Python文件读取编码错误问题解决之(PyCharm开发工具默认设置的坑。。。)
刚接触Python学习,正准备做个爬虫的例子,谁知道代码一开始就遇到了一个大坑,狂汗啊。
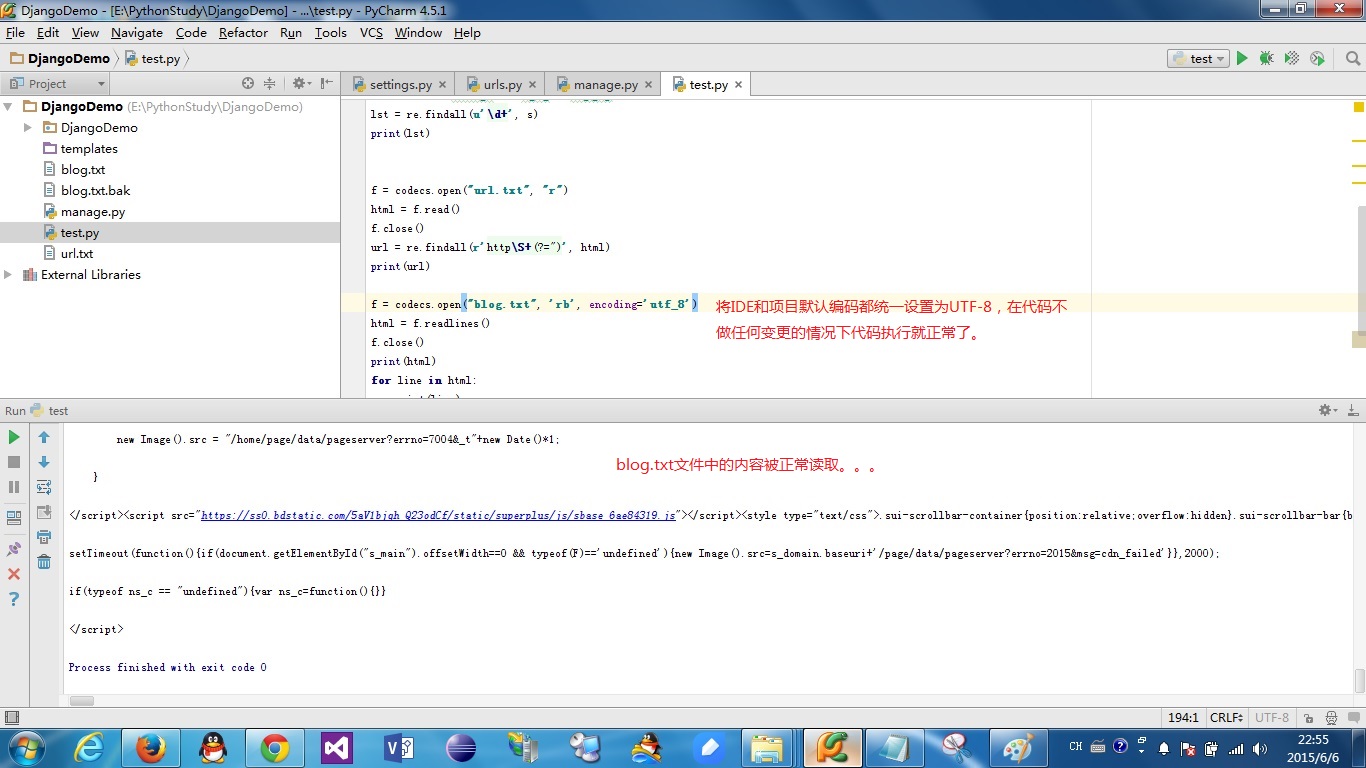
问题是这样的:我通过代码爬取了博客园首页的HTML代码并存入到blog.txt文件当中,然后准备读取出来之后进行分析,可就在读取文件的这一步出现了问题。
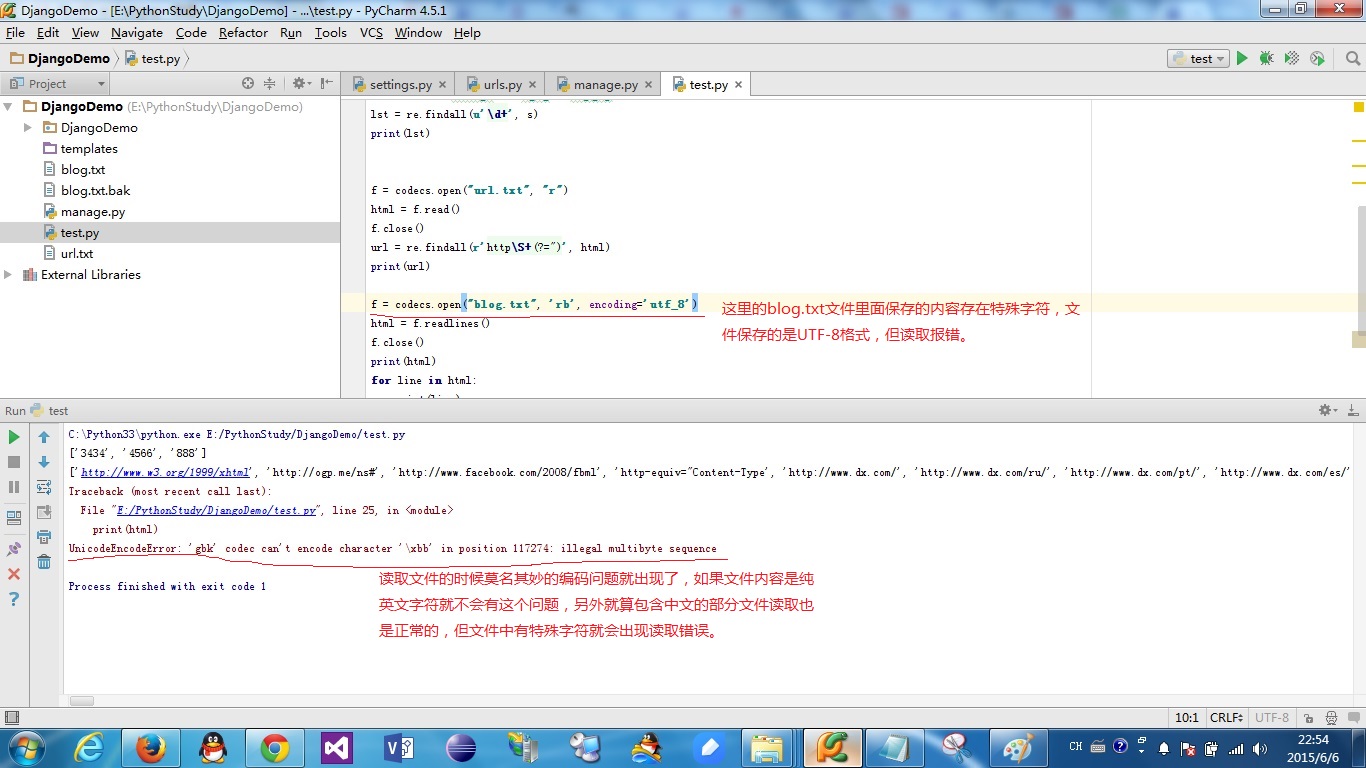
执行读取代码的时候程序总是会抛一个叫 “UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 117274: illegal multibyte sequence”的异常。
刚开始以为是简单的编码问题,又是在代码中设置编码格式,又是百度谷歌的。可是,没找到一个靠谱的解决方案,问题依然存在。
折腾了好几天实在是没办法了,后来突然想到会不会和IDE的设置有关系(我使用的IDE是PyCharm)。呵呵,折腾一番还真的解决了。
错误截图:
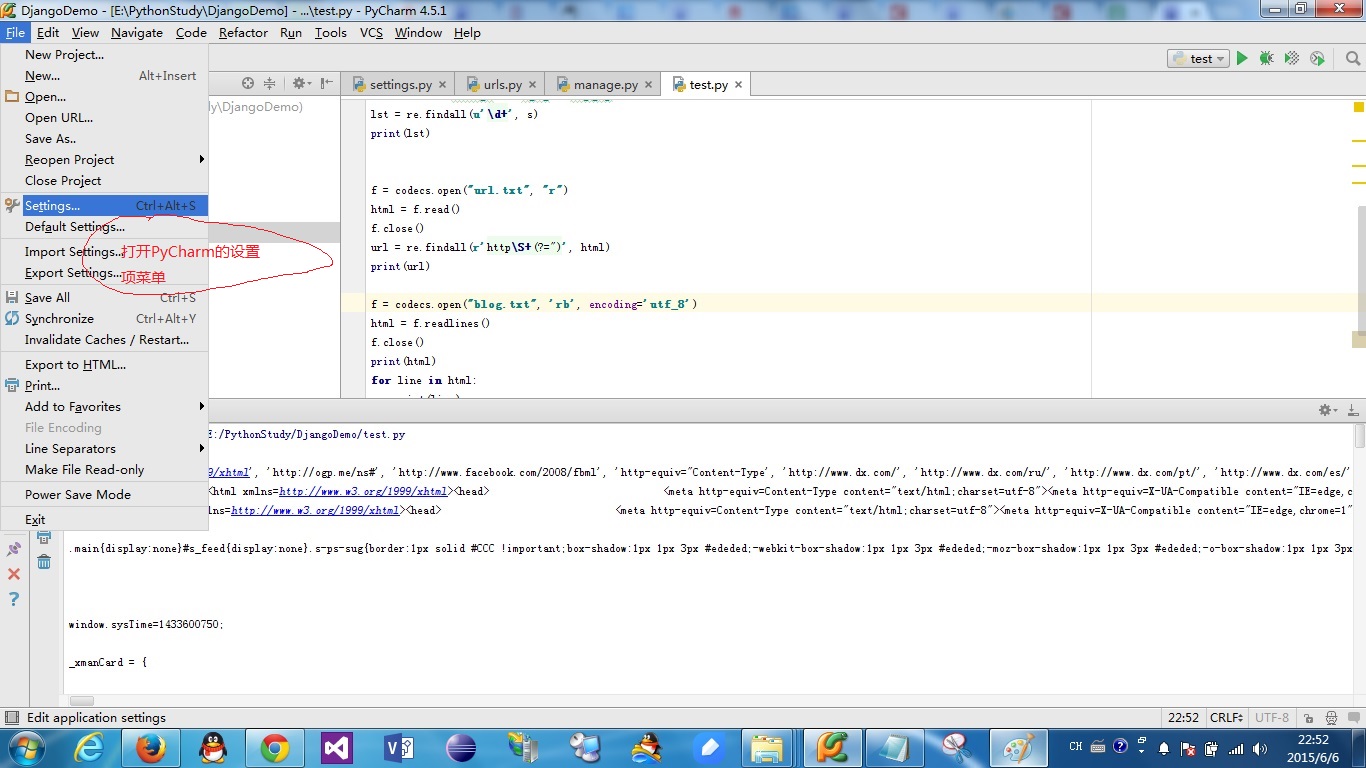
步骤一:打开IDE的设置选项
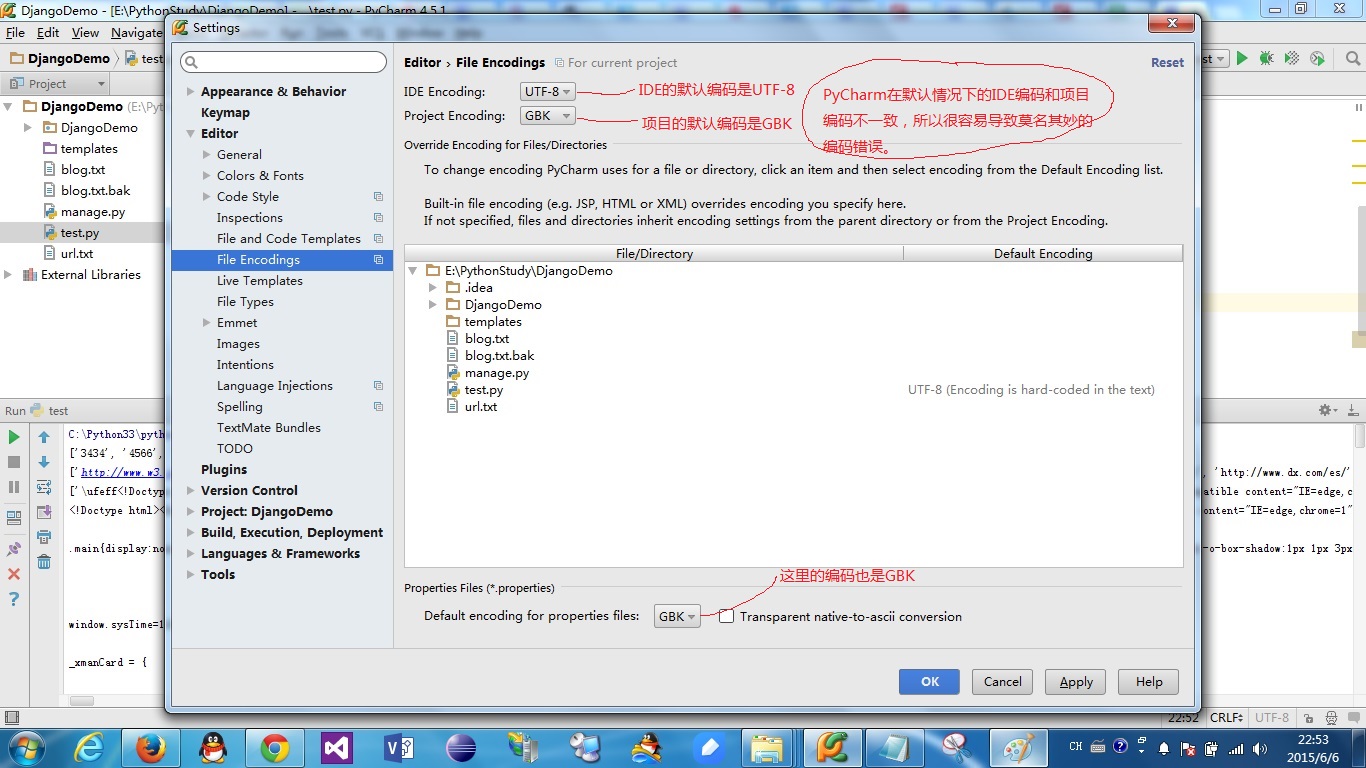
步骤二 查看编码设置,并将所有设置都设置为UTF-8
步骤三 编码设置完后重新执行代码,问题解决