
RNN Train和Test Mismatch
李宏毅深度学习
https://www.bilibili.com/video/av9770302/?p=8
在看RNN的时候,你是不是也会觉得有些奇怪,
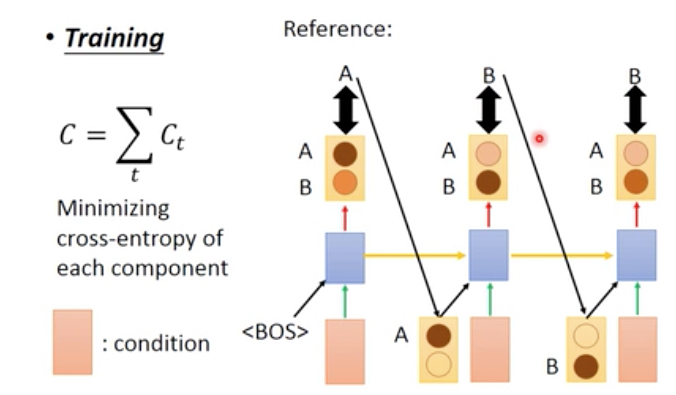
Train的过程中,
是把训练集中的结果作为下一步的输入
目标函数,是每一步的真实输出和训练集结果的交叉熵
Test的过程中,
是直接把每一步的输出作为下一步的输入
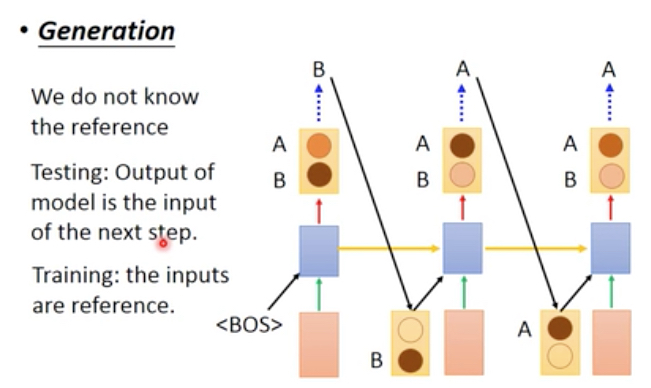
可以看到train和test的时候,每一步的输入是不一样的,这种不一致会带来什么问题?
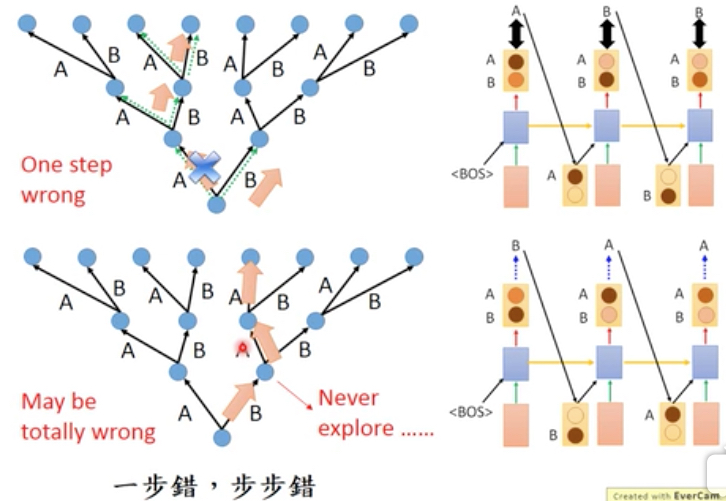
对上面的树形结构,
表示学习的过程,如果网络完全正确的学习到我们的训练集,那就是左边的分支
但如果网络只在第一步没有学对,选择了B,而不是A
那么在test的时候,面对相同的句子,
那么它第一步会选B,但我们之前大部分的学习到的知识都集中在左边的分支,而右边的分支在学习的时候没有碰到过
所以对于网络后续的选择都只能乱选
从这个例子可以看出来,这种mismatch所带来的问题
那么问题是,为什么train的时候,不也把真实的输出作为下一步的输入?

将真实输出作为下一步的输入,会导致网络很难训练
原因是,真实的输出是会变化的,
如上图,开始第一步的输出是B,那么第二步学到的是,输入是B的时候,我们也应该得到一个B
但是随着train的继续,第一步的输出会变成A,趋向正确的结果,这样,之前在第二步学的知识就没有用了,
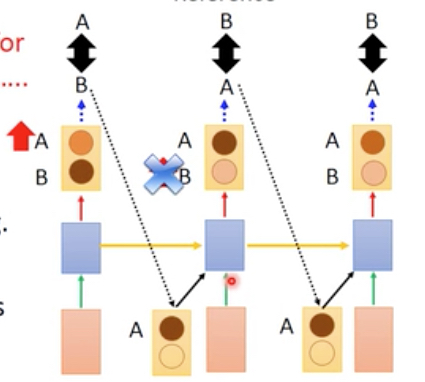
所以对于训练过程中,我们需要保持condition的稳定性
那到底应该怎么样做?
Scheduled Sampling的方法就是每次用一个随机sampling来决定是用哪一个作为下一步的输入

那这个方法不是也会有我们上面说的不稳定问题吗?
注意上面的曲线图,这里sampling的概率是不断变化的,图表示的是用reference的概率随着训练次数的变化
可以看出来,刚开始选reference的概率非常大,所以刚开始和普通的RNN训练没有区别
但是随着训练次数的增多,慢慢的用model的概率会越来越大
这样做的好处是啥,
因为刚开始的时候model不稳定,所以用reference,但是随着训练的进行,model的输出越来越稳定,这时就换成用medel的输出来训练
这样做的好处是,在condition相对稳定的情况下,又可以消除train和test的mismatch

