
HTTP 长连接
上周再做一个easyproxy的小项目,实现代码反向代理的工作,具体就是在tcp层对各个请求(只要遵循建立在tcp层之上的协议即可)进行解析,然后分发各个具体服务上。
这中间遇到的一个问题就是HTTP中的长连接问题,重新去看了下具体的http协议,发现之前对这块知识还是存在盲点。
这篇文章可以算是自己的学习笔记, 很多内容更是直接使用我看到和觉得讲得不错的资料,希望对大家也有所帮助。
基础知识
1. 名称
维基百科中的介绍:
“HTTP persistent connection, also called HTTP keep-alive, or HTTP connection reuse, is the idea of using a single TCP connection to send and receive multiple HTTP requests/responses, as opposed to opening a new connection for every single request/response pair.”
讲这个,是因为我觉得“长连接”这个称呼并不是非常准确,用“持久连接”,而“Long Connection”这种直接翻译词就更不用再用了。但毕竟这个名字已经沿用这么久了,我们也就继续用这个名
2. 原理
在HTTP协议中长连接中同一个TCP连接来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
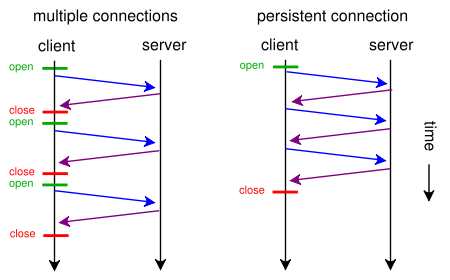
下图是网上一张很形象讲解普通连接和长连接区别的图
从图中,我们就能清晰地看到,两者区别就是长连接会“复用”原先建立TCP连接
3. 实现
在 HTTP 1.0 中
没有官方的 keepalive 的操作。通常是在现有协议上添加一个指数。如果浏览器支持 keep-alive,它会在请求的包头中添加:
Connection: Keep-Alive
然后当服务器收到请求,作出回应的时候,它也添加一个头在响应中:
Connection: Keep-Alive
这样做,连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个连接。这一直继续到客户端或服务器端认为会话已经结束,其中一方中断连接。
比如我用chrome访问博客园首页
request header:

response header:

在 HTTP 1.1 中
所有的连接默认都是持续连接,除非特殊声明不支持。
所以现在各个浏览器的高版本基本都是支持长连接。
4. 优势
- 较少的CPU和内存的使用(由于同时打开的连接的减少了)
- 允许请求和应答的HTTP pipelining
- 降低网络阻塞 (TCP连接减少了)
- 减少了后续请求的延迟(无需再进行握手)
- 报告错误无需关闭TCP连接
其实它一切的优势就在于复用了原先建立的TCP连接,减少重新建立TCP连接的消耗
5. 劣势
- 空闲的连接需要过段时间后才能被断开,可能影响整体性能(比如那些单次访问次数多的web 服务)
6. 浏览器
现在的高版本浏览器都是默认支持长连接的,而它们维护长连接的方式就是用“超时管理”。
在一段时间内没有请求和相应时,就自动将连接断掉。
参考文章:
维基百科介绍:英文
Persistent HTTP Connections in RFC 2616 "Hypertext Transfer Protocol -- HTTP/1.1

