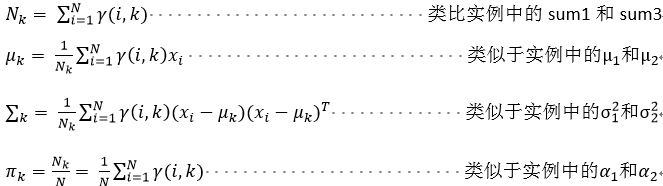4-EM算法原理及利用EM求解GMM参数过程
1.极大似然估计
原理:假设在一个罐子中放着许多白球和黑球,并假定已经知道两种球的数目之比为1:3但是不知道那种颜色的球多。如果用放回抽样方法从罐中取5个球,观察结果为:黑、白、黑、黑、黑,估计取到黑球的概率为p;
假设p=1/4,则出现题目描述观察结果的概率为:(1/4)4 *(3/4) = 3/1024
假设p=3/4,则出现题目描述观察结果的概率为:(3/4)4 *(1/4) = 81/1024
由于81/1024 > 3/1024,因此任务p=3/4比1/4更能出现上述观察结果,所以p取3/4更为合理
以上便为极大似然估计的原理
定义如下图:(图片来自浙江大学概率论课程课件)


2.知晓了极大似然估计的原理之后,我们可以利用极大似然估计的原理来解决如下问题:
即,若给定一圈样本x1,x2.....xn,已知他们服从高斯分布N(μ,σ),要求估计参数均值μ,标准差σ
(1) 高斯分布的概率密度为:
![]()
(2) 利用上述极大似然估计的原理,构建似然函数为:
![]()
(3) 为例求解方便我们取对数似然:
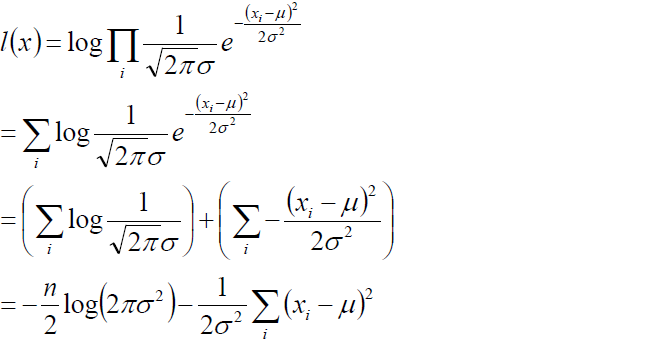
(4) 我们的目标是求上述l(x)的最大值,对上式,分别关于μ,σ求二阶导数,很容易证明2次倒数均小于0 ,所以上述函数关于μ,和σ均为凹函数,极大值点满足一阶导数等于0,故通过对μ,和σ求偏导并且倒数为0 我们即可得到如下等式:
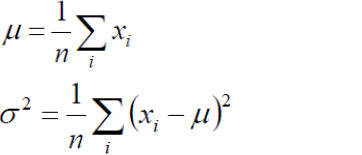
3.EM算法原理推导
3.1 EM算法与极大似然估计的区别于联系(直接饮用李航-统计学习方法中的内容)
概率模型有时即含有观测变量,又含有隐变量或潜在变量,如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计法,或者贝叶斯估计法估计模型参数。但是当模型含有隐量时,就不能简单的用这些估计方法,EM算法就是含有隐变量的概率模型参数的极大似然估计法
什么是隐变量?
举例:比如现要在一所学校中随机选取1000个人测量身高,最终我们会得到一个包含1000个身高数据的数据集,此数据集就称为观测变量,那这1000个学生中,既有男生又有女生,我们在选取完成以后并不知道男生和女生的比例是多少?此时这1000名学生中男生的占比以及女生的占比就称为隐变量
3.2 有了上述简单的认识之后,下边解决EM算法的推导过程
在对EM算法原理进行推导之前,先用一个实例理解一下下文中θ所表示的意义:
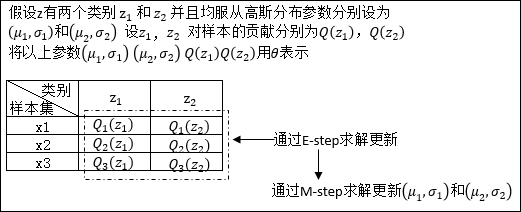
假设现有样本集T= {x1,x2 .....xm},包含m个独立样本,其中每个样本对应的类别z(这里的类别z就可以类比3.1中的男生女生两种性别去理解)是未知的,所以很难直接用极大似然法去求解。
以x1为例:x1发生的概率可以表示为:![]() ,θ表示的就是我们要估计的参数的一个总称后续证明过程中的Q(z)也是θ中的一个参数。举例,如果每一个类别z均符合高斯分布,那么θ中还会包含均值μ和标准差σ,如果对θ的理解不是不到
,θ表示的就是我们要估计的参数的一个总称后续证明过程中的Q(z)也是θ中的一个参数。举例,如果每一个类别z均符合高斯分布,那么θ中还会包含均值μ和标准差σ,如果对θ的理解不是不到
整个数据集T的似然函数可以表示为:
![]()
为了便于计算我们取对数似然得:
![]()
对上上述函数log中有求和运算,求解困难,故我们可以对其形式进行转化,转化为易于我们求解的方式如下式: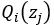 表示第i个样本第j个类别的概率,则
表示第i个样本第j个类别的概率,则![]() 表示
表示![]() 的期望
的期望
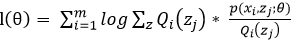
log函数是一个凹函数,故利用jenson不等式的原理可以得出期望的函数值大于等于函数值的期望,故表达如下:

![]() 在上述不等式的等号成立时和
在上述不等式的等号成立时和![]() 是等价的,也就是说后式的最大值即为前式的最大值。当log函数的图像是一条直线时等号成立,故
是等价的,也就是说后式的最大值即为前式的最大值。当log函数的图像是一条直线时等号成立,故![]() 为常数时,等号成立。
为常数时,等号成立。
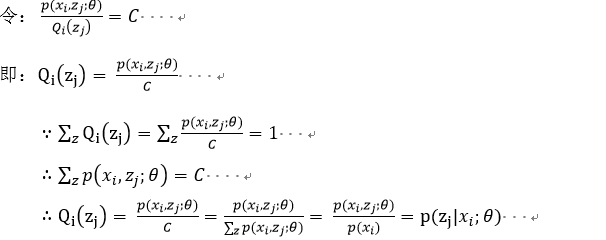
#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#
E-step:即就是上述的![]()
M-step:在E-step的基础上求使得上述函数值的期望取得最大值的参数θ的取值
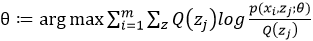
#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#-#
对上述E-step和M-step不断进行迭代,知道我们估计的模型参数收敛(即变化趋近于一个定值)我们即可得到最适合观测数据集的模型参数,者便是EM算法
4.利用EM原理推导GMM(混合高斯模型)
随机变量X是有K个高斯分布混合而成,取各个高斯分布的概率为φ1,φ2...φK,第i个高斯分布的均值为μi,方差为Σi。若观测到随机变量X的一系列样本x1,x2...xn,试估计参数φ,μ,Σ。
第一步:依据3中E-step估计φ用wj(i) 表示,意义是对第i个样本第j个高斯分布的贡献率(即第j个高斯分布的占比)
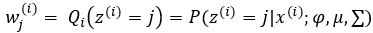
第二步:依据3中的M-step估计μ,和σ 用 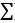 表示σ2
表示σ2
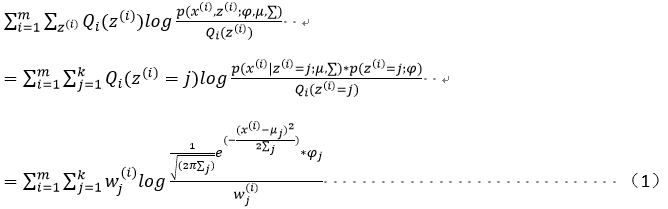
对上述关于μ求偏导得:

对(2)式为0 可得:
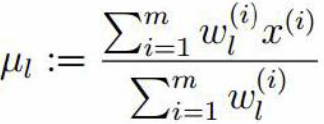
同理对方差求偏导,并令导入为0 可得:
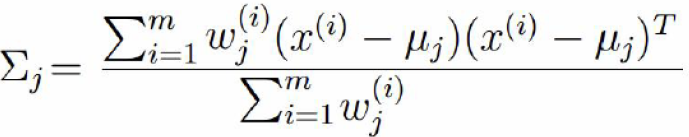
对于φj 由于 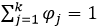 ,故对于φj 必须采用添加极值的方式求解,需构建拉个朗日方程进行求解。
,故对于φj 必须采用添加极值的方式求解,需构建拉个朗日方程进行求解。
观察(1)式,log函数中可以看成是一个常数与φj相乘。由对数函数求导法则指,在求导之后,常数项终被抵消,如f(x) = lnax 关于x求导结果与g(x)=lnx关于x求导结果相同,故对于(1)式在构建拉个朗日函数时,直接去掉log函数中的常数项,如下:
由于φj 为正在log函数中已有现值,故这里无需构建不等式约束
![]()
对朗格朗日函数关于φj求导并取倒数为0 可得:
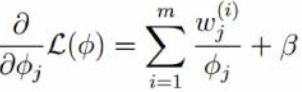
![]()
![]()
5.用实例理解GMM的参数估计过程
5.1 在正式引入GMM(混合高斯模型)前我们以下述情景的求解为例,用实例看先熟悉以下参数更新的过程
情景:假设从商场随机选取10位顾客,测量这10位顾客的身高,这些顾客中既包含男性顾客也包含女性顾客,现在我们已知测量数据,T=[x1,x2 .....x10]为我们测试的身高数据,即为可观测数据集。并且知道男性女性顾客的身高均服从高斯分布N(μ1,σ1),N(μ2,σ2),估计参数μ1,σ1,μ2,σ2 ,以及男女比例 α1,α2;
高斯分布的概率密度函数为:
![]()
(1)对于测试数据x1 其产生的概率我们可以表示为:
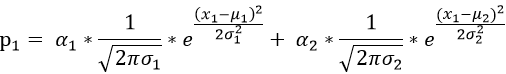
我们用γ(i,k)来表示男性或者女性在生成数据x1 时所做的贡献(γ(i,k)就相当于我们初始给定的α1,α2)。或者说表示单由男性或者女性产生数据xi的概率,前后两个说法所想表达的意思是相同的,那么就有:
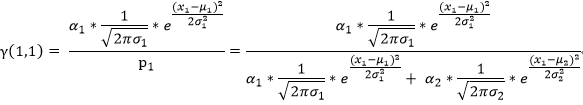
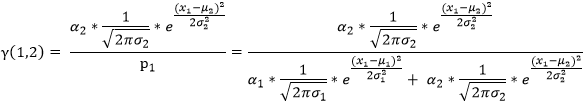
(2)对于测试数据x2 其产生的概率我们可以表示为:
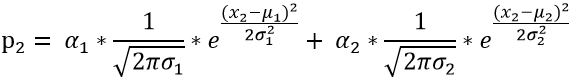
同(1)可知:
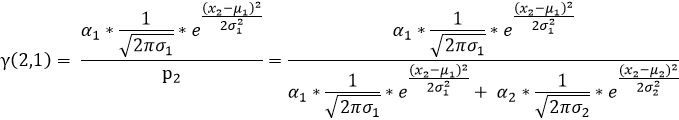
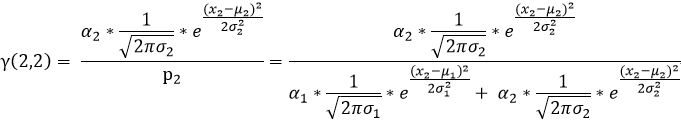
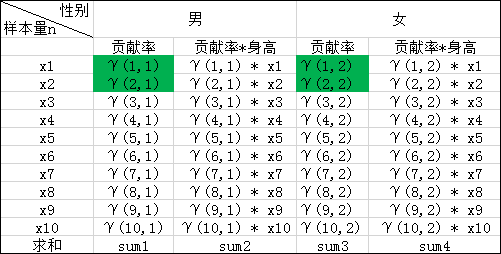
(3)依次按照上述(1)(2)的规律我们就可以求出如下表格中的所有值,表中标绿的在上述(1)(2)步已求出
我们在上文2中的(4)已经推导出来了μ和σ2的计算公式,故
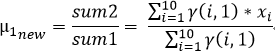

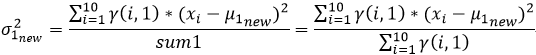

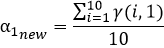
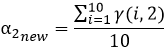
对于上述α1,α2计算方式的理解:α1,α2表示的是同一次实验,或者说针对同一个样本,两类数据来源(男性,女性)对样本结果的贡献率,那么对于每一个样本来说他们的男性和女性的贡献率都应该是恒定的,故我们采用取平均的方式更新α1,α2;
(4)用计算出来的μ1new,μ2new σ21new σ22new α1new,α2new 再次重复迭代上述(1)(2)(3)步骤,直到μ1new,μ2new σ21new σ22new α1new,α2new 收敛我们即得到的关于本次观测数据最合适的参数
5.2 有了上述实例以后,我们直接给出GMM的推广式:(下述式子的正面过程见4中GMM的证明过程)
随机变量X是有K个高斯分布混合而成,取各个高斯分布的概率为φ1,φ2...φK,第i个高斯分布的均值为μi,方差为Σi。若观测到随机变量X的一系列样本x1,x2...xn,试估计参数φ,μ,Σ。
第一步:(如上述实例中(1)和(2))

第二步:(如上述实例中的(3))