
Spark Streaming的容错和数据无丢失机制
spark是迭代式的内存计算框架,具有很好的高可用性。sparkStreaming作为其模块之一,常被用于进行实时的流式计算。实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复。
在实际使用中,容错和数据无丢失显得尤为重要。最近看了官网和一些博文,整理了一下对Spark Streaming的容错和数据无丢失机制。
checkPoint机制可保证其容错性。spark中的WAL用来改进恢复机制,保证数据的无丢失。
checkPoint机制介绍
Spark Streaming需要checkpoint足够的信息到容错存储系统中, 以使系统从故障中恢复。有两种数据是需要checkpointed.
- Metadata checkpointing: 保存流计算的定义信息到容错存储系统,如HDFS中。这用来恢复应用程序中运行driver的故障。元数据包括:
- Configuration :创建Spark Streaming应用程序的配置信息
- DStream operations :定义Streaming应用程序的操作集合
元数据checkpoint主要是为了从driver故障中恢复数据。数据checkpoint能节省RDD恢复性能。
WAL介绍
对于一些文件的数据源,driver的恢复机制可以保证数据无丢失,因为所有的数据都保存在HDFS或S3上面,对于一些像kafka,flume等数据源,接收的数据保存在内存中将有可能丢失,这是因为spark应用分布式运行的,如果driver进程挂了,所有的executor进程将不可用,保存在这些进程所持有内存中的数据将会丢失。为了避免这些数据的丢失,spark streaming中引入了一个write ahead logs。
WAL在文件系统和数据库中用于数据操作的持久化,先把数据写到一个持久化的日志中,然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。对于像kafka和flume这些使用接收器来接收数据的数据源。接收器作为一个长时间的任务运行在executor中,负责从数据源接收数据,如果数据源支持的话,向数据源确认接收到数据,然后把数据存储在executor的内存中,driver在exector上运行任务处理这些数据。
如果wal启用了,所有接收到的数据会保存到一个日志文件中去(HDFS), 这样保存接收数据的持久性,此外,如果只有在数据写入到log中之后接收器才向数据源确认,这样drive重启后那些保存在内存中但是没有写入到log中的数据将会重新发送,这两点保证的数据的无丢失。
当一个Spark Streaming应用启动了, 相应的StreamingContext使用SparkContet去启动receiver,receiver是一个长时间执行的作业,这些接收器接收并保存这些数据到Spark的executor进程的内存中,这些数据的生命周期如下图所示
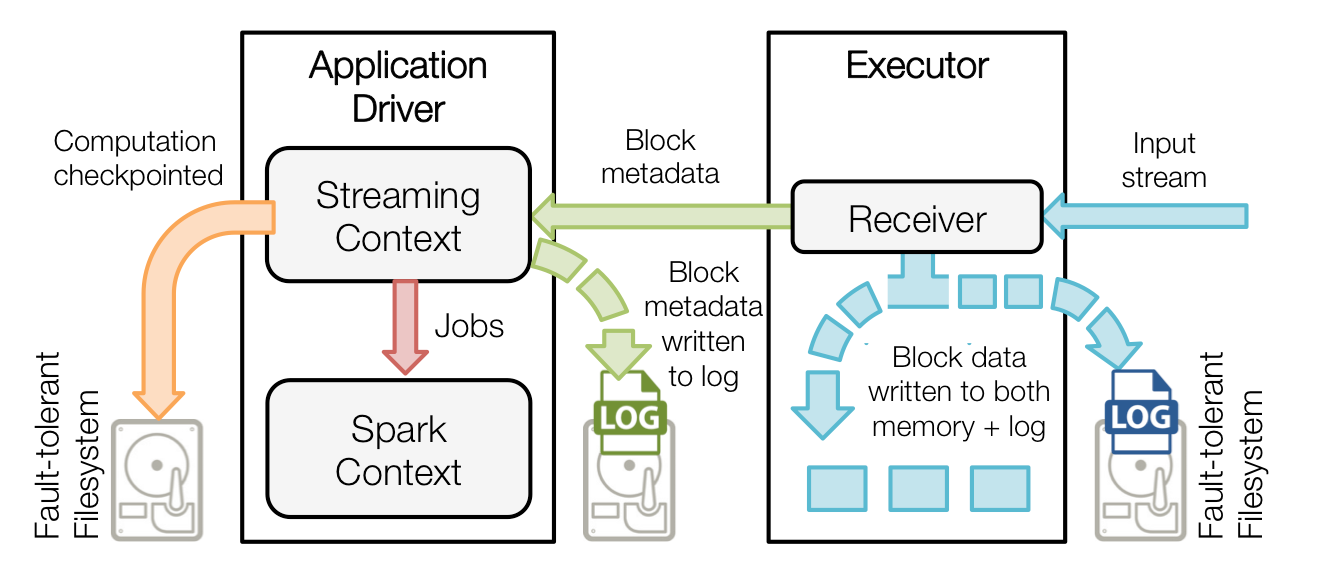
1)蓝色的箭头表示接收的数据,接收器把数据流打包成块存储在的内存中,如果开启了WAL,将会把数据写入到存在容错文件系统的日志文件中
2)青色的箭头表示提醒driver, 接收到的数据块的元信息发送给driver中的StreamingContext, 这些元数据包括:executor内存中数据块的引用ID和日志文件中数据块的偏移信息
3)红色箭头表示处理数据,每一个批处理间隔,StreamingContext使用块信息用来生成RDD和jobs. SparkContext执行这些job用于处理executor内存中的数据块
4)黄色箭头表示checkpoint这些计算,以便于恢复。流式处理会周期的被checkpoint到文件中
当一个失败的driver重启以后,恢复流程如下

1)黄色的箭头用于恢复计算,checkpointed的信息是用于重启driver,重新构造上下文和重启所有的receiver
2)青色箭头恢复块元数据信息,所有的块信息对已恢复计算很重要重新生成未完成的job(红色箭头),会使用到恢复的元数据信息
3)读取保存在日志中的块(蓝色箭头),当job重新执行的时候,块数据将会直接从日志中读取
4)重发没有确认的数据(紫色的箭头)。缓冲的数据没有写到WAL中去将会被重新发送。


