a,b))=1,即两个数都除以GCD,则运算后的结果互质
而且我们也可以这么想,ax0+by0=GCD(a,b),同除以GCD(a,b),a/GCD(a,b)*x0+b/GCD(a,b)*y0=1,
我们知道它的解一定存在,那么根据上述的某一条性质我们可以得出结论,a/GCD(a,b)与b/GCD(a,b)互质
并且我们知道GCD(a,b),的含义在这里是能够整除a,b的最大约数,如果约数比GCD(a,b)还大,那么a,b至少有一方不能被此约数整除
所以根据定理2,考虑方程a*x+b*y=c=>a/GCD(a,b)*x+b/GCD(a,b)*y=c/GCD(a,b)
于是我们可以得到方程,A*x+B*y=C,GCD(A,B)=1,于是我们可以得到(x0,y0是ax+by=c的一组解)
x=x0+B*k,y=y0-A*k,(A=a/GCD(a,b),B=b/GCD(a,b)),所以这里我们就求得了a*x+b*y=c的所有解
我们在求出特解x0,y0时,向所有解推广时,运用了上面一个显然的事实
a*(-b)-b*(a)=0,那么我们知道当你获得了ax0+by0=c,你可以写成a(x0+bk)+b(y0-ak)=c
但是这里k取整数则会漏解,因为我们知道要想这个式子成立,x0需要加上一个b为分子,能整除a,b的的数作为分母
y0需要减去一个a为分子,能整除a,b的数作为分母,(这两个分母当然取一样的)这样才能满足等式
但是我们知道能整除a,b的数非常多,but 我们知道了能同时整除a,b最大的数,我们取这个数作分母
k取任意整数就能获得所有解,你担心漏掉a,b其他公共约数作为分母的情况的解?不存在的,因为k是任意的
k能枚举所有其他公约数为分母比(例如b/GCD(a,b))大的部分的所有因子的情况,所以这有点类似于基元的思想
所以我们来推一下这个解最终的形式应该是怎么样的,要求ax+by=c的解
我们只能先求出ax+by=GCD(a,b)的解,设这组解为x0,y0
给这组解同乘以c/GCD(a,b),这样我们就得到了ax+by的一组解,X0=x0*c/GCD(a,b),Y0=y0*c/GCD(a,b)
然后我们知道通解X=X0+B*k,Y=Y0-A*k,带入X0,Y0,A,B,(A=a/GCD(a,b),B=b/GCD(a,b))
X=x0*c/GCD(a,b)+b/GCD(a,b)*k,Y=y0*c/GCD(a,b)-a/GCD(a,b)*k,其中k可以取任意整数
但在实际问题中,我们往往被要求去求最小整数解,也就是一个特解,
X=(X%B+B)%B,Y=(Y%A+A)%A,
所以就是X1=(X0%B+B)%B, Y1=(Y0%A+A)%A
那么为什么这样就能求出最小整数解呢
因为所有解的形式后面都带B*k,或者A*k,我们把这些都%掉
就剩下最小的X0,Y0,然后我们知道%剩下的这些一定小于B或A(取模运算)
那么如果此时(c语言%运算)%的结果小于零,但是它的绝对值的结果一定小于B或A
此时我们再给他加上B或A,所以我们求出的是最小非负整数解
因为这个解有可能是零
逆元
若a*x=1(mod b) ,a,b互质,则称x为a的逆元,记为a-1
根据逆元的定义,可转化为a*x+b*y=1,我们知道如果a,b互质,那么GCD(a,b)=1
那么我们只需跑一趟EXGCD就能算出来a的逆元是多少
求逆元还有一个线性算法,具体过程如下
首先1-1=1(mod p)
然后我们设p=k*i+r,是p/i的带余除法,令i>1&&i<p,令p是质数,那么所有i都与p互质,都互质那么就都存在逆元
然后我们显然可以知道r<i,这意味着r也是存在逆元的,再将这个式子放到mod p的意义下
k*i+r=0(mod p)
在两边同时乘上i-1,r-1就会得到
k*r-1+i-1=0(mod p)
i-1=-k*r-1(mod p)
i-1=-(p/i)*(p%i)-1(mod p)
因为我们不想得出一个小于零的结果,我们知道
p-(p/i)=p/i(mod p) 所以作替换
i-1=(p-(p/i))*(p%i)-1(mod p)
这就是线性求逆元的递推式子了
实际上这也提供了一种O(logn)底数为2,
的时间内求出单个数逆元的方法,只要直接按照那个公式递归就可以了。可以证明p mod i<i/2
每次递归问题规模减半,最终只会有O(logn)次递归,GCD貌似只需要位数乘5的复杂度,这个要比GCD快一个常数
我突然想到了GCD和线性差分方程,然而线性差分方程又和斐波那契数列有关(斐波那契数列是线性差分方程的一种特殊形式)
GCD为什么和线性差分方程有关呢
比如说这种形式
r1=a-q1*b
r2=b-q1*r1
r3=r1-q3*r2
r4=r2-q4*r3
r5=r3-q5*r4
r6=r4-q6*r5
这不就是典型的差分形式么
整数的唯一分解定理
任意正整数都有且只有一种方式写出其素因子的乘积表达式
A=(p1^k1)*(p2^k2)*(p3^k3)....*(pn^kn),其中pi为素数
这里有一个显然但是容易忽略的事实
那就是A和A/(pi^ki)互质
约数和公式
对于已经分解的整数,A=(p1^k1)*(p2^k2)*(p3^k3)....*(pn^kn)
有A的所有因子之和为
S=(1+p1^1+p1^2+...+p1^k1)*(1+p2^1+p2^2+...p2^k2)*(1+p3^1+p3^2+...+p3^k3)*...(1+pn^1+pn^2+...pn^kn)
这个很好理解,因为A的所有因数必然是A中所有素因子及其幂次的组合(与顺序无关所有和排列没有关系)
同余模公式
(a+b)%m=(a%m+b%m)%m
(a*b)%m=(a%m+b%m)%m
这个非常好理解,因为如果a=km+r,则你先%m对答案无影响
如果k=0,也是没有影响的
素因子分解
不断对A的素因子取模,只要A%pi==0,则cnt[pi]++,A/=pi,当A%pi!=0时我们分解pi+1
但是我们需要对A本身就是一个素数进行特判
求A^B的所有约数之和
sum=(1+p1^1+p1^2+...+p1^(k1*B))*(1+p2^1+p2^2+...+p2^(k2*B))*...*(1+pn^1+pn^2+...+pn(kn*B))
对于每一个pi我们需要
递归二分求等比数列1+pi+pi^2+...+pi^n
本质就是我们提出来一个因子使得问题的规模缩小一半
n分奇偶来讨论,如果n是奇数则一共有偶数项比如说n=7
下取整除法
pi^0 pi^4
pi^1 pi^5
pi^2 pi^6
pi^3 pi^7
所以我们就发现了pi^(7/2+1)+...+pi^7=(1+pi^1+...+pi^(7/2))*(pi^(7/2+1))
然后1+pi^1+pi^2+...+pi^7=(1+pi^1+...+pi^(7/2))+(1+pi^1+...+pi^(7/2))*(pi^(7/2+1))=(1+pi^1+...+pi^(7/2))*(1+pi^(7/2+1))
其实我们发现如果n是奇数。。则都是满足这个规律的
如果n是偶数,比如说n=8
pi^0 pi^5
pi^1 pi^6
pi^2 pi^7
pi^3 pi^8
但是我们发现少了pi^4,所以偶数情况的形式应该是(1+pi^1+pi^2+...+pi^(n/2-1))*(1+pi^(n/2+1))+pi^(n/2)
奇数情况的形式应该是(1+pi^1+pi^2+...+pi^(n/2))*(1+pi^(n/2+1))
所以这样我们就能递归求解等比数列和了
中国剩余定理 CRT
设自然数m1,m2,...,mr两两互素,并记N=m1*m2*...*mr,则同余方程组
x=b1(mod m1)
x=b2(mod m2)
...
x=br(mod mr)
在模N同余的意义下有唯一解
仅仅是这个结论,它并不显然,但是只要我们能构造出解,就证明了这个结论
证明:
考虑方程组
(i>=1&&i<=r)
x=0 (mod m1)
...
x=0(mod mi-1)
x=1(mod mi)
x=0(mod mi+1)
...
...
x=0(mod mr)
由于诸mi两两互素,这个方程组作变量替换,令x=(N/mi)*y
方程组等价于解同余方程,(N/mi)*yi=1(mod mi),我们知道GCD(N/mi,mi)=1
所以yi一定有解,则xi=(N/mi)yi
则方程组的解为X=x1*b1+x2*b2+...+xr*br(mod N)
答案超过N怎么办。。我们边算边模就行了
斐波那契数列,常系数差分方程,待定系数法求通解
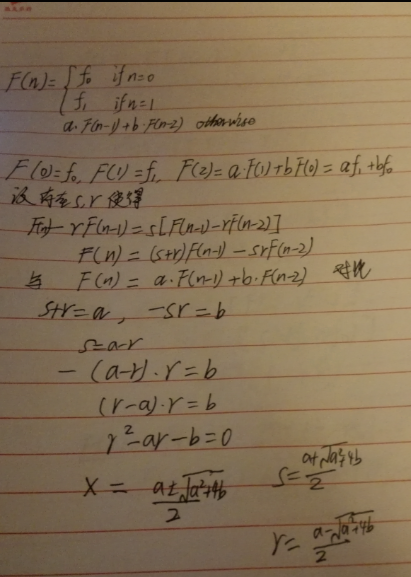


所以最终答案就是s^n(f1-rf0)+r^n(sf0-f1)/(s-r)
这是这种方程的通解,然后对于项数很大的常系数差分方程,我们可以利用矩阵快速幂
[F(n-1),F(n-2)]*(a 1)=[a*F(n-1)+b*F(n-2),F(n-1)]=[F(n),F(n-1)]
(b 0)
然后依次类推就行了,就能一直算出后面的项
卡特兰数
求卡特兰数列的第n项,可以用如下几个公式
1.递归公式1

2.递归公式2
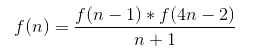
3.组合公式1

4.组合公式2
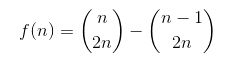
素数理论
素数的判定
在数据范围比较小的情况下,我们可以sqrt(N)判断一个数是不是素数,如果数据规模是S则总共需要S*sqrt(S)才能判别所有数,非常慢
它的原理就是考虑所有<=sqrt(N)的N的约数,为什么不考虑>sqrt(N)的约数?因为如果一个约数大于sqrt(N)那么另外一个约数必定小于sqrt(N)
对于数据范围较大的情况,我们需要素数筛法
一个经典的素数筛法是这样的,
先将2~N(1不是素数不考虑)之间所有数写在纸上,
在2的上面画圈,然后划去2的其他倍数,第一个既没有画圈也没被划去的数是3
在3的上面画圈,然后划去3的其他倍数
重复上面这个过程,知道<=N的所有数都被考虑过画圈还是被划去
i是过程中第一个既没有画圈也没被划去的数
其中我们在枚举i的倍数时,只需从i*i开始筛,因为k*i(k<i)的情况已经被考虑过
从上述算法我们可以发现事实
该算法会造成重复筛除合数,
30=2*15=5*6 所以说30会被重复筛除
所以这里有了一个线性的筛法
首先,明确一个条件,任何合数都能表示成一系列素数的乘积
考虑i是否是质数
1.如果i是素数的话,那简单,一个大的素数i乘以不大于i的素数,这样筛除的数跟之前的是不会重复的
2.如果i是合数,此时i可以表示成递增素数相乘i=p1*p2*p3*...*pn,pi都是素数
(i>=2&&i<=n),pi<=pj(i<=j),p1是最小的系数
这种筛法的关键就在于,当我们判断p1==prime[j]的时候,不再进行筛除,开始下一轮
什么时候判断p1==prime[j]呢,由于prime数组单调递增(从小往大筛除顺序决定的)
所以当i第一次碰到,i%prime[j]==0,就说明了p1==prime[j],因为prime[j]是i最小的质因数
可以直观地举个例子,当i=2*3*5,我们可以筛去2*i,但是没有必要筛除3*i
如果i'=3*3*5,由于i'%2!=0,所以2*i'一定被筛去,但是3*i==2*i',即可以表示成一个更大的合数和一个更小的质数的乘积
这个终止条件我们还可以这么看待,i%prime[j]==0
i=k*prime[j]
此时不终止算法我们将筛,i*prime[j+1],而prime[j+1]>prime[j]
i*prime[j+1]=k*prime[j]*prime[j+1]=(乘法交换律)k*prime[j+1]*prime[j]
我们看到k*prime[j+1]是比i大的合数,prime[j]是比prime[j+1]小的质数
所以仍然是避免了下一个筛除的数可以表示成一个更大的合数和更小的质数的乘积
而且我们知道这个算法的核心就在于
每个数我们只用他最小的质因子去筛除
还有两个结论可以证明
1.一个数不会被重复筛除
2.合数肯定会被筛除
为什么一个数不会被重复筛除呢。。还是基于前面对数字的唯一表示法的限定
我说的这个唯一表示法是什么呢,就是我们知道一个数可以被分解成唯一素因子的幂次的乘积的形式
但是如果这么多散开的因子(2^3散开就是2*2*2),不按照固定的规则排列,那么显然有n!的排列方式(这里只是粗略地算了一下,实际应该是可重集合排列
所以这样不行,我们把它所有素因子全部排序。。那么他就可以表示成i*a,i是它最小的素因子,a当然不用管啦,我们把它内部看成有序的不就好了吗
当然a的最小素因子是大于等于i的,
所以在筛2*3*5时,为什么不筛素因子3,5呢,筛3的话会筛掉3*2*3*5,然而这和排序后的2*3*3*5是等价的,素数2可以轻易处理这种情况
筛5呢,5*2*3*5,然而和排序后的2*3*5*5等价,3*5*5遍历2时即可处理,当前处理则是不明知的重复劳动
内循环有一个细节,i*pr[j]<maxn,如果没有这个。。不仅会多跑。。而且可能会越界re
假设合数不能被筛除,则说明合数不能表示成最小质数i*a(最小质数大于等于i的数),这显然是不成立的。。但是我感到这是不严谨的,,后续再补
素数的相关定理
1.唯一分解定理
2.威尔逊定理
若p为素数,则(p-1)!=-1(mod p)(!是阶乘符号)
威尔逊定理的逆定理也成立
3.费马定理
若p为素数,a为正整数,且,a和p互质,则a^(p-1)=1(mod p)
证明:
首先,p-1个整数,a,2a,3a,...,(p-1)a 中没有一个是p的倍数(a与p互质)
其次,a,2a,3a,...,(p-1)a中没有任何两个同余于mod p
因为a=1(mod p) a*i=i(mod p) (i>=1&&i<p)(这个是错的)
因为没有任何一个数能表示成 ka=qp+r,其中q>=1
q只能等于0,所以每个(等会这个也是错的)
假设存在s1,s2(均小于等于p-1)使得,a*s1=a*s2(mod p),且s1!=s2,a与p互质
两边同乘以a的逆元可以得到
s1=s2(mod p),但是s1,s2都<=p-1&&>=1,s1一定等于s2,这与假设矛盾,因此不存在s1,s2
也就不存在
于是:a,2a,3a,...,(p-1)a,对mod p的同余既不为0,也没有两个同余相同,
由于s*a!=s(mod p),所以我们只有算一下才知道是多少
并且mod p的结果有p个0~p-1,但是没有0,所以就剩下p-1个,然而这p-1个结果还各不相同,
所以说这p-1个数对模p的同余结果一定是,1,2,3,...,p-1的某种排列
也就是,a*2a*3a*...*(p-1)a=1*2*3*...*(p-1)(mod p)
化简可以得到,a^(p-1)*(p-1)!=(p-1)!(mod p)
由于(p-1)!和p显然互质,所以(p-1)!的逆元一定存在
所以我们两边同时乘以(p-1)!的逆元,式子就变成了a^(p-1)=1(mod p)
其实这是一种特殊情况,一般情况下,若p为素数,则a^p=a(mod p)
这就是著名的费马小定理
Miller-Rabin素数测试
说Miller-Rabin测试以前先说两个比较高效的求a*b% n 和 ab %n 的函数,这里都是用到二进制思想,将b拆分成二进制,然后与a相加(相乘)
下面这个方法还有另外一个名字,俄罗斯乘法(雾)

// a * b % n
//例如: b = 1011101那么a * b mod n = (a * 1000000 mod n + a * 10000 mod n + a * 1000 mod n + a * 100 mod n + a * 1 mod n) mod n
ll mod_mul(ll a, ll b, ll n) {
ll res = 0;
while(b) {
if(b&1) res = (res + a) % n;
a = (a + a) % n;
b >>= 1;
}
return res;
}当相乘的两个数在long long 范围内的时候我们可以使用O(1)乘法
inline LL Multiply(LL x, LL y) { LL w = x * y - (LL)((double)x * y / p + 0.001) * p; if(w < 0) w += p; return w; }//a^b % n
//同理
ll mod_exp(ll a, ll b, ll n) {
ll res = 1;
while(b) {
if(b&1) res = mod_mul(res, a, n);
a = mod_mul(a, a, n);
b >>= 1;
}
return res;
}下面开始说Miller-Rabin测试:
费马小定理:对于素数p和任意整数a,有ap ≡ a(mod p)(同余)。反过来,满足ap ≡ a(mod p),p也几乎一定是素数。
伪素数:如果n是一个正整数,如果存在和n互素的正整数a满足 an-1 ≡ 1(mod n),我们说n是基于a的伪素数。如果一个数是伪素数,那么它几乎肯定是素数。
Miller-Rabin测试:不断选取不超过n-1的基b(s次),计算是否每次都有bn-1 ≡ 1(mod n),若每次都成立则n是素数,否则为合数。
伪代码:
Function Miller-Rabin (n : longint) :boolean;
begin
for i := 1 to s do
begin
a := random(n - 2) + 2;
if mod_exp(a, n-1, n) <> 1 then return false;
end;
return true;
end;
注意,MIller-Rabin测试是概率型的,不是确定型的,不过由于多次运行后出错的概率非常小,所以实际应用还是可行的。(一次Miller-Rabin测试其成功的概率为3/4)前边说的伪代码实现很简短,下面还有一个定理,能提高Miller测试的效率:
二次探测定理:
如果p是奇素数,则 x2 ≡ 1(mod p)的解为 x = 1 || x = p - 1(mod p);
可以利用二次探测定理在实现Miller-Rabin上添加一些细节,具体实现如下:
bool miller_rabin(ll n) {
if(n == 2 || n == 3 || n == 5 || n == 7 || n == 11) return true;
if(n == 1 || !(n%2) || !(n%3) || !(n%5) || !(n%7) || !(n%11)) return false;
ll x, pre, u;
int i, j, k = 0;
u = n - 1; //要求x^u % n
while(!(u&1)) { //如果u为偶数则u右移,用k记录移位数
k++; u >>= 1;
}
srand((ll)time(0));
for(i = 0; i < S; ++i) { //进行S次测试
x = rand()%(n-2) + 2; //在[2, n)中取随机数
if((x%n) == 0) continue;
x = mod_exp(x, u, n); //先计算(x^u) % n,
pre = x;
for(j = 0; j < k; ++j) { //把移位减掉的量补上,并在这地方加上二次探测
x = mod_mul(x, x, n);
if(x == 1 && pre != 1 && pre != n-1) return false; //二次探测定理,这里如果x = 1则pre 必须等于 1,或则 n-1否则可以判断不是素数
pre = x;
}
if(x != 1) return false; //费马小定理
}
return true;
}前边这个算法经过测试还是比较靠谱的,可以用作模板。本菜也找过其他模板,可是有的居然把9测成素数,汗 -_-!
额,这个是我转的尊重作者:AC_Von 原创,转载请注明出处:http://www.cnblogs.com/vongang/archive/2012/03/15/2398626.html
Miller-Rabin理解的时候有一个我自己的小trick
n%(n-2)的范围是0~n-3,而不是0~n-1,这一点千万别搞错!
然后0~n-3,加上2,就变成了2~n-1,make sense
欧拉定理
费马定理是用来阐述在素数模下,指数的同余性质。当模式合数的时候,就要应用范围更广的欧拉定理
欧拉函数:对正整数n,欧拉函数是小于等于n的数中与n互质的数的数目
欧拉函数又称为phi函数,例如phi(8)=4,因为1,3,5,7与8互质
引理1:
1.如果n为某一个素数p,则phi(p)=p-1
2.如果n为某一个素数p的幂次p^a,则phi(p^a)=(p-1)*p^(a-1)
3.如果n为任意两个互质的数a,b的乘积,则phi(a*b)=phi(a)*phi(b)
证明:
1.显然
2.因为比p^a小的正整数一共有p^(a)-1个
其中,所有能被p整除的数,都可以表示成p*t(t=1,2,3,...,p^(a-1)-1),如果t=p^(a-1)-1+1=p^(a-1)
则pt=p^a,不满足比p^a小的条件,所以t只能到p^(a-1)-1
也就是说一共有p^(a-1)-1个数能被p整除,从而不与p^a互质
所以phi(p^a)=(p^(a)-1)-(p^(a-1)-1)=p^a-p^(a-1)=(p-1)*(p^(a-1))
3.在比a*b小的a*b-1个整数中,只有那些既和a互质(phi(a)个),又和b互质(phi(b) 个)
的数才会与a*b互质,显然满足这种条件的数有phi(a)*phi(b)个,所以有phi(a*b)=phi(a)*phi(b)
引理2:
设n=p1^a1+p2^a2+p3^a3+...+pk^ak
为正整数n的素数幂乘积表达式
则phi(n)=n*(1-1/p1)*(1-1/p2)*...*(1-1/pk)
证明:由于诸素数幂之间是互质的,根据引理1得出:
phi(n)=phi(p1^a1)*phi(p2^a2)*...*phi(pk^ak)
=p1^a1*(1-1/p1)*p2^a2*(1-1/p2)*...*pk^ak*(1-1/pk)
=p1^a1*p2^a2*...*pk^ak*(1-1/p1)*(1-1/p2)*...*(1-1/pk)
比如phi(100)=phi(2^2*5^2)=100*(1-1/2)*(1-1/5)=100*2/5=40
欧拉定理
若a与m互质,则a^(phi(m))=1(mod m)
Pollard Rho算法求大数因子
首先,对于任意一个偶数,我们都可以提取出一个2的质因子,如果结果仍然为偶数,则可继续该操作
直至其化为一个奇数和2的多少次幂的乘积,
那么我们可以假定这个奇数可以被表示为N=2*n+1,如果这个数是合数,那么一定可以写成N=c*d的形式
不难发现式子中的c,d都是奇数,否则N是偶数,不妨设c<d,c=d怎么办,c=d我们则可以写成c=1,d=N=c*d,这样就好了
我们可以令a=(c+d)/2,b=(c-d)/2
那么我们可以得到,a*a=c^2+d^2+2cd/4,b*b=c^2+d^2-2cd
a*a-b*b=4cd/4=cd=N
则N=a*a-b*b
这正是Fermat整数分解的基础
由基本不等式可得 a>=sqrt(c*d)=sqrt(N)
那么我们就枚举大于N的完全平方数a*a
计算a*a-N的值,判断计算的结果是否是一个完全平方数,如果是的话,则a+b和a-b都是N的因子(因为N=a^2-b^2=(a+b)*(a-b)=c*d)
然后我们就可以将算法递归地进行下去,直到求出n的所有质因子
pollard-rho。是一个寻找n的因子的方法。基于这个事实:如果a不为n的倍数,那么gcd(a,n)为n的一个因子。
I、选取一个x1
II、利用函数计算出x2使得x2-x1不被n整除。
III、如果gcd(x2-x1,n)>1那么找到因子,结束过程
IV、否则重复I。
所以这里这个显然但是容易忽略的事实,如果a不为n的倍数,那么gcd(a,n)为n的一个因子。派上大用场了。。
具体操作当中,我们通常使用函数 x[i+1]=(x[i]*x[i]+c)mod n 来计算逐步迭代计算a和b的值
实践中通常取c=1,即b=a*a+1,在下一次计算中,将b的值赋给a,
再次使用上式来计算新的b值,当a,b出现循环时,即可退出进行判断,当然初值由自己确定,
但是这样的话判断循环比较麻烦,我们可以用另一种方法。
是由Floyd发明的一个算法,我们举例来说明这个聪明又有趣的算法
假设我们在一个很长很长的圆形轨道上行走,我们如何知道我们已经走了一圈呢,当然我们可以像第一种方法那样做
更聪明的方法是让A和B按照B的速度是A的两倍从同一起点开始往前走,当B第一次赶上A时,(套圈,因为B在第一圈之内一定无法和A相遇除非速度一样)
我们便知道B已经走了至少一圈。
所以我们可以把x当作B,y当作A来进行循环测试,具体实现详见参考程序
先来说一下欧拉函数的线性筛法
我们要证明的是其中要用到的一个结论,
如果i mod p==0,那么phi(i*p)=p*phi(i)
========================
设P是素数,
若p是x的约数,则E(x*p)=E(x)*p.
若p不是x的约数,则E(x*p)=E(x)*E(p)=E(x)*(p-1).
证明如下:
E(x)表示比x小的且与x互质的正整数的个数。
*若p是素数,E(p)=p-1。
*E(p^k)=p^k-p^(k-1)=(p-1)*P^(k-1)
证:令n=p^k,小于n的正整数数共有n-1即(p^k-1)个,其中与p不质的数共[p^(k-1)-1]个(分别为1*p,2*p,3*p...p(p^(k-1)-1))。
所以E(p^k)=(p^k-1)-(p^(k-1)-1)=p^k-p^(k-1).得证。
*若ab互质,则E(a*b)=E(a)*E(b),欧拉函数是积性函数.
*对任意数n都可以唯一分解成n=p1^a1*p2^a2*p3^a3*...*pn^an(pi为素数).
则E(n)=E(p1^a1)*E(p2^a2)*E(p3^a3)*...*E(pn^an)
=(p1-1)*p1^(a1-1)*(p2-1)*p2^(a2-1)*...*(pn-1)*pn^(an-1)
=(p1^a1*p2^a2*p3^a3*...*pn^an)*[(p1-1)*(p2-1)*(p3-1)*...*(pn-1)]/(p1*p2*p3*...*pn)
=n*(1-1/p1)*(1-1/p2)*...*(1-1/pn)
* E(p^k) =(p-1)*p^(k-1)=(p-1)*p^(k-2)*p
E(p^(k-1))=(p-1)*p^(k-2)
->当k>1时,E(p^k)=E(p*p^(k-1))=E(p^(k-1))*p.
(当k=1时,E(p)=p-1.)
由上式: 设P是素数,
若p是x的约数,则E(x*p)=E(x)*p.
若p不是x的约数,则E(x*p)=E(x)*E(p)=E(x)*(p-1). 证明结束。我们可以取证明过程中的一个结论。。那就是E(p^k)=E(p^(k-1))*p,实际上这是一个显然但容易忽略的事实
为什么显然呢,我们知道E(p^k)=(p^k-1)-(p^(k-1)-1)=p^k-p^(k-1)=p*p^(k-1)-p^(k-1)=(p-1)*p^(k-1)
我们只需提取一个p,变成(p-1)*p^(k-2)*p,显然,E(p^(k-1))=(p-1)*p^(k-2),那么就可以写成E(p^(k-1))*p,
前提是k>1,
然后如果i mod p==0,那么i不断对p取模,直到i%p!=0,i可以写成i=q*p^r
则E(i*p)=E(q*p^r*p)=E(q*p^(r+1)),我们知道q和p^r互质(显然),那么当然q和p^(r+1)也互质
所以E(q*p^(r+1))=E(q)*E(p^(r+1)),运用截取的事实
E(q)*E(p^(r+1))=E(q)*E(p^r)*p,然而E(i)=E(q)*E(p^r)
所以E(q)*E(p^r)*p=E(i)*p,
则结论,E(i*p)=E(i)*p成立,证毕
这里我们考虑了在线性筛中i%pr[j]==0的情况,互质的情况呢
显然如果没有碰到i%pr[j]==0的情况时,这个合数(质数就不用考虑了),还没有遇到和他最小的质因子相等的质数,那么又唯一分解定理可知,这些情况
两个数都是互质的
BabyStep-GiantStep 及扩展算法
有一个显然但是容易忽略的事实,A>0,A如果不是C的倍数,A一定小于C,(如果C是质数那么A和C一定互质)
先来了解一个概念:离散对数,离散对数是一种在整数中基于同余运算和原根的对数运算。
原根就是。。



并不是每一个模都存在原根。。
当模m有原根时,设G为模m时的一个原根,则当x=G^k(mod m)时,logG(x)=k(mod phi(m))因为G^(phi(m))=1,所以多于phi(m)的部分砍掉就好了,
Baby-Step Giant-Step 及 扩展算法 Extended BSGS
用来求解A^(x)=B(mod C)
(x>=0&&x<C)这样的问题,
因为C是质数,如果A是C的倍数则B=0,否则A<C,则A,C互质
则A的幂次mod C有循环节(欧拉定理),所以x是这个范围的
这个算法是以空间换时间,对穷举算法的一个改进
原始的BSGS只能解决C为素数的情况
设m=sqrt(C)上取整,x=i*m+j,那么A^x=(A^m)^i*A^j(i>=0&&i<m,j>=0&&j<m)
如果我们枚举i,j则这是sqrt(C)*sqrt(C)的,但是这样我们就枚举出了所有的x,由此可知该枚举方法的正确性
其实就是。。我们需要枚举小于sqrt(C)和大于sqrt(C)的情况
但是我们可以只枚举i,这是sqrt(C)级别的枚举
对于一个枚举出来的i,令D=(A^(m)^i),现在问题转化为了求D*A^j=B(mod C)
由于A,C互质,则A的幂次也和C互质,所以相当于求Dx+Cy=B
而GCD(D,C)=1,所以B%(GCD(D,C))==0,所以x一定有解,即A^j一定有解
所以跑一遍扩展欧几里得算法,我们就能算出A^j是多少
求出了A^j,现在的问题就是我怎么知道j是多少,一个非常聪明的方法是,先用sqrt(C)的时间
将A^j全部存进hash表里面,然后查表只需O(1)就知道j是多少了,当然这里是手工Hash的复杂度
如果你用map的话,大概是O(log(sqrt(C)))
消因子
关于消因子,是这样的,
A=B(mod m)
那么我们可以推出 A=B(mod mc)
然后我们又可以推出
AC=BC(mod mc)
那么由于是充分必要条件,我们也可以反推回A=B(mod m)
我们也可以这么想,A=B(mod m)
可以看作是A=pm+r,B=qm+r,同余嘛,r相同
那么我们可以推出,AC=pCm+Cr,BC=qCm+Cr
这个可以推出AC=BC(mod mC)
那么如果AC,和mC有公因子,这个情况显然有公因子C嘛,于是我们可以消去公因子,那么BC也要消去同样的公因子C
那么可以推出,A=B(mod m)
扩展的BSGS不要求C是素数,大致的做法和原始的BSGS一样
只是做一些修改,因为同余具有一条性质
令d=GCD(A,C),A=a*d,B=b*d,C=c*d
则a*d=b*d(mod c*d)
等价于a=b(mod c)
因此开始前先消除因子
只要GCD(A,C)!=1,我们就A,B,C都同除以GCD(A,C)
其中A不用真的除,我们记录一个D=1,每次D*=A/GCD(A,C),和乘法的次数cnt
在消除因子时如果GCD(A,C)!=1,且B%(GCD(A,C))!=0此时无解
为什么呢
假设a*d=k(mod c*d)
则a*d=q*c*d+k
显然d能整除a*d,那么d也能整除k,如果d不能整除k就无解
进一步分析我们可以知道假如A是小于d的,那么K<d,(mod Cd)
假如A是d的倍数,那么mod C*d是绝对不会剩下一个比d还小的数,
并且这个数一定是d的倍数,刨去单个的d,同理不会剩下比d小的数,所以一定是d的倍数,所以一定会被d整除
前提是A是d的倍数哦
执行完上面的过程,问题变成了,D*A^(x-cnt)=B(mod C)
令x=i*m+j+cnt
后面做法就跟BSGS一样了。
但是注意到i>=0,j>=0,我们明显存在小于等于cnt的情况,
所以在消因子之前需要做一次log(C)的枚举,直接验证A^i%C=B
据说这样是要考虑到ρ型轨道,问题来了,,轨道是什么呢
那个轨道是这样,因为n^x mod p 的值最终会产生循环,所以你可以想象各种轨道就好像循环的链表!
阶:满足 x r ≡ 1 (mod m) 最小正整数 r 称为 x 的阶 ordm(x) ,不难得到 ordm(x) | ϕ(m)
因为phi(m)是循环节结尾,如果有比phi(m)小的循环节尾,那么那个数一定可以整除phi(m)
判定a是否为x的原根
枚举 phi(x) 的因子,熟知阶是 phi(x) 的因子,
但是你发现如果某个 a^(phi(x)/(prime factor of phi(x))) 是 1
就存在某个 <phi(x) 的因子是阶
就不是原根了所以我们在log(phi(x))的时间里能够判别a是否是x的原根一、枚举
从2开始枚举,然后暴力判断g^(P-1) = 1 (mod P)是否当且当指数为P-1的时候成立
而由于原根一般都不大,所以可以暴力得到.二、讲究方法
例如求任何一个质数x的任何一个原根,一般就是枚举2到x-1,并检验。有一个方便的方法就是,求出x-1所有不同的质因子p1,p2...pm,对于任何2<=a<=x-1,判定a是否为x的原根,只需要检验a^((x-1)/p1),a^((x-1)/p2),...a^((x-1)/pm)这m个数中,是否存在一个数mod x为1,若存在,a不是x的原根,否则就是x的原根。
原来的复杂度是O(P-1),现在变成O(m)*log(P-1)m为x-1质因子的个数。很明显质因子的个数远远小于x-1。
证明可用欧拉定理和裴蜀定理:
说明了对任何整数a、b和它们的最大公约数d,关于未知数x和y的线性丢番图方程(称为裴蜀等式):
ax + by = m
有解当且仅当m是d的倍数。裴蜀等式有解时必然有无穷多个整数解,每组解x、y都称为裴蜀数,可用辗转相除法求得。例如,12和42的最大公因子是6,则方程12x + 42y = 6有解。事实上有(-3)×12 + 1×42 = 6及4×12 + (-1)×42 = 6。
特别来说,方程 ax + by = 1 有解当且仅当整数a和b互素。
裴蜀等式也可以用来给最大公约数定义:d其实就是最小的可以写成ax + by形式的正整数。这个定义的本质是整环中“理想”的概念。因此对于多项式整环也有相应的裴蜀定理。
那我来把下面的证明啰嗦地说一遍吧,防止有的同学看不懂了。
1 假设x-1可以分解为p1~pm的幂次,Si=(x-1)/pi;
那么假设a的S1~Sm幂次存在一个等于1的数,那么显然这个不是我们要的答案,因为他构成互不相同的元素集合
2 那么如果a的S1~Sm次方都没有等于1的,此时我们用反证法来证明再没有因子能使得a的幂次等于1 3 假设存在一个t<phi(x)=x-1使得a^t = 1 (mod x) 4 5 由裴蜀定理,一定存在一组k,r使得kt=(x-1)r+gcd(t,x-1) 6 7 由欧拉定理有,a^(x-1) = 1 (mod x) 8 9 于是由上述三个等式 1 = a^(kt) = a^(xr-r+gcd(t,x-1)) = a^gcd(t,x-1) (mod x) 10 11 而t<x-1故gcd(t,x-1)<x-1 12 (而我们知道一个数被分解质因数之后,他的因子必能写成他的质因子的乘积,故因子最小为p1~pm
所以比x-1小的尽量包含尽可能多因数的情况最多有多少种呢,显然让他减去最小的质因子的一个幂次就可以也就是,x-1/pi) 13 又gcd(t,x-1)|x-1 于是gcd(t,x-1)必整除(x-1)/p1,(x-1)/p2...(x-1)/pm其中至少一个,设其一为(x-1)/pi 14 15 那么a^((x-1)/pi) = (a^gcd(t,x-1))^s = 1^s = 1 (mod x) 16 17 那么这个假设与Si中没有能使a^Si=1的前提矛盾,故,在任意a^Si!=1时,再也没有比x-1小的数t能使a^t=1这里的存在是说。。那m个数中是否有一个是mod =1
反证法很明白。。对于裴蜀定理。。这个是无条件成立的。。任意两个数都能找到,pa+qb=gcd(a,b)
然后我们为什么只枚举这m个数呢。。因为这是m个最大的约数的情况,这些情况包含了phi(x)的最小的因子的幂次的所有情况
如果枚举了phi(x)/pi那么就没有必要枚举phi(x)/pi^2,因为如果phi(x)/pi能检测出来mod之后等于1,那么phi(x)/pi^2就不用检测
如果不能检测的话,那么后面那个也是不能检测的。。


