
Akka源码分析-深入ActorRef&ActorPath
上一节我们深入讨论了ActorRef等相关的概念及其关系,但ActorRef和ActorPath的关系还需要再加以分析说明。其实还是官网说的比较清楚。
“A path in an actor system represents a “place” which might be occupied by a living actor. Initially (apart from system initialized actors) a path is empty. When actorOf() is called it assigns an incarnation of the actor described by the passed Props to the given path. An actor incarnation is identified by the path and a UID.”
“A restart only swaps the Actor instance defined by the Props but the incarnation and hence the UID remains the same. As long as the incarnation is same, you can keep using the same ActorRef. Restart is handled by the Supervision Strategy of actor’s parent actor, and there is more discussion about what restart means.
The lifecycle of an incarnation ends when the actor is stopped. At that point the appropriate lifecycle events are called and watching actors are notified of the termination. After the incarnation is stopped, the path can be reused again by creating an actor with actorOf(). In this case the name of the new incarnation will be the same as the previous one but the UIDs will differ. An actor can be stopped by the actor itself, another actor or the ActorSystem”
“An ActorRef always represents an incarnation (path and UID) not just a given path. Therefore if an actor is stopped and a new one with the same name is created an ActorRef of the old incarnation will not point to the new one.”
我们总结一下官网的说明。开发者自定义的Actor通过actorOf创建的时候,都会分配一个UID,actor的路径(层级关系)+UID唯一标志一个Actor实例,也就是所谓的ActorRef。
@tailrec final def newUid(): Int = {
// Note that this uid is also used as hashCode in ActorRef, so be careful
// to not break hashing if you change the way uid is generated
val uid = ThreadLocalRandom.current.nextInt()
if (uid == undefinedUid) newUid
else uid
}
上面是UID的生成方法,其实就是一个随机数,这样可以保证每次生成的UID不重复。从官网描述来看,这个uid就是ActorRef的hashCode值。
在Actor完整的生命周期过程中,也就是没有被terminate,UID不会发生变化,即使Actor发生了restart。但如要注意理解此处的restart,是指actor处理消息时抛出了异常,被监督者处理并调用了restart方法。这与Actor先stop,再actorOf创建是截然不同的。actorOf用同样的名字重新创建actor会导致Actor的UID发生变化,也就会导致ActorRef不会重新指向新创建的Actor,其实此时Actor的路径(层级关系)是相同的。
final override def hashCode: Int = {
if (path.uid == ActorCell.undefinedUid) path.hashCode
else path.uid
}
/**
* Equals takes path and the unique id of the actor cell into account.
*/
final override def equals(that: Any): Boolean = that match {
case other: ActorRef ⇒ path.uid == other.path.uid && path == other.path
case _ ⇒ false
}
我们来看一下abstract class ActorRef对hasCode和equals的定义就大概明白,UID的具体作用了,跟我们分析的是一致的。那我们来看看ActorPath的equals是如何定义的。
override def equals(other: Any): Boolean = {
@tailrec
def rec(left: ActorPath, right: ActorPath): Boolean =
if (left eq right) true
else if (left.isInstanceOf[RootActorPath]) left equals right
else if (right.isInstanceOf[RootActorPath]) right equals left
else left.name == right.name && rec(left.parent, right.parent)
other match {
case p: ActorPath ⇒ rec(this, p)
case _ ⇒ false
}
}
对上面的代码简单分析一下就会发下,ActorPath在计算是否相等时,除了判断当前的hashCode是否相同外,就是在递归的判断当前ActorPath的name是否相同,跟UID没有关系,虽然在ActorPath的定义中也有uid值,且Actor的uid就是保存在ActorPath中,但该uid是一个内部变量,且只提供给ActorRef使用。
我们再来看看Actor的restart过程。
final def invoke(messageHandle: Envelope): Unit = {
val influenceReceiveTimeout = !messageHandle.message.isInstanceOf[NotInfluenceReceiveTimeout]
try {
currentMessage = messageHandle
if (influenceReceiveTimeout)
cancelReceiveTimeout()
messageHandle.message match {
case msg: AutoReceivedMessage ⇒ autoReceiveMessage(messageHandle)
case msg ⇒ receiveMessage(msg)
}
currentMessage = null // reset current message after successful invocation
} catch handleNonFatalOrInterruptedException { e ⇒
handleInvokeFailure(Nil, e)
} finally {
if (influenceReceiveTimeout)
checkReceiveTimeout // Reschedule receive timeout
}
}
相信invoke大家应该知道这是做什么的了吧,所有发送个mailbox的用户消息都会通过调用invoke来处理。很明显在receiveMessage发生异常的过程中,如果不是致命错误,就会去调用handleInvokeFailure处理。
final def handleInvokeFailure(childrenNotToSuspend: immutable.Iterable[ActorRef], t: Throwable): Unit = {
// prevent any further messages to be processed until the actor has been restarted
if (!isFailed) try {
suspendNonRecursive()
// suspend children
val skip: Set[ActorRef] = currentMessage match {
case Envelope(Failed(_, _, _), child) ⇒ { setFailed(child); Set(child) }
case _ ⇒ { setFailed(self); Set.empty }
}
suspendChildren(exceptFor = skip ++ childrenNotToSuspend)
t match {
// tell supervisor
case _: InterruptedException ⇒
// ➡➡➡ NEVER SEND THE SAME SYSTEM MESSAGE OBJECT TO TWO ACTORS ⬅⬅⬅
parent.sendSystemMessage(Failed(self, new ActorInterruptedException(t), uid))
case _ ⇒
// ➡➡➡ NEVER SEND THE SAME SYSTEM MESSAGE OBJECT TO TWO ACTORS ⬅⬅⬅
parent.sendSystemMessage(Failed(self, t, uid))
}
} catch handleNonFatalOrInterruptedException { e ⇒
publish(Error(e, self.path.toString, clazz(actor),
"emergency stop: exception in failure handling for " + t.getClass + Logging.stackTraceFor(t)))
try children foreach stop
finally finishTerminate()
}
}
handleInvokeFailure我们也分析过,它给父actor发送了一个Failed消息,表明某个子actor发生了异常。
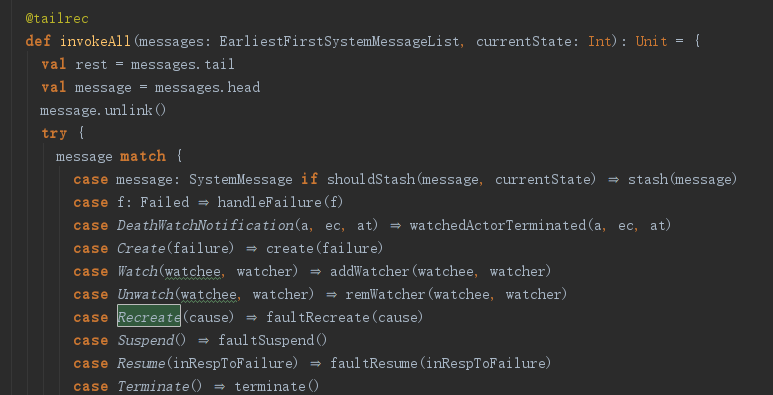
Failed属于系统消息,会去调用invokeAll,很显然调用了handleFailure处理异常。
final protected def handleFailure(f: Failed): Unit = {
currentMessage = Envelope(f, f.child, system)
getChildByRef(f.child) match {
/*
* only act upon the failure, if it comes from a currently known child;
* the UID protects against reception of a Failed from a child which was
* killed in preRestart and re-created in postRestart
*/
case Some(stats) if stats.uid == f.uid ⇒
if (!actor.supervisorStrategy.handleFailure(this, f.child, f.cause, stats, getAllChildStats)) throw f.cause
case Some(stats) ⇒
publish(Debug(self.path.toString, clazz(actor),
"dropping Failed(" + f.cause + ") from old child " + f.child + " (uid=" + stats.uid + " != " + f.uid + ")"))
case None ⇒
publish(Debug(self.path.toString, clazz(actor), "dropping Failed(" + f.cause + ") from unknown child " + f.child))
}
}
handleFailure中通过发生异常的Actor的ActorRef找到对应的Actor实例,然后去调用该Actor的监督策略对异常的处理方案,如果该actor无法处理该异常,则继续throw。
def handleFailure(context: ActorContext, child: ActorRef, cause: Throwable, stats: ChildRestartStats, children: Iterable[ChildRestartStats]): Boolean = {
val directive = decider.applyOrElse(cause, escalateDefault)
directive match {
case Resume ⇒
logFailure(context, child, cause, directive)
resumeChild(child, cause)
true
case Restart ⇒
logFailure(context, child, cause, directive)
processFailure(context, true, child, cause, stats, children)
true
case Stop ⇒
logFailure(context, child, cause, directive)
processFailure(context, false, child, cause, stats, children)
true
case Escalate ⇒
logFailure(context, child, cause, directive)
false
}
}
通过当前监督策略来判断如何处理异常,默认情况下,都是Restart,所以调用了processFailure方法。默认的监督策略一般是OneForOneStrategy
def processFailure(context: ActorContext, restart: Boolean, child: ActorRef, cause: Throwable, stats: ChildRestartStats, children: Iterable[ChildRestartStats]): Unit = {
if (restart && stats.requestRestartPermission(retriesWindow))
restartChild(child, cause, suspendFirst = false)
else
context.stop(child) //TODO optimization to drop child here already?
}
上面是OneForOneStrategy的processFailure方法实现,就是去调用restarChild。
final def restartChild(child: ActorRef, cause: Throwable, suspendFirst: Boolean): Unit = {
val c = child.asInstanceOf[InternalActorRef]
if (suspendFirst) c.suspend()
c.restart(cause)
}
restarChild最终又调用了发生异常的Actor的restart方法,是通过ActorRef调用的。通过前面的分析我们知道,这个ActorRef最终是一个RepointableActorRef。
def restart(cause: Throwable): Unit = underlying.restart(cause)
上面是restart的定义,我们发现又去调用了underlying的restart,真是很绕啊。underlying是啥?当然是ActorRef引用的ActorCell了啊。但是我们翻了ActorCell的代码并没有发现restart的实现!但是我们却在ActorCell混入的Dispatch中发现了restart的踪影!
final def restart(cause: Throwable): Unit = try dispatcher.systemDispatch(this, Recreate(cause)) catch handleException
很简单,就是使用dispatcher给当前的ActorCell发送了一个Recreate消息。通过前面invokeAll我们知道收到Recreate后调用了faultRecreate,这个函数我们也分析过,就是调用了原有Actor的aroundPreRestart函数,然后调用finishRecreate函数。
private def finishRecreate(cause: Throwable, failedActor: Actor): Unit = {
// need to keep a snapshot of the surviving children before the new actor instance creates new ones
val survivors = children
try {
try resumeNonRecursive()
finally clearFailed() // must happen in any case, so that failure is propagated
val freshActor = newActor()
actor = freshActor // this must happen before postRestart has a chance to fail
if (freshActor eq failedActor) setActorFields(freshActor, this, self) // If the creator returns the same instance, we need to restore our nulled out fields.
freshActor.aroundPostRestart(cause)
if (system.settings.DebugLifecycle) publish(Debug(self.path.toString, clazz(freshActor), "restarted"))
// only after parent is up and running again do restart the children which were not stopped
survivors foreach (child ⇒
try child.asInstanceOf[InternalActorRef].restart(cause)
catch handleNonFatalOrInterruptedException { e ⇒
publish(Error(e, self.path.toString, clazz(freshActor), "restarting " + child))
})
} catch handleNonFatalOrInterruptedException { e ⇒
clearActorFields(actor, recreate = false) // in order to prevent preRestart() from happening again
handleInvokeFailure(survivors, PostRestartException(self, e, cause))
}
}
finishRecreate中调用newActor产生了一个新的Actor实例,调用了该实例的aroundPostRestart函数,最后如果可能则循环调用子actor的restart函数。
在actor的restart的工程中,我们发现没有任何涉及ActorPath和ActorRef修改或更新的地方,更没有uid变更的地方。这样就意味着,Actor的restart过程中,ActorRef不会失效,ActorPath更不会失效。还记得actorOf的过程么,其中有一步调用了makeChild,里面调用newUid产生了一个新的uid值给ActorRef,所以Actor被stop掉,然后用actorOf重建之后,actorRef当然会失效了。
其实我们可以这样简单的理解,ActorRef = “ActorPathString” + UID。开发者自定义的Actor类是一个静态的概念,当类通过actorOf创建的时候,就会产生一个Actor实例,如果该Actor由于某种原因失败,被系统restart,系统会新生成一个Actor实例,但该实例的UID不变,所以ActorRef指向相同路径下的actor实例。ActorPath标志Actor的树形路径,通过它可以找到这个路径下的实例,但实例的UID是不是相同则不关心。

