

PIVOT和UNPIVOT两个运算符可将表中的数据进行行列置换;本文介绍这两个关系运算的语法、语义、实现原理,及与其他关系运算联合使用时,SQL Server 2005所做的优化。
翻译得很烂,并没有严格按照原文翻译,有些容易理解但却又不好翻译的地方,直接Copy原文没有翻译。建议还是直接看原文:
Conor Cunningham, César A. Galindo-Legaria, Goetz Graefe,
PIVOT and UNPIVOT: Optimization and Execution Strategies in an RDBMS,
http://www.vldb.org/conf/2004/IND1P2.PDF
1. 简介
Pivot用于将行转换成列,UnPivot用于将列转换成行;
Pivot transforms a series of rows into a series of fewer rows with additional columns. Data in one source column is used to determine the new column for a row, and another source column is used as the data for that new column.
Unpivot provides the inverse operation, removing a number of columns and creating additional rows that capture the column names and values from the wide form.
以前要实现Pivot功能,需要在关系数据库之外或者Query Processing之后对结果集进行处理;例如,Excel支持Pivoting,用户可以对数据源执行查询得到一个结果集,然后将该结果集导入到Excel,再对结果Excel进行Pivot;Access也支持Pivoting,但其是通过在Query Processing之后通过游标来实现的;它们的实现都不是很高效,没有将Pivot和UnPivot做为数据库关系操作.
现有的数据建模技术中,都要求将表之间的关系和表内的属性(Attribute)进行持久存储。将列按照自然特点进行强定义(columns be strongly defined contrasts with the nature),可以很方便地进行插入和删除行。PIVOT和UnPivot可以在编译和执行时进行行列转换;当列集不能预先确定,可以使用属性表(包含ID、PropertyName、PropertyName的表),用多行来存储一组属性值;通常,如果增加属性时不想修改表结构(schema)定义,或需要避免关系数据库的实现限制(例如表中列数量的限制、或storage overhead associated with many empty columns in a row)时,可以采用这种设计;这种设计引发的问题是如果更好地使用和查询表,编写和维护对属性表的查询相对较困难,而且复杂的操作可能会导致DB不能选择最优的执行计划;通常,操作属性表中数据的应用程序,按Wide(Pivoted)格式处理时会比较费力。
关系数据库能高效地执行关系运算,在T-SQL中使用Pivot/Unpivot操作符,SQL Server可以很好地进行优化.

2. Imtroducing Pivot And Unpivot
2.1 Pivot And Unpivot in SQL
使用SQL标准语法,也能实现Pivoting功能,但操作麻烦且性能很差;一种方法是在结果列中使用标量子查询(use scalar subqueries in the projection list);例如下面的示例sql,使用标量子查询来创建需要的列:
SELECT
Year
,(SELECT Sales FROM SalesTable AS T2 WHERE T2.Month='Jan' AND T2.Year=T1.Year) AS 'Jan'
,(SELECT Sales FROM SalesTable AS T2 WHERE T2.Month='Feb' AND T2.Year=T1.Year) AS 'Feb'
,(SELECT Sales FROM SalesTable AS T2 WHERE T2.Month='Mar' AND T2.Year=T1.Year) AS 'Mar'
FROM SalesTable AS T1
GROUP By Year;
不幸的是,这种处理方式有很大的局限性,并不能充分发挥Pivoting的优势:必须为每个要转换的列定义相似语句的子查询,列数越多越麻烦,DBMS只会当子查询处理,不能很好的进行优化;而且可读性差,很难根据语法来推断查询想要干嘛.
因此,Pivot横空出世了。如下例中的SQL所示,这样的语法阅读、书写和维护都很方便,老少咸宜啊。。。
SELECT * FROM
(SalesTable Pivot (Sales FOR Month IN ('Jan','Feb','Mar'));
上面的查询中,Pivot对SalesTable进行操作;Sales列中的值被转置到pivoted column中,Month列中的值限制该如何转置(定义了映射关系);IN列表中的值来自于Month列,并作为pivoted column的列名;SalesTable中其余的没有列出来的列,会被隐式地进行分组,每组对应Pivot结果集中的一行。
至于Unpivot,其语法与Pivot相似,但执行与Pivot相反的操作,将IN列表中的列转换成行。
SELECT * FROM
(SalesReport Unpivot (Sales FOR Month IN ('Jan','Feb','Mar'));
2.2 Pivot AND Unpivot Semantics
使用Pivot和Unpivot时,还需要注意数据冲突(例如两个值映射到同一个位置)和缺值的情况。
出现数据冲突时,有以下几种处理方式:(1).报错;(2).使用聚集函数(sum、avg等),如下例所示;(3).数据在进行Pivot处理之前先除掉重复值;(4).引入嵌套结果集。
SELECT * FROM
(SalesTable Pivot (SUM(Sales) FOR Month IN ('Jan','Feb','Mar'));
3.代数优化
PIVOT的定义:

UNPIVOT的定义:

3.1 Projection(投影)和Filters(选择)
(1) 投影+Pivot:如果一个查询对Pivot生成的列进行投影操作,则查询将被优化成Pivot时就不处理这些列,从而避免不必要的计算。

(2) 选择+Pivot:Select对Pivot的输出结果进行过滤时,并不会在Pivot之前就对行进行过滤;Pivot会为输入源中的每组数据生成一行,即使输入源中的数据于pivot生成的转置列不匹配。如果提前进行过滤,有些情况下可能产生错误的结果;当且仅当分组列与Pivot生成的装置列组合后正好包含键(候选码),且折叠函数满足恒等性(the collapsing function is the identity),这种提前过滤得到的最终结果才是正确的,且可以有效地应用索引(如果有的话)。如下图所示:

(3) 投影+Unpivot:Projections over UNPIVOT are straightforward. Projections limiting grouping columns can be safely applied below the UNPIVOT.
(4) 选择+Unpivot:A filter on the columns introduced by UNPIVOT enables a whole column to be removed from the input to UNPIVOT. 这里不存在上面(2)总存在的问题。

3.2 PIVOT and Property Tables
属性表包含两列:属性名称和属性值;我们可以用这种存储方式来代替稀疏矩阵。 我们可以用PIVOT来将属性表转换成包含所有列的虚拟表(稀疏矩阵,缺值时用NULL进行填充),其是通过将主表与从表进行Left Outer Join(LOJ)来实现的。
属性表的设计增加了使用复杂性;通常情况下,在主表中用于分组的列(grouping columns)和属性表中的属性名、属性值上创建索引,可以提高查询效率;
(1) 投影:对Pivot生成的结果集执行投影,投影操作会提前到LOJ之前;如果投影会去掉转置生成的列,则在Pivot时就不会转置这些列;特别地,当对Pivot结果集执行去掉所有生成的转置列的投影操作,则数据库可以不用查找属性表,直接优化掉Left Outer Join,如下图所示:

(2) 选择:执行Pivot时,属性表中的数据可以根据IN列表中的值来进行提前(在LOJ之前)过滤,执行过程如下图所示:

如果对选择条件是根据生成的转置列进行过滤,则优化成如下如下:

显然这样优化后,增加了一次对属性表的查询,当且仅当在属性表上建立了合适的索引后,此优化才是合理的。
3.3 PIVOT as GROUP BY
可以用Group By来实现Pivot:
MIN(CASE Month WHEN 'Jan' THEN Sales ELSE
NULL END) AS 'Jan',
MIN(CASE Month WHEN 'Feb' THEN Sales ELSE
NULL END) AS 'Feb',
MIN(CASE Month WHEN 'Mar' THEN Sales ELSE
NULL END) AS 'Mar'
在Group By中使用了多个聚合运算,DBMS的优化器将将很难检查和理解;如果使用Pivot,逻辑相对集中,不是分散在那些聚合函数中,it is easier for rule-based optimizers to target with special-purpose transformation logic.
将PIVOT当作Group By处理(Mapping PIVOT to GROUP BY)需要满足一个假设:增加NULL值时,聚合函数的结果不变(the collapsing (aggregate) function be invariant to additional NULLs)。也就是说,聚合函数F需要满足F(S)=F(S U {Null}) (S是输入值,U表示Union);SUM()、MAX()等聚合函数满足次条件,但Count(*)不满足!
既然PIVOT是一种特殊的GROUP BY,RDBMS可以很容易地支持PIVOT功能,而不用专门在查询处理器中每个地方为其写一套新的逻辑。在编译查询(query compilation)时,尽可能早地将PIVOT转换成GROUP By(例如,在查询优化或启发式重写的最开始[at or near the start of query optimization or heuristic rewrite]),数据库为实现PIVOT功能所需要做的改动最小:不需要增加新的执行操作符(execution operator),little new optimization or costing logic is needed。
将PIVOT看作GROUP BY,则不需要做重大更改,就可以将现有的GROUP BY优化逻辑应用到PIVOT。These benefits include:
(1). Removal of duplicate or grouping columns by other grouping columns, which reduces overall row width;
(2). Filters and semi-joins restricting complete groups can be performed below the GROUP BY;
(3). Local/Global techniques for pushing grouping optimizations below joins and other operations;
(4). Query logic to perform groupings using parallel threads of execution.
3.4 UNPIVOT as Apply
从本节开始UNPIVOT的定义中,我们可以看到,PIVOT是通过APPLY来实现的。Apply can be reordered easily with other join operators, and it has well-defined interactions with filters, projections, and other query operations. It is also possible to perform these operations in parallel by segmenting the input rows into different groups。DBMS已经对Apply进行了很多优化,这些优化对UNPIVOT同样适用。
3.5 减少JOIN结果集的基数(Join Cardinality Reduction)
如果联合使用PIVOT和UNPIVOT并执行相反的操作(If PIVOT and UNPIVOT are inverses),查询优化器(query optimizer)可以在查询树(query tree)中引入PIVOT和UNPIVOT,从而减少高代价运算符所处理的关系集的基数(reduce cardinality in portions of a query tree around expensive operations, such as joins.)。如果使用PIVOT能无损地减少输入源的基数,则JOIN(或者其他的高代价运算符)可以执行更少地次数;UNPIVOT也同样。基于代价的查询优化器(Cost-based optimizers)可以在查询评估(query evaluation)时使用此技术。如下图所示:

4. 执行策略(Execution Strategies)
用GROUP BY来表示PIVOT,提供了一种新的方式来重用现有的操作符。上面的3.3节中,演示了PIVOT可以通过GROUP BY来实现。PIVOT中可以使用hash和stream聚集函数(hash and stream aggregation),且保留了聚集函数原有的行为特性;只要每组中的所有记录是在一个线程中被处理,使用这种PIVOT实现策略 就可以并行地执行查询(Parallel query execution can also be supported using these execution strategies as long as the members of each group are processed in the same thread.)。PIVOT的实现过程中,使用了大量的聚集函数(PIVOT does use a relatively large number of identical aggregates with almost identical scalar logic.)。PIVOT的一种新的执行策略是:group the computation of these aggregates together,有如下两种实现方式:(1). 将这组聚合函数当过向量运算来进行处理(treating the set of aggregates as a vector computation);
(2). 重写现有的聚集函数:rewriting each individual aggregate computation into a dispatch table (as each column will be looking for a single and likely unique scalar for each input row).
也可以通过行转列的迭代器(a specialpurpose iterator transposing rows into column)来实现PIVOT。当遍历已经排序(根据要分组的列[Grouping columns]和转置列[pivot column])的输入流时(Consuming a sorted stream),当前组中的下一行中的值就是下一列的值;如果输入源中,转置列没有相应行,就用空值代替;与grouping运算相似,这种实现方式中,也可以实现不同分组并行计算。
如前面所述,可以通过相关的嵌套循环连接(nested loops join, apply)来实现UNPIVOT,Apply中的每个步骤可以并行处理(Each invocation of the Apply can be performed in parallel)。也可以通过列转行的迭代器(a special purpose execution iterator that consumes one row and returns a number of rows in unpivoted form.)来实现UNPIVOT,这种实现方式中,输入源中的每行能独立地被处理,因此要实现并行运算也很简单。
5. Experimentation
SQL Server 2005中已经实现了PIVOT和UNPIVOT。SQL Server 2005查询优化器的体系结构是基于Cascades framework的,该framework允许定义新的关系运算符和为这些运算符定义新的优化规则。这些优化规则是根据上面所描述的PIVOT和UNPIVOT的属性(property)得出的。
这节中,通过几个示例来展示系统的性能。使用TPCH数据库,1GB规模;测试机为2GHz双处理器,1GB内存。每次执行前清理数据缓存,所以展示结果数据都是基于cold cache的。测试时禁用了并行执行,这不会对测试结果产生重大影响(Parallel execution is disabled in the results we present, since it does not qualitatively affect our results)。
5.1 PIVOT vs. SQL子查询
比较Pivot与2.1中的子查询两种写法,实现如下功能:统计Orders表中的销售数据,每年一条记录,每月占一列。
SELECT * FROM
(SELECT
YEAR(O_ORDERDATE),
MONTH(O_ORDERDATE),
O_TOTALPRICE
FROM ORDERS) ORD(YEAR, MONTH, PRICE)
PIVOT (SUM(PRICE)
FOR MONTH IN (1,2,3,4,5,6,7,8,9,10,11,12)) T
下图展示了两种写法的执行时间。分别改变两种写法中的月数,3个月、6个月、12个月;子查询的性能差异主要是由于子查询中的重复计算,而Pivot的性能差异很小,因为每个转置列是被独立计算的(as each pivoted column is computed separately)。子查询的写法中,不能对每列进行独立计算。
可以使用索引来优化子查询的性能;在上面的例子中,在year、month、price列上建立索引,可以让子查询的性能优化到接近Pivot性能的程度(Fast lookup of the value from the dimensions columns (e.g. and index on year, month, price in the case above) would make performance comparable to the PIVOT form.)。但是, 这样会给应用程序开发人员带来冗余和重复的工作(it remains verbose and repetitive to the application writer)。
5.2. 访问属性表(Property table access)
前面提到了使用Pivot来支持属性表。数据按照稀疏格式存储在属性表,应用程序开发人员可以用Pivot来使其展现成wide rows。在这个实验中,我们将TPCH CUSTOMER表中的数据按照属性表的方式来进行存储,属性表的Schema如下:
CUSTPROPERTY(CP_CUSTKEY, CP_NAME, CP_VALUE);
列 (CP_CUSTKEY, CP_NAME)组成属性表的复合主键;记录customer的属性时,就向该表中增加一条记录;我们在CP_NAME、CP_VALUE、CP_CUSTKEY上创建索引,以高效地查询属性值。
现在创建一个视图按纵表格式来展示属性表中的数据。由于要保留没有定义属性的customer,所以视图中使用了outer join。假定我们只关心‘A’到‘E’ 5个属性:
CREATE VIEW EXTCUSTOMER AS
SELECT *
FROM (
SELECT *
FROM CUSTOMER
LEFT JOIN CUSTPROPERTY
ON C_CUSTKEY = CP_CUSTKEY
) CUSTNARROW
PIVOT
(
MIN(CP_VALUE) FOR CP_NAME IN ('A','B','C','D','E')
) CUSTPIVOTED
应用程序如果想查找具有特定属性的customer,则可以直接查询该视图,例如:
SELECT * FROM EXTCUSTOMER
WHERE A IS NOT NULL
下图展示了视图的性能,其中比较了三种实现方式:
(1). 将所有信息放在纵表(Wide Table)中,为'A'——'E' 5个属性分别创建5列,并在每列上分别创建索引;
(2). 使用属性表,并为属性表创建视图,然后在视图上执行操作,例如选择(filtering);
(3). 使用属性表,直接对在属性表上进行Pivot操作;
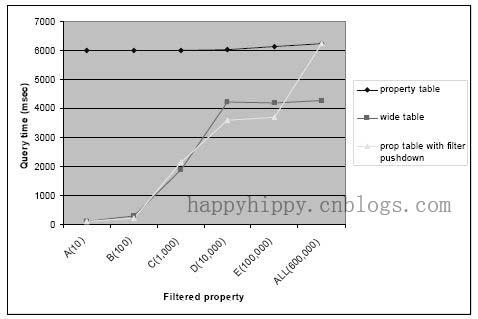
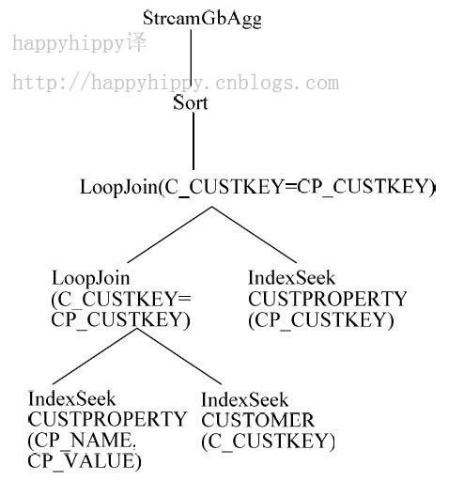
为了改变谓词的选择度(To change the selectivity of predicates),我们对属性值进行了分类。10个customer定义(纵表格式中不是NULL值)了属性'A',定了属性'B'到'E'的customer数量分别为100、1000、1000、10000。在这个实验中,customer的记录数在15万~60万之间。属性'A'和'B'的选择度很低,下图展示了其查询计划。先通过索引查找,根据CUSTPROPERTY表的非聚集索引查询到具有此属性的customer;然后,通过CUSTOMER表上的聚集索引进行索引查找,取得表中所有的列;接着再功过索引查找来为这些customer取得剩余的属性值;最后对数据进行组合,使用分组和聚合(stream aggregation)来完成pivot。
相比之下,属性表比CUSTOMER表小;当所有的数据都已被加载,使用属性表与纵表("wide" table)的性能差异主要在于Pivot的执行代价。当查询中有谓词存在时,我们的转换规则可以生成高效的执行计划,使用索引来快速地定位需要的行,使Pivot的性能接近与使用纵表。
另外还需要指出的是,索引带来有的优势也有一定的限制。当在数据建模中直接使用纵表,则可以创建并使用多列的组合索引;但属性表却无法提供这种访问方式,所以其预期行为与在每列上分别建立索引的效果比较接近。
6. 扩展(Extensions)
本文展示了PIVOT和UNPIVOT处理单列的情况,我们也可以很容易地扩展它们来处理任意多列的情况:Pivot可以将每列转换到独立的列集中(Each value column could be transposed into independent sets of columns in PIVOT);同样地,UNPIVOT可以同时拆分不同的分组(UNPIVOT can collapse different groups at the same time)。各组使用不同聚集函数,且不同的聚集函数可以应用到同一列上。或者根据具体需要,创建复杂数据类型来存储多值。这些扩展都不会影响上面描述的优化和实现技术。
扩展折叠函数(collapsing function)也可以增加PIVOT和UNPIVOT的功能。折叠函数就是单列聚集函数(例如SUM()、MIN()等)。可以使用RDBMS中的任何聚集函数(包括用户自定义函数和顺序敏感的聚集函数),这些函数都不会影响上面描述的行列转换方式。即使引入其他的聚集函数(例如允许输入多列或输出多列),也可以通过简单的扩展来适配PIVOT和UNPIVOT的语法。在这种上下文中,也可以考虑不使用聚集函数(it is possible to consider non-aggregate functions in this context),当出现数据冲突时抛出异常,或者使用嵌套关系来处理数据冲突(handle data collisions by storing data from multiple rows as a nested relation),或者some other format that UNPIVOT can reassemble into multiple rows without losing data。这些扩展使PIVOT和UNPIVOT具有很大的扩展性。
PIVOT and UNPIVOT are related to OLAP structures such as data cubes。但是,OLAP操作并不是总能很好地适合SQL language。如果SQL可以访问多维结构,PIVOT和UNPIVOT就可以将CUBE当作关系集合来处理(例如二维的行列)(If a multidimensional structure is accessible through SQL, PIVOT and UNPIVOT could work on a portion of a cube visible as a relation)。
7. Related Work
PIVOT并不是一个新的概念,[4]描述了关于分组的一些扩展,包括“cross-tab”查询,里面的讨论对与PIVOT没有多少帮助,并且没有讨论如何有效地实现、如果与其他运算符联合使用。
SchemaSQL [5] 实现了转置运算符。其实现是在RDBMS之外,因此没有关于查询优化的讨论。[6]通过unfold和fold运算符来分别实现了pivoting和unpivoting功能。这些工作都没有尝试将行列转置功能深入到RDBMS内部去实现。
[8] describes a system to expose spreadsheet-like functionality into a RDBMS, 包括这种访问方式中如何优化查询。This model exposes behavior closer to OLAP than traditional flat relations, though some predicate pushing would be related in these two models.
[8]也描述了一个N维数组数据模型,其中数组中每个单元(cell)described through a coordinate system using names。虽让实现了功能,但范例与传统的SQL运算符不同,很难理解。我们的表示法使用SQL语言实现数据旋转(data rotation),是一种更加自然的表示法。
[8]和[4]都描述了一个关系表是从二维的角度来看CUBE,可以表现cross-tabulation数据。但是,只有[4]中讨论了如何在cross-tabulated和flat (narrow) form两种格式之间转换数据,并且[4]只提到了Microsoft Access具有此功能。
最后,我们先前的工作[2]使用unpivot运算符的设计来实现一个特殊功能。
8. Conclusion
我们介绍了两个新的可以在RDBMS内部使用的数据操作运算符:Pivot和Unpivot。These improve many existing user scenarios and enable several new ones。此外,这篇文章概况地描述了他们的基本语法、语义,及如何在现有的RDBMS(based on algebraic, cost-based optimization and algebraic data flow execution)中实现它们。Pivot is an extension of Group By with unique restrictions and optimization opportunities,这使得Pivot在grouping的基础上很容易实现。最后,我们使用Pivot和Unpivot展示了几个有用的代数转换公理。
9. References
[1] C. A. Galindo-Legaria, M. M. Joshi. Orthogonal Optimization of Subqueries and Aggregation, ACM SIGMOD 2001, May 21-24, 2001, Santa Barbara, California, USA, pages 571-581.
[2] G. Graefe, U. Fayyad, and S. Chaudhuri. On the Efficient Gathering of Sufficient Statistics for Classification from Large SQL Databases, Proceedings of The Fourth International Conference on Knowledge Discovery and Data Mining, 1998, pages 204-208.
[3] G. Graefe. The Cascades Framework for Query Optimization. Data Engineering Bulletin 18 (3) 1995, pages 19-29.
[4] J. Gray, A. Bosworth, A. Layman, H. Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals, Data Mining and Knowledge Discovery, vol. 1, no. 1, 1997.
[5] L. V. S. Lakshmanan, F. Sadri, and S. N. Subramanian. On Efficiently Implementing SchemaSQL on a SQL Database System. In Proceedings of 25th International Conference on Very Large Data Bases, September 7-10, 1999, Edinburgh, Scotland, pages 471-482.
[6] R. Agrawal, A. Somani, Y. Xu. Storage and Querying of ECommerce Data, In Proceedings of 27th International Conference on Very Large Data Bases, September 11-14, 2001, Roma, Italy, pages 149-158.
[7] M. Jaedicke, B. Mitshcang. On Parallel Processing of Aggregate and Scalar Functions in Object-Relational DBMS. 1998 Proceedings of the ACM SIGMOD International Conference on Management of Data, Seattle, WA, pages 379-389.
[8] A. Witkowski, S. Bellamkonda, T. Bozkaya, G. Dorman, N. Folkert, A. Gupta, L. Shen, S. Subramanian. Spreadsheets in RDBMS for OLAP. 2003 Proceedings of the ACM SIGMOD International Conference on Management of Data, San Diego,CA, pages 52-63.1009
happyhippy补充:
(1). 关于基数(Cardinality)的定义:
Cardinality represents the number of rows in a row set. Here, the row set can be a base table, a view, or the result of a join or GROUP BY operator.
Base cardinality is the number of rows in a base table. The base cardinality can be captured by analyzing the table. If table statistics are not available, then the estimator uses the number of extents occupied by the table to estimate the base cardinality.
Effective cardinality is the number of rows that are selected from a base table. The effective cardinality depends on the predicates specified on different columns of a base table, with each predicate acting as a successive filter on the rows of the base table. The effective cardinality is computed as the product of the base cardinality and combined selectivity of all predicates specified on a table. When there is no predicate on a table, its effective cardinality equals its base cardinality.
Join cardinality is the number of rows produced when two row sets are joined together. A join is a Cartesian product of two row sets, with the join predicate applied as a filter to the result. Therefore, the join cardinality is the product of the cardinalities of two row sets, multiplied by the selectivity of the join predicate.
Distinct cardinality is the number of distinct values in a column of a row set. The distinct cardinality of a row set is based on the data in the column. For example, in a row set of 100 rows, if distinct column values are found in 20 rows, then the distinct cardinality is 20.
Group cardinality is the number of rows produced from a row set after the GROUP BY operator is applied. The effect of the GROUP BY operator is to decrease the number of rows in a row set. The group cardinality depends on the distinct cardinality of each of the grouping columns and on the number of rows in the row set. For an illustration of group cardinality.

