
什么是TD-IDF?(计算两篇文章相似度)
什么是TD-IDF?
计算特征向量(或者说计算词条的权重)
构造文档模型
我们这里使用空间向量模型来数据化文档内容:向量空间模型中将文档表达为一个矢量。
We use the spatial vector model to digitize the document content: the vector space model represents the document as a vector.
用特征向量(T1,W1;T2,W2;T3, W3;…;Tn,Wn)表示文档。
The eigenvectors (T1, W1; T2, W2; T3, W3; ... ; Tn, Wn) represents the document.
- Ti是词条项 ti is term
- Wi是Ti在文档中的重要程度 (Wi is the importance of term Ti in the document)
即将文档看作是由一组相互独立的词条组构成
Think of a document as a set of independent phrases
把T1,T2 …,Tn看成一个n 维坐标系中的坐标轴
T1, T2... Tn as an n - dimensional coordinate system
对于每一词条根据其重要程度赋以一定的权值Wi,作为对应坐标轴的坐标值。
Each term is assigned a certain weight, Wi, according to its importance, as the coordinate value of the corresponding coordinate axis.
权重Wi用词频表示,词频分为绝对词频和相对词频。
Weighted Wi is represented by word frequency, which is divided into absolute word frequency and relative word frequency.
- 绝对词频,即用词在文本中出现的频率表示文本。Absolute word frequency, that is, the frequency of words in the text represents the text.
- 相对词频,即为归一化的词频,目前使用 最为频繁的是TF*IDF(Term Frequency * Inverse Document Frequency)TF乘IDF The relative word frequency is the normalized word frequency, and TF*IDF is the most frequently used at present
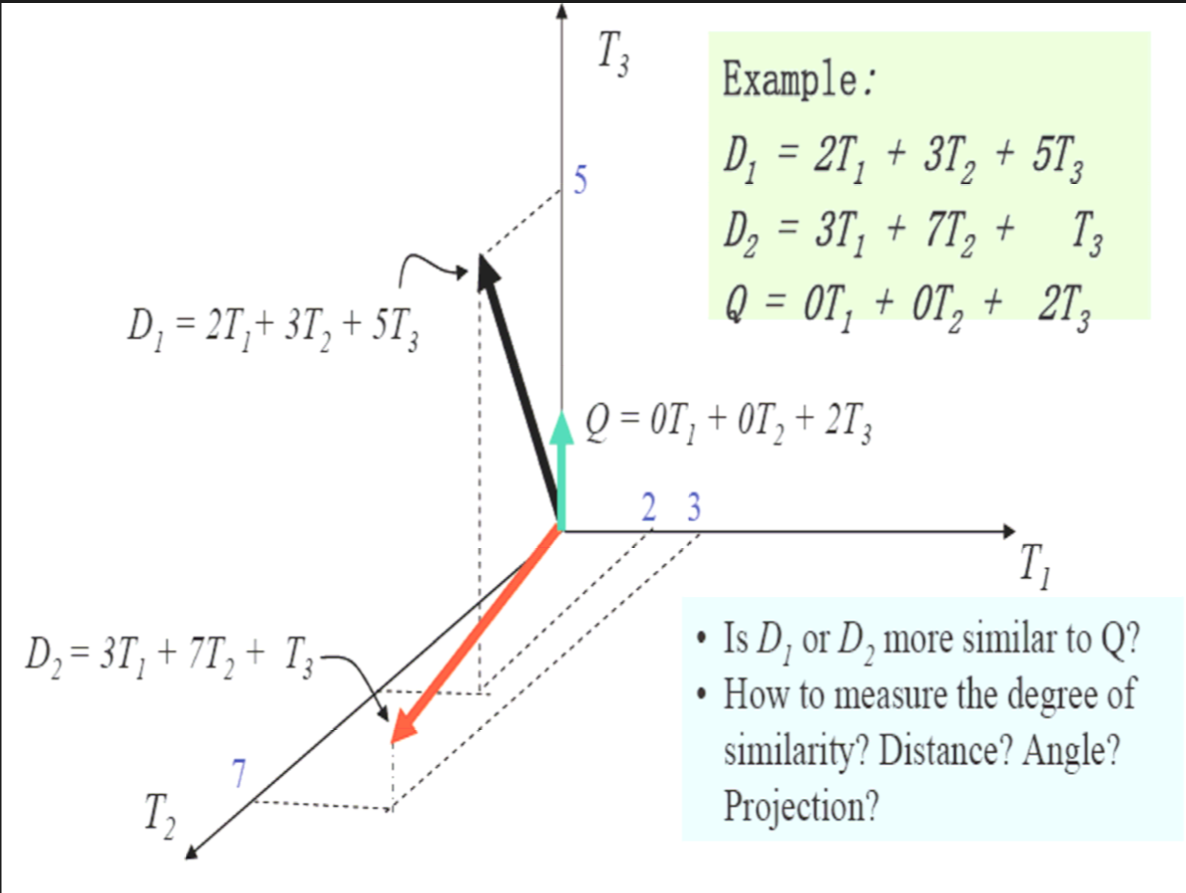
将文档量化了之后我们很容易看出D1与Q更相似~因为D1与Q的夹角小,我们可以用余弦cos表示After quantifying the document, it's easy to see that D1 is more similar to Q ~ because the Angle between D1 and Q is small, we can express it in terms of cosine cosine of theta
分析一下这个例子:analyze this example
有三个文档D1,D2,Q there have three documents D1,D2,Q
这三个文档一共出现了三个词条,我们分别用T1,T2,T3表示 this documents appears three terms,we present them by using T1,T2,T3 individualy
在文档D1中词条T1的权重为2,T2权重为3,T3权重为5
在文档D2中词条T1权重为0,T2权重为7,T3权重为1
在文档Q中词条T1权重为0,T2权重为0,T3权重为2
T1 has a weight of 2, T2 has a weight of 3, and T3 has a weight of 5 in document D1
T1 has a weight of 0, T2 has a weight of 7, T3 has a weight of 1 in document D2
T1 has a weight of 0, T2 has a weight of 0, and T3 has a weight of 2 in document D3
| D1 | D2 | Q | |
| T1 | 2 | 3 | 0 |
| T2 | 3 | 7 | 0 |
| T3 | 3 | 1 | 2 |
接下来我们看tf*idf的公式:
tf:tf(d,t) 表示词条t 在文档d 中的出现次数
Tf (d,t) represents the number of occurrences of term t in document d
idf:idf(t)=log N/df(t)
-
df(t) 表示词条t 在文本集合中出现过的文本数目(词条t在哪些文档出现过) the number of occurences of document in all doucuments ,which term t appear in documents
-
N 表示文本总数 N represent the numbers of all documents
对于词条t和某一文本d来说,词条在该文本d的权重计算公式:
For term t and a document d, the formula for calculating the weight of term in that dpcument d is:
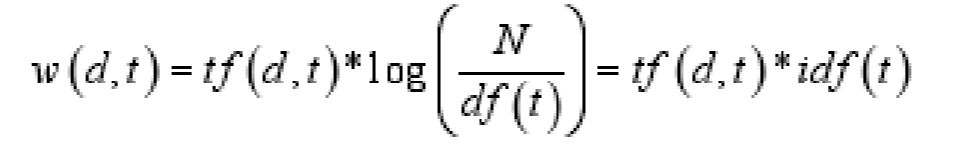
- 特征向量(T1,W1;T2,W2;T3, W3;…;Tn,Wn)就可以求出了!
Eigenvectors (T1, W1; T2, W2; T3, W3; ... ; Tn, Wn, that's it!
是不是很简单呢~
进一步思考:
如果说一个词条t几乎在每一个文档中都出现过那么:
If an term t appears in almost every document, then:
idf(t)=log N/df(t)
趋近于0,此时w(t)也趋近于0,从而使得该词条在文本中的权重很小,所以词条对文本的区分度很低。
near 0,w(t) is also tend to zero,then make the weight of this term in the dicument is small ,so the distinction of this term in document is very low
停用词:在英文中如a,of,is,in.....这样的词称为停用词,它们都区分文档的效果几乎没有,但是又几乎在每个文档中都出现,此时idf的好处就出来了
In English, such as a,of,is,in... Such words, called stop words, have little effect on distinguishing documents but appear in almost every document, and the benefits of idf come out
我们通常根据w(d,t)值的大小,选择指定数目的词条作为文本的特征项,生成文本的特征向量(去掉停用词)We usually select a specified number of entries as text feature items based on the size of the w(d,t) value, and generate text feature vectors (minus stop words).
这种算法一方面突出了文档中用户需要的词,另一方面,又消除了在文本中出现频率较高但与文本语义无关的词条的影响
On the one hand, this algorithm highlights the words needed by users in the document, while on the other hand, it eliminates the influence of terms that appear frequently in the text but have nothing to do with the semantic meaning of the document
文本间相似性 :
基于向量空间模型的常用方法,刚才我们提到过可以用余弦值来计算,下面我讲一下具体步骤
Now, the usual way of doing it based on vector space models, we mentioned earlier that you can do it with cosines, so let me go through the steps
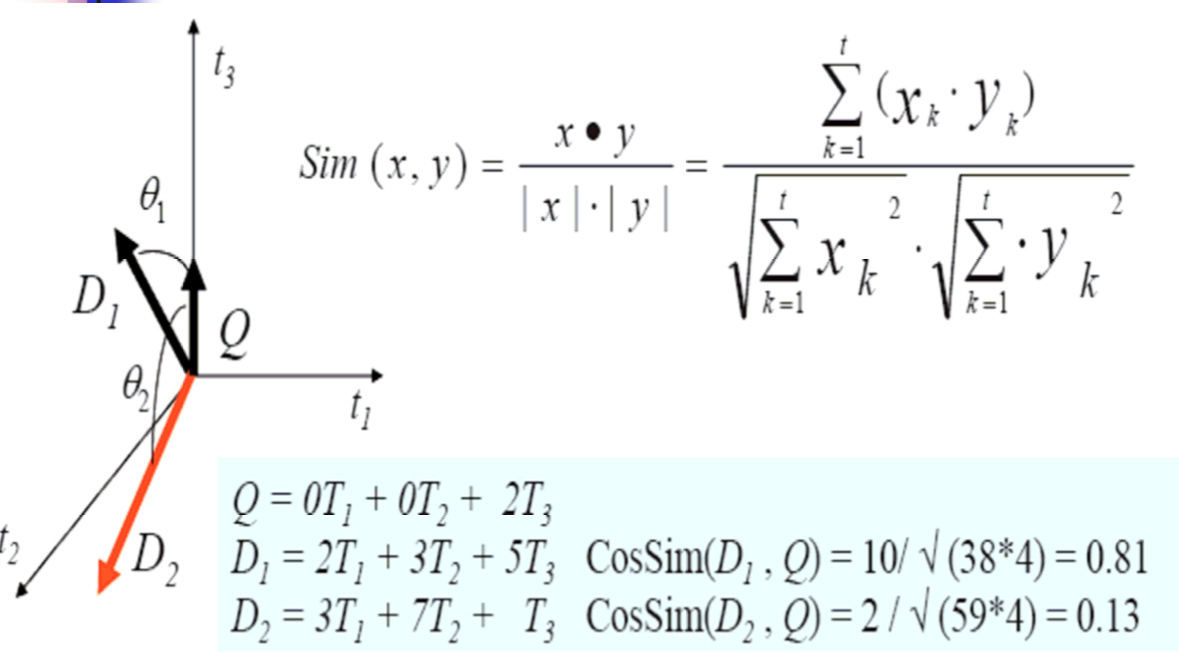
内积不会求得自行百度。。。。
为了提高计算效率:可以先算x'=x/|x|,y'=y/|y|;大量计算两两文档间相似度时,为降低计算量,先对文档向量进行单位化。
In order to improve the efficiency of calculation, x'=x/|x|,y'=y/|y|; When calculating the similarity between two documents in large quantities, in order to reduce the amount of computation, So let's first unit the document vector
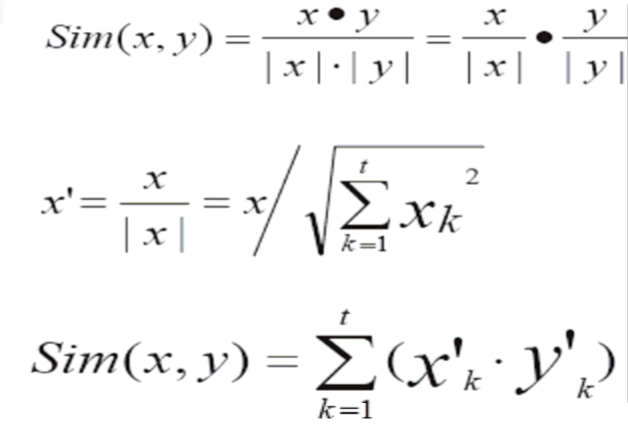
ok~tf*idf就先到这里
总结:
我们可以通过计算tf*idf的值来作为特征向量的权重
然后通过计算特征向量之间的余弦值来判断相似性。
We can calculate the value of tf*idf as the weight of the eigenvector
Then the similarity is determined by calculating the cosine between the eigenvectors

