

ML-Agents(三)3DBall
# ML-Agents(三)3DBall例子
前一周忙着公司的考试,都没有怎么学新的,今天补上~
之后的记录,我准备先只研究官方的示例,主要是把研究过程中的疑惑和想法记下来。首先我先补充一下如何利用GPU进行训练,结合(一)中的安装方法,需要CUDA v10.0,cuDNN v7.6.5 for CUDA v10.0,对应Tensorflow的版本是2.0.1。
一、利用GPU进行训练
前置工作在文章(一)中都有,原先的环境可以保留。现在可以拉一个新的ml-agents源码,然后修改ml-agents文件下的setup.py中如下图:
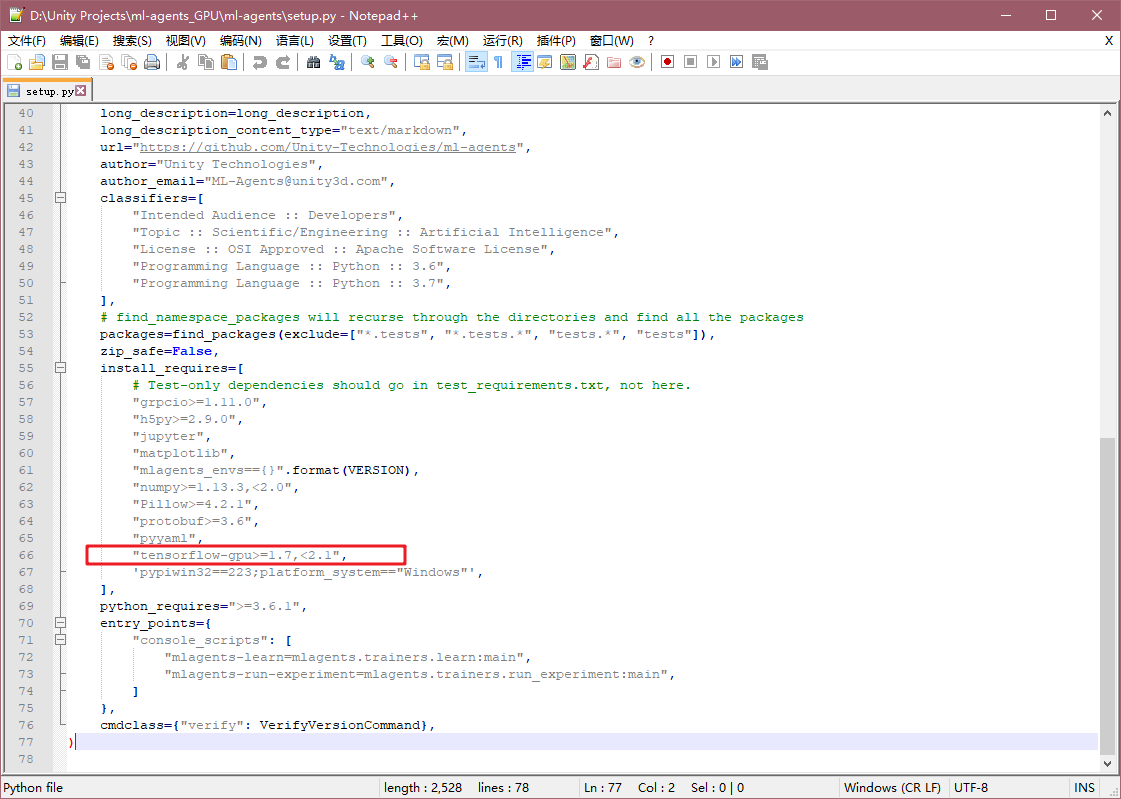
原来是"tensorflow>=1.7,<2.1",现在修改为"tensorflow-gpu>=1.7,<2.1",然后再在Anaconda中新建一个环境,如下:
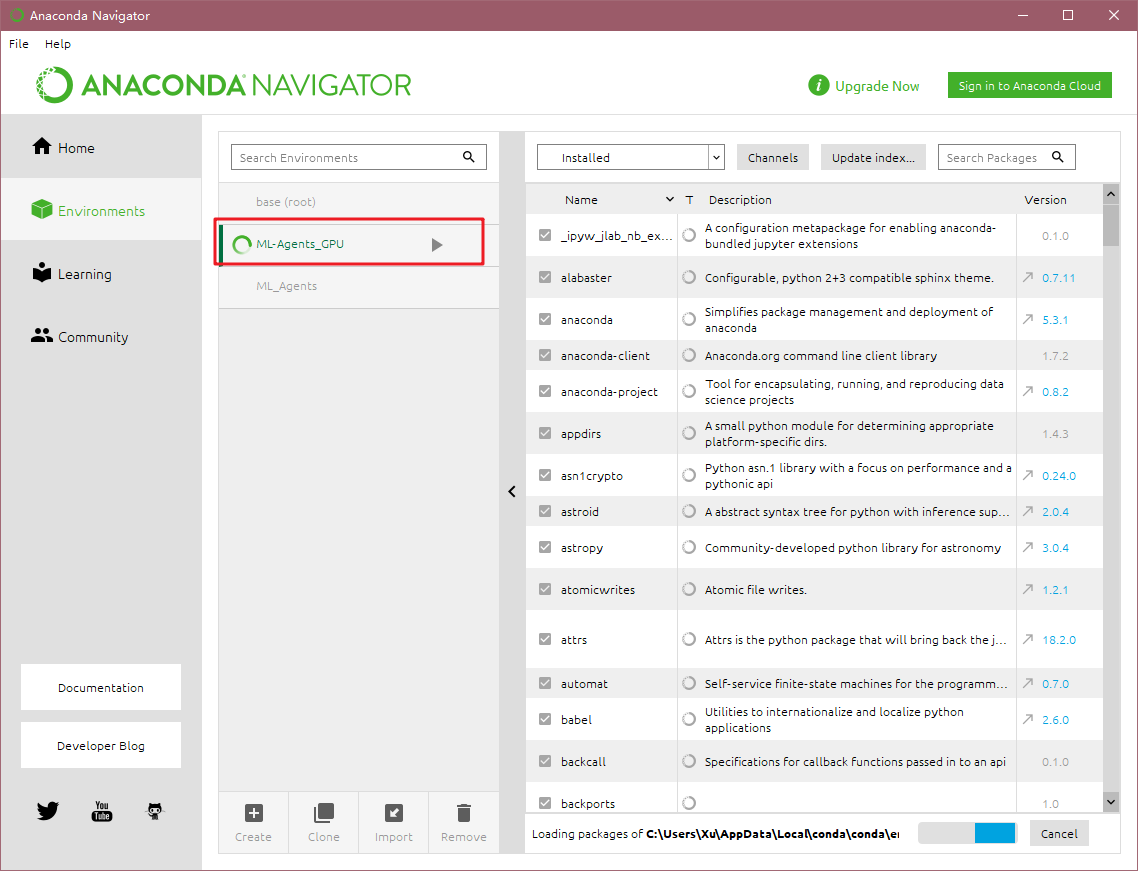
建好后在命令行中重新安装环境(别忘记cd到新的ml-agents源码),分别输入:
pip install -e ml-agents-envs -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install -e ml-agents -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
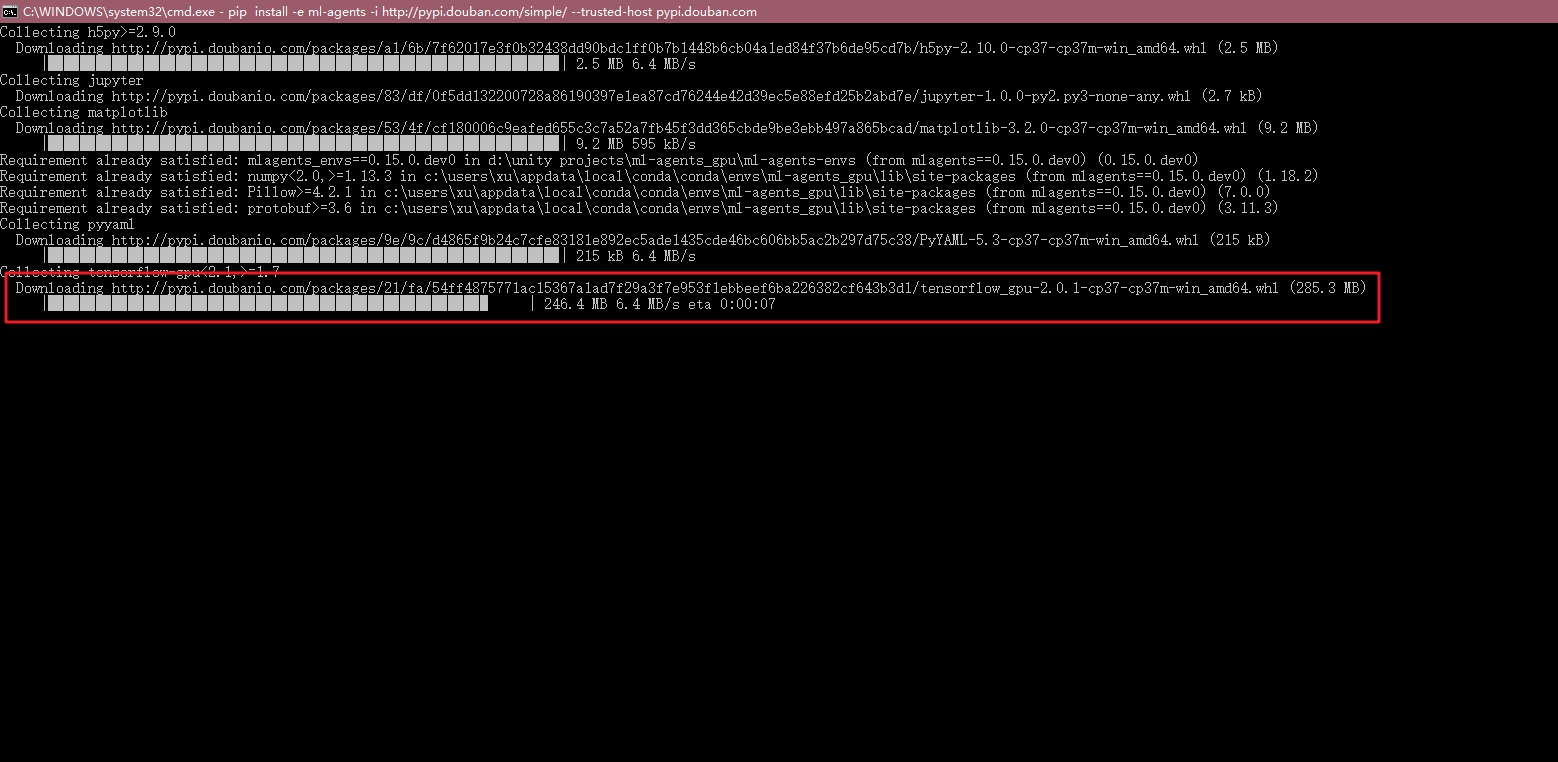
就是分别安装两个环境,可以发现他会自动下载tensorflow_gpu-2.0.1,如下图:
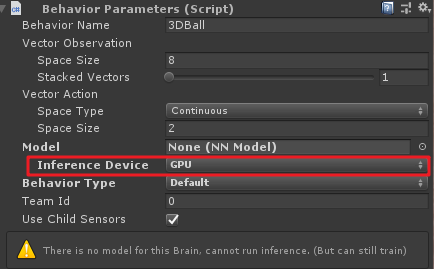
配置好后,在Unity对应的Agent脚本上,也需要将Inference Device勾选为GPU,然后按以前的方法开始训练,就可以了。
二、3DBall介绍
官方示例中,3Dball是一个比较简单的例子,主要运用了reinforcement learning(强化学习)。就是小球在平台上,萌版平台要控制自己绕x、z轴旋转,从而保持小球在自己头上不掉下来。
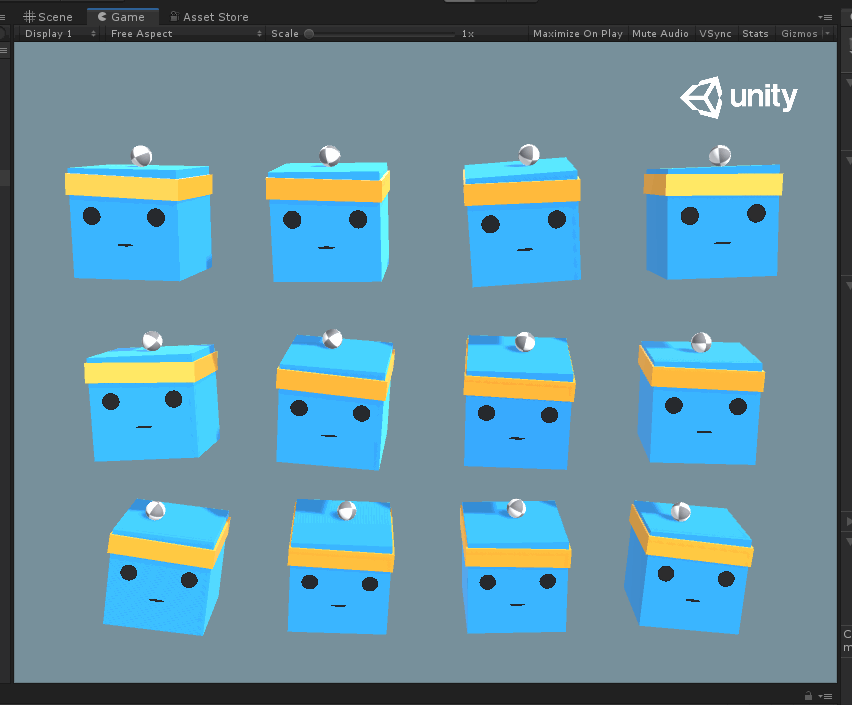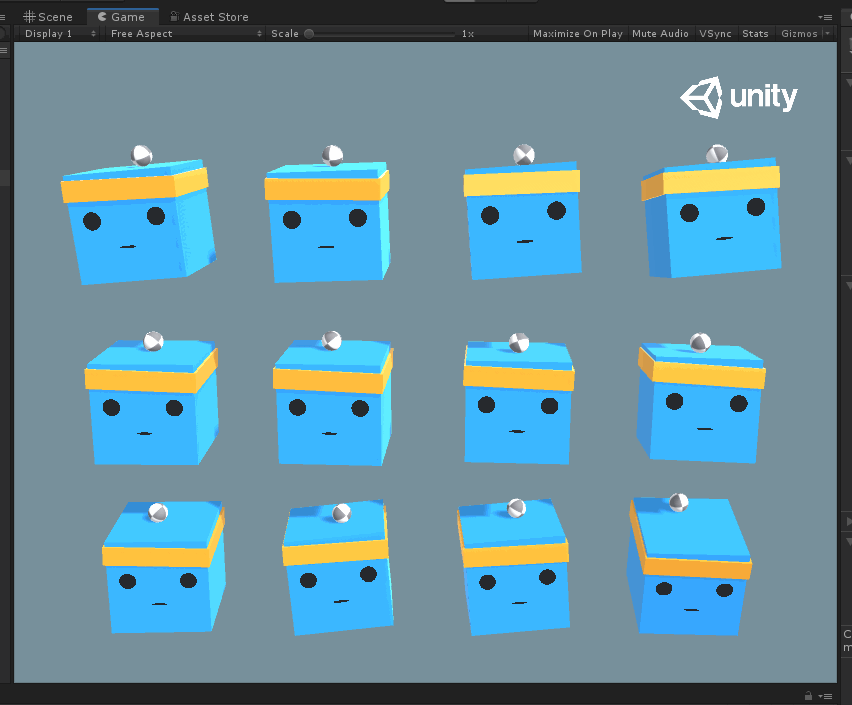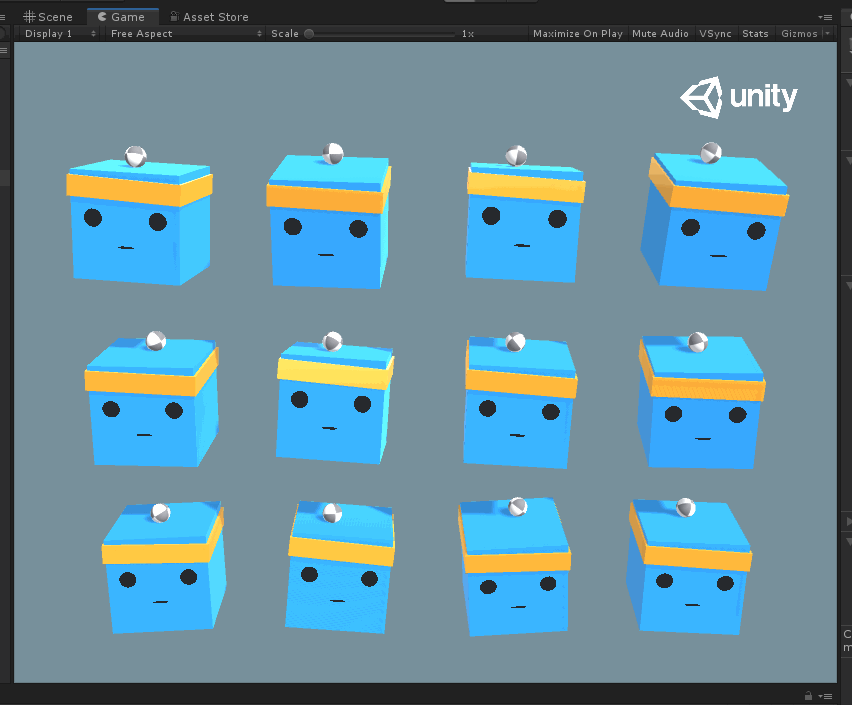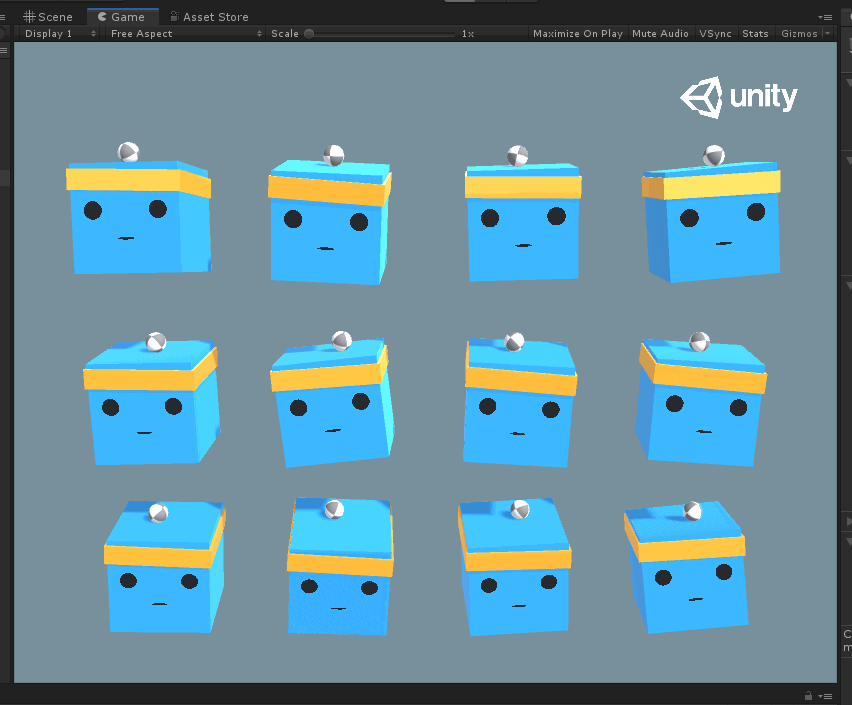
现根据官方文档翻译一下:
-
设置:一个平衡球任务,agent需要保持小球在其脑袋上的平衡
-
目标:Agent必须尽可能长时间地保持球在头顶的平衡
-
Agent设置:环境中包含12个想同类型的agent,全部使用同样的行为参数
-
Agent奖励设置:
-
小球每一步保持在方块头顶上就奖励+0.1
-
如果小球掉落,惩罚-0.1
-
-
行为参数
- 矢量观察空间:8个变量,包括agent方块的旋转角度(两个值,x、z轴方向),球和方块之间的相对位置关系(Vector3),球上刚体的速度(Vector3)
- 矢量动作空间:类型为
Continuous,Size为2,分别控制绕x轴旋转、绕z轴旋转
-
Float属性:三个
- scale(比例):小球的比例,默认为1,推荐最小值为0.2,最大值为5
- gravity(重力):重力加速度,默认为9.81,推荐最小值4,最大值为105
- mass(质量):小球的质量,默认为1,推荐最小值为0.1,最大值为20
-
基准平均奖励:100
OK,上面是借鉴官方文档,随意翻译了一下,大概可以了解3DBall主要用途和一些主要参数,里面的Float属性我这里不是很明白,在代码中是用在Agent.InitializeAgent()中的SetResetParameters(),这个方法顾名思义应该是对Agent进行初始化的操作。也许在这里,我们可以任意修改小球的比例、质量、重力加速度来改变小球在不同的情况下,训练的效果如何吧。
三、3DBall代码分析
看到目前为止,ml-agents其中的精华就在agent的脚本如何设置了,我们下面来分析一下Ball3DAgent代码。
初始化
public class Ball3DAgent : Agent
{
[Header("Specific to Ball3D")]
public GameObject ball;
Rigidbody m_BallRb;
IFloatProperties m_ResetParams;
public override void InitializeAgent()
{
m_BallRb = ball.GetComponent<Rigidbody>();
m_ResetParams = Academy.Instance.FloatProperties;
SetResetParameters();
}
public void SetBall()
{
//从Academy中获取小球的属性(质量、比例)
m_BallRb.mass = m_ResetParams.GetPropertyWithDefault("mass", 1.0f);
var scale = m_ResetParams.GetPropertyWithDefault("scale", 1.0f);
ball.transform.localScale = new Vector3(scale, scale, scale);
}
public void SetResetParameters()
{
SetBall();
}
}
这里初始化应用了InitializeAgent()方法,这里获取了小球的刚体,并且利用SetBall()来设置了小球的质量和比例,这里的的m_ResetParams变量是Academy的FloatProperties变量,这里的变量好像是会作为环境参数传递给Python,具体的用途我也还没研究清楚,姑且先看做是初始化小球的属性。
环境观察值
直接上源码。
public override void CollectObservations(VectorSensor sensor)
{
//平台绕Z轴旋转值
sensor.AddObservation(gameObject.transform.rotation.z);
//平台绕X轴旋转值
sensor.AddObservation(gameObject.transform.rotation.x);
//小球与平台的相对位置
sensor.AddObservation(ball.transform.position -gameObject.transform.position);
//小球刚体的速度
sensor.AddObservation(m_BallRb.velocity);
}
以上一共运用了8个观察值,注意Vector3类型的变量算是3个观察值(x,y,z)。
在Ball3DHardAgent项目里,与Ball3DAgent的区别就在于这里少了小球刚体速度的收集,从而导致前者在其他设置都相同的情况下,训练效果不佳,如下图。
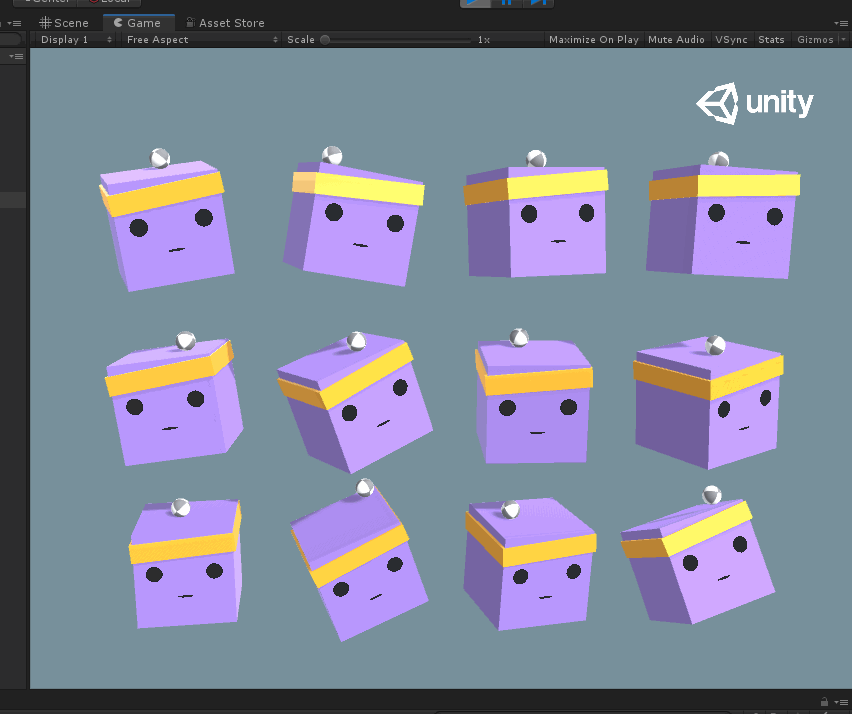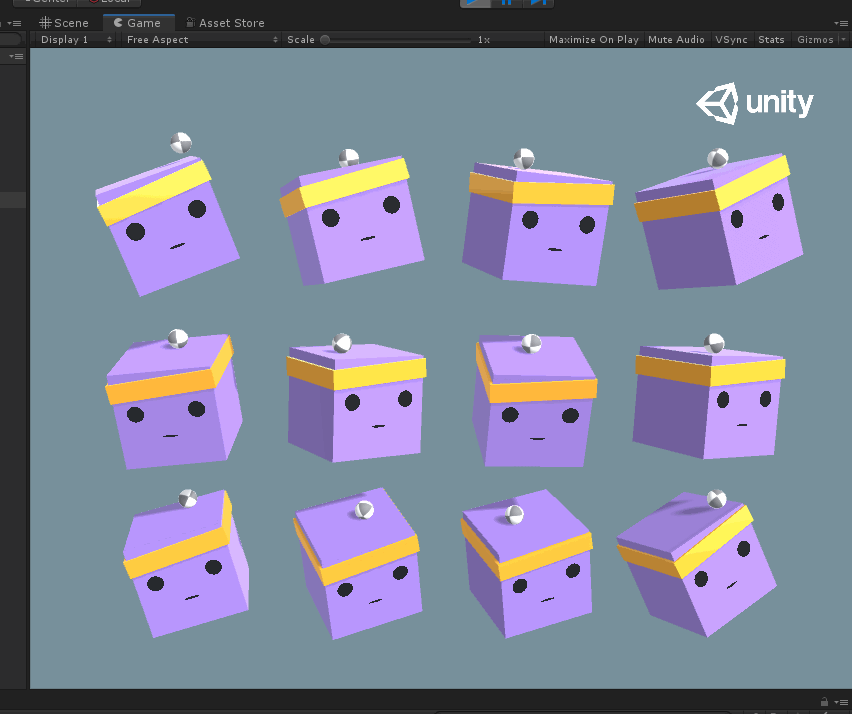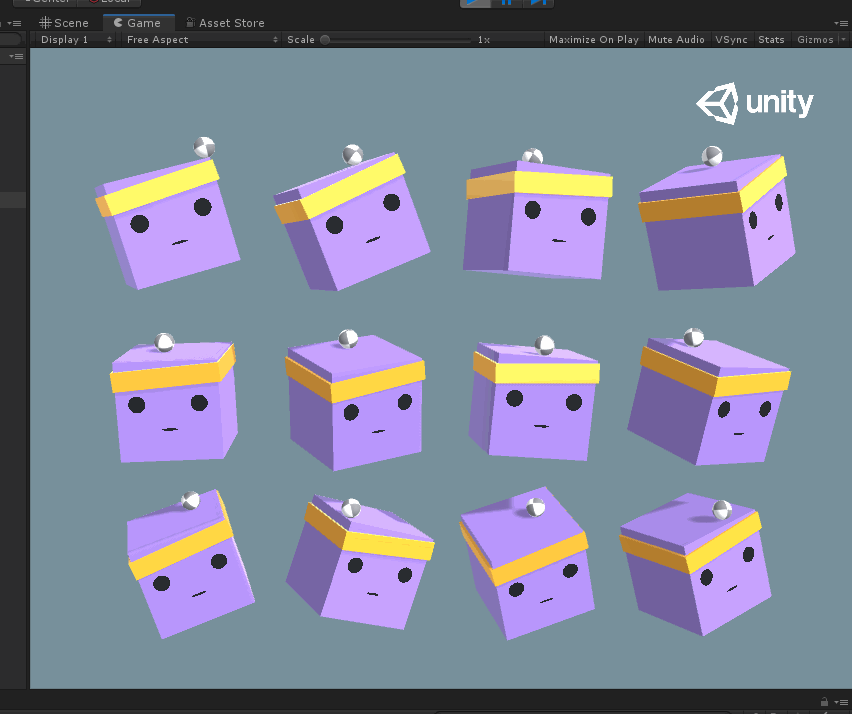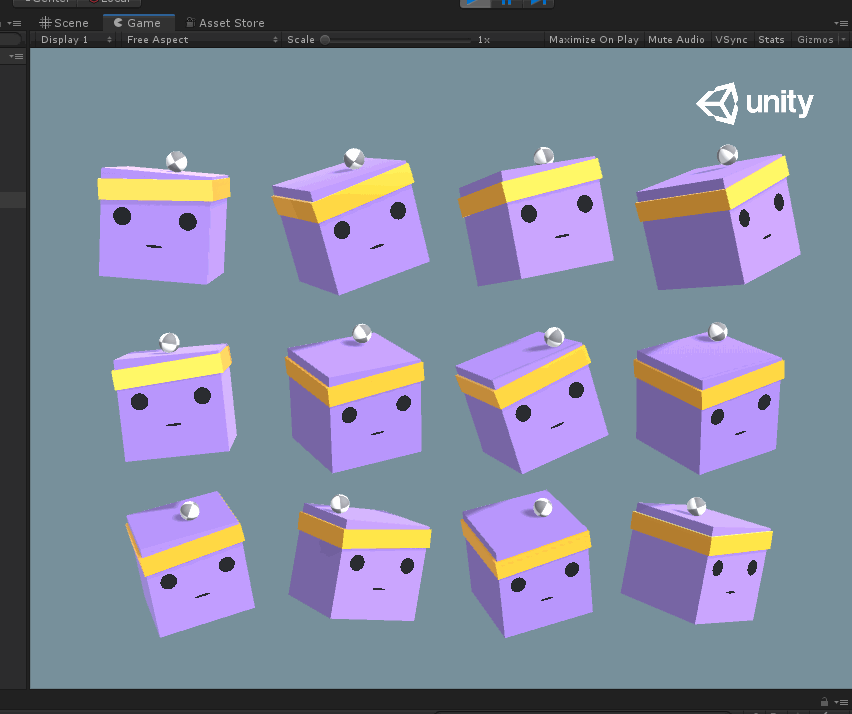
可以看到平台的抖动很大,就是因为没有考虑到小球的速度影响而导致训练结果天差地别,因此在用ML-Agents的时候,需要严谨的考虑环境的观测项,可能由于一个观测项的增加或删除,就导致最终学习结果的好坏,这里我也是慢慢才学习,这就是我为什么要先研究官方的示例,到时候最坏也可以照猫画虎。
Agent动作反馈
这里是Agent的核心实现,观测值通过Agent收集到Brain处,Brain再通过外部Python训练环境反馈动作,再沿相同的路线返回到Agent的AgentAction(float[] vectorAction)上(这里不知道我的想法对不对),具体的代码如下。
public override void AgentAction(float[] vectorAction)
{
//控制平台绕Z轴、X轴旋转的值
//用Mathf.Clamp()将响应的动作值限制到-2到2
var actionZ = 2f * Mathf.Clamp(vectorAction[0], -1f, 1f);
var actionX = 2f * Mathf.Clamp(vectorAction[1], -1f, 1f);
//平台绕Z轴旋转响应
if ((gameObject.transform.rotation.z < 0.25f && actionZ > 0f) ||
(gameObject.transform.rotation.z > -0.25f && actionZ < 0f))
{
gameObject.transform.Rotate(new Vector3(0, 0, 1), actionZ);
}
//平台绕X轴旋转响应
if ((gameObject.transform.rotation.x < 0.25f && actionX > 0f) ||
(gameObject.transform.rotation.x > -0.25f && actionX < 0f))
{
gameObject.transform.Rotate(new Vector3(1, 0, 0), actionX);
}
//gameObject.transform.Rotate(new Vector3(0, 0, 1), actionZ);
//gameObject.transform.Rotate(new Vector3(1, 0, 0), actionX);
//当小球在平台上,掉落或飞出平台,分别进行奖励或惩罚
if ((ball.transform.position.y - gameObject.transform.position.y) < -2f ||
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f ||
Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f)
{
SetReward(-1f);//惩罚1
Done();//此次训练结束并重新开始,会调用AgentReset()
}
else
{
SetReward(0.1f);//在平台上的时候,每次动作都奖励0.1
}
}
首先是平台对于旋转的响应,我又将两个if的条件去掉训练了一下,发现平台训练过程中比较不稳,抖动较大,因为只要一来值就让平台旋转,可能这里会造成平台一直在调整姿态的过程中,而源代码中,以绕Z轴为例,只有在平台Z轴旋转值<0.25f且actionZ>0、或平台Z轴旋转值>0.25f且actionZ<0时才对平台的姿态进行动作,这样就相当于设置了一个缓冲区间,不会让平台不停调整姿态,而是根据小球情况来适当调整姿态。
这里附上两次训练的tensorboard。
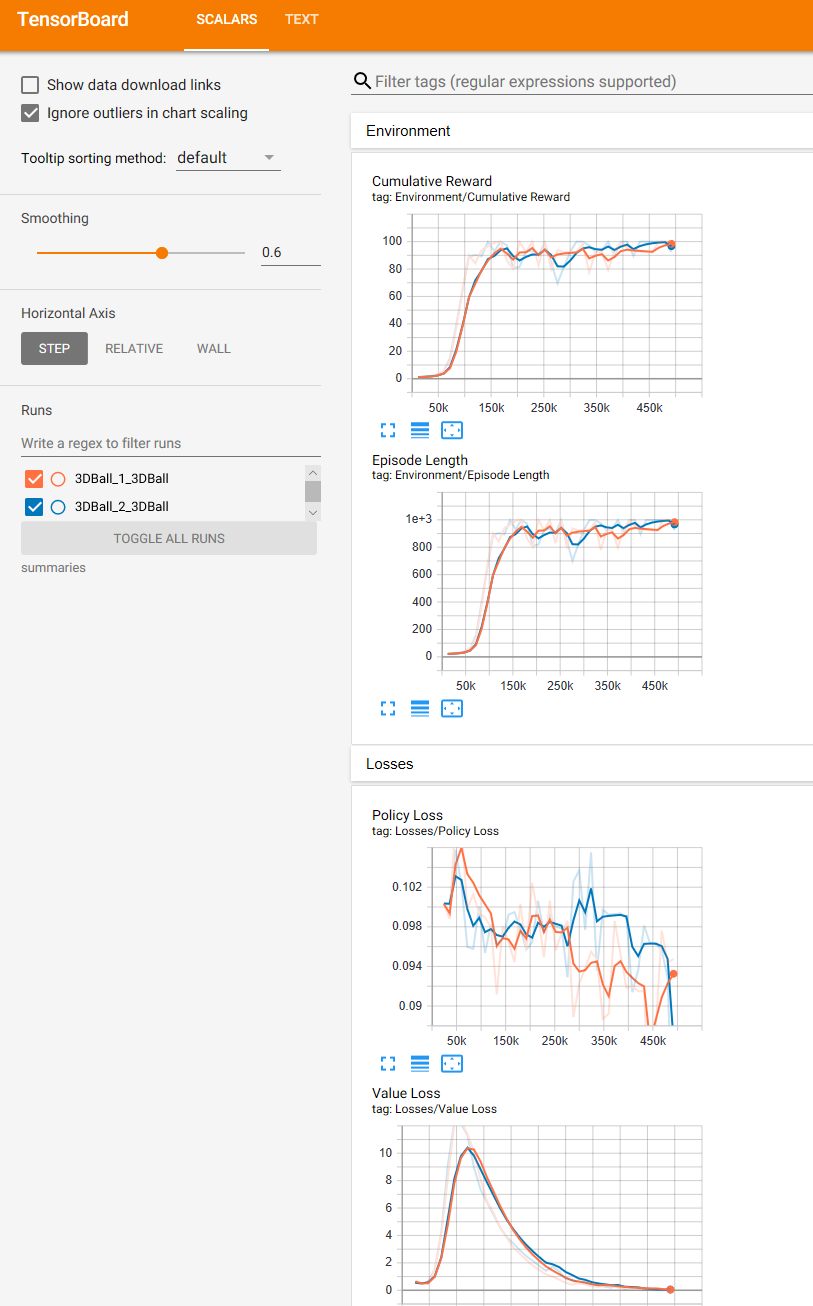
红色的是不加if条件的,蓝色的是官方加if的。其实从数据来看,大的趋势都差不多,不过我从训练现象来看,确实官方加if之后训练过程比较稳定。
后面的奖励代码中,有三个条件判断小球应该受到惩罚。
-
(ball.transform.position.y - gameObject.transform.position.y) < -2f
小球与平台y方向上的差值小于2,如下图:
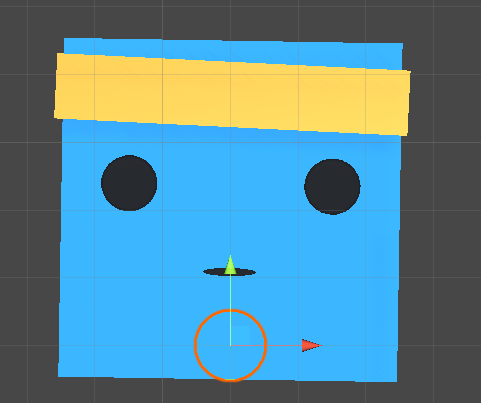
这里可以看出是小球掉落到平台下边,其实大多数情况是其他两种情况。
-
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f
和Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f
这两种放一起将,先来看看小球的位置:
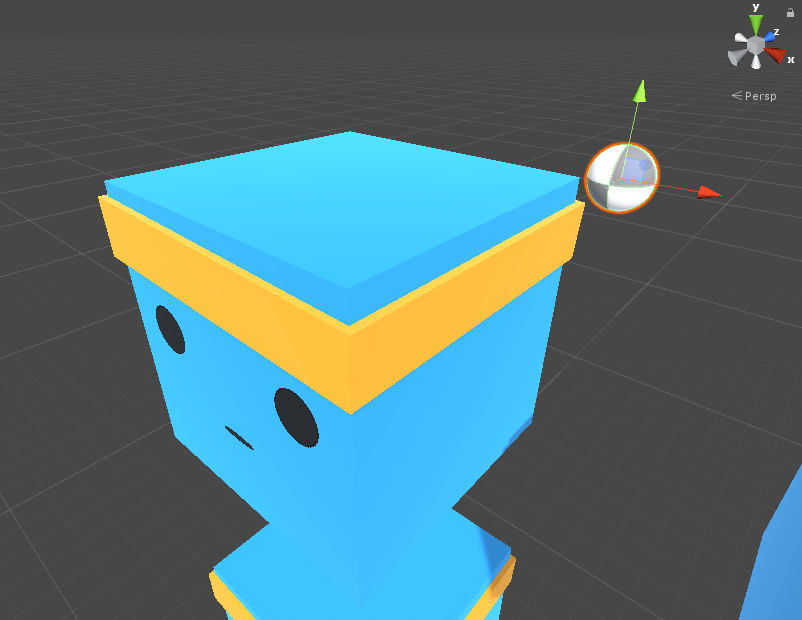
此时小球的x,z值都是3,可以看出小球刚好在x轴方向或者z方向滚出了平台边缘。
所以,上面三种情况只要发生一种就对小球Agent做出-1惩罚,同时调用Done()。
Agent复位
复位就比较简单了,来看代码:
public override void AgentReset()
{
//复位平台旋转角度
gameObject.transform.rotation = new Quaternion(0f, 0f, 0f, 0f);
//令平台随机绕x轴旋转-10~10度
gameObject.transform.Rotate(new Vector3(1, 0, 0), Random.Range(-10f, 10f));
//令平台随机绕z轴旋转-10~10度
gameObject.transform.Rotate(new Vector3(0, 0, 1), Random.Range(-10f, 10f));
//小球刚体速度变为0
m_BallRb.velocity = new Vector3(0f, 0f, 0f);
//小球在y(相对平台高度)为4的地方,同时随机x、z值出现
ball.transform.position = new Vector3(Random.Range(-1.5f, 1.5f), 4f, Random.Range(-1.5f, 1.5f))
+ gameObject.transform.position;
//Agent重置时,同时重置参数,[Obsolete]这里是指小球的质量和比例,其实我觉得这里没必要,估计之后别的项目有用
//[new]这里重新设置泛化参数,具体见本博“ML-Agents(四)3DBall补充の引入泛化”
SetResetParameters();
}
这里的代码比较简单,注释能看明白即可。
Agent手动设置
这里主要是当训练模式为Heuristic Only时调用,具体设置如下:
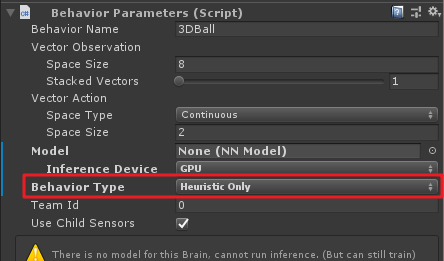
代码如下:
public override float[] Heuristic()
{
var action = new float[2];
action[0] = -Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}
这里的代码相当于我们输入来控制动作向量空间的值,其实就是action[]数组,我们令action[0]控制平台绕x轴的旋转,action[1]控制平台绕z轴的旋转。
可以试一下,其实要保持小球在平台上还有点难度。
至此第一个例子就研究到这,有什么问题欢迎大家一起探讨。
写文不易~因此做以下申明:
1.博客中标注原创的文章,版权归原作者 煦阳(本博博主) 所有;
2.未经原作者允许不得转载本文内容,否则将视为侵权;
3.转载或者引用本文内容请注明来源及原作者;
4.对于不遵守此声明或者其他违法使用本文内容者,本人依法保留追究权等。

