OpenGL基础之Shadow Mapping
现有的实时渲染的阴影计算都是tricky的,还没有完美的阴影计算算法。但是有几种很不错的方法来计算阴影,这些方法或多或少都有一些问题,需要我们在实现的时候注意。
在现有的视频游戏领域,有一种称为shadow mapping的方法。该方法简单易懂,开销也低,可以提供一个不错的阴影效果,并且可以很方便地扩展到高级的阴影算法(OSM,CSM)。
shadow mapping的原理是:
我们从光源位置处渲染一遍场景(即将视点放在光源位置,渲染一次场景),所有在该视锥体中看到的物体,都是被光照照到的;所有没被看到的物体都是位于阴影中的。如图
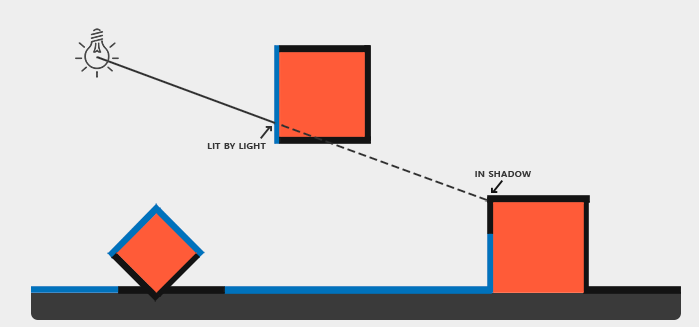
图中所有蓝色的片元都是被光照点亮的,而黑色的则处于阴影当中。
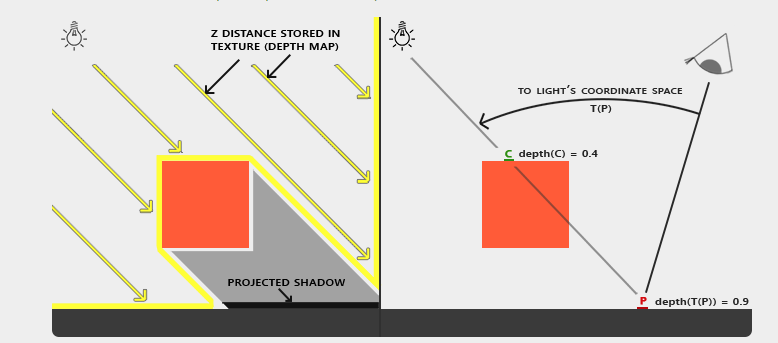
通过这种对比,我们可以利用深度图,来比较像素是否处于阴影当中,实现的方法是:
pass1:我们从光源位置渲染一遍场景,取得场景的深度buffer,输出为一张depth map或者叫shadow map的纹理;
pass2: 我们从正常的视点渲染场景,并通过投影纹理的方式采样步骤1中生成的深度图,然后比较当前片元的深度值和采样得到的深度值,如果采样得到的深度值小于当前片元的深度值,说明该片元是处在阴影当中的,我们就可以对其进一步处理,比如给其着色为阴影颜色。如图
1、获取shadow map
这其中的主要技术细节是如何从光源位置渲染一遍场景。其实最主要的是求出一个将世界坐标转换到以光源为视点的视锥体坐标的矩阵T。
T = lightProjectionMatrix * lightViewMatrix;
在为平行光计算阴影时,因为平行光的光线都是平行的,所以我们使用正视投影来计算投影矩阵lightProjectionMatrix,例如:
float near_plane = 1.0f, far_plane = 7.5f; glm::mat4 lightProjection = glm::ortho(-10.0f, 10.0f, -10.0f, 10.0f, near_plane, far_plane);
这只是最基本的一个投影计算方法,在实际应用中,这一步也设计到很多的优化方法,例如通过场景包围盒来确定远近裁剪面等优化手段。
lightViewMatrix则是根据光源位置lightPos,场景中心center,up向量三个量来确定:
glm::mat4 lightView = glm::lookAt(glm::vec3(-2.0f, 4.0f, -1.0f), glm::vec3( 0.0f, 0.0f, 0.0f), glm::vec3( 0.0f, 1.0f, 0.0f));
最后,渲染深度图时的顶点着色器为:
gl_Position = T * model * vec4(aPos, 1.0);
因为我们只需要深度图,所以可以简化片元着色器,什么都不做:
void main() { // gl_FragDepth = gl_FragCoord.z; }
2、光照计算
我们将步骤1得到的矩阵T和纹理shadow map都传入pass2的着色器中,通过矩阵T,我们可以将世界坐标先转入light perspective中,然后我们再将其转换到裁剪空间[-1,1],又因为depth map中的深度值范围是[0,1],所以再将坐标转换到[0,1]范围内。最后我们在light perspective中比较采样的深度值和当前的深度值,具体的着色器代码如下:
顶点着色器:
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
layout (location = 2) in vec2 aTexCoords;
out VS_OUT {
vec3 FragPos;
vec3 Normal;
vec2 TexCoords;
vec4 FragPosLightSpace;
} vs_out;
uniform mat4 projection;
uniform mat4 view;
uniform mat4 model;
uniform mat4 lightSpaceMatrix;
void main()
{
vs_out.FragPos = vec3(model * vec4(aPos, 1.0));
vs_out.Normal = transpose(inverse(mat3(model))) * aNormal;
vs_out.TexCoords = aTexCoords;
vs_out.FragPosLightSpace = lightSpaceMatrix * vec4(vs_out.FragPos, 1.0);
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
片元着色器:
out vec4 FragColor;
in VS_OUT {
vec3 FragPos;
vec3 Normal;
vec2 TexCoords;
vec4 FragPosLightSpace;
} fs_in;
uniform sampler2D diffuseTexture;
uniform sampler2D shadowMap;
uniform vec3 lightPos;
uniform vec3 viewPos;
float ShadowCalculation(vec4 fragPosLightSpace)
{
vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w;
projCoords = projCoords * 0.5 + 0.5;
float closestDepth = texture(shadowMap, projCoords.xy).r;
float currentDepth = projCoords.z;
float shadow = currentDepth > closestDepth ? 1.0 : 0.0;
return shadow;
}
void main()
{
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb;
vec3 normal = normalize(fs_in.Normal);
vec3 lightColor = vec3(1.0);
vec3 ambient = 0.15 * color;
vec3 lightDir = normalize(lightPos - fs_in.FragPos);
float diff = max(dot(lightDir, normal), 0.0);
vec3 diffuse = diff * lightColor;
vec3 viewDir = normalize(viewPos - fs_in.FragPos);
float spec = 0.0;
vec3 halfwayDir = normalize(lightDir + viewDir);
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0);
vec3 specular = spec * lightColor;
// calculate shadow
float shadow = ShadowCalculation(fs_in.FragPosLightSpace);
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color;
FragColor = vec4(lighting, 1.0);
}
最后得到的结果如图:
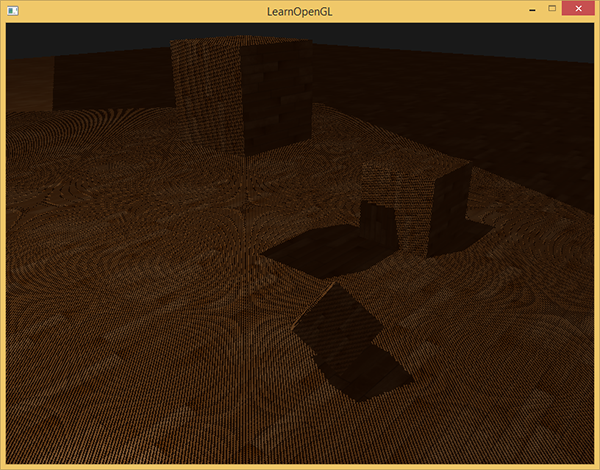
Shadow acne
由上图可以看出,渲染的结果有比较明显的人造痕迹,会有条纹状的明暗条带,这种现象称为shadow acne。其主要原因是因为由于shadow map的分辨率有限,可以场景中的多个片元对应的是shadow map中的一个像素,也就是多个片元在light perspective坐标系中采样到的深度值时一样的,但是这说个片元在camera perpective中的深度值时不同的,所以就造成比较结果有的大,有的小,有的在阴影有的不在,导致了上图的现象。如图所示:
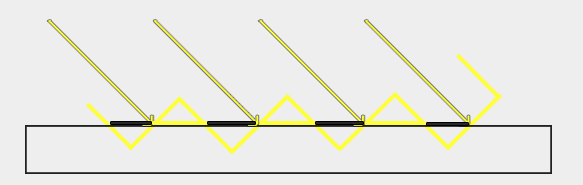
解决这种现象的方法,可以通过一个比较小的偏移量称为shadow bias,来强制让这些像素全部小于map中的像素,这样就全部是被照亮的了,就不会出现黑白条纹的问题,如图示:
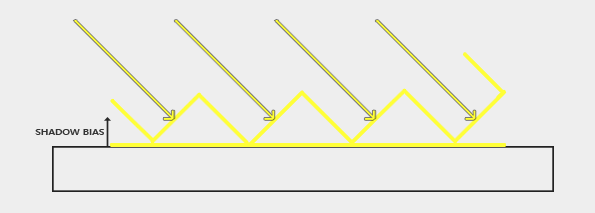
代码示例:
float bias = 0.005; float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
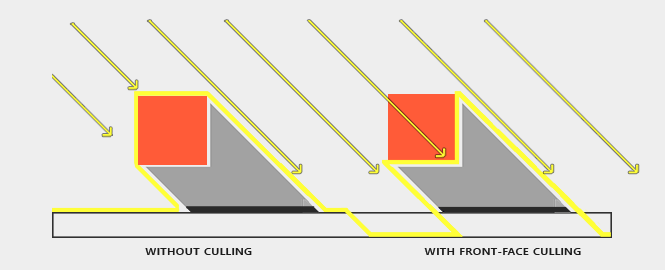
Peter panning
使用shadow bias解决shadow acne的问题会产生一种称为peter panning的新问题,如图:

该问题会让物体跟它的阴影分开了,产生了很大的偏移,给人一种物体漂浮的错觉。
解决Peter panning有一种比较简单的方法,就是light pass渲染的时候,我们使用前面裁剪Front-Face culling,只渲染后面back face。而使用camera pass时则使用正常的背面裁剪。对其有体积的模型,这种方法的效果最后,原理如图: