

参考资料:
http://blog.csdn.net/v_july_v/article/details/6530142
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
https://dev.mysql.com/doc/refman/5.6/en/mysql-indexes.html
https://www.zhihu.com/question/36996520
https://stackoverflow.com/questions/21927117/what-is-this-operator-in-mysql
http://thephper.com/?p=142
0. 环境
MySQL: 5.6.22
1. 概述
大部分MySQL索引(PRIMARY KEY, UNIQUE, INDEX, FULLTEXT)是以B+tree算法存储。例外:
- 基于空间数据类型(spatial data types)使用R-trees算法
- MEMORY引擎支持Hash算法
- InnoDB引擎的全文检索索引(FULLTEXT)使用倒排列表(inverted lists)算法
2. B+tree索引与Hash索引的区别
B+tree索引可以在=, >, >=, <, <= 和 BETWEEN操作中使用,也适用于不以通配符开始的LIKE操作(eg. LIKE '1%' or LIKE '1%2%'),而Hash索引限制如下:
- 仅适用于=, <=> 操作且检索速度很优秀('a' IS NULL等价于'a' <=> NULL,<=>只能用于Mysql)
- 无法使用Hash索引优化ORDER BY
- 无法使用Hash索引计算两个值间区间大小
- Hash索引不能拆分使用(相对于B-tree的最左匹配原则)
3. 为什么使用B+tree?
由于MySQL的索引文件通常很大无法常驻内存,故以文件形式存储于磁盘,于是优化MySQL检索速度很大程度上是在优化磁盘IO,即减小磁盘使用空间以及降低IO频率。动态查找树主要有:
- 二叉查找树(Binary Search Tree)
- 平衡二叉查找树(Balanced Binary Search Tree)
- 红黑树(Red-Black Tree )
- B-tree/B+tree/ B*tree (B~Tree)
前三者都是二叉树结构,随着结点的增加,会导致树的深度过大从而导致磁盘IO过于频繁,相反B-tree等使用多叉树结构,可以保持树的高度较低,减少IO次数,提升查找速度。
4. B-tree与B+tree区别
- B+tree的内部结点并没有指向关键字具体信息的指针,故内部结点相对B-tree更小,于是需要的存储空间更小
- B+tree所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,B+tree只要遍历叶子节点就可以实现整棵树的遍历
5. MyISAM及InnoDB的B+tree区别
尽管MyISAM和InnoDB都以基于B+tree实现的索引,但实现方式并不一样:
- MyISAM的索引与数据分开两个文件存储,而InnoDB的索引与数据存储在同一个文件里
- MyISAM的辅助索引的data域存储相应记录主键的地址,而InnoDB存储主键的值
6. 联合索引的最左匹配原则测试
创建表并初始化数据
CREATE TABLE `t_question` ( `id` int(11) NOT NULL AUTO_INCREMENT, `course` varchar(10) NOT NULL COMMENT '科目', `grade` varchar(10) NOT NULL COMMENT '年级', `type` varchar(10) NOT NULL COMMENT '类型', `content` text COMMENT '题目内容', `upload_time` datetime NOT NULL COMMENT '上传时间', `source` varchar(50) DEFAULT NULL COMMENT '来源', PRIMARY KEY (`id`), KEY `Index 3` (`course`,`grade`,`type`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='题目表';
- 联合索引使用不一定与顺序相关
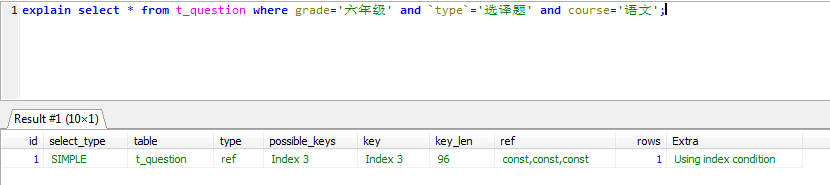
explain select * from t_question where course='语文' and grade='六年级' and `type`='选译题'; explain select * from t_question where grade='六年级' and `type`='选译题' and course='语文';
由于MySQL查询优化器,它们使用了相同的索引

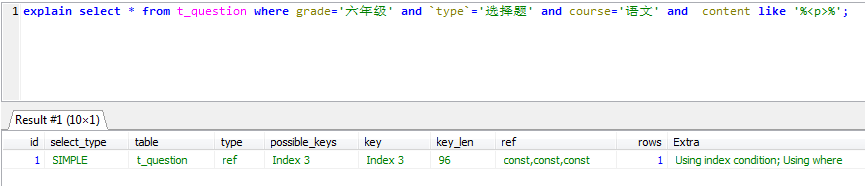
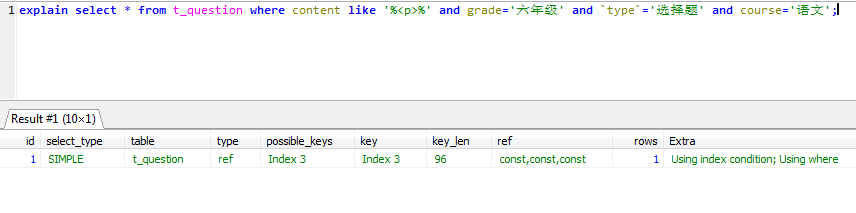
同理,以下语句也使用了相同的索引
explain select * from t_question where content like '%<p>%' and grade='六年级' and `type`='选择题' and course='语文'; explain select * from t_question where grade='六年级' and `type`='选择题' and course='语文' and content like '%<p>%';
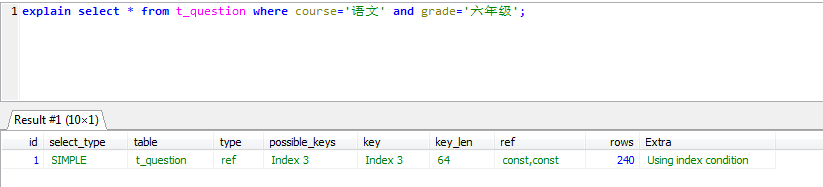
- 联合索引可以使用部分索引
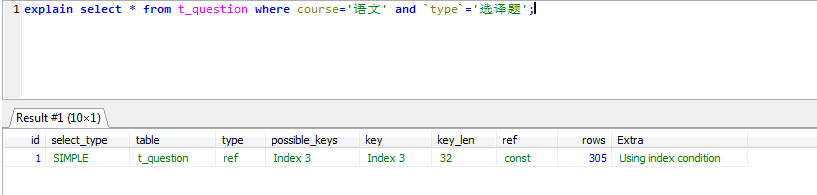
explain select * from t_question where course='语文' and grade='六年级'; explain select * from t_question where course='语文' and `type`='选译题';
仍然可以使用联合索引,只是key_len不一样而已
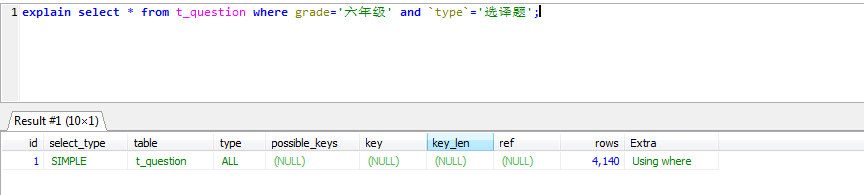
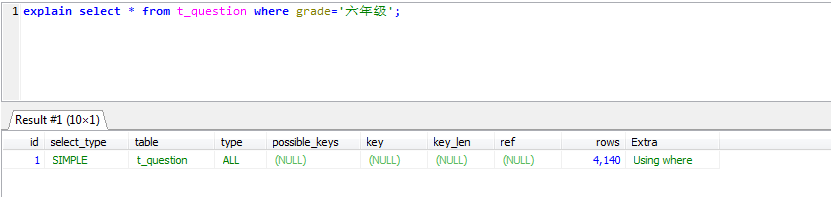
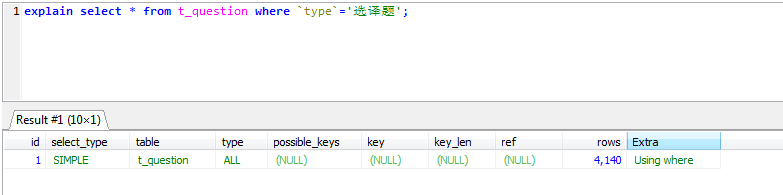
- 最左字段缺席时不能使用联合索引
explain select * from t_question where grade='六年级' and `type`='选译题'; explain select * from t_question where grade='六年级'; explain select * from t_question where `type`='选译题';
7. 常见字段已创建索引但不能使用索引的情况
- 不符合索引的最左匹配原则
- MySQL估计使用索引效率不及全表扫描
- 以通配符开头的模糊查询,例如SELECT * FROM t_question WHERE course LIKE '%文'
- NOT IN,例如SELECT * FROM t_question WHERE course NOT IN('语文')
- !=或<>,例如SELECT * FROM t_question WHERE course!='语文'
- OR,例如SELECT * FROM t_question WHERE course='语文' OR grade='一年级'
- 对列进行函数运算,例如SELECT * FROM t_question WHERE substring(course, 1, 1)='文'
- 字符型的列使用数值型的检索方式,例如SELECT * FROM t_question WHERE course=1,而SELECT * FROM t_question WHERE course='1'则可以用到索引
8. MySQL锁的引申阅读
http://blog.csdn.net/mysteryhaohao/article/details/51669741
http://jaeger.blog.51cto.com/11064196/1765906
MyISAM引擎支持表锁,而InnoDB引擎支持表锁和行锁。
- 在使用MyISAM引擎时,读写基本可以理解为串行,但可以通过修改系统变量concurrent_insert达到并发
- 在使用InnoDB引擎时,若执行的语句未使用索引,那么MySQL将使用表锁而非行锁,因为MySQL的行锁是通过给索引上的索引项加锁来实现的。一旦索引项加锁,操作不同行但使用同索引的数据也会因无法获得锁而阻塞
 posted on
posted on

