
Hadoop3.0完全分布式集群安装部署
1. 配置为1个namenode(master主机),2个datanode(slave1主机+slave2主机)的hadoop集群模式,
在VMWare中构建3台运行Ubuntu的机器作为服务器;
关闭操作系统防火墙:ubuntu下默认是关闭的,可以通过命令ufw status检查;
master主机配置如下:
vim /etc/hostname 编辑此文件,设置主机名为master
vim /etc/hosts 编辑此文件,添加如下主机内容信息:
192.168.107.128 master
192.168.189.129 slave1
192.168.189.130 slave2
同理配置slave1,
vim /etc/hostname 编辑此文件,设置主机名为slave1
vim /etc/hosts 编辑此文件,添加如下主机内容信息:
192.168.107.128 master
192.168.189.129 slave1
192.168.189.130 slave2
同理配置slave2主机
vim /etc/hostname 编辑此文件,设置主机名为slave2
vim /etc/hosts 编辑此文件,添加如下主机内容信息:
192.168.107.128 master
192.168.189.129 slave1
192.168.189.130 slave2
2. 下载安装jdk1.8.0_91,并设置好环境变量;
如下命令在master机器上配置:
vim .bashrc 编辑此文件,添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_91
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export
CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
export PATH=$JAVA_BIN:$PATH
退出root账户,重新登陆,使环境变量生效。
master,slave1,slave2三台服务器配置一样。
3. 安装配置ssh, 使得master主机能够免密码ssh登录到所有slave主机,因为集群里面的主机需要在后台通信。
(1)安装:
SSH分客户端openssh-client和openssh-server,如果你只是想登陆别的机器的SSH只需要安装openssh-client(ubuntu有默认 安装客户端),如果要使本机开放SSH服务就需要安装openssh-server。
(2) 配置免密码登陆:
在master主机上登陆root用户, 输入命令:ssh-keygen -t
rsa
然后根据提示一直按enter,就会按默认的选项生成的密钥对(私钥id_rsa和公钥id_rsa.pub)并保存在/root/.ssh文件夹中;
将master服务器上的公钥拷贝到slave1上,输入命令:ssh-copy-id root@slave1(root为slave1上的账户)
将master服务器上的公钥拷贝到slave2上,输入命令:ssh-copy-id root@slave2(root为slave2上的账户)
可以测试免密码登陆是否成功,输入命令:ssh slave1或ssh slave2来测试,若不用密码表是配置成功
4. 下载编译好的hadoop二进制文件在master主机上
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
解压:tar -zxvf
hadoop-3.0.0-src.tar.gz 至 /usr/local/hadoop-3.0.0
5. 在master主机上设置相关环境变量,将hadoop的bin目录下的可执行文件加入到系统环境
vim .bashrc 编辑此文件,添加如下内容:
export
HADOOP_HOME=/usr/local/hadoop-3.0.0
export
PATH=$PATH:$HADOOP_HOME/bin
使root用户重新登陆后,此环境变量生效
同理配置slave1和slave2两台主机,重新用root账户登陆后使环境变量生效
6. 配置hadoop环境变量
vim /usr/local/hadoop-3.0.0/etc/hadoop/hadoop-env.sh
编辑hadoop的全局配置文件,设置JAVA_HOME环境变量:
export JAVA_HOME=/usr/local/jdk1.8.0_91
设置哪个用户可以执行namenode和datanode命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
设置哪个用户可以启动resourcemanager和弄得manager的命令
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
执行source
hadoop-env.sh使环境变量生效
同理配置slave1和slave2两台主机
7. 创建相关目录 ,依次在所有主机上执行
root@master:/usr/local/hadoop-3.0.0# mkdir tmp
root@master:/usr/local/hadoop-3.0.0# mkdir hdfs
root@master:/usr/local/hadoop-3.0.0# cd hdfs/
root@master:/usr/local/hadoop-3.0.0/hdfs# mkdir name
root@master:/usr/local/hadoop-3.0.0/hdfs# mkdir tmp
root@master:/usr/local/hadoop-3.0.0/hdfs# mkdir data
8. 配置核心配置文件core-site.xml
在master主机上配置hdfs地址
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.0.0/tmp</value>
<description>A base for other
temporary directories</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> #master为主机名
<description>The name of the default
file system</description>
</property>
</configuration>
上面/usr/local/hadoop-3.0.0/tmp为创建的临时文件夹;master为主机名
9. 编辑hdfs-site.xml文件,配置副本的个数及数据的存放路径
<configuration>
<property>
<name>dfs.replication</name> --数据块的副本数量
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> --元数据存放路径
<value>/usr/local/hadoop-3.0.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> --数据节点存放路径
<value>/usr/local/hadoop-3.0.0/hdfs/data</value>
</property>
</configuration>
10. 配置mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
11. 配置yarn-site.xml文件
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
12. 配置workers 文件,列出所有workers的主机名
vim workers
slave1
slave2
hdfs分布式文件系统下的datanode进程和YARN下面的nodemanager进程会在这些workers主机上启动
注意:hadoop2.x配置的是slaves文件
13. 远程复制hadoop3.0.0文件下所有文件到slave1和slave2的主机上
scp -r hadoop-3.0.0 root@slave1:/usr/local/
scp -r hadoop-3.0.0 root@slave2:/usr/local/
14. 启动hdfs集群
在master主机上执行以下命令,格式化hdfs文件系统
$HADOOP_HOME/bin/hdfs namenode -format
在master主机上执行以下命令,初始化namenode节点
$HADOOP_HOME/bin/hdfs --daemon start
namenode
分别在所有slave节点上执行以下命令,初始化datanode节点
$HADOOP_HOME/bin/hdfs --daemon start
datanode
如果前面的ssh配置成功,也可以直接
$HADOOP_HOME/sbin/start-dfs.sh 启动所有进程
(确保ssh master免密码登陆能成功,一开始我可以免密码登陆ssh slave1和ssh slave2,不能免密码登陆ssh master,后面再master主机目录下,切换到~/.ssh目录,执行cat id_rsa.pub >>
authorized_keys就可以了)
15. 启动YARN
在master主机上启动resourcemanage进程
$HADOOP_HOME/bin/yarn
--daemon start resourcemanager
在所有slave节点上启动nodemanager进程
$HADOOP_HOME/bin/yarn
--daemon start nodemanager
如果前面的ssh配置成功,也可以直接
$HADOOP_HOME/sbin/start-yarn.sh 启动所有进程
16. 通过网页访问hdfs集群的状态
默认端口时9870,可以通过hdfs-default.xml配置文件里面的 dfs.namenode.http-address配置

hdfs集群状态
17. 通过网页访问YARN集群的状态
默认端口是8088,可通过yarn-site.xml文件里面的yarn.resourcemanager.webapp.address配置
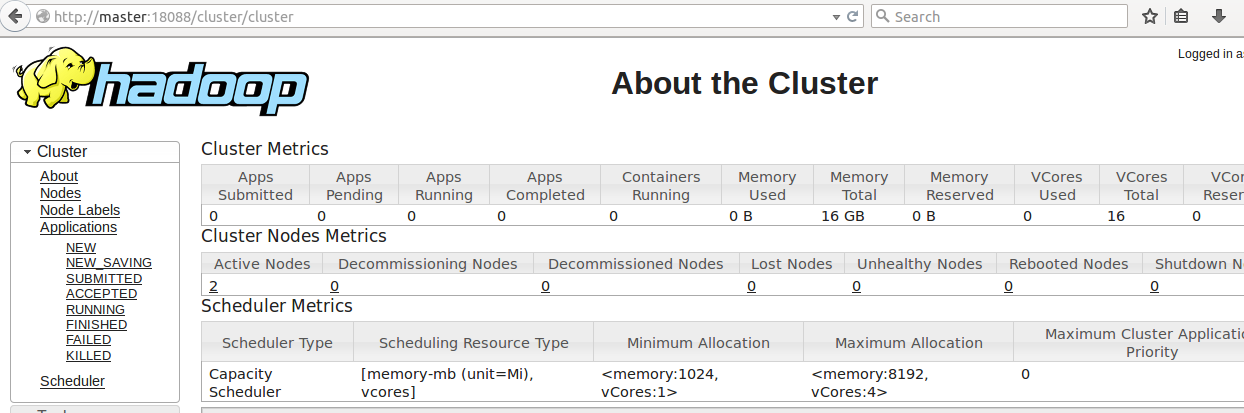
YARN管理下的hadoop集群状态

