urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务。
1、urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的。安装方式:pip install beautifulsoup4
其官方文档中文版地址:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
2、爬取任务:爬取的内容为每部电影的名字 导演 主演 年代 国家 类型 评分 评分人数
3、展示方法:(1)、直接打印 (2)、存到Mysql数据库
4、分析:
网站布局:1、Top250共10页 每页25部电影 网站格式:https://movie.douban.com/top250?start=[0,25,50,75,100,125,150,175,200,225] 每一个数字代表一行
对其中一部电影进行分析:
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a><span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>765942人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
主要部分在 div class='article'下的 ol class='grid_view'中的 li里面。各个信息都可以在这里面找到。
《一》利用BeautifulSoup的find函数,可以轻松的实现打印功能,保存到本地csv中:
代码如下:
#-*- encoding:utf-8 -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.error import HTTPError
import re
import csv
####本程序为爬取豆瓣电影Top250 ,先放在本地txt文档中,后续放到Mysql中
####本程序为bs4,后续改为Scrapy
###爬取的内容为每部电影的名字 导演 主演 年代 国家 类型 评分 评分人数 。。。
"""分析部分: 网站布局:1、Top250共10页 每页25部电影 网站格式:https://movie.douban.com/top250?start=
"""
def crawl(baseurl,bias):
try:
html=urlopen(baseurl+'?start=%d' %bias)
except HTTPError:
return None
bsObj=BeautifulSoup(html,'lxml')
totalContent=bsObj.find('ol',{'class':'grid_view'}).findAll('li')###每一页25个电影的全部信息
retList=[]
for eachMovie in totalContent:
rank=eachMovie.em.get_text() ###获取排名
href=eachMovie.a['href'] ####获取到连接地址
nameList=eachMovie.find_all('span',{'class':'title'})
Chinesename=nameList[0].get_text() ### 中文名字
if(len(nameList)==2):
Englishname=nameList[1].get_text() ##英文名字
else:
Englishname="None"
othername=eachMovie.find('span',{'class':'other'}).get_text().replace('/','')
relate=eachMovie.find('p',{'class':''}).get_text().replace(' ','') ###主演,导演等信息 需要分割处理
rating=eachMovie.find('span',{'class':'rating_num','property':'v:average'}).get_text() ##评分
starDiv=eachMovie.find('div',{'class':'star'})
ratingN=starDiv.find_all('span')[3].get_text()
ratingNum=re.split(r"\D",ratingN)[0] ####评价的人数
try:
abstract=eachMovie.find('span',{'class':'inq'}).get_text()
except AttributeError:
abstract="None"
OutputStr="排名: "+rank+'\t网址: '+href+'\t中文名: '+Chinesename+'\t英文名: '+Englishname+'\t别名: '+othername+\
'\t评分: '+rating+'\t评价人数: '+ratingNum+'\t摘要: '+abstract+"\t"+'相关信息:'+relate
print(OutputStr)
eachList=[rank,href,Chinesename,Englishname,othername,rating,ratingNum,abstract,relate]
retList.append(eachList)
return retList
def storeToCsv(AttributeList):
csvFile=open('res.csv','a+',encoding='utf-8')
try:
writer=csv.writer(csvFile)
writer.writerow(('排名',"网址",'中文名','英文名','别名','评分','评价人数','摘要','相关信息'))
for i in range(10):
for j in range(25):
writer.writerow(AttributeList[i][j])
finally:
csvFile.close()
if __name__=='__main__':
url='https://movie.douban.com/top250'
biasList=[0,25,50,75,100,125,150,175,200,225]
allList=[]
for eachBias in biasList:
s=crawl(url,eachBias)
allList.append(s)
storeToCsv(allList)
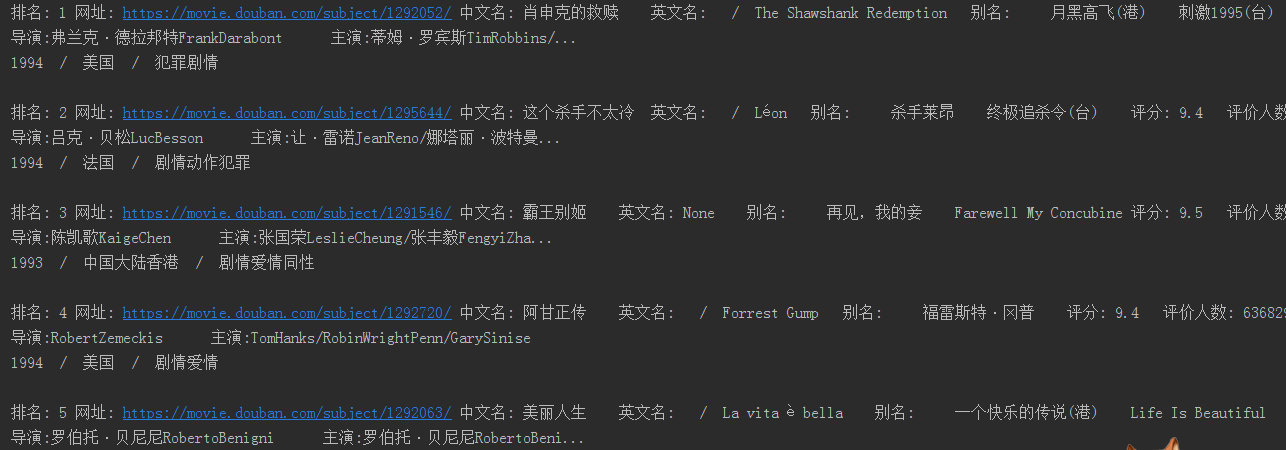
运行结果如下图: