
Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考。
1. 建设背景
我们公司主要为医院建立大数据应用平台,需要从各个医院系统中抽取数据建立大数据平台。如医院信息系统,实验室(检验科)信息系统,体检信息系统,临床信息系统,放射科信息管理系统,电子病例系统等等。

在这么多系统中构建大数据平台有哪些痛点呢?大致列举如下。
- 接入的数据库多样化。其中包括很多系统,而系统又是基于不同数据库进行开发的,所以要支持的数据库比较多,例如MySQL,Oracle,Mongo db,SQLServer,Cache等等。
- 统一数据建模。针对不同的医院不同的系统里面的表结构,字段含义都不一样,但是最终数据模型是一定的要应用到大数据产品上的,这样需要考虑数据模型的量化。
- 数据量级差别巨大。不一样的医院,不一样的系统,库和表都有着很大的数据量差异,处理方式是需要考虑兼容多种场景的。
- 数据的时效性。数据应用产品需要提供更高效的实时应用分析,这也是数据产品的核心竞争力。
2. 为什么选择Hudi
我们早期的数据合并方案,如下图所示
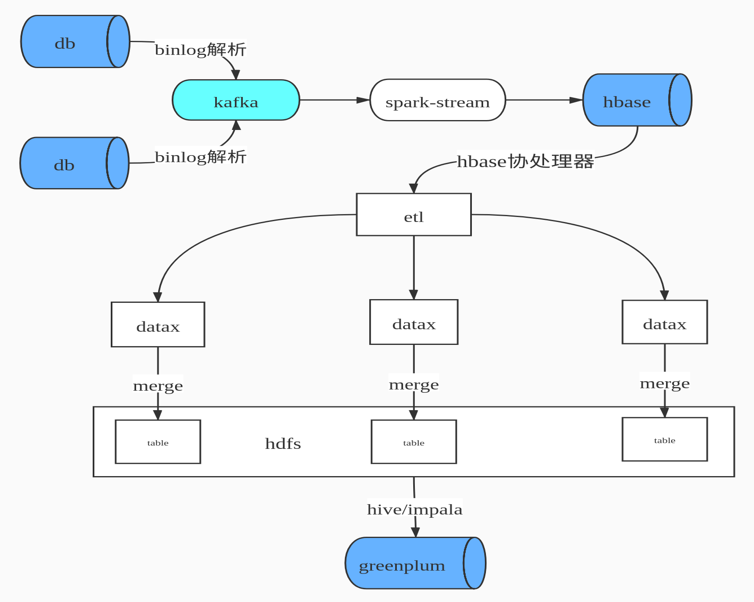
即先通过binlog解析工具进行日志解析,解析后变为JSON数据格式发送到Kafka 队列中,通过Spark Streaming 进行数据消费写入HBase,由HBase完成数据CDC操作,HBase即我们ODS数据层。由于HBase 无法提供复杂关联查询,这对后续的数据仓库建模并不是很友好,所以我们设计了HBase二级索引来解决两个问题:1. 增量数据的快速拉取,2. 解决数据的一致性。然后就是自研ETL工具通过DataX 根据最后更新时间增量拉取数据到Hadoop ,最后通过Impala数据模型建模后写入Greenplum提供数据产品查询。
上述方案面临了如下几个问题
- 数据流程环节复杂,数据要经过Kafka,HBase,Hdfs,Impala。
- 数据校验困难,每层数据质量校验比较麻烦。
- 数据存储冗余,HBase存储一份,Hive Hdfs 也存储一份。
- 查询负载高,HBase表有上限一旦表比较多,维护的Region个数就比较多,Region Server 容易出现频繁GC。
- 时效性不高,流程长不能保证每张表都能在10分钟内同步,有些数据表有滞后现象。

面对上述的问题,我们开始调研开源的实现方案,然后选择了Hudi,选择Hudi 优势如下
- 多种模式的选择。目前Hudi 提供了两种模式:Copy On Write和Merge On Read,针对不同的应用场景,可选择不同模式,并且每种模式还提供不同视图查询,。
- 支持多种查询引擎。Hudi 提供Hive,Spark SQL,presto、Impala 等查询方式,应用选择更多。
- Hudi现在只是Spark的一个库, Hudi为Spark提供format写入接口,相当于Spark的一个库,而Spark在大数据领域广泛使用。
- Hudi 支持多种索引。目前Hudi 支持索引类型HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引以及用户自定义索引以加速查询性能,避免不必要的文件扫描。
- 存储优势, Hudi 使用Parquet列式存储,并带有小文合并功能。
3. Hudi 数据同步
Hudi数据同步主要分为两个部分:1. 初始化全量数据离线同步;2. 近实时数据同步。

离线同步方面:主要是使用DataX根据业务时间多线程拉取,避免一次请求过大数据和使用数据库驱动JDBC拉取数据慢问题,另外我们也实现多种datax 插件来支持各种数据源,其中包括Hudi的写入插件。
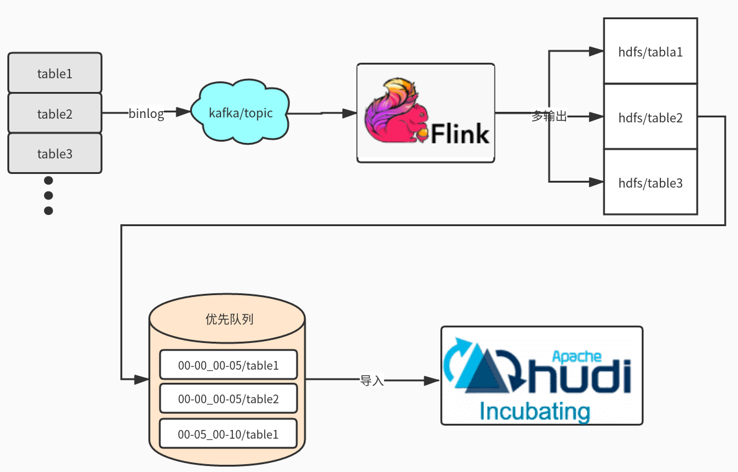
近实时同步方面:主要是多表通过JSON的方式写入Kafka,在通过Flink多输出写入到Hdfs目录,Flink会根据binlog json的更新时间划分时间间隔,比如0点0分到0点5分的数据在一个目录,0点5分到0点10分数据一个目录,根据数据实时要求选择目录时间的间隔。接着通过另外一个服务轮询监控Hdfs是否有新目录生成,然后调用Hudi Merge脚本任务。运行任务都是提交到线程池,可以根据集群的资源调整并合并的数量。
这里可能大家有疑问,为什么不是Kafka 直接写入Hudi ?官方是有这样例子,但是是基于单表的写入,如果表的数据多达上万张时怎么处理?不可能创建几万个Topic。还有就是分流的时候是无法使用Spark Write进行直接写入。
4. 存储类型选择及查询优化
我们根据自身业务场景,选择了Copy On Write模式,主要出于以下两个方面考虑。
- 查询时的延迟,
- 基于读优化视图增量模式的使用。
关于使用Spark SQL查询Hudi也还是SQL拆分和优化、设置合理分区个数(Hudi可自定义分区可实现上层接口),提升Job并行度、小表的广播变量、防止数据倾斜参数等等。
关于使用Presto查询测试比Spark SQL要快3倍,合理的分区对优化非常重要,Presto 不支持Copy On Write 增量视图,在此基础我们修改了hive-hadoop2插件以支持增量模式,减少文件的扫描。
5. 未来发展与思考
-
离线同步接入类似于FlinkX框架,有助于资源统一管理。FlinkX是参考了DataX的配置方式,把配置转化为Flink 任务运行完成数据的同步。Flink可运行在Yarn上也方便资源统一管理。
-
Spark消费可以支持多输出写入,避免需要落地Hdfs再次导入。这里需要考虑如果多表传输过来有数据倾斜的问题,还有Hudi 的写入不仅仅只有Parquert数据写入,还包括元数据写入、布隆索引的变更、数据合并逻辑等,如果大表合并比较慢会影响上游的消费速度。
-
Flink对Hudi的支持,社区正在推进这块的代码合入。
-
更多参与社区,希望Hudi社区越来越好。
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



