


使用最大似然法来求解线性模型(4)-最大化似然函数背后的数学原理
在 使用最大似然法来求解线性模型(3)-求解似然函数 文章中,我们让 logL 对 w 求一阶偏导数,让偏导数等于0,解出 w,这个 w 就是使logL取最大值的w
那为什么令一阶偏导数等于0,求得的w就能够使 logL 取最大值呢?
在高等数学中,对于一元可导函数f(x)而言,一阶导数f′(x)=0的点称为拐点。而拐点不一定是极值点,一种判断拐点是否是极值点的方式是:判断拐点处的二阶导数是否大于0
若拐点处的二阶导数大于0,则f(x)在拐点处取极小值;若拐点处的二阶导数小于0,则f(x)在拐点处取极大值;若拐点处的二阶导数等于0,则拐点处不是极值。
上面的结论,可以用f(x)=x2 和 f(x)=x3 来验证。当然,结论的前提是f(x)是二阶可导的,如果二阶导数都不存在,上面的方法自然就不能用来判断极值点了。
而在机器学习中,我们考虑的样本的特征有很多,不止一个,因此我们所处理的函数一般是多元的(多个自变量)。
比如 logL 是关于 w 的函数,而 w=[w1,w2] 是一个向量,logL 关于w求偏导数时,其实质就是对 w 个的每一个分量wi 求偏导数。
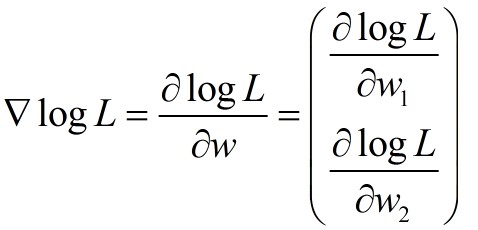
上面的![]() 就是:logL 关于w的偏导数,又称为梯度。从公式中可看出:logL是一个实数,它是一个标量--我们的目标也是寻找最大的logL,而梯度是一个向量。
就是:logL 关于w的偏导数,又称为梯度。从公式中可看出:logL是一个实数,它是一个标量--我们的目标也是寻找最大的logL,而梯度是一个向量。
是不是想到了梯度方法?没错,梯度下降方法就是用到了梯度的一个性质:
- 梯度性质:梯度方向
![]() 就是函数f 在w处 增加最快的方向,因此要搜索函数f 的最大值,往梯度方向搜索应该是一个很好的搜索方向。
就是函数f 在w处 增加最快的方向,因此要搜索函数f 的最大值,往梯度方向搜索应该是一个很好的搜索方向。
这里不讨论梯度的一些理论,而是在梯度的基础上,再对wT求导,就得到了一个矩阵,如下所示:

这个矩阵就是黑塞矩阵,而 logL 在 w 点 是否取极值就由这个黑塞矩阵的性质来决定。
- 极小值定理:多元实值函数f(w)在定义域上二阶连续可微,w*是定义域上的一个内点,如果w*满足如下两个条件:
- 则w*是函数f(w)的一个严格局部极小点。其中F(w)是黑塞矩阵。关于这个定理的证明可参考:《最优化导论 第四版》Edwin K.P.Chong著 孙志强译
由前面的公式:![]() ,再对wT求导,得出:
,再对wT求导,得出:![]()
因此,对于函数logL而言,它的黑塞矩阵是:F(w)=(-1/σ2)XT*X
要想使得在w处logL取极大值,则黑塞矩阵:F(w)=(-1/σ2)XT*X < 0 。也即:XT*X > 0,也就是判断矩阵XT*X是正定矩阵。
而在使用最大似然法来求解线性模型(3)-求解似然函数:中,矩阵X如下:
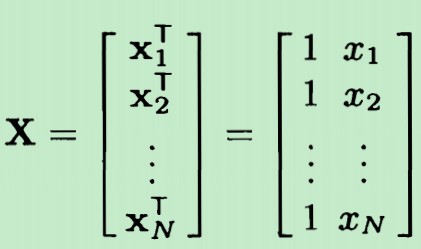
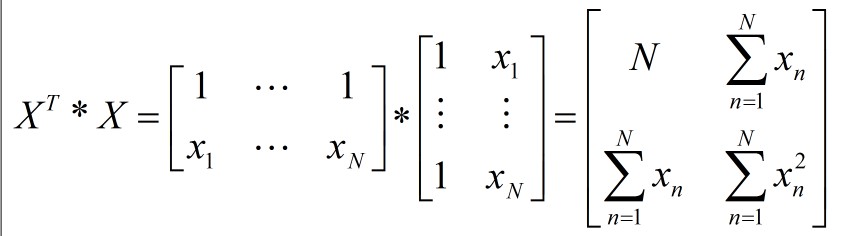
得到XT*X是一个对称矩阵。判断对称矩阵是正定矩阵的定理有:
- 对称阵A为正定的充分必要条件是:A的特征值全为正
- 对称阵A为正定的充分必要条件是:A的各阶顺序主子式都为正
- 对于任意的一个非零向量z=[z1,z2]T,有 zT*A*z > 0。也即对称矩阵A的 二次型 大于0
当一个矩阵是对称矩阵时,根据上面的定理判断它的正定性,是很方便的。这也是为什么将一般矩阵转换成对称矩阵来处理的原因。
这里采用第二种方式,来证明 XT*X 正定矩阵,由于它是2*2矩阵,故一共只有两个顺序主子序。
XT*X 的一阶顺序主子式为N,N>0 显然成立。
XT*X 的二阶顺序主子式为:![]()
这里从概率论中随机变量的方差角度出发来证明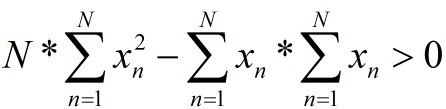
将上式除以N的平方,得到: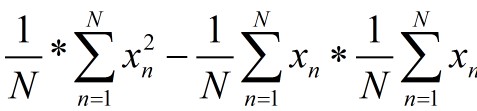
再根据方差DX的定义,DX=E(X-EX)2是大于0的。故下面等式成立。
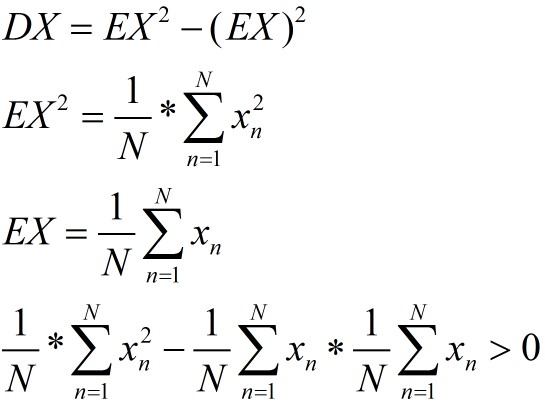
从而证明了二阶主子式也大于0。故对称矩阵XT*X是正定矩阵。
因此,对于一阶偏导数等于0的点w*而言,它的黑塞矩阵总是正定的。因而满足“极值定理”成立的条件。故w*是一个极大值点。
参考文献:
- 《a first course of machine learning》
- 《最优化导论》第四版 Edwin K.P.Chong著
原文:http://www.cnblogs.com/hapjin/p/6633471.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号