gkENGINE渲染优化
gkENGINE上次总结了一篇开发总结(上)。然后二进制DEMO发到了OPENGPU上,算是引起了挺多的关注。
友情链接一下,openGPU帖子:
效率这个问题被很多大牛提及,因此,正在撰写的开发总结(下)被我停了下来。认真的分析渲染流程,找到性能瓶颈,尝试修改,突破。再分析新的性能瓶颈,尝试修改,突破...
整个优化完成下来,渲染器结构也重构了不少,接下来继续总结渲染流程应该更加得心应手。
题外话:gkENGINE之前的二进制DEMO已经上传至项目主页
https://gkengine.codeplex.com/
gkENGINE 项目已经决定开源,代码正在整理中,准备工作完毕后就上传至codeplex托管,欢迎到时各位朋友捧场,相互学习!
终于,经过两周的业余时间,把DEMO的开场镜头的效率提升到了240%。期间的一些有意思的分析和优化方法,值得记录一下。
MISSON START
当时是一个周末,先在程序中将DEMO中截图的那个镜头锁定了下来。然后开始用Intel GPA这个图形分析工具开始分析。
插一句,GPA是Intel出品的一款图形分析工具。类同DirectX SDK自带的PIX和 Nv著名分析工具PerfHUD。GPA的最大优势是使用便捷,稳定性高。个人认为这是PIX和perfHUD的弊端。因此一般的简单分析任务我都选用GPA来完成。
工具的下载页面在这里:http://software.intel.com/en-us/vcsource/tools/intel-gpa
不过要说的一点是,虽然GPA已经更新到了2013 R2版本。但是个人觉得最好用的还是历史的4.3版。对nvidia, ati的显卡支持得不错。后继版本的支持就显得不那么友好了。并且坑爹的是,好像Intel官方不再提供以前的版本,需要在其他网站搜索下载...
接下来,便得到了精确的GPU时间数据和各阶段的详细资源:

渲染效率:GTX560 104frame/s 9.6ms/frame
这是对0425DEMO版本,第一个镜头的GPA时间分析。简要分析,将一些不太合理的瓶颈标红,如下:
SSAO:全屏的AO计算,占用了整体场景着色时间的一半。
SHADOWMASKGEN:阴影mask的生成,总体消耗的时间和SSAO等同。
POSTPROCESS:FOG, HDR, DOF等后处理效果,消耗时间也很高。
REFLECTMAP: 反射图的生成,在此场景中没有水面,REFLECT MAP的生成应该被裁剪掉。
第一轮,与分辨率的战斗
以上的瓶颈,都是后处理算法,都是像素计算密集型的渲染算法,因此,如果能够在基本保证渲染质量的情况下,显著的降低像素计算复杂度,那么性能将会得到成倍的提升。
1. SSAO优化
SSAO的shader,汇编指令169, 11个采样指令。1280x720分辨率,每帧执行92W次。根据场景复杂度,优化了一下旋转纹理的采样方式,使用半分辨率的SSAO处理(降采样)。可以将计算量降低为1/4,而质量下降很低。
2. ShadowMask优化
采用相同策略,使用半尺寸渲染,将计算量降为1/4。不过这时在后面的着色阶段,会产生渲染错误。

如图,由于MASK采用半尺寸,因此在全尺寸的着色阶段,会由于线性采样,在阴影和受光的交界像素处采样到非阴影值(树干的边缘,后面的茅屋阴影有非阴影白边)。
解决的办法是,在着色阶段,在采样点都右下方像素多采样一个阴影值,两者取最小值作为当前像素的阴影值,过滤掉这个渲染错误。这个解决方案也有必然的弊端:可能会在本身没有阴影的地方产生一定程度的阴影黑边。但是相对白边,黑边造成的瑕疵完全可以接受。
3. POST PROCESS优化
之前的POSTPROCESS有很多RT来回倒腾的操作(紫色的矩形块)。经过RT的合理分配和顺序调整,可以去掉一些RT STRETCH的操作,提高POST-PROCESS的效率。
4. 终极优化 - 可变渲染分辨率
之前都是针对各种特性渲染的降采样,来降低像素计算压力。但是在移动平台上,提升依然不是太明显,因此,需要一个终极的解决方案。经过PHOTOSHOP里测试,使用3/4的尺寸渲染,然后“放大”到全尺寸。最终的画面质量下降不是太大。但是像素计算量能直接下降为接近1/2。带来的性能提升是十分显著的。因此在之前的texture管理器中添加了一个scale属性。对除BACKBUFFER之外的所有纹理进行降采样处理。渲染完成后,STRETCH到BACKBUFFER上。
第二轮,解决新问题
第一轮优化暂告一段落,和分辨率的斗争结束了。渲染效率直接提升了接近100%。当时就在OPENGPU上补充了一个跟帖,效率的确是提上去了,不过也有坛友提出质量下降的问题。
1. 为低分辨率渲染添加锐化pass

如上图所示,的确,使用3/4的渲染分辨率,少了近一半的像素,质量下降难免,如坛友所说,结果像是图片经过了质量压缩。但是这个下降是否可以再补偿回来一些呢?
经过一些调研,轻微的尺寸缩放可以通过锐化来补偿。于是开始尝试之前做过的锐化算法,将图像进行微弱的高斯模糊,再利用模糊结果和原图进行线性外插,强化像素的“反差”,达到锐化目的。
color = lerp( blur, curr, sharpvalue ); // sharpvalue取值大于1
2. 使用手动MIPMAP解决地形颗粒感过重的问题
对于有坛友提出的颗粒感过重的问题,因为terrian的多层混合是直接在shader中计算的,由于纹理的重复采样是直接在shader总通过frac得出,因此打开mipmap会有采样错误(由于frac计算出的texcoord不连续),之前图省事直接关闭了mipmaping。因此这里用了一个简单的方法,解决这个问题:利用像素的线性深度,手动计算应该采样的mipmap层数(避免使用自动的ddx计算,造成地块间的不连续值),然后使用texlod来取得对应Mipmap的值。
这时再观察GPA的数据。

这时之前的几个瓶颈已经被压到合理的消耗范围。渲染时间大部分集中在了shadowmap生成,zpass, general pass上。这算是一个合理的渲染管线消耗分配了。
但是也可以注意到,图标中标黄的两个消耗块,占据了相当大的时间,已经超过了SSAO和SHADOWMASK的消耗。
这两个消耗,就是地形系统中占屏幕像素最大的那个block。分析他们的shader assembly,发现每个像素采样的次数达到了惊人的26次!(zpass 7次, general pass 19次)
3. tex2dlod和tex2dgrad的选择
而仔细看却发现tex_ld, tex_ldl的次数却没有那么多,通过搜素发现,原来tex2dlod这个函数可以显式的指定lod层数,消耗比tex2d, tex2dgrad都要大。在GPA中会显示两次采样指令。
因此,将tex2dlod的方式改为tex2dgrad, 手动计算ddx送入插值而非直接指定mip层数。像素采样次数直接砍半。
4. 高光纹理合并到diffuse的alpha通道
同时,发现地形纹理使用高光贴图稍微有些浪费,索性直接将高光值做成单色存入diffuse的alpha,砍掉采样高光纹理的消耗。
至此,地形block的采样次数从26次降低到了9次,地形block的渲染消耗直接降到了50%。
第三轮,引入混合渲染管线
经过前两轮优化,基本上性能已经被榨干至极限了。不开启锐化的情况下,在720p分辨率在GTX560上已经能跑到260FPS以上,接下来想要在保证画面质量的情况下,进一步尝试一下优化,突破点大概只有几点了:
- 1. 降低DP
- 2. 降低shader复杂度
对于第二点,要保证渲染效果不变,这将是个漫长的优化-测试的循环过程。
对于第一点,目前渲染管线是Deferred Lighting(延迟光照),CryEngine3使用的是这个方式。
优点:在拥有延迟渲染解耦光照运算的优势下,能保证主光源丰富的材质效果,同时获得一个低带宽开销的渲染流程。
缺点:所有不透明物体需要渲染两次:Zpass一次,输出法线和线性深度,GeneralPass一次,利用生成好的光照数据,和主光源,进行传统的材质运算。
而Crytek在GDC2013的演讲中提出了Hybird Deferred Shading的概念,将之前实现的延迟光照和传统的延迟渲染进行混合,对于普遍材质使用延迟渲染方式,只需要一次渲染调用。而对于复杂材质,和以前一样走延迟光照的渲染流程。
因此,我决定先引入传统的DeferredShading实现,先观察效率,并做成可以实时灵活切换渲染管线的架构,再考虑进一步的混合渲染方式。
而要引入混合可切换的延迟渲染管线,就需要对之前的渲染流程进行改造。之前的流程是
shadowmapgen -> zpass -> ssao -> deferred lighting -> shadowmask -> general pass -> fog/hdr/dof -> msaa -> output
对于传统延迟渲染,大体流程都是需要的,但是在zpass, deferred lighting, general pass阶段是需要有不同的算法流程
于是我将各个阶段抽象成IBasePipe, 通过策略模式,将算法包装进Pipe的派生类,然后主渲染流程调用各个pipe执行,选择对应的pipe实现进行渲染算法的组织。
因此,渲染流程变为了
pipe[shadowmapgen] -> pipe[zpass] -> pipe[ssao] -> pipe[shadowmask] -> pipe[deferred lighting] -> pipe[general pass] -> pipe[postprocess] -> output
同时,延迟渲染还需要新的zpass和最后的合成pass的shader,同时,因为不能使用独立的generalpass了,因此之前的一些特殊材质效果一定需要损失。
对于G-BUFFER,之前的配置是DEPTH|R32F + NORMAL+GLOSS|RGBA8。而延迟渲染需要记录物体的材质信息,所以至少需要多添加一层ALBETO颜色信息,所以GBUFFER在原有的基础上扩展了一个ALBETO DIF+SPEC|RGBA8的MRT。用于输出ALBETO颜色和单色的高光。
对于物理属性,诸如:FRESNEL等,暂时没有写入。后期考虑压缩NORMAL,在NORMAL中多开辟一个通道来存储。
渲染流程改为deferred shading后,DP少了一半,G-BUFFER的带宽压力增加了50%。但总体下来效率还是提高了5%左右。
可惜的是,deferred shading要求更加统一的材质属性设置。所以,之前为延迟光照设置的材质属性,在延迟渲染下表现有了差异。考虑到提升并不明显,因此还是默认使用deferred lighing渲染管线。
MISSION ACCOMPLISHED
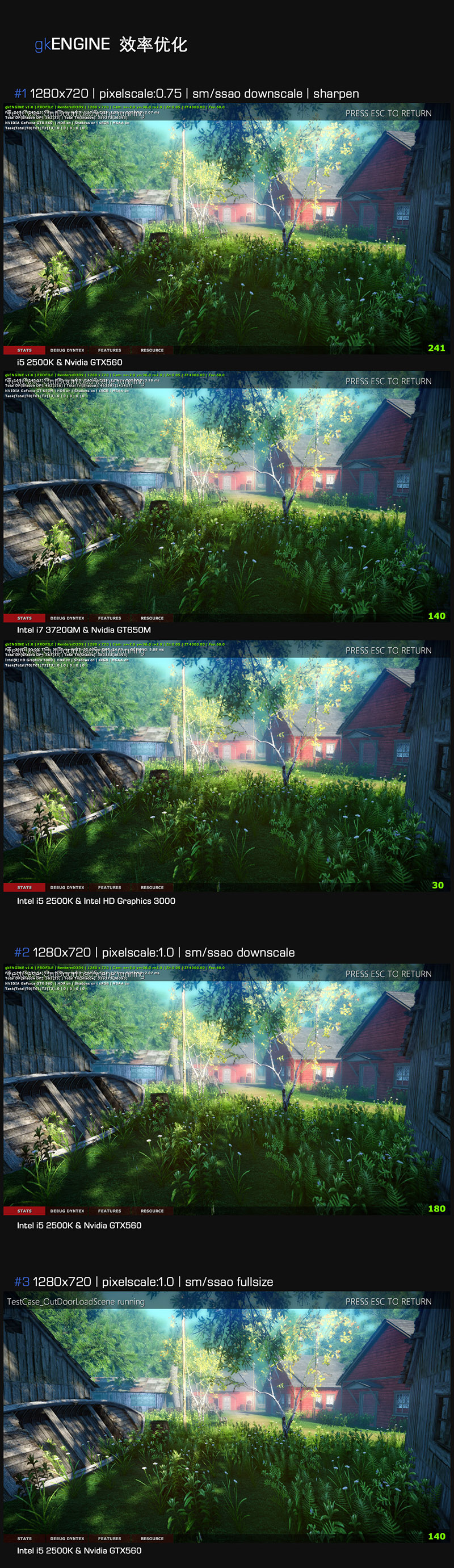
任务完成,总结一下最终的效率。
渲染配置:
1280 x 720分辨率, 35.9W三角面, 362 DrawCall
特效全开
0.75的渲染尺寸,ssao, shadowmask一倍降采样
测试结果:
| 测试平台 | 帧率 | 帧时间 |
| Intel i5 2500K & Nvidia GTX560 | 241FPS | 4.14ms |
| Intel i7 3720QM & Nvidia GT650M | 140FPS | 7.14ms |
| Intel i5 2500K & Intel HD Graphics 3000 | 30FPS | 33.33ms |
效果对比:
最下面的两张渲染结果分别是全渲染尺寸 和 shadow, ssao全尺寸的渲染结果。基本代表了优化开始时的渲染质量。
出处:http://gameknife.cnblogs.com/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

