杜教筛 学习总结
看了看唐老师的blog,照猫画虎的做了几道题目,感觉对杜教筛有些感觉了
但是稍微有一点难度的题目还是做不出来,放假的时候争取都A掉(挖坑ing)
这篇文章以后等我A掉那些题目之后再UPD上去就好啦
由于懒得去写怎么用编辑器写公式,所以公式就准备直接copy唐老师的啦
首先积性函数和完全积性函数什么的就不再多说了
列举常见的积性函数:
1、约数个数函数和约数个数和函数
2、欧拉函数phi
3、莫比乌斯函数mu
4、元函数e 其中e(n)=[n==1]
5、恒等函数I 其中I(n)=1
6、单位函数id 其中id(n)=n
有关狄利克雷卷积
定义: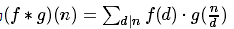
我们简单记为f*g
注意,狄利克雷卷积满足交换律,结合律,对于加法满足分配率
两个很显然的事情是:1、f*e=e*f=f
2、设h=f*g,若f和g是积性函数,则h是积性函数
积性函数的一些性质:
1、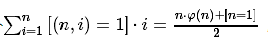
2、e=mu*I
3、id=phi*I
之后我们由第二条性质可以得到一些很有趣的结论:
设存在函数g=f*I (通过f求g)
那么我们可以得到g*mu=f*I*mu
进而化简得到f=g*mu (通过g求f)
唐老师的博客里还举了一些更为有趣的例子
好了,前置技能都说完了,我们来说正题
杜教筛基本可表示成如下形式:
求F(n)=sigma(f(i))
存在g=f*I,定义G(n)=simga(g(i))
就可以得到F(n)=G(n)-sigma(F(n/i)) (这里i从2开始)
如果G(n)是可以在一定时间内求解(不一定要求O(1))
那么我们就可以做到O(n^(3/4))求解F(n)
如果加一些预处理我们可以做到O(n^(2/3))求解F(n)
下面通过几个例子来说一说为什么是这样的:
1、求sigma(phi(i))
由于我们知道id=phi*I
而且id的前缀和是可以O(1)的计算的
所以我们可以做以下推导
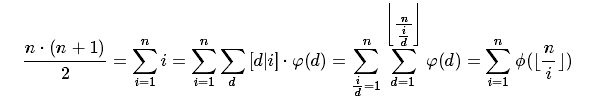
对,没错,推完了之后就是我们上面提到过的形式,那么至于证明上面的形式的正确性就可以用这种推导方式啦
时间复杂度的分析:
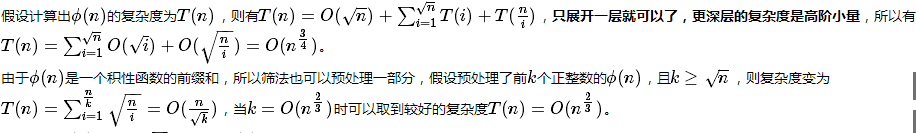
这个结论非常的神奇,因为看上去复杂度像是sqrt(n)*sqrt(n)=n的,有兴趣的话可以自己化简一下,时间复杂度的确是上述所说
2、求sigma(mu(i))
有了上面的经验,我们又知道e=mu*I
那么我们就可以直接写了
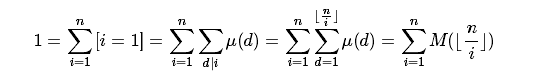
这样我们就机智的做出来了
唐老师的blog上还有一道题目,不过公式太长了,就不说了
有了上面学习的一些东西,我们就可以刷一些水题了
(感觉还是很好理解和学习的呢)
51Nod 莫比乌斯函数之和
直接套用上面的公式即可,但是真正写起来还是要注意一些事情的
由于杜教筛的时间复杂度的原因,通常情况下给定的n是超过int范围内,这就要求我们在计算过程中要时刻小心算术溢出
第二点是预处理多少比较合适,自己动手实验了一下,唐老师说的不错,大概预处理n^(2/3)较优
第三点就是在写的过程中要把每次递归计算好的函数用哈希表存进来实现记忆化,不然时间复杂度难以保证
#include<cstdio>
#include<iostream>
#include<cstdlib>
#include<algorithm>
#include<cstring>
using namespace std;
const int mod=1333331;
typedef long long LL;
LL a,b;
LL mu[5000010];
int p[500010],cnt=0;
bool vis[5000010];
struct HASHMAP{
int h[mod+10],cnt;
int next[100010];
LL st[100010],S[100010];
void push(LL k,LL v){
int key=k%mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return;
}
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
LL ask(LL k){
int key=k%mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
}H;
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=5000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>5000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}
for(int i=2;i<=5000000;++i)mu[i]+=mu[i-1];
}
LL mu_sum(LL n){
if(n<=5000000)return mu[n];
LL tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,A=1;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
A=A-(la-i+1)*mu_sum(n/i);
}H.push(n,A);return A;
}
int main(){
scanf("%lld%lld",&a,&b);
Get_Prime();
printf("%lld\n",mu_sum(b)-mu_sum(a-1));
return 0;
}
51Nod 欧拉函数之和
直接写就可以了
#include<cstdio>
#include<iostream>
#include<cstdlib>
#include<algorithm>
#include<cstring>
using namespace std;
const int mod=1333331;
typedef long long LL;
LL a,b;
LL mu[5000010];
int p[500010],cnt=0;
bool vis[5000010];
struct HASHMAP{
int h[mod+10],cnt;
int next[100010];
LL st[100010],S[100010];
void push(LL k,LL v){
int key=k%mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return;
}
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
LL ask(LL k){
int key=k%mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
}H;
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=5000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>5000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}
for(int i=2;i<=5000000;++i)mu[i]+=mu[i-1];
}
LL mu_sum(LL n){
if(n<=5000000)return mu[n];
LL tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,A=1;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
A=A-(la-i+1)*mu_sum(n/i);
}H.push(n,A);return A;
}
int main(){
scanf("%lld%lld",&a,&b);
Get_Prime();
printf("%lld\n",mu_sum(b)-mu_sum(a-1));
return 0;
}
BZOJ 3944 Sum
上面两道题目的混合版,唯一的坑点就是如果你想用int读入,在i=la+1的时候会有爆掉的风险
#include<cstdio>
#include<iostream>
#include<cstring>
#include<algorithm>
#include<cstdlib>
using namespace std;
typedef long long LL;
const int mod=1333331;
int T;
int p[500010],cnt=0;
bool vis[2000010];
LL mu[2000010],phi[2000010];
LL n;
struct HASHMAP{
int h[mod+10],cnt;
int next[3000010];
LL S[3000010],M[3000010],P[3000010];
void push(LL k,LL v1,LL v2){
int key=k%mod;
if(key<0)key+=mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return;
}
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;M[cnt]=v1;P[cnt]=v2;
}
pair<LL,LL>ask(LL k){
int key=k%mod;
if(key<0)key+=mod;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return make_pair(M[i],P[i]);
}return make_pair(-1,-1);
}
}H;
void Get_Prime(){
mu[1]=1;phi[1]=1;
for(int i=2;i<=2000000;++i){
if(!vis[i]){
p[++cnt]=i;
phi[i]=i-1;mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>2000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0){
phi[ip]=phi[i]*p[j];
break;
}mu[ip]=-mu[i];phi[ip]=phi[i]*(p[j]-1);
}
}
for(int i=2;i<=2000000;++i)phi[i]+=phi[i-1],mu[i]+=mu[i-1];
}
pair<LL,LL>sum(LL n){
if(n<=2000000)return make_pair(mu[n],phi[n]);
pair<LL,LL>tmp=H.ask(n);
if(tmp.first!=-1)return tmp;
LL A=1,B=1LL*n*(n+1)/2;LL la;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
tmp=sum(now);
A=A-1LL*tmp.first*(la-i+1);
B=B-1LL*tmp.second*(la-i+1);
}H.push(n,A,B);
return make_pair(A,B);
}
int main(){
scanf("%d",&T);
Get_Prime();
while(T--){
scanf("%lld",&n);
pair<LL,LL>ans=sum(n);
printf("%lld %lld\n",ans.second,ans.first);
}return 0;
}
hdu 5608
QAQ 标准的不能在标准的杜教筛形式
首先n^2-3n+2的前缀和我们可以O(1)的求出来(表告诉我你不会平方前缀和公式)
之后我们考虑如果预处理f,我们设g(n)=n^2-3n+2
可以得到g=f*I,进而得到g*mu=f*I*mu,则f=g*mu
我自己比较懒,并不知道f是不是积性函数(貌似不是)
然后直接O(nlogn)的贡献过去的,这样就可以预处理前100w的f了
之后运用杜教筛就可以O(n^(2/3))求出答案了
#include<cstdio>
#include<cstring>
#include<iostream>
#include<cstdlib>
#include<algorithm>
using namespace std;
const int mod=1e9+7;
const int MOD=1333331;
typedef long long LL;
int T,n,inv1,inv2;
bool vis[1000010];
int p[1000010],cnt=0;
int mu[1000010];
int f[1000010];
struct HASHMAP{
int h[MOD+10],cnt;
int next[3000010];
int S[3000010],st[3000010];
void push(int k,int v){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return;
}
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
int ask(int k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
}H;
int pow_mod(int v,int p){
int tmp=1;
while(p){
if(p&1)tmp=1LL*tmp*v%mod;
v=1LL*v*v%mod;p>>=1;
}return tmp;
}
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=1000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>1000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}return;
}
void Get_f(){
for(int i=1;i<=1000000;++i){
int now=(1LL*i*i-3*i+2)%mod;
int cnt=0;
for(int j=i;j<=1000000;j+=i){
cnt++;
f[j]=f[j]+now*mu[cnt];
if(f[j]<0)f[j]+=mod;
if(f[j]>=mod)f[j]-=mod;
}
}
for(int i=2;i<=1000000;++i){
f[i]+=f[i-1];
if(f[i]>=mod)f[i]-=mod;
}
return;
}
int sum(int n){
if(n<=1000000)return f[n];
int tmp=H.ask(n);
if(tmp!=-1)return tmp;
int A=1LL*n*(n+1)%mod*(2*n+1)%mod*inv1%mod;
A=A-3LL*n*(n+1)%mod*inv2%mod;
if(A<0)A+=mod;
A=A+2*n%mod;
if(A>=mod)A-=mod;
int la;
for(int i=2;i<=n;i=la+1){
int now=n/i;
la=n/now;
A=A-1LL*sum(n/i)*(la-i+1)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
int main(){
scanf("%d",&T);
Get_Prime();Get_f();
inv1=pow_mod(6,mod-2);
inv2=pow_mod(2,mod-2);
while(T--){
scanf("%d",&n);
printf("%d\n",sum(n));
}return 0;
}
51Nod 最大公约数之和
貌似网上并没有题解,那我就来发一份吧,没准能骗骗访问量
注意到这道题是n和n,不是n和m
我们不妨枚举最大公约数k
又因为我们知道(i,j)=k成立当且仅当(i/k,j/k)=1成立
然后我们就可以把原来的式子转化一下变成:
设P(n)=sigma(phi(i))
原式=2*sigma(k*P(n/k))-n*(n+1)/2
式子转化的正确性是显然的
这样我们利用杜教筛就可以求出P(n/k)的值
由于我们知道杜教筛求解所有n的约数k的所有的P(k)的值只需要O(n^(2/3))
所以我们在外面套上一个分块也不会影响时间复杂度
总时间复杂度O(sqrt(n)+n^(2/3))
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<cstdlib>
using namespace std;
const int mod=1e9+7;
const int MOD=1333331;
typedef long long LL;
int inv;
int p[500010],cnt=0;
int phi[5000010];
bool vis[5000010];
LL n;
struct HASHMAP{
int h[MOD+10],cnt;
int next[100010],st[100010];
LL S[100010];
void push(LL k,int v){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return;
}
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
int ask(LL k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
}H;
int pow_mod(int v,int p){
int tmp=1;
while(p){
if(p&1)tmp=1LL*tmp*v%mod;
v=1LL*v*v%mod;p>>=1;
}return tmp;
}
void Get_Prime(){
phi[1]=1;
for(int i=2;i<=5000000;++i){
if(!vis[i]){
p[++cnt]=i;
phi[i]=i-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>5000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0){
phi[ip]=phi[i]*p[j];
break;
}phi[ip]=phi[i]*(p[j]-1);
}
}
for(int i=2;i<=5000000;++i){
phi[i]+=phi[i-1];
if(phi[i]>=mod)phi[i]-=mod;
}return;
}
int sum(LL n){
if(n<=5000000)return phi[n];
int tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,k=n%mod;
int A=k*(k+1)%mod*inv%mod;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
A=A-(la-i+1)%mod*sum(now)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
int main(){
scanf("%lld",&n);
inv=pow_mod(2,mod-2);
Get_Prime();
LL la,ans=0;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
ans=ans+(i+la)%mod*(la-i+1)%mod*inv%mod*sum(now)%mod;
if(ans>=mod)ans-=mod;
}ans<<=1;if(ans>=mod)ans-=mod;
LL k=n%mod;
ans=ans-k*(k+1)%mod*inv%mod;
if(ans<0)ans+=mod;
printf("%lld\n",ans);
return 0;
}
BZOJ 4176
貌似是SDOI2015某道题的加强版?
接下来是一个悲伤的故事,故事的名称叫做不会用博客园写公式的代价
首先我们有一个结论:
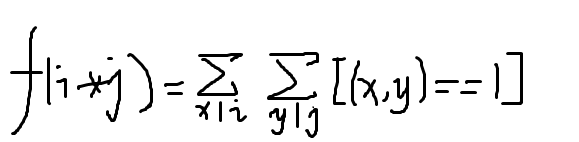
好吧,凑合着看吧,结论的证明我知道的有三种,其中最简单的一种是利用数学归纳法
然后式子就变成了(把e函数等价代换成mu函数)

然后我们枚举k,式子等价转换成
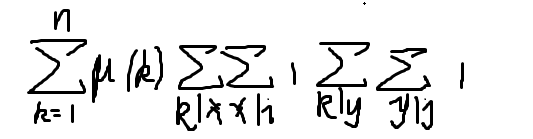
我们很容易发现中间那两个sigma连一起的奇怪的东西其实就是这个玩意
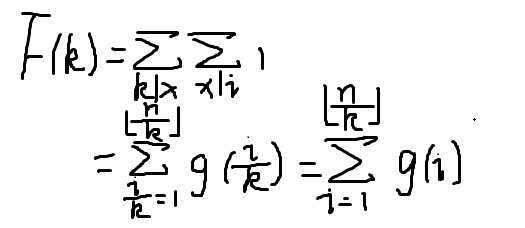
好了,终于不用在写这歪歪扭扭的公式了,结束了QAQ
g函数是约数个数函数,我们求约数个数函数的前缀和可以做到O(sqrt(n))
实际做法是枚举每个数i,(n/i)就是这个数对答案的贡献,分块求和即可
然后我们整体枚举k,做分块求和,某一段mu的和我们可以用杜教筛搞定
由于段的起点和终点都是n的约数,所以杜教筛的时间复杂度是O(n^(2/3))的
至于两次分块求和叠加看似是sqrt(n)*sqrt(n)=n的,但是根据上面的时间复杂度分析
时间复杂度是O(n^(3/4))的,到此这道题我们就做完了
(我一定要学会如何用blog写公式(太丑了,捂脸。。挖坑ing))
写这道题的时候我发现一个很逗的事情
就是我之前的题目的哈希表的push其实不用看之前有没有push过
直接push进去就好了,因为之前已经ask过发现并没有放进去了
代码在BZOJ上跑的还是很快的
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<cstdlib>
using namespace std;
const int mod=1e9+7;
const int MOD=1333331;
typedef long long LL;
int n,inv;
int mu[1000010];
bool vis[1000010];
int p[1000010],cnt=0;
struct HASHMAP{
int h[MOD+10],cnt;
int next[100010];
int S[100010],st[100010];
void push(int k,int v){
int key=k%MOD;
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
int ask(int k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
}H;
int pow_mod(int v,int p){
int tmp=1;
while(p){
if(p&1)tmp=1LL*tmp*v%mod;
v=1LL*v*v%mod;p>>=1;
}return tmp;
}
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=1000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>1000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}
for(int i=2;i<=1000000;++i)mu[i]+=mu[i-1];
}
int sum(int n){
if(n<=1000000)return mu[n];
int tmp=H.ask(n);
if(tmp!=-1)return tmp;
int la,A=1;
for(int i=2;i<=n;i=la+1){
int now=n/i;
la=n/now;
A=A-1LL*(la-i+1)*sum(now)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
int g(int n){
int la,A=0;
for(int i=1;i<=n;i=la+1){
int now=n/i;
la=n/now;
A=A+1LL*(la-i+1)*now%mod;
if(A>=mod)A-=mod;
}return 1LL*A*A%mod;
}
int main(){
scanf("%d",&n);
Get_Prime();inv=pow_mod(2,mod-2);
int la,ans=0;
for(int i=1;i<=n;i=la+1){
int now=n/i;
la=n/now;
ans=ans+1LL*(sum(la)-sum(i-1))*g(now)%mod;
if(ans>=mod)ans-=mod;
if(ans<0)ans+=mod;
}printf("%d\n",(ans%mod+mod)%mod);
return 0;
UPD:最近又做了几道51Nod的题目,公式推导不知道比上面的长到哪里去了
鉴于本人并不会用编辑器写公式,所以就只放代码了
51Nod 最小公倍数之和
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long LL;
const int mod=1e9+7;
const int MOD=1333331;
LL n,inv2,inv6;
bool vis[5000010];
int p[500010],cnt=0;
LL phi[5000010];
struct HASHMAP{
int h[MOD+10],cnt;
int next[100010];
LL S[100010],st[100010];
LL ask(LL k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
void push(LL k,LL v){
int key=k%MOD;
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
}H;
void Get_Prime(){
phi[1]=1;
for(int i=2;i<=5000000;++i){
if(!vis[i]){
p[++cnt]=i;
phi[i]=i-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*i*p[j]>5000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0){
phi[ip]=phi[i]*p[j];
break;
}phi[ip]=phi[i]*(p[j]-1);
}
}
for(int i=2;i<=5000000;++i){
phi[i]=phi[i]*i%mod*i+phi[i-1];
phi[i]%=mod;
}return;
}
LL pow_mod(LL v,LL p){
LL tmp=1;
while(p){
if(p&1)tmp=tmp*v%mod;
v=v*v%mod;p>>=1;
}return tmp;
}
LL Get_mod(LL v){return v%mod;}
LL S(LL n){
if(n<=5000000)return phi[n];
LL tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,A=Get_mod(n);
A=A*(A+1)%mod*inv2%mod;
A=A*A%mod;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
LL t1=Get_mod(la),t2=Get_mod(i-1);
t1=t1*(t1+1)%mod*((t1<<1)|1)%mod*inv6;
t2=t2*(t2+1)%mod*((t2<<1)|1)%mod*inv6;
t1=t1-t2;t1%=mod;if(t1<0)t1+=mod;
A=A-t1*S(now)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
int main(){
scanf("%lld",&n);
Get_Prime();
LL la,ans=0;
inv2=pow_mod(2LL,mod-2);
inv6=pow_mod(6LL,mod-2);
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
ans=ans+Get_mod(i+la)*Get_mod(la-i+1)%mod*inv2%mod*S(now);
ans%=mod;
}printf("%lld\n",ans);
return 0;
}
51Nod 平均最小公倍数
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long LL;
const int mod=1e9+7;
const int MOD=1333331;
int p[100010],cnt=0;
bool vis[1000010];
LL phi[1000010];
LL L,R,inv2,inv6;
struct HASHMAP{
int h[MOD+10],cnt;
int next[100010];
LL S[100010],st[100010];
LL ask(LL k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
void push(LL k,LL v){
int key=k%MOD;
++cnt;next[cnt]=h[key];h[key]=cnt;
S[cnt]=k;st[cnt]=v;
}
}H;
void Get_Prime(){
phi[1]=1;
for(int i=2;i<=1000000;++i){
if(!vis[i]){
p[++cnt]=i;
phi[i]=i-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*i*p[j]>1000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0){
phi[ip]=phi[i]*p[j];
break;
}
phi[ip]=phi[i]*(p[j]-1);
}
}
for(int i=2;i<=1000000;++i){
phi[i]=phi[i]*i%mod;
phi[i]+=phi[i-1];
if(phi[i]>=mod)phi[i]-=mod;
}return;
}
LL pow_mod(LL v,LL p){
LL tmp=1;
while(p){
if(p&1)tmp=tmp*v%mod;
v=v*v%mod;p>>=1;
}return tmp;
}
LL sum(LL n){
if(n<=1000000)return phi[n];
LL tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,A=n*(n+1)%mod*((n<<1)|1)%mod*inv6%mod;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
A=A-(i+la)*(la-i+1)%mod*inv2%mod*sum(now)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
LL Get_ans(LL n){
LL la,ans=0;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
ans=ans+(la-i+1)*sum(now)%mod;
if(ans>=mod)ans-=mod;
}ans+=n;if(ans>=mod)ans-=mod;
return ans*inv2%mod;
}
int main(){
scanf("%lld%lld",&L,&R);
inv2=pow_mod(2LL,mod-2);
inv6=pow_mod(6LL,mod-2);
Get_Prime();
printf("%lld\n",(Get_ans(R)-Get_ans(L-1)+mod)%mod);
return 0;
}
51Nod 最小公倍数计数
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<algorithm>
#include<cmath>
using namespace std;
typedef long long LL;
LL L,R;
int mu[1000010];
int p[1000010],cnt=0;
bool vis[1000010];
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=1000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>1000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}return;
}
LL S(LL n){
LL t1=0,t2=0,t3=0;
LL p1=(int)(pow(n,1.0/3.0)+0.00000001);
LL p2=(int)(sqrt(n));
for(LL i=1;i<=p1;++i){
t3++;
LL lim=n/i;
LL p3=(int)(sqrt(lim));
for(int j=i;j<=p3;++j){
t1=t1+(lim/j)-j+1;
}
}
for(LL i=1;i<=p2;++i)t2=t2+(n/(i*i));
t1=6LL*t1-3LL*t2-2LL*t3;
return t1;
}
LL Solve(LL n){
LL d=1,ans=0,sum,la;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;sum=0;
while(d*d<=la){sum+=mu[d];d++;}
if(sum)ans=ans+sum*S(now);
}ans+=n;ans>>=1;
return ans;
}
int main(){
scanf("%lld%lld",&L,&R);
Get_Prime();
printf("%lld\n",Solve(R)-Solve(L-1));
return 0;
}
51Nod 约数之和
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<cstdlib>
using namespace std;
typedef long long LL;
const int maxn=1000010;
const int mod=1e9+7;
const int MOD=1333331;
LL n,inv;
int mu[maxn];
int p[maxn],cnt=0;
bool vis[maxn];
struct HASHMAP{
int h[MOD+10],cnt;
int next[100010];
LL S[100010],st[100010];
LL ask(LL k){
int key=k%MOD;
for(int i=h[key];i;i=next[i]){
if(S[i]==k)return st[i];
}return -1;
}
void push(LL k,LL v){
int key=k%MOD;
++cnt;next[cnt]=h[key];h[key]=cnt;
st[cnt]=v;S[cnt]=k;
}
}H;
void Get_Prime(){
mu[1]=1;
for(int i=2;i<=1000000;++i){
if(!vis[i]){
p[++cnt]=i;
mu[i]=-1;
}
for(int j=1;j<=cnt;++j){
if(1LL*p[j]*i>1000000)break;
int ip=i*p[j];
vis[ip]=true;
if(i%p[j]==0)break;
mu[ip]=-mu[i];
}
}
for(int i=2;i<=1000000;++i){
mu[i]=1LL*mu[i]*i%mod;
mu[i]+=mu[i-1];
if(mu[i]>=mod)mu[i]-=mod;
}return;
}
LL pow_mod(LL v,LL p){
LL tmp=1;
while(p){
if(p&1)tmp=tmp*v%mod;
v=v*v%mod;p>>=1;
}return tmp;
}
LL sum(LL n){
if(n<=1000000)return mu[n];
LL tmp=H.ask(n);
if(tmp!=-1)return tmp;
LL la,A=1;
for(LL i=2;i<=n;i=la+1){
LL now=n/i;
la=n/now;
LL t1=(i+la)*(la-i+1)%mod*inv%mod;
A=A-t1*sum(now)%mod;
if(A<0)A+=mod;
}H.push(n,A);
return A;
}
LL f(LL n){
LL la,ans=0;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
ans=ans+(la-i+1)*now%mod*(now+1)%mod*inv%mod;
if(ans>=mod)ans-=mod;
}return ans;
}
LL g(LL n){
LL la,ans=0;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
ans=ans+(i+la)*(la-i+1)%mod*inv%mod*now%mod;
if(ans>=mod)ans-=mod;
}return ans;
}
int main(){
scanf("%lld",&n);
Get_Prime();
inv=pow_mod(2LL,mod-2);
LL la,ans=0;
for(LL i=1;i<=n;i=la+1){
LL now=n/i;
la=n/now;
LL t1=sum(la)-sum(i-1);
t1%=mod;if(t1<0)t1+=mod;
ans=ans+t1*f(now)%mod*g(now)%mod;
if(ans>=mod)ans-=mod;
}printf("%lld\n",ans);
return 0;
}
Em,总结一下吧
杜教筛具有非常明显的特征:
1、数据范围特征:10^9,10^10,10^11
2、能解决的问题是求解某个函数的前缀和或者一段区间的和
但是前提是其和I函数的狄利克雷卷积的前缀和是比较好求的
3、可以在预处理的情况下O(n^(2/3))的时间复杂度内求出O(sqrt(n))个值,也就是n的约数的所有值
因为有记忆化的存在,所以在计算时间复杂度的时候杜教筛不能简单的跟其他东西相乘来计算
4、一定不要忘记记忆化,一定不要忘记预处理
5、由于数据范围的特殊性,所以在计算过程中非常容易整数溢出
在写的时候一定要仔细分析之后在码,码完之后要通过对拍或者测极限数据等方法来检验
留下的一些坑:
51Nod 加权约数之和
BZOJ 3512

