
sersync简介与测试报告
2013-06-28 18:38 御云 阅读(1271) 评论(0) 编辑 收藏 举报在分布式应用中会遇到一个问题,就是多个服务器间的文件如何能始终保持一致。一种经典的办法是将需要保持一致的文件存储在NFS上,这种方法虽然简单方便但却将本来多点的应用在文件存储上又变成了单点,这违背了分布式应用部署的初衷。为了保留多点特性,文件仍然保存在各服务器上,那就需要在每个服务器中保持文件的同步。
服务器同步的解决方案有很多。比较流行的有inotify-tools+rsync和Openduckbill(依赖于inotify-tools)。现在介绍一个解决方案sersync,相对上面两个项目有以下优点:
- sersync是使用c++编写,而且对linux系统文件系统产生的临时文件和重复的文件操作进行过滤,所以在结合rsync同步的时候,节省了运行时耗和网络资源。因此更快。
- sersync配置起来很简单,其中bin目录下已经有基本上静态编译的2进制文件,配合bin目录下的xml配置文件直接使用即可。
- 使用多线程进行同步,尤其在同步较大文件时,能够保证多个服务器实时保持同步状态。
- 有出错处理机制,通过失败队列对出错的文件重新同步,如果仍旧失败,则按设定时长对同步失败的文件重新同步。
- 自带crontab功能,只需在xml配置文件中开启,即可按要求隔一段时间整体同步一次。无需再额外配置crontab功能。
- 能够实现socket与http插件扩展。
1.sersync的安装与配置
sersync的安装非常简单,将从https://code.google.com/p/sersync/上下载的文件解压就可以了,无需编译。
wget http://sersync.googlecode.com/files/sersync2.5.4_64bit_binary_stable_final.tar.gz mkdir sersync tar zxvf sersync2.5.4_64bit_binary_stable_final.tar.gz -C sersync cd sersync/GNU-Linux-x86
解压后的文件有sersync2和confxml.xml,sersync2是执行文件,confxml.xml是默认的配制文件(可以用-o参数指定配制文件)。
由于sersync需要结合rsync作同步,所以在目标机上必须配置rsync并启动rsync的守候进程,主服务器上只有rsync就行了无需配置。
启动sersync的命令如下:
./sersync -d
如果需要先整体同步一次可以加-r参数,也可以用-n参数指定线程数(默认10线程)如下:
./sersync -n 5 -d
sersync的配制文件比较简单,大多数配置项保留默认的即可(详细配置项含义参考http://blog.johntechinfo.com/technology/96)。这里只说明必须要改动的参数如下:
<localpath watch="/opt/tongbu"> <remote ip="127.0.0.1" name="tongbu1"/> <!--<remote ip="192.168.8.39" name="tongbu"/>--> <!--<remote ip="192.168.8.40" name="tongbu"/>--> </localpath>
其中watch属性是主服务器需要同步的目录(当前是/opt/tongbu可以改成实际需要维持同步的目录);remote元素表示远程需要同步到的服务器信息,ip属性是远程服务器的IP,name属性是远程服务器上rsync的同步目录。remote元素可以有多个,这样就可以同步多个远程服务器的文件了。不过localpath元素只能有一个(写多个也只有第一个起作用),这意味着只能监控主服务器上的一个目录(及其子目录),不过如果需要监控多个目录的话,可以写多个配置文件,每个配制文件配制各自需要同步的目录,启动多个sersync进程(加-o参数对应各个配制文件)即可。
2.sersync的测试
2.1测试环境
主服务器:虚拟机、4核CPU、4G内存
目标服务器A:物理机、1核CPU、4G内存
目标服务器B:虚拟机、4核CPU、8G内存
2.2测试方案和过程
方案1:for循环生成文件10万个,sersync 10线程,主服务器同步到服务器B
生成文件共394M,平均每文件4K。生成文件耗时9秒,服务器B延迟时间(同步完成时间比生成文件的结束时间晚)13秒。
主服务器负载如下:
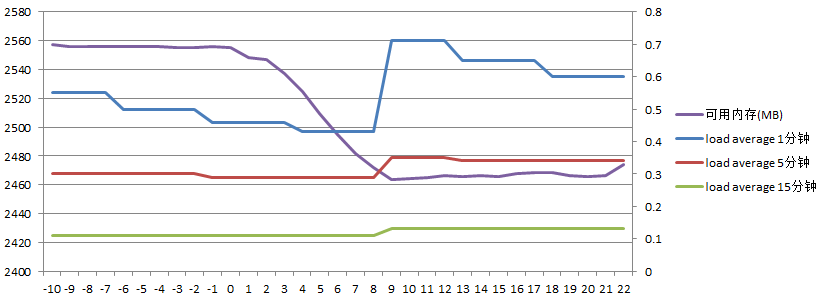
(模坐标表示时间,单位为秒,0表示开始生成文件的时刻。左纵坐标表示可用内存MB,右纵坐标为load average。下同)
可以看到在同步过程中可用内存大约减少了100M内存,而load average始终维持在较低水平。
服务器B负载如下:
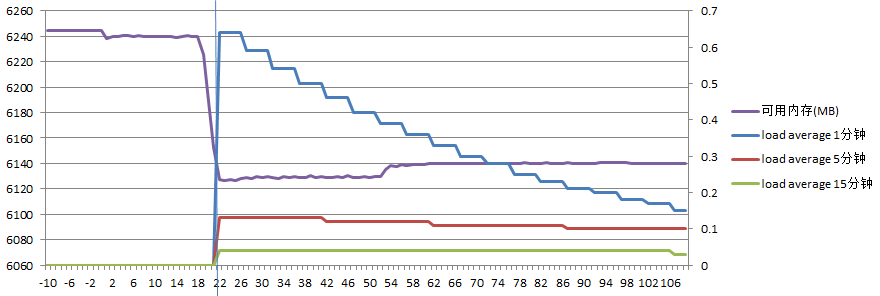
(图中蓝色竖线表示同步完成的时刻,下同。由于同步时间较短,load average在同步结束后才反应出来)
可以看到在同步过程中可用内存大约减少了110M内存,同样load average也始终维持在较低水平。
方案2:for循环生成文件10万个,sersync 10线程,主服务器同步到服务器A和B
生成文件共394M,平均每文件4K。生成文件耗时10秒,服务器A延迟时间为26秒,服务器B延迟时间为24秒。
主服务器负载如下:
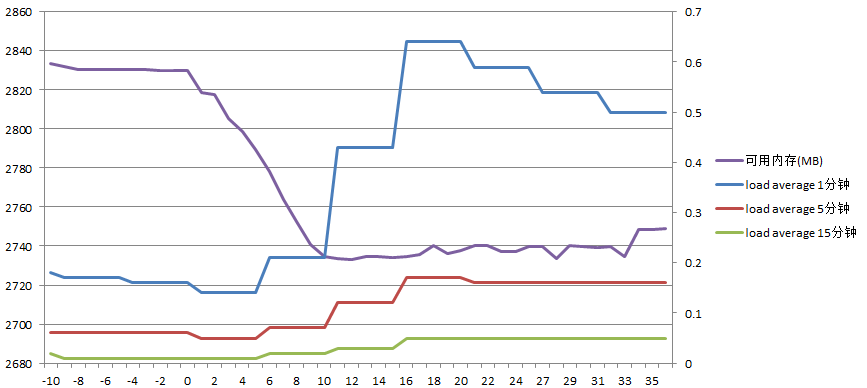
可以看到在同步过程中可用内存仍是大约减少100M内存,而load average始终维持在较低水平。
服务器A负载如下:
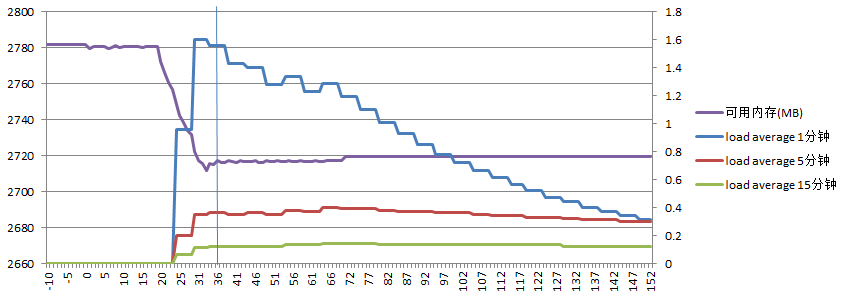
可以看到在同步过程中可用内存大约减少了60M内存,load average最高达到1.6,这应该是由于服务器A的配置较低的原因。
服务器B负载如下:

可以看到在同步过程中可用内存大约减少了100M内存,load average最高都不到0.08,这应该是由于服务器B的配置较高的原因。
结论一:同步两台目标服务器,每台目标服务器的延迟时间都会比只同步一台服务器花费的时间要多。
方案3:复制大量文件,sersync 10线程,主服务器同步到服务器A
复制文件31930个,共345M,平均每个文件11K。服务器A延迟(同步完成时间比开始复制时间晚)77秒。
主服务器负载如下:
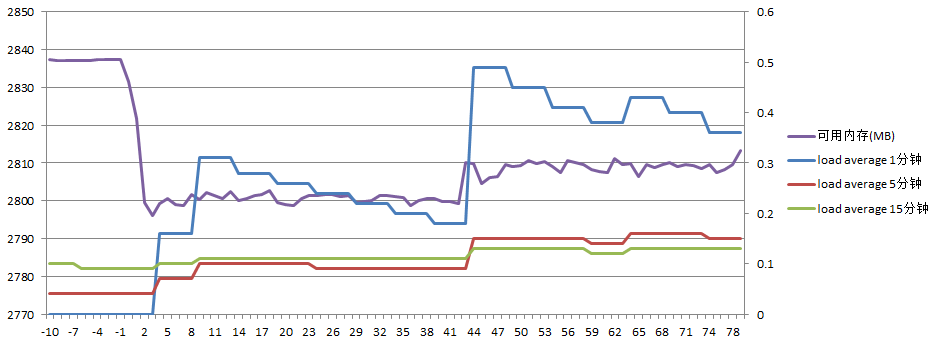
(模坐标表示时间,单位为秒,0表示开始复制文件的时刻。下同)
可用内存先大约减少40M,后又增长了10M,load average最高0.5
服务器A负载如下:

可用内存大约减少30M,load average最高2.3
方案4:复制大量文件,sersync 2线程,主服务器同步到服务器A
复制文件31930个,共345M,平均每个文件11K。服务器A延迟240秒。
主服务器负载如下:
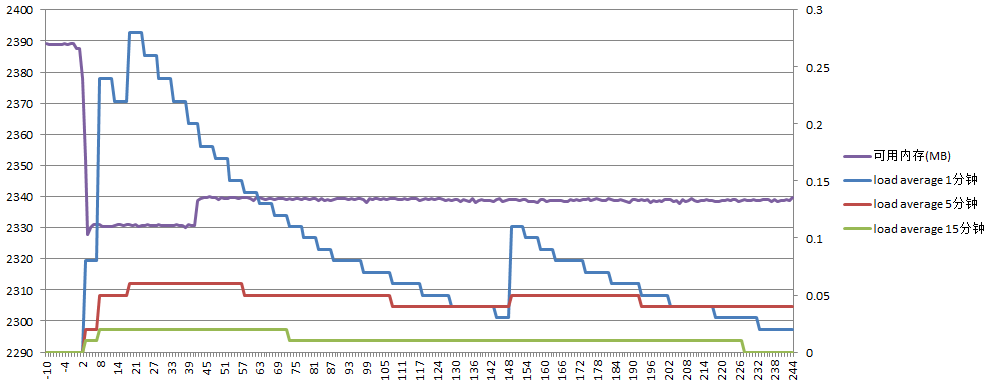
可用内存先大约减少60M,后又增长了10M,load average最高0.28
服务器A负载如下:
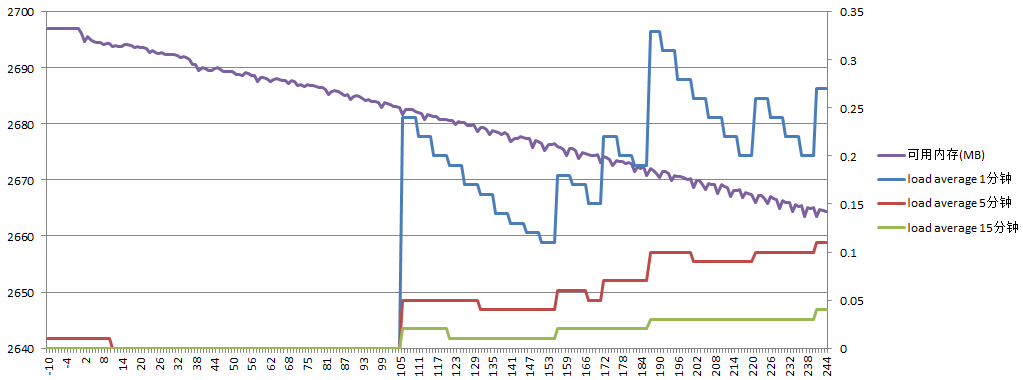
可用内存大约减少30M,load average最高0.33
结论二:将sersync线程数从10减少到2,延迟时间大为增加,占用内存变化不大,但load average明显降低。
方案5:模拟实际项目中在主服务器上生成页面,sersync 10线程,同步到服务器B
生成文件38366个,共152M,平均每文件4K。由于是模拟实际项目生成页面,生成页面的耗时较多,共73分钟,同步到服务器B延迟168秒。
主服务器负载如下:
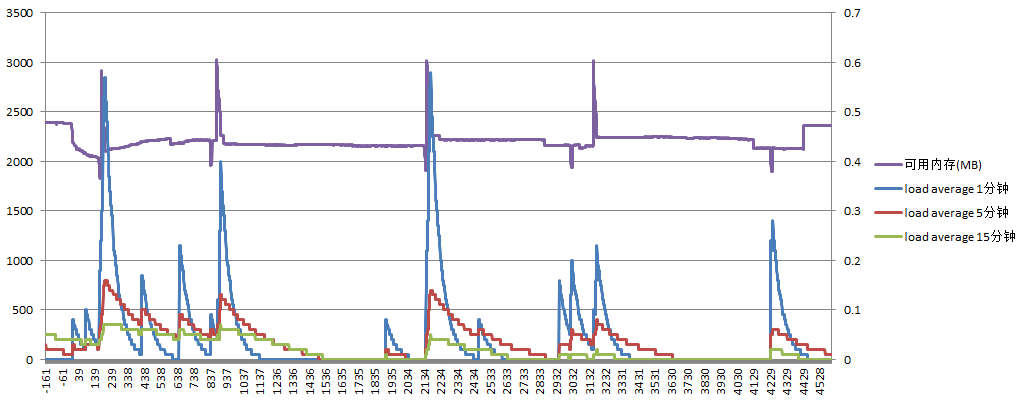
可用内存与load average有相同的波锋,这可能是和用实际的项目代码生成页面有关,但由于生成页面文件耗时较长,load average始终保持在较低水平。
服务器B负载如下:
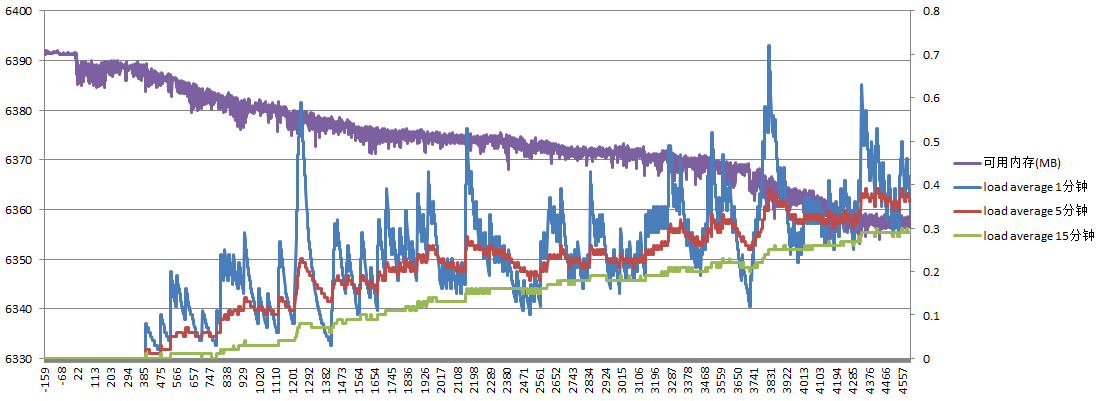
可用内存大约减少35M,load average始终维持在较低水平
结论三:在实际项目中由于生成文件速度一般不会非常快,总耗时较多,导致load average始终维持在较低水平
方案6:在主服务器上用rm -rf删除大量文件,sersync 10线程,同步到服务器A
删除文件数量31930个,共345M,平均每个文件11K。服务器A延迟125秒。
主服务器负载如下:
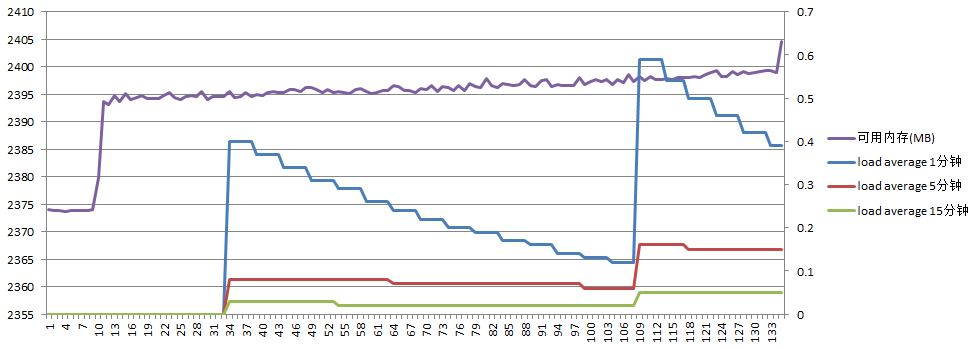
可用内存增加了25M;load average最高0.6
服务器A负载如下:
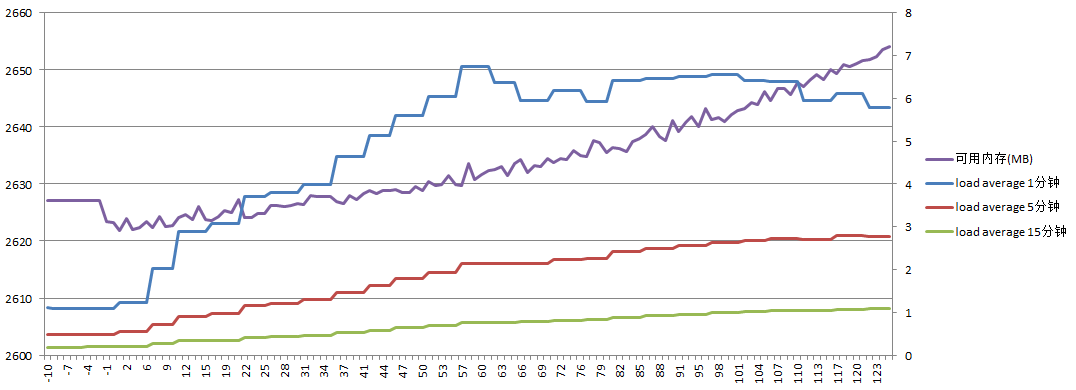
可用内存增加了25M;load average最高达到7.3,这是因为虽然主服务器只是做了rm -rf删除,但通过inotify通知的删除动作却非常多

