
【搜索引擎Jediael开发笔记1】搜索引擎初步介绍及网络爬虫
详细可参考
(1)书箱:《这就是搜索引擎》《自己动手写网络爬虫》《解密搜索引擎打桩实践》
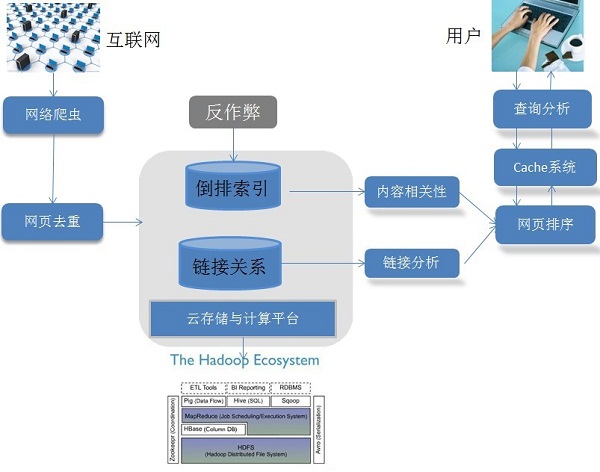
(一)搜索引擎的开发一般可分为以下三大部分
1、数据采集层:一般使用爬虫获取互联网的数据,重要的开源项目有Heritrxi
2、数据分析处理层:将从互联网上获取到的数据进行提取归类、分词、语义分析得出索引得内容,等待用户查询使用,重要的开源项目有Lucene
3、视图层:也用户的交互界面,如一个网站的首页
其基本架构可参考下图:
(二)网络爬虫的简介
下面例子将简单实现宽度优先搜索策略。
广度优先搜索策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页, 一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
还是以上面的图为例,抓取过程如下:
广度搜索过程:

首先访问页面v1 和v1 的邻接点v2 和v3,然后依次访问v2 的邻接点v4 和v5 及v3 的邻接点v6 和v7,最后访问v4 的邻接点v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由些完成了图的遍历。得到的顶点访问序列为:
和深度优先搜索类似,在遍历的过程中也需要一个访问标志数组。并且,为了顺次访问路径长度为2、3、…的顶点,需附设队列以存储已被访问的路径长度为1、2、… 的顶点。
(1)采用广度优先的原因:
重要的网页往往离种子站点距离较近;万维网的深度没有我们想象的那么深,但却出乎意料地宽(中文万维网直径长度只有17,即任意两个网页之间点击17次后便可以访问到);
宽度优先有利于多爬虫合作抓取;
(2)广度优先的存在不利结果:
容易导致爬虫陷入死循环,不该抓取的反复抓取;
应该抓取的没有机会抓取;
(3) 解决以上两个缺点的方法是深度抓取策略(Depth-First Trsversal)和不重复抓取策略
(4)为了防止爬虫无限制地宽度优先抓取,必须在某个深度上进行限制,达到这个深度后停止抓取,这个深度就是万维网的直径长度。当最大深度上停止抓取时,那些深度过大的未抓取网页,总是期望可以从其他种子站点更加经济地到达。限制抓取深度会破坏死循环的条件,即使出现循环也会在有限次后停止。
(5)评价: 宽度(广度)优先,兼顾深度的遍历策略,可以有效保证抓取过程中的封闭性,即在抓取过程(遍历路径)中总是抓取相同域名下的网页,而很少出现其他域名下的网页。

