
AndrewNG Deep learning课程笔记 - CNN
参考,
An Intuitive Explanation of Convolutional Neural Networks
http://www.hackcv.com/index.php/archives/104/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
CNN基础
CNN网络主要用于compute vision
对于图片输入而言,是一种极高维度的数据,比如分辨率1000*1000*3的图,可能会产生3 billion的参数,这不太可行
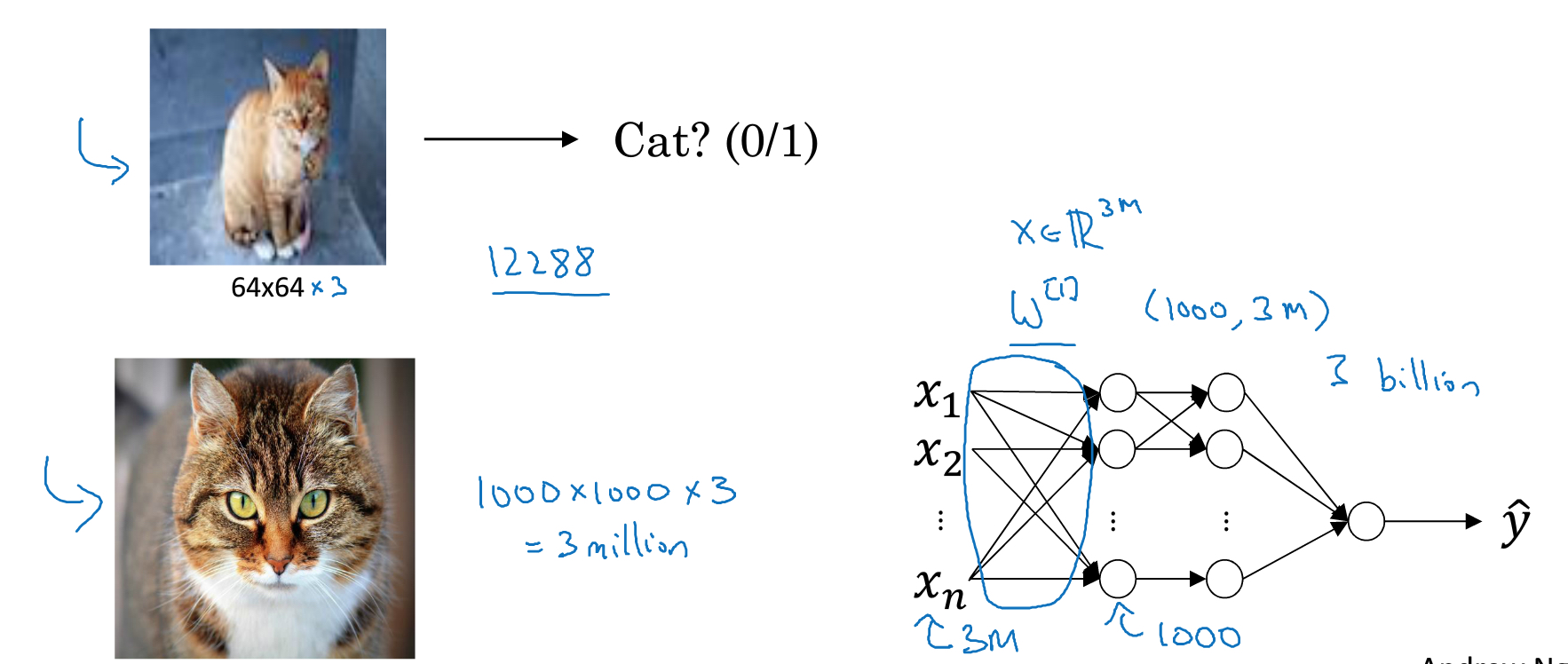
所以我要使用convolutional NN来解决这种问题,
首先看看什么是卷积操作,
如下图,
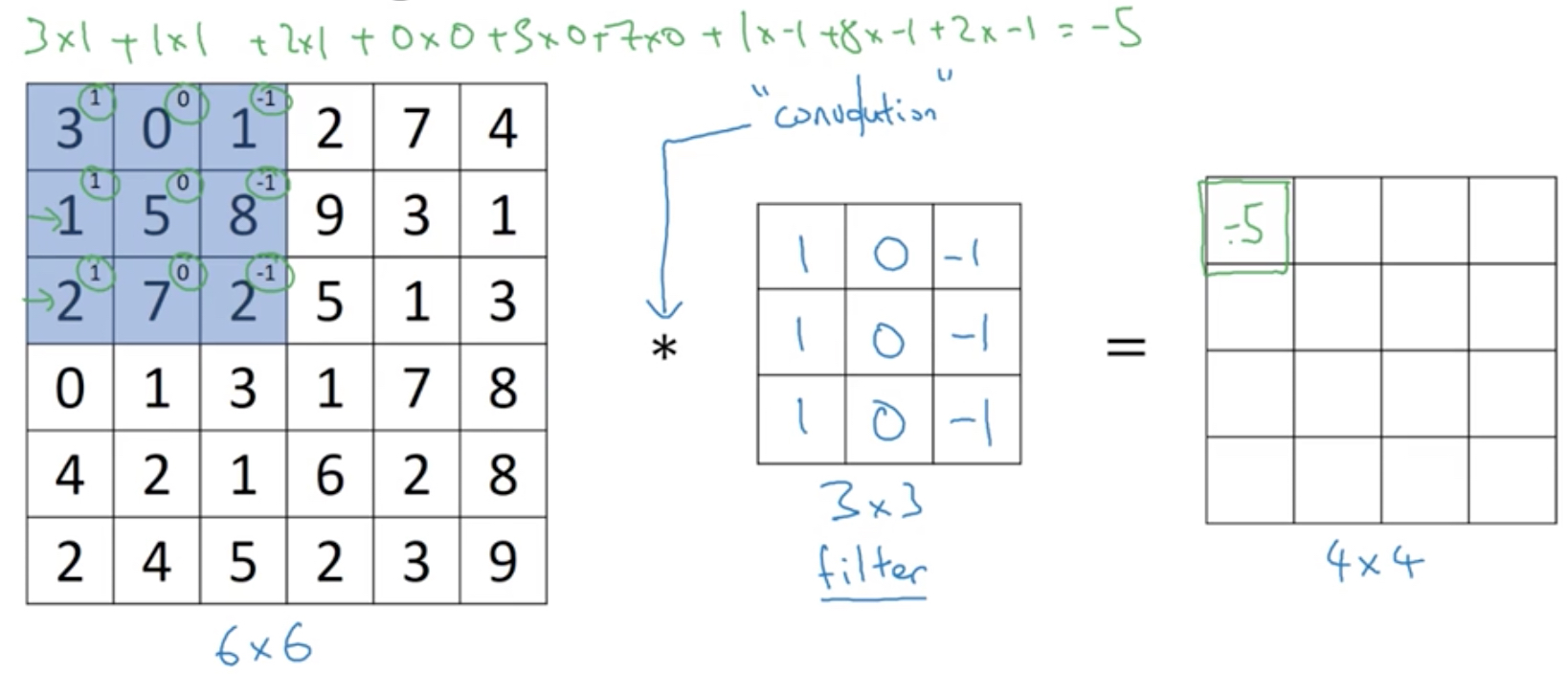
原图片6*6
中间3*3的矩阵,称为filter或卷积核kernel,它表示你需要匹配的模式,这里detect edge,竖线
最右边4*4的矩阵,就是进行卷积操作后的结果
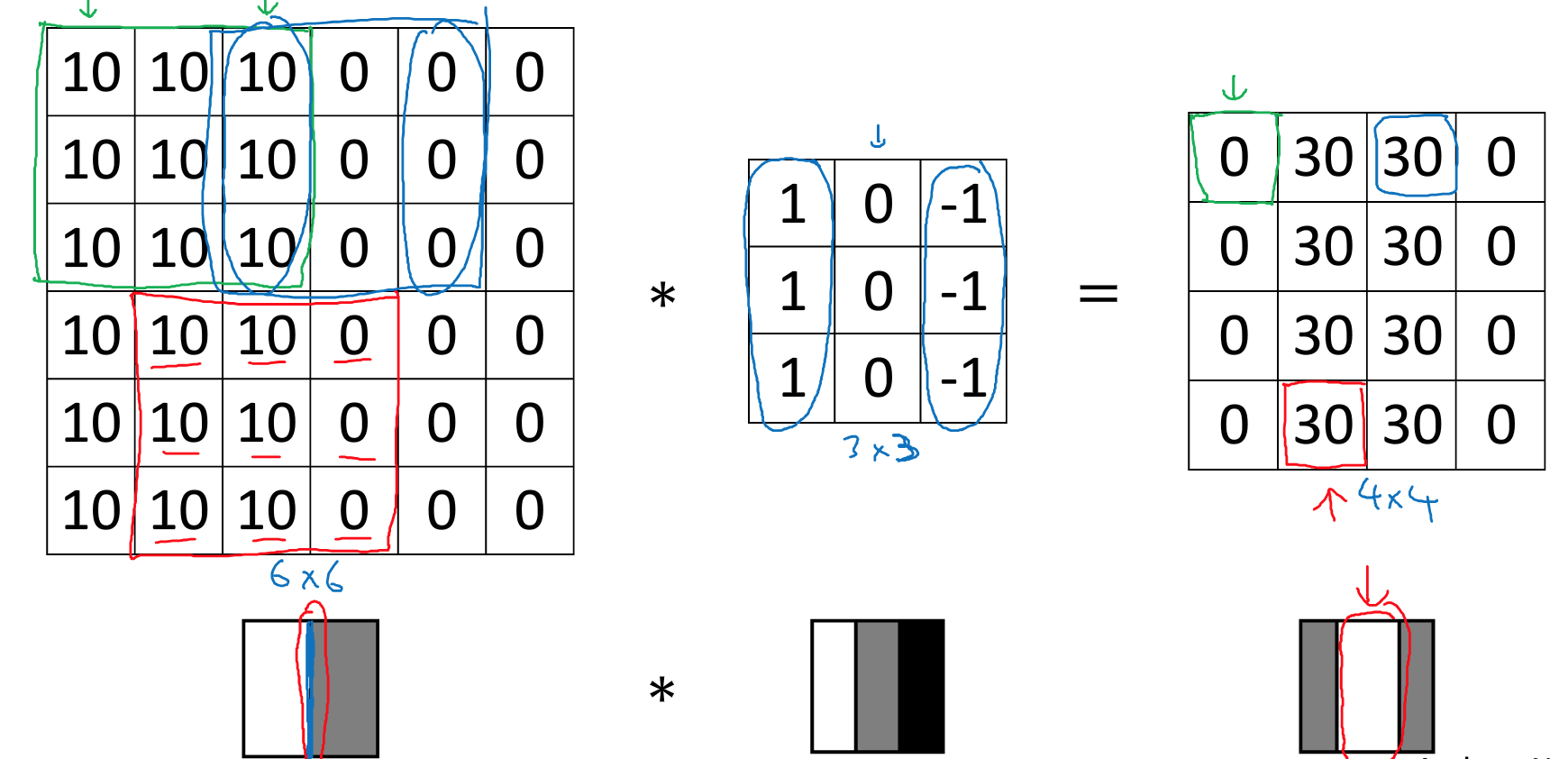
为何这个filter可以找出竖线,直观理解,filter找出左右存在色彩反差的区域或者找出由明转向暗的区域,如下图
实际中还有很多其他的filter,
但是其实在deep learning中,你不需要去手工设计或者选择filter,因为他们是学习的参数,可以通过模型学习到
可以看出用卷积可以大大减少需要学习的参数,
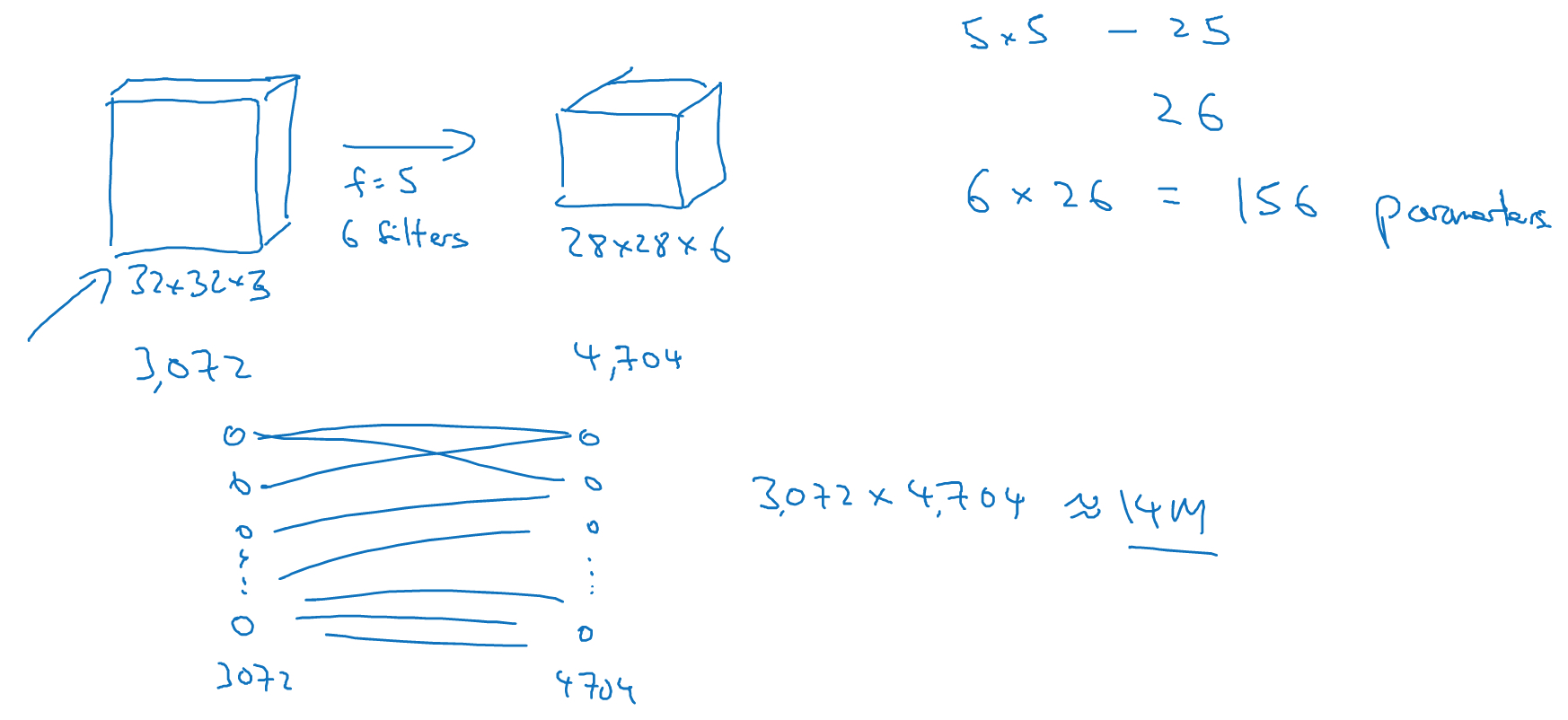
为什么卷积网络,可以用这么少的参数?
首先是参数共享
通过一个filter可以找出图片上任何位置的特征,如竖线
这样的好处是无论输入图片多大,参数size都是固定的,由filter本身决定
第二,稀疏链接
如果是全连接层,每个输出的每个维度都和输入的每个维度相关,所以需要很多的参数
而在卷积层,一个输出的某个维度如下图,是由输入中的9个feature算出的,而其他特征无关
这样需要的参数大大减少,同时也降低了过拟合
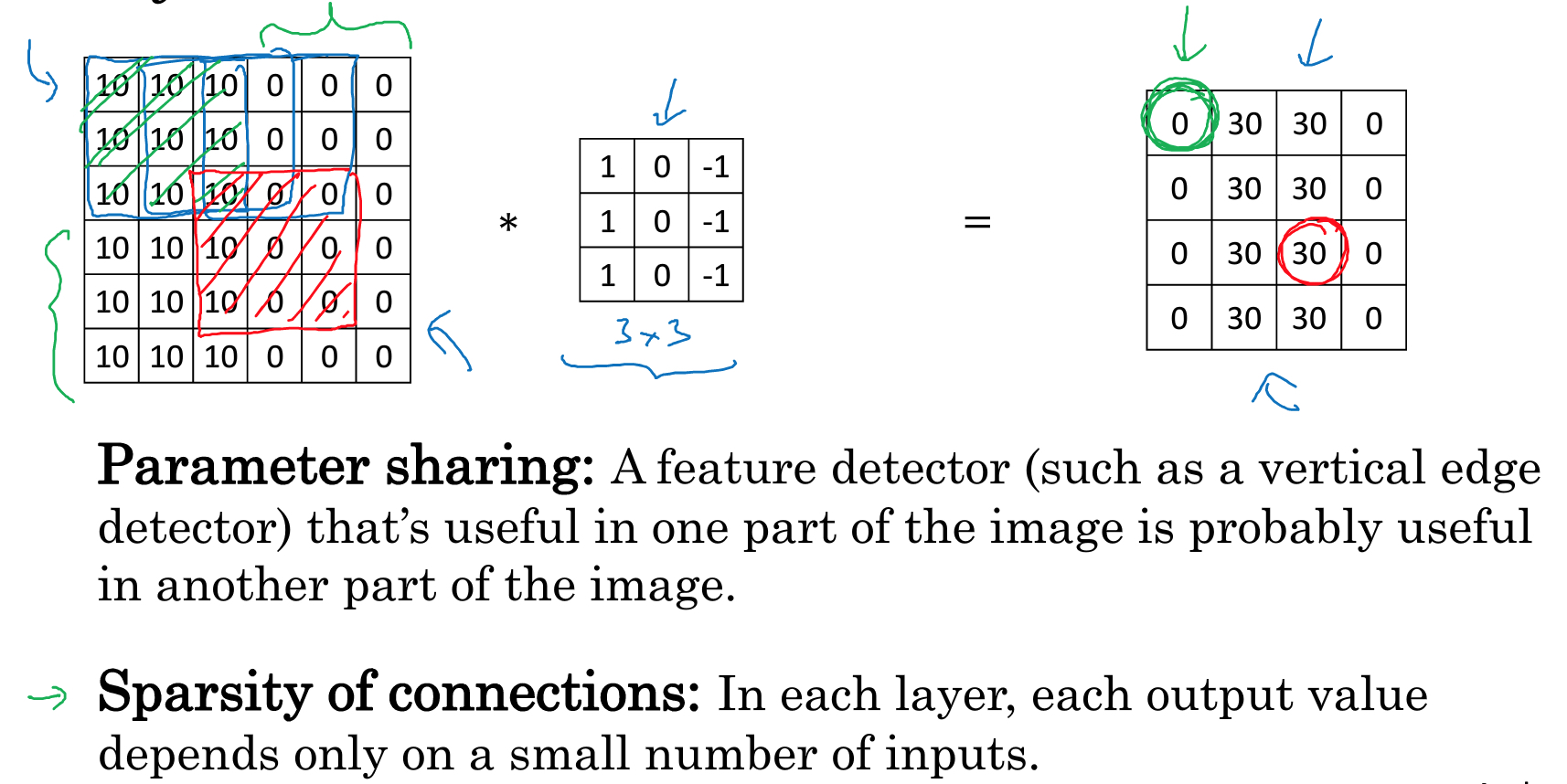
Padding
上面的卷积操作有两个问题,
每次卷积操作都会缩小图片的尺寸
会丢失边缘区域的特征
所以为了解决这些问题,padding就是把图片扩大一圈,用0填充
这样就有两种convolution操作,

valid就是no padding,结果大小的公式,n-f+1
same就是padding让输出结果大小不变,根据公式算,p=2的时候,就可以保证不变
这里描述filter一般都是odd,而不会是偶数,直观上讲,如果f是偶数,那么没法对称的padding,而且f是奇数是filter是有中心点的,这个很方便
所以filter一般都是3*3,5*5,7*7
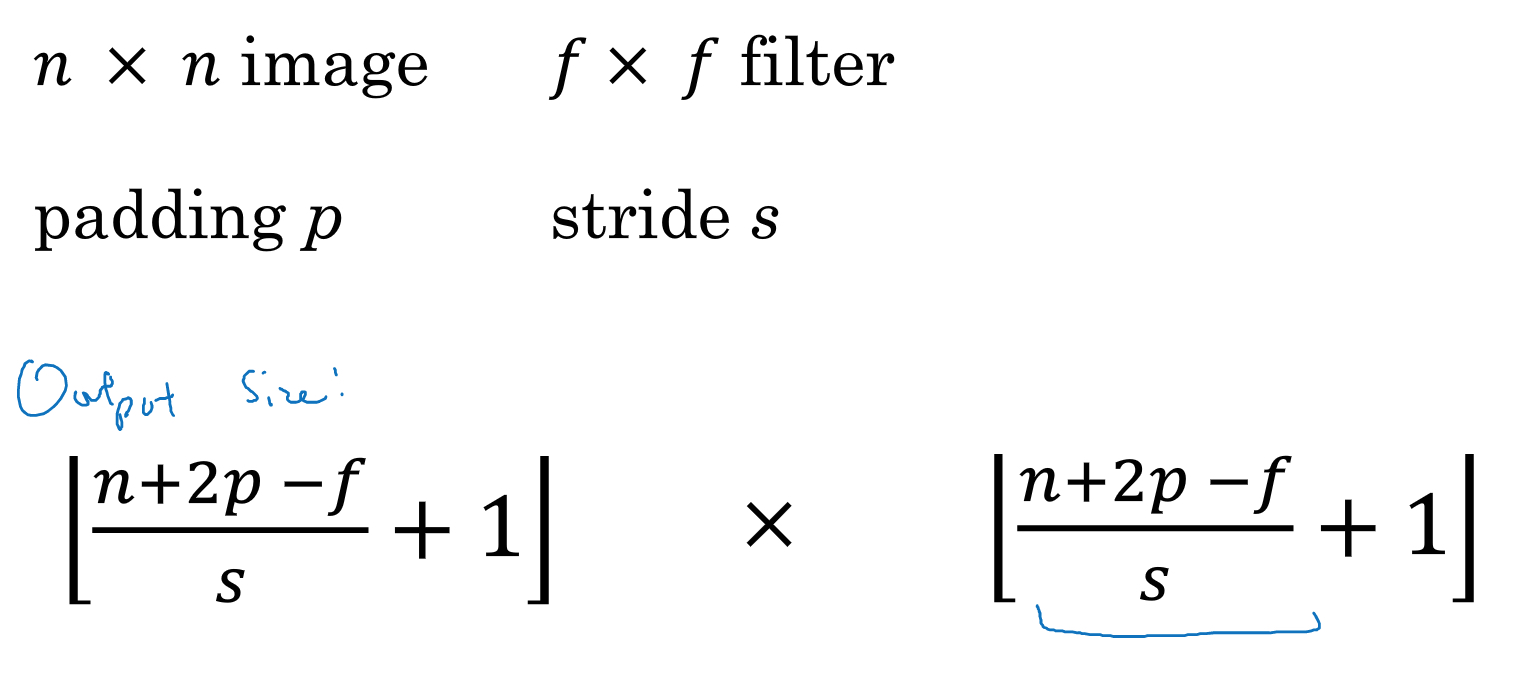
strided convolution
对于convolution,除了调整filter size,padding,还可以调整stride的大小
可以每次滑动超过1步,那公式会变成如下,
cross-correlation VS convolution
在通信或数据中,convolution操作要先把filter,同时在横轴和竖轴上进行翻转,如图,
这样做的好处,是可以让convolution操作满足结合律
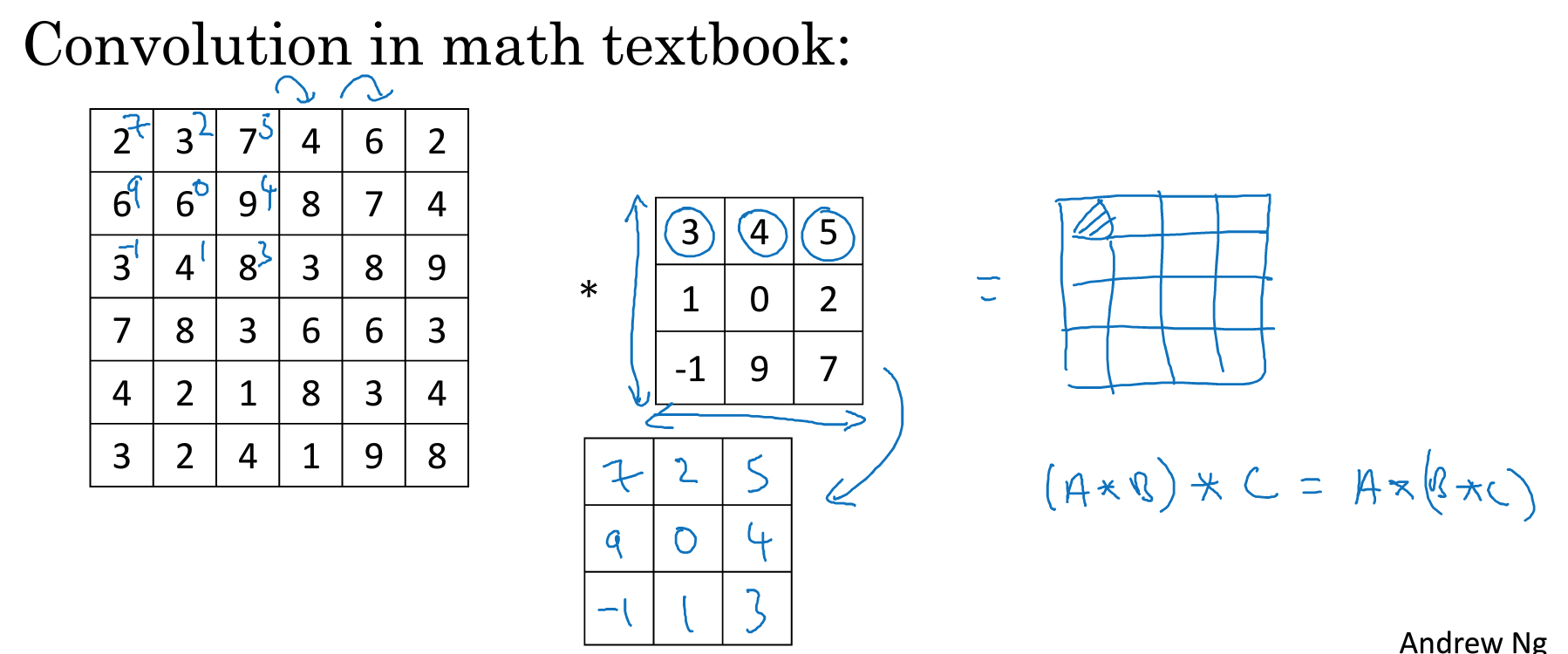
但是在DL中,我们其实没有做这种翻转,这种操作其实应该叫做cross-correlation
但是大家都习惯和默认称为convolution
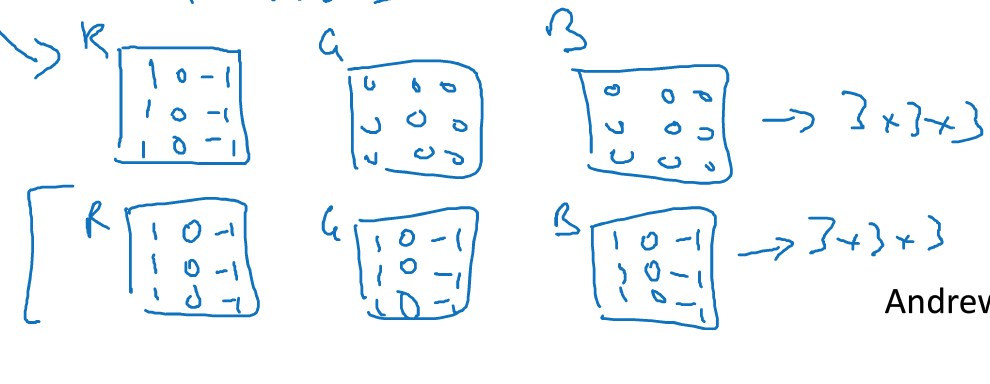
convolutions on volumes
真实的图片有RBG三层,所以是立体的,这样如果进行convolution
输入数据的层数,称为depth或channel
当输入数据有3个channel,那么filter对应也需要有3个channel
如图,上面这个3*3*3的filter可以detect 红色的竖线
下面这个,可以detect 任意颜色的竖线
在实际使用中,需要同时detect多个feature,所以有多个filter,如下图

输出数据的channel数,取决于filter的数目
one layer of a convolutional network
那把卷积操作放到网络中的一层结构如下,
卷积再加上b,就完成了线性变换的部分,后面跟上非线性变换,就完成了一个神经单元
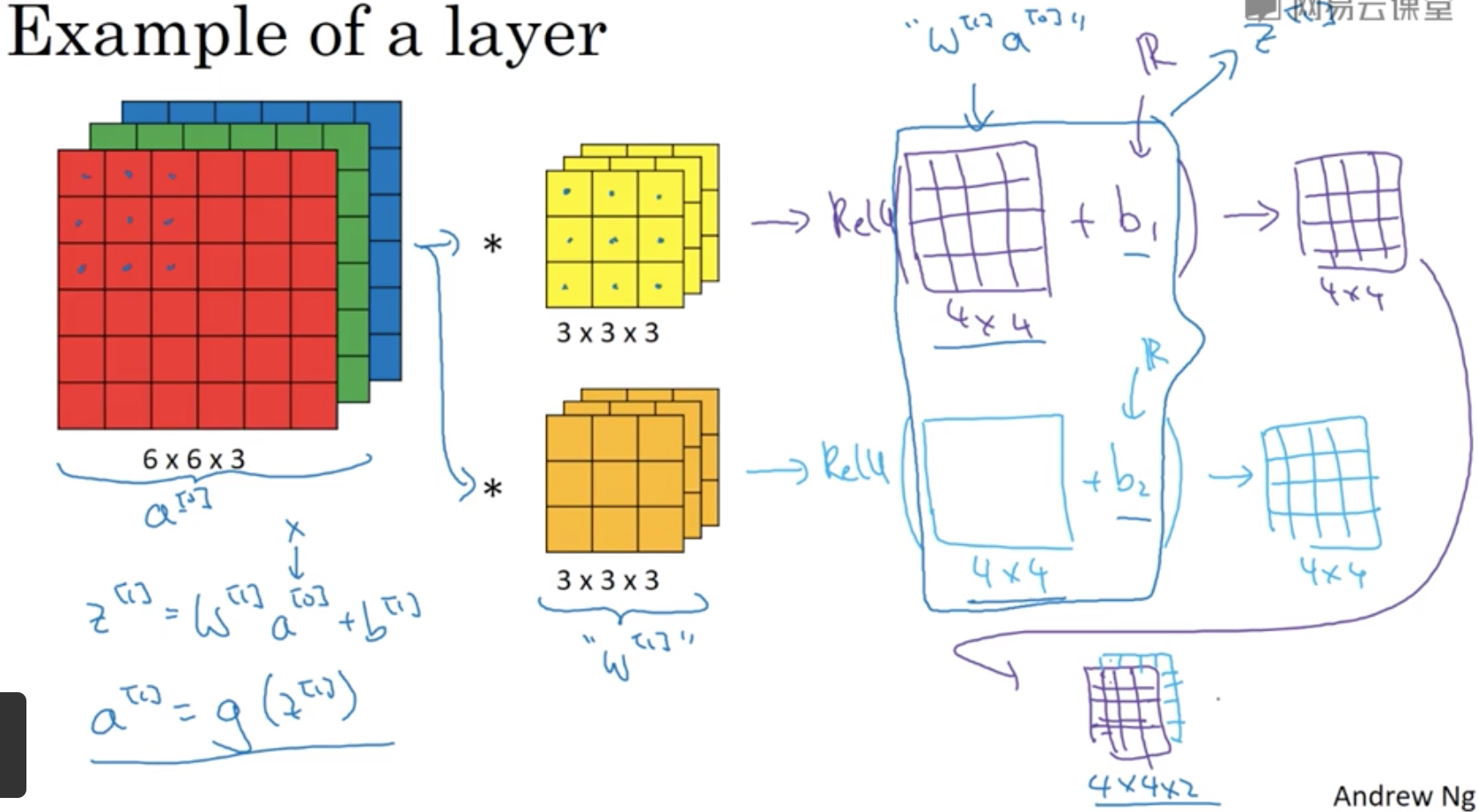
上图中的各个参数的表示如下,

给出一个完整的CNN的例子,

每层的结构,根据上面的公式很容易算出,卷积层只是做特征的提取和变换,最终输出前,还是需要fully connected,然后用logistics或softmax输出结果
CNN网络一般有三种layer组成,convolution层,pooling层,fully connected层
pooling layers
池化层,利用采样高效的降低维度和减少特征值
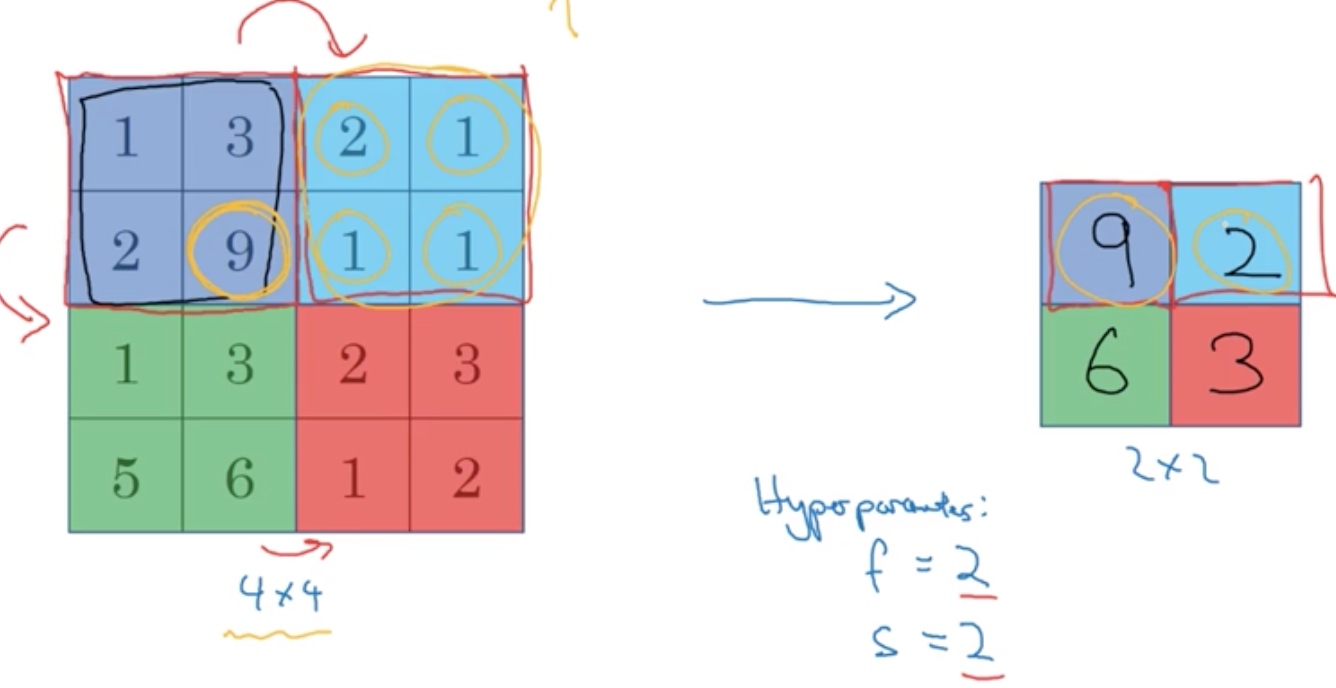
一般有最大和平均池化,这层是没有参数的
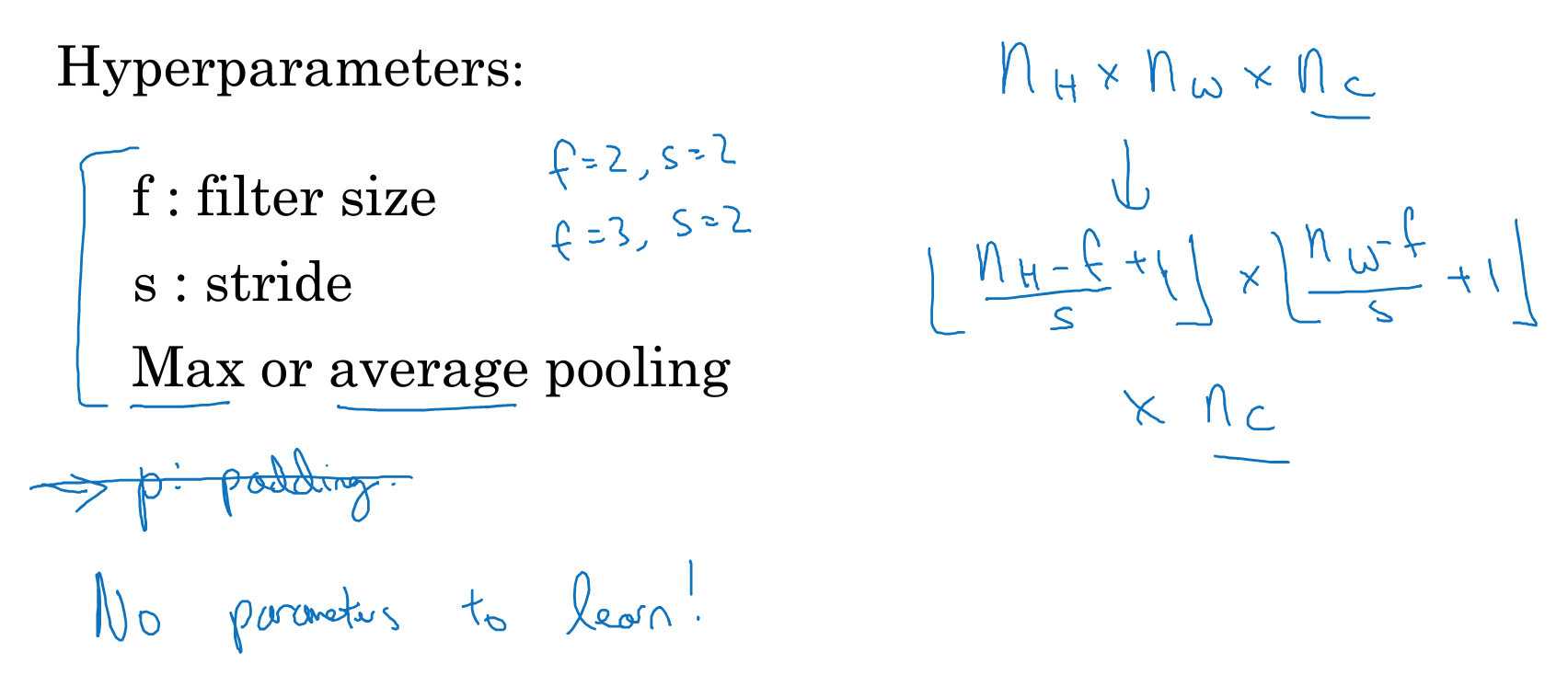
neural network example
卷积神经网络的结构比较复杂,而且超参数非常多,所以常用的方法是参考经典的网络结构
先看个例子,用于手写体数字识别,
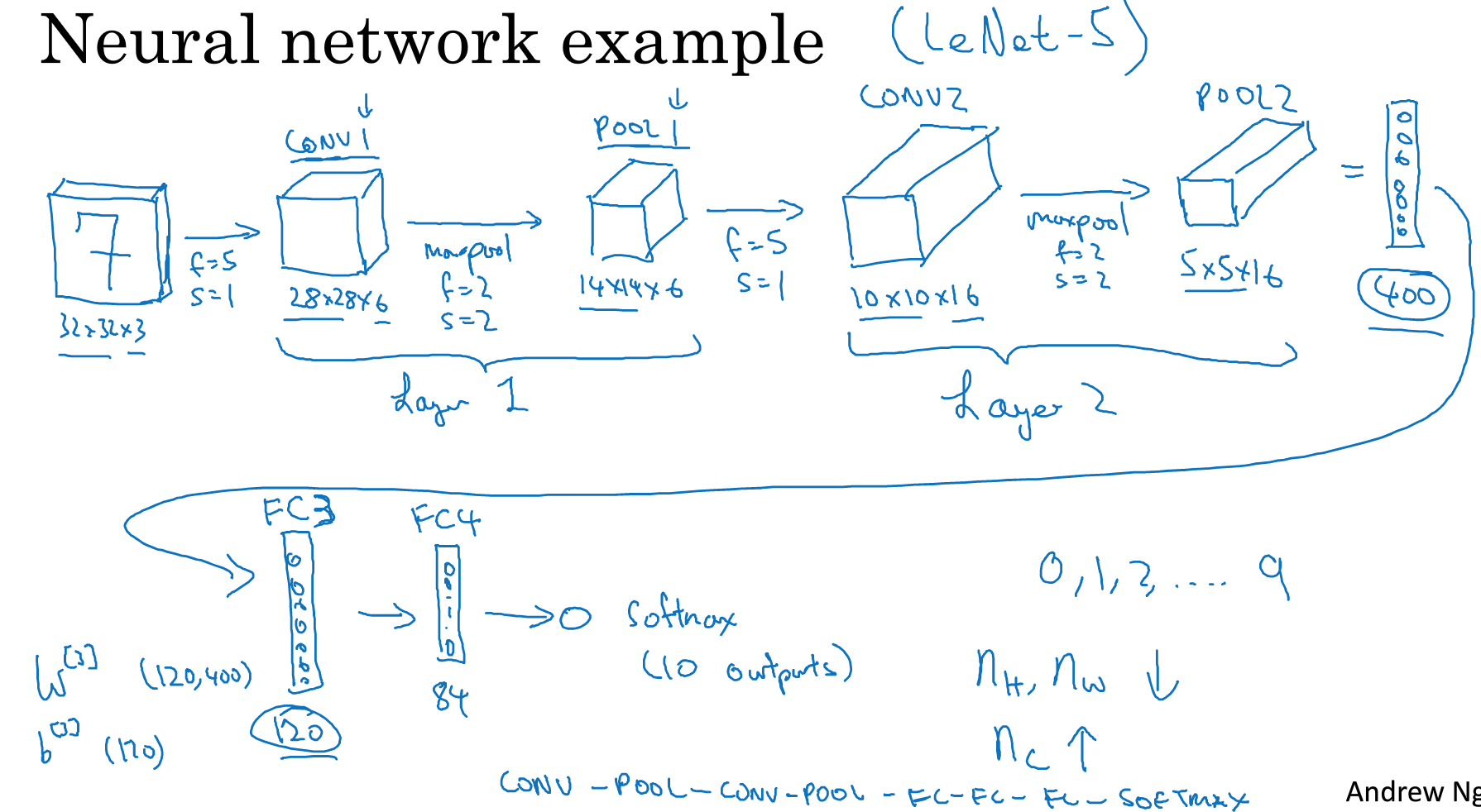
如下图,总结下这个网络的结构,
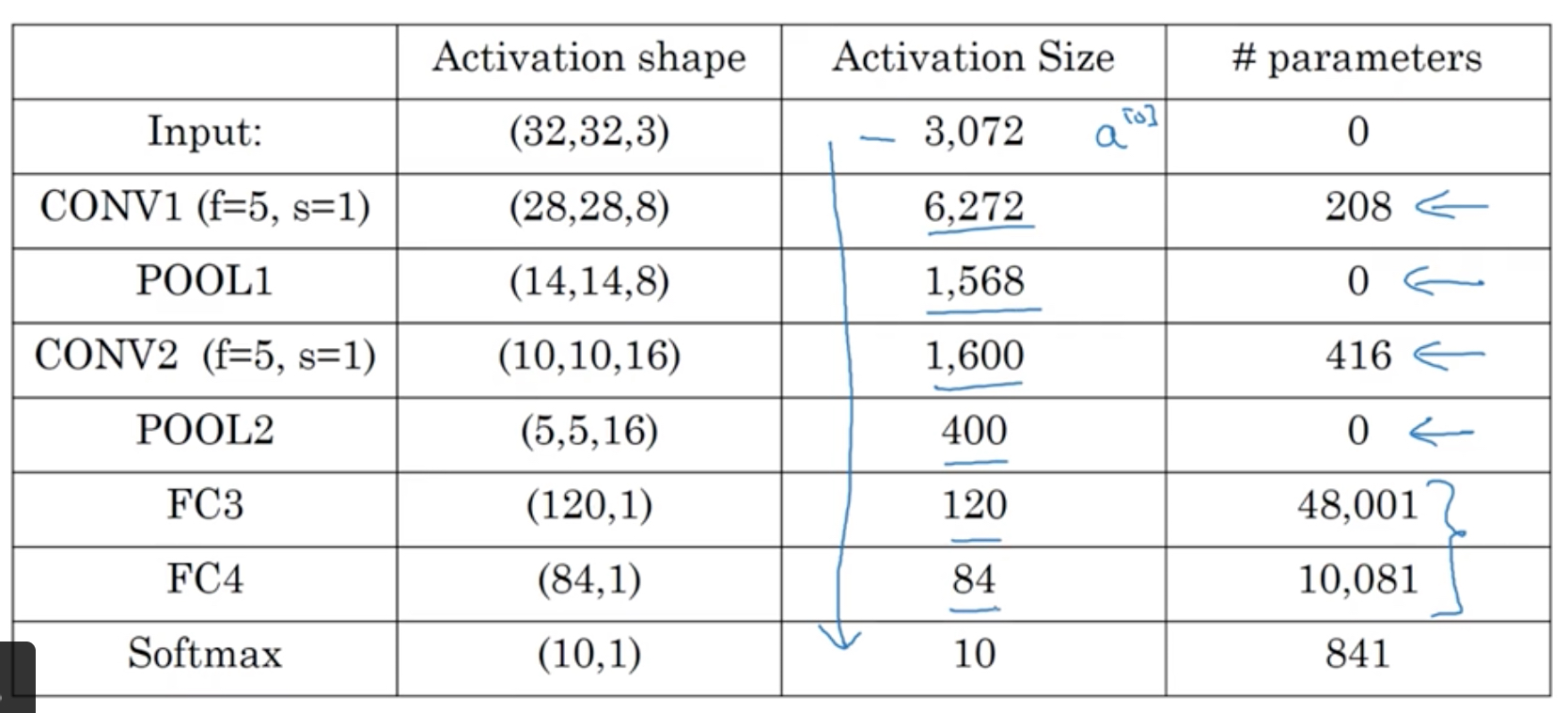
能学到的规律,
首先,池化层没有参数,而卷积层的参数并不多,参数主要集中在全连接层
然后,CNN的经典结构就是,cov-pool-cov-pool-fc-fc-fc-softmax,几层cov和pool组合,加上几组fc层
再者,activation size是慢慢减少的,如果降低的太快会影响模型的性能
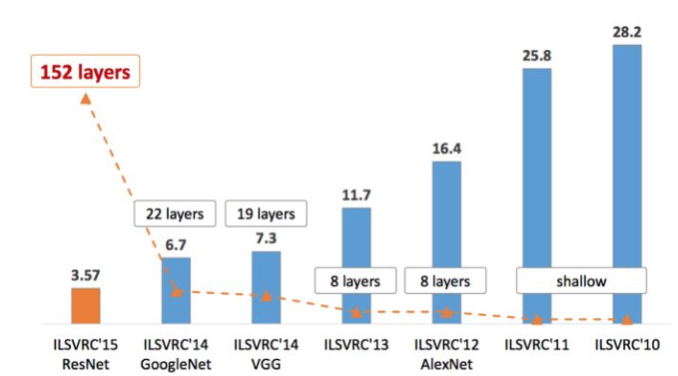
Case Studies
参考,https://zhuanlan.zhihu.com/p/22094600
比较直观看出各个网络的年代和性能差距
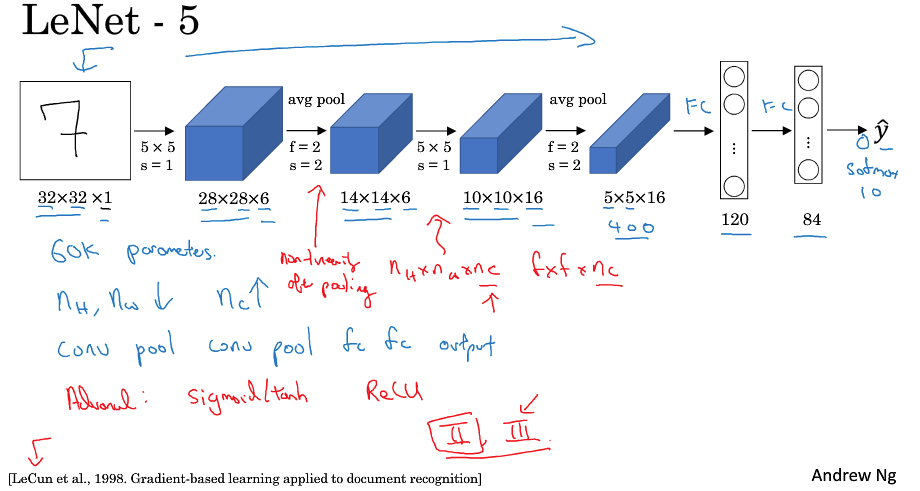
LeNet-5
该网络由作者名字LeCun命名,5代表五层模型
该网络,用于手写数字识别,用于灰度图片,所以图片channel为1
网络整体有60k的参数,比较小
用于当时没有padding技术,所以随着网络depth增加,size是不断变小,但是channel是不断变大的
网络结构被后续沿用,若干cov+pool + 若干fc + output
从原始图片1024个像素到最后一层FC的维度84,所以cnn关键就是抽象和提取特征
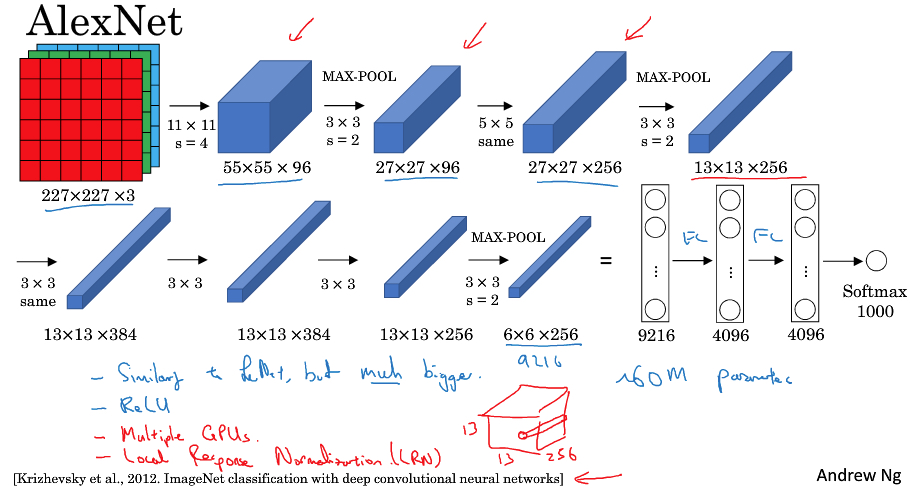
AlexNet
这个网络也是用作者名字命名的
AlexNet和LeNet其实比较像,就是规模大了许多,参数从60k到60m
只所以可以训练这么大的网络,是因为AlexNet在工程实践上利用的GPU
然后AlexNet,采用了Relu和dropout,最终把compute vision带到一个新世界
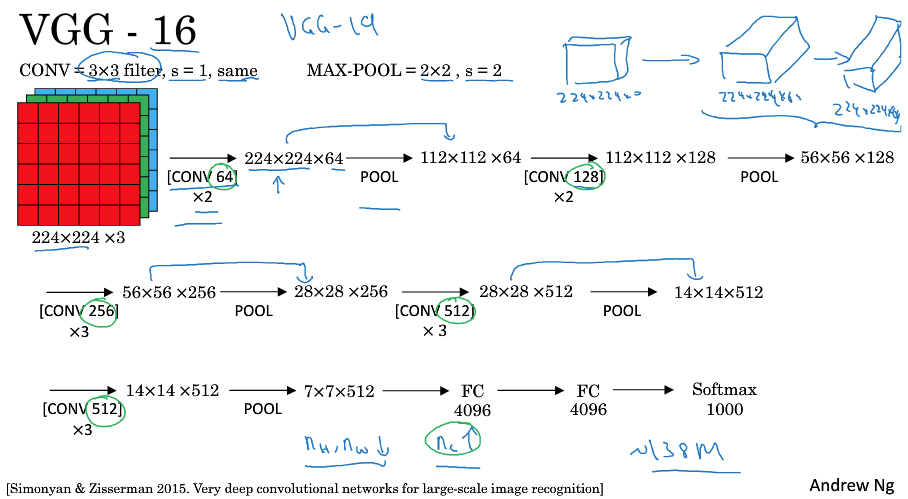
VGG
VGG网络是比AlexNet规模更大,更深的网络模型,参数达到138M之多
16表示有参数的layer有16层
VGG的特点是结构规整,工业化的思路,我们不去精巧的设计,依赖网络的规模和数据规模来解决问题
首先他用的Conv和Pool模块是固定的,
Conv是3*3,s=1,same
Pool是2*2,s=1
然后为了便于表示,在图中省略了Conv的参数,Conv 64 *2,表示2层卷积层,每层有64个filter
再者,
由于这里用same conv,所以conv是不会改变图片size的
全靠pooling层改变图片size,并且也很有规律
多个Same Conv后,会接一个Pool,这样picture的size减半,并且每个Pool后,加上的Conv层的channel都会double
所以还是符合size变小,channel变大的规律,只是更规整
Residual Networks(ResNets)
残差网络的本质是要解决网络太深后难以训练的问题,由于梯度消失或梯度爆炸
可以看到之前的网络也就十几层,而残差网络都是上百层,甚至上千层
所以残差网络效果好,不是有什么秘诀,因为更深的网络,更好的性能,这是理所当然的
只是之前的网络模型,在实践中无法训练到那么深
残差网络,是由residual block组成的,
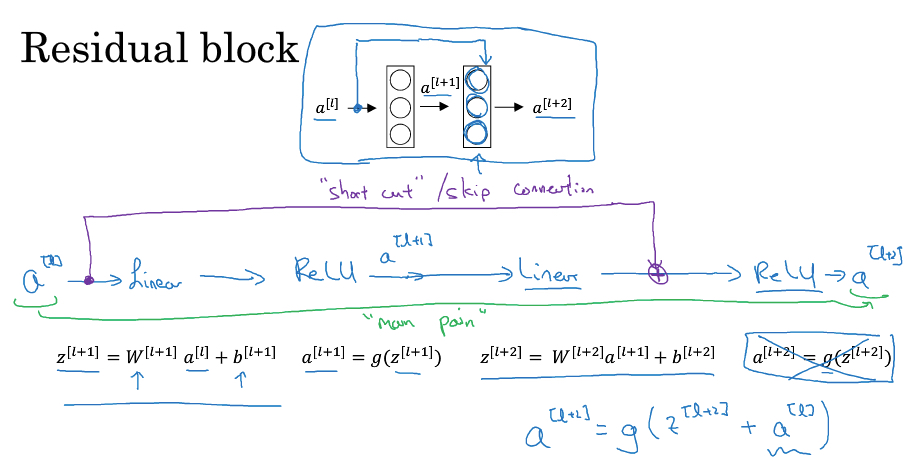
residual block至少两层layer组成,
除了普通的main path,不同就是多了shotcut或skip connection
即,会把第一层的输入a1,叠加到第二层的激活函数前
所以第二层的输出,就从a2 = g(z2),变成a2 = g(z2 + a1)
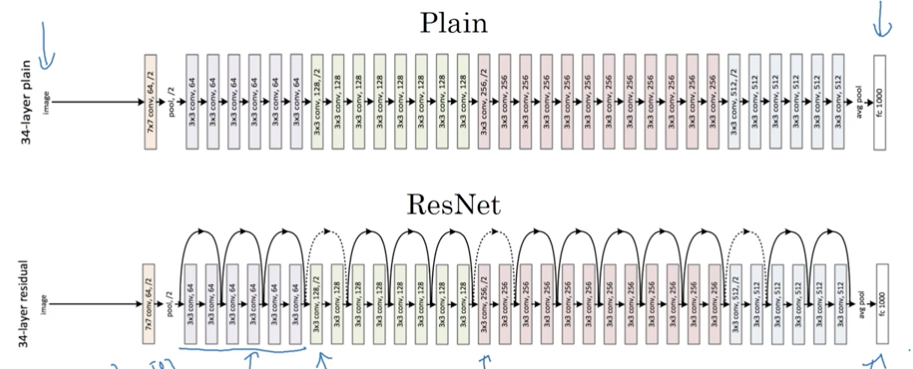
我们把很多的residual block 堆叠(stack)在一起,就形成residual network,如下图,
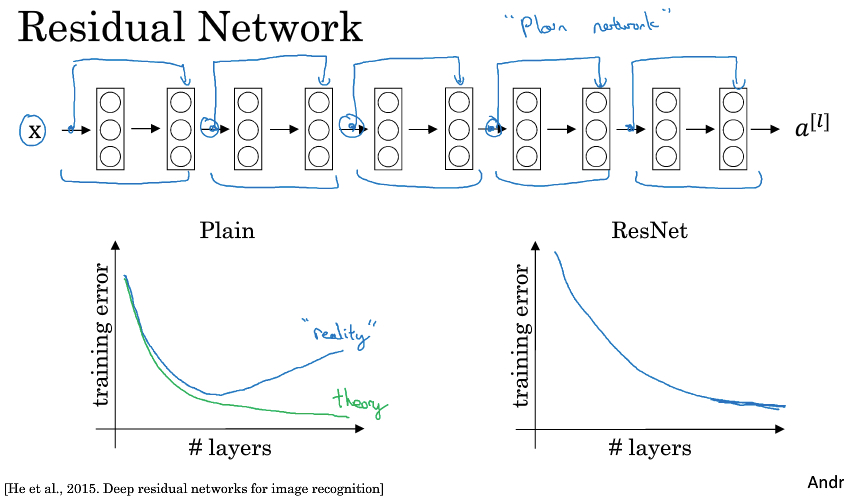
如图,把plain network变成ResNet,只需要给每两层加上shortcut,这样就可以解决plain network当layer数过大性能明显下降的问题
为什么残差网络可以帮助网络增加深度?
NG的观点是,因为residual block对网络是无副作用的
如下图,由于residual block的输出是a2 = g(z2 + a1)
那么只要让z2 = w2a1 + b2的参数,w2,b2趋于0(类似正则化),那么a2=g(a1),如果g是relu,那么g(a1)=a1,所以得到a2 = a1
而让参数为0这是很容易学习的
所以说residual block最差的情况就是,原封不动的传递输入,这样当然无论迭代多深都没有关系
但是,如果不是最差情况,能学到些东西,对网络就可以产生正向的帮助
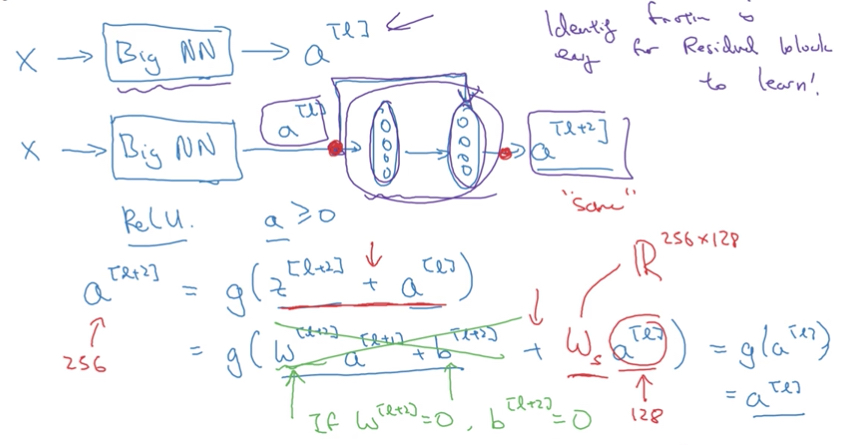
这里residual block有个假设,就是z2 + a2,那么两者的size需要一样
如果不一样了?那这里需要增加一个参数,Ws用于把a2的size转成和z2一样
下图是个实际的例子,如何将一个plain的cnn,转化为一个ResNet网络
注意虚线的链接,表示经过pool,size变化后,需要进行size转换
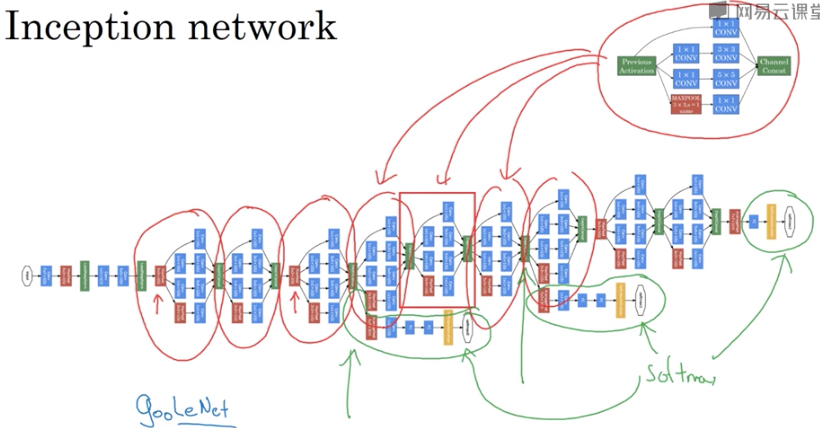
Inception网络
inception各个版本对比
https://blog.csdn.net/xbinworld/article/details/61674836
inception的命名,是因为在盗梦空间,inception,中有一句台词,“we need to go to deeper”
所以可以看出,inception network或GoogleNet的主要目的,也是让网络更深
首先看下1*1 convolution,
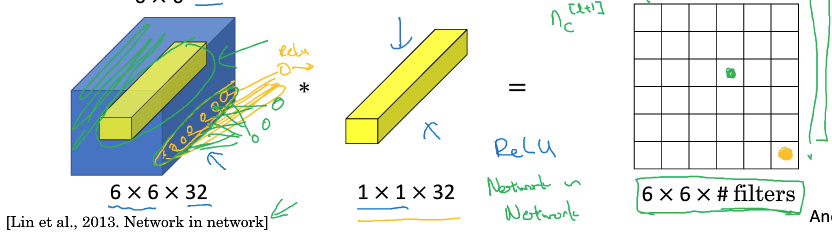
1*1 convolution,其实就是单像素点,在各个channels上的线性组合
它的作用,
主要就是低成本的调节channel数,或depth;在不需要调整长宽的情况下,用3*3,5*5,比较耗费性能
再者,因为有relu输出,附带一层非线性效果
下面就看看啥是inception网络,
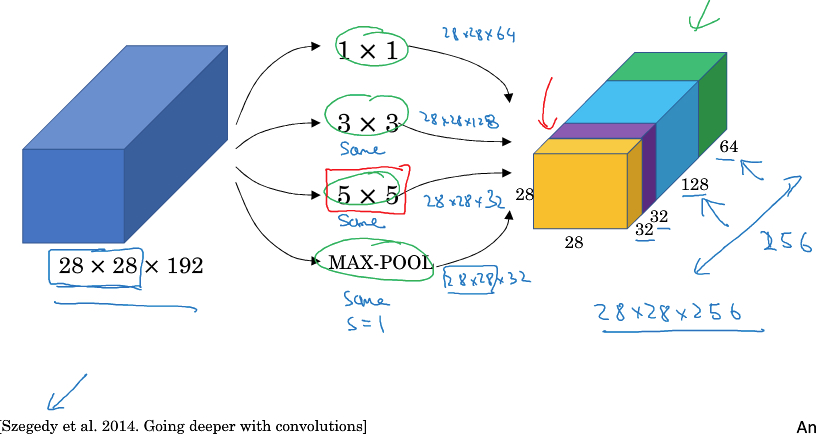
普通的convolution网络,你要选择用什么样的filter或是用pool层,选择困难怎么办?
Inception的思路就是,都用上,然后把结果stack在一起,让模型去决定
注意这里要保证输出的size一致,所以这里的pool是same pool,不会压缩尺寸,这是很特殊的pool用法
这个思路最大的问题就是计算量太大,那么这时我们的1*1 convolution就用上了
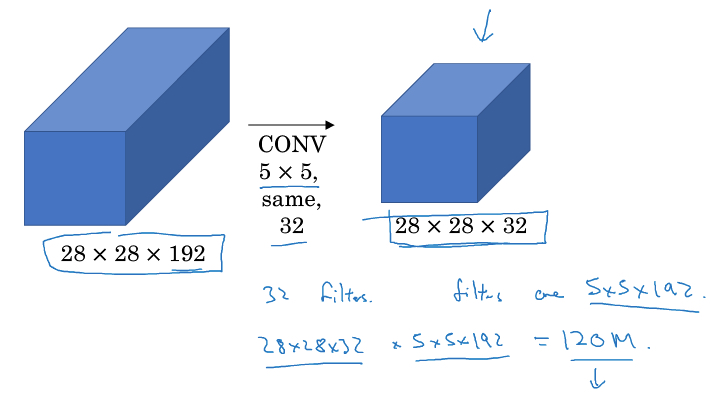
比如上面的例子,直接对输入做5*5 convolution,那么计算量120 million
用上1*1 convolution,先把depth降下来,再算5*5 convolution,这样计算量只有12 million左右,小十倍
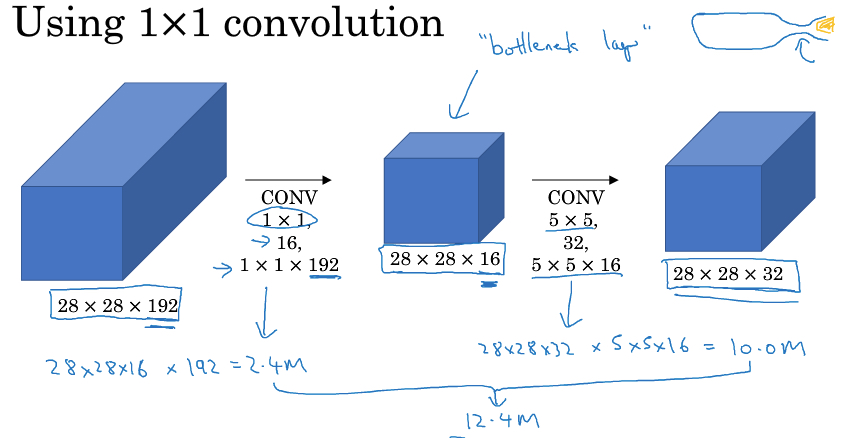
可以看到,两个方法,输入和输出都是一样的,但用上1*1 convolution降低channel后,计算量大大降低
中间这层称为,bottleneck layer,使用恰当的情况下,降维优化并不会损失算法的performance
我个人的理解,由于1*1 convolution是各个channel的线性组合,加上适当数量的filter,并不会丢失太多的信息
Inception module
现在来看inception module就比较清楚了,
如图就是一个inception module,其中1*1 convolution都是用来调节depth的
比如MaxPool后面的,就把depth调节到32,避免pool的结果在最终stack中占太大的空间
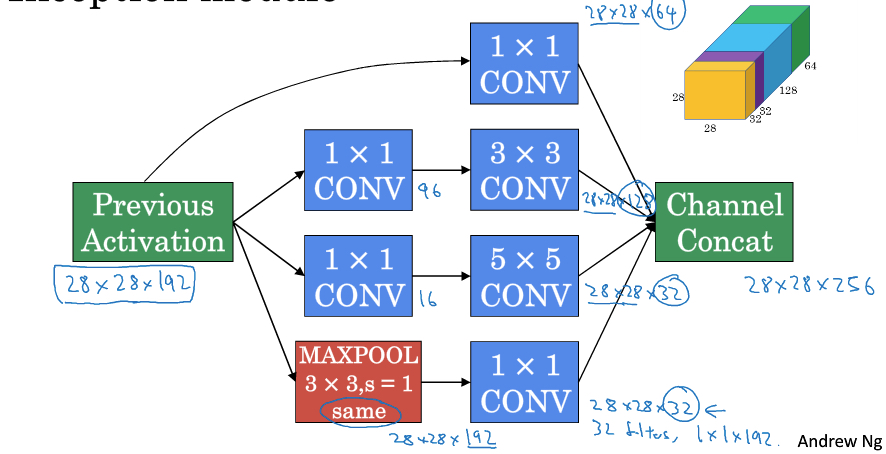
而inception网络,就是inception module的堆叠,中间还会加上些红色的pool层来调节size
Object Detection
classification with localization
这个和普通图片分类的区别,就是除了给出类别,还要给出在图中的位置信息
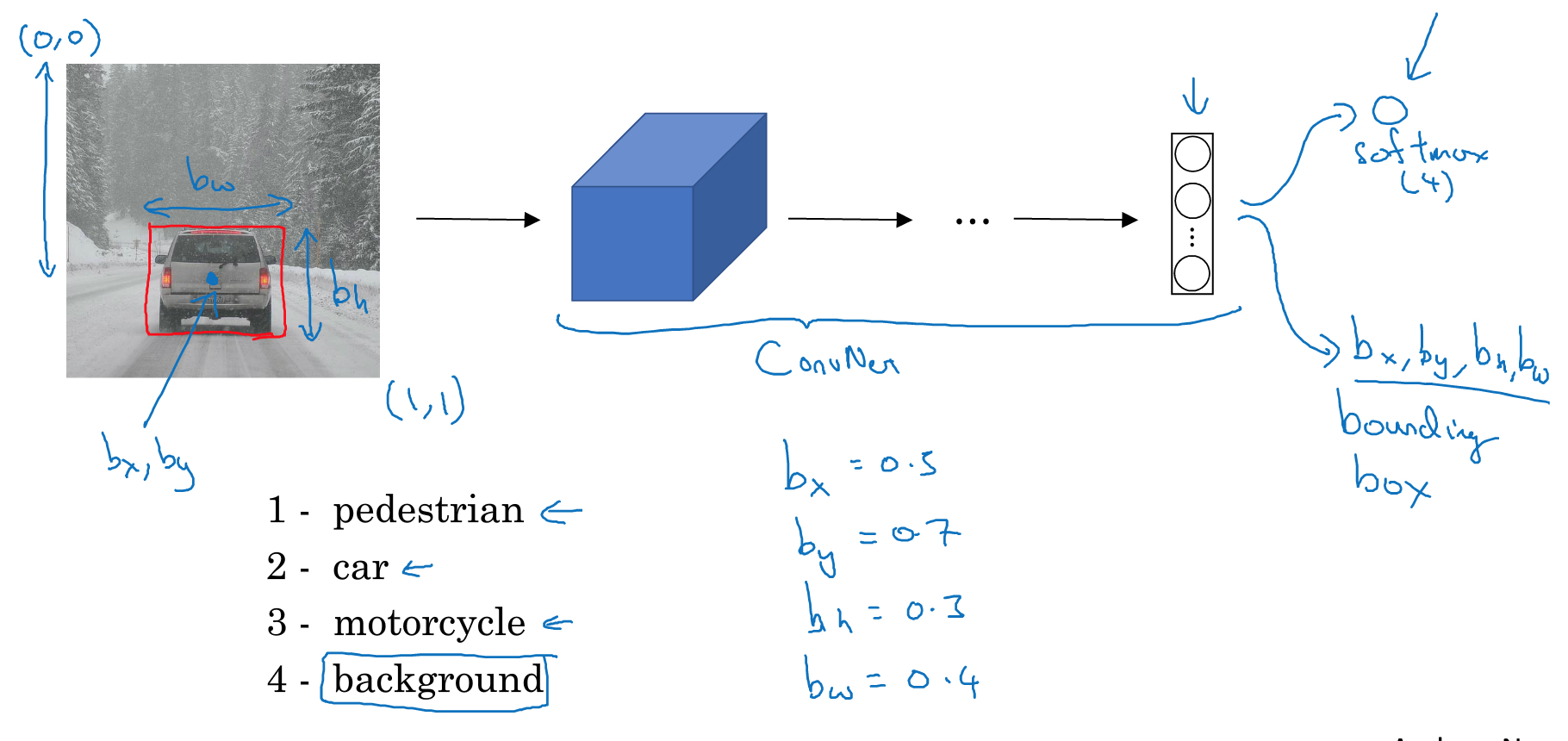
看这个例子,除了要给出图片是哪一类,1,2,3,4,car是2
还要给出car的位置,bx,by,bh,bw
这里假设图片的坐标是,从(0,0)到(1,1)
这样就有5个输出,其他的和原来一样,还是交给模型去训练
具体实现如下,
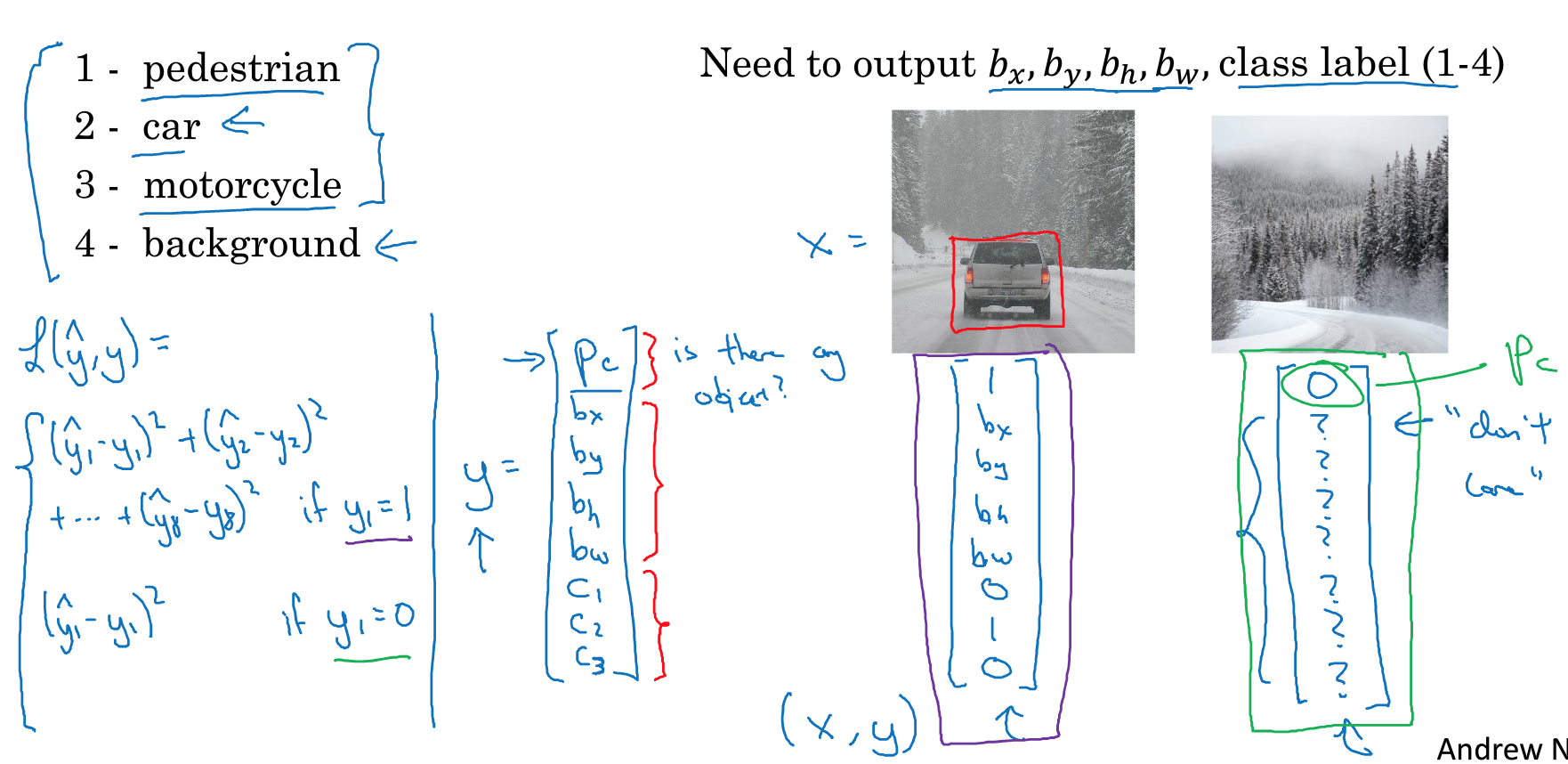
这里的输出增加一个Pc,表示是否有object,0或1
bx到bw是代表object的位置
c1,c2,c3表示具体的类别
这里给出两个例子,一个是车的,一个是单纯背景无object的
注意,
loss function中,如果Pc=0,表示没有object,那么后面的值就没有意义,所以在算loss function的时候就不需要考虑,只需要算第一项的平方误差
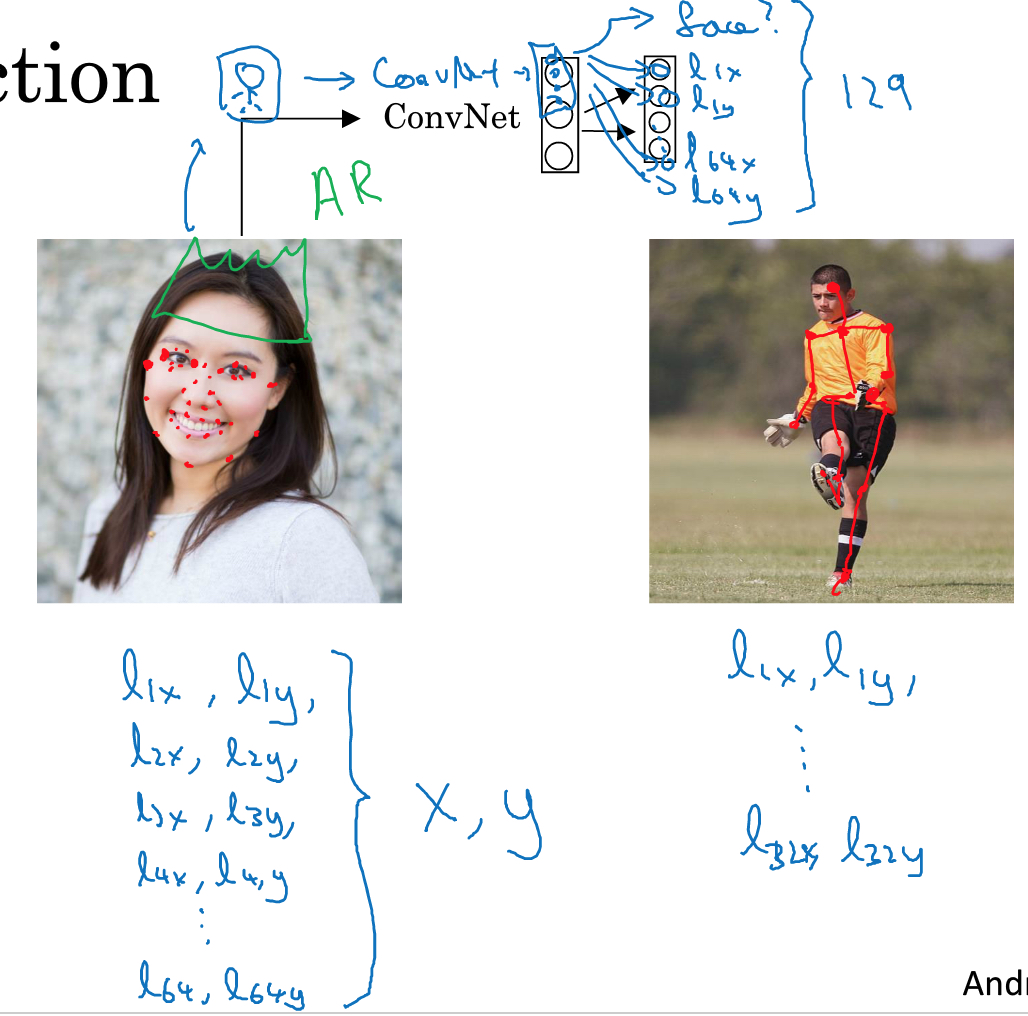
上面是比较简单的位置的例子,还可以检测面部特征或体态特征这样的case,思路都是一样的,关键是定义清楚位置特征作为输出
当然关键是,你需要有相当的训练集
sliding windows object detection
如果一个图里面有多个对象怎么办,这个就是object detection
传统的方法就是,sliding windows object detection,很naive的方法

拿一个框去遍历裁剪图片,对每个裁剪下来的小图,做分类,是否有object,是什么object
这个方法的问题很明显,你如何定义裁剪尺寸,太大就没有意义,太小计算量就会非常大
传统的方法是用线性回归来做分类,性能还能接受,但是用cnn性能就不行了
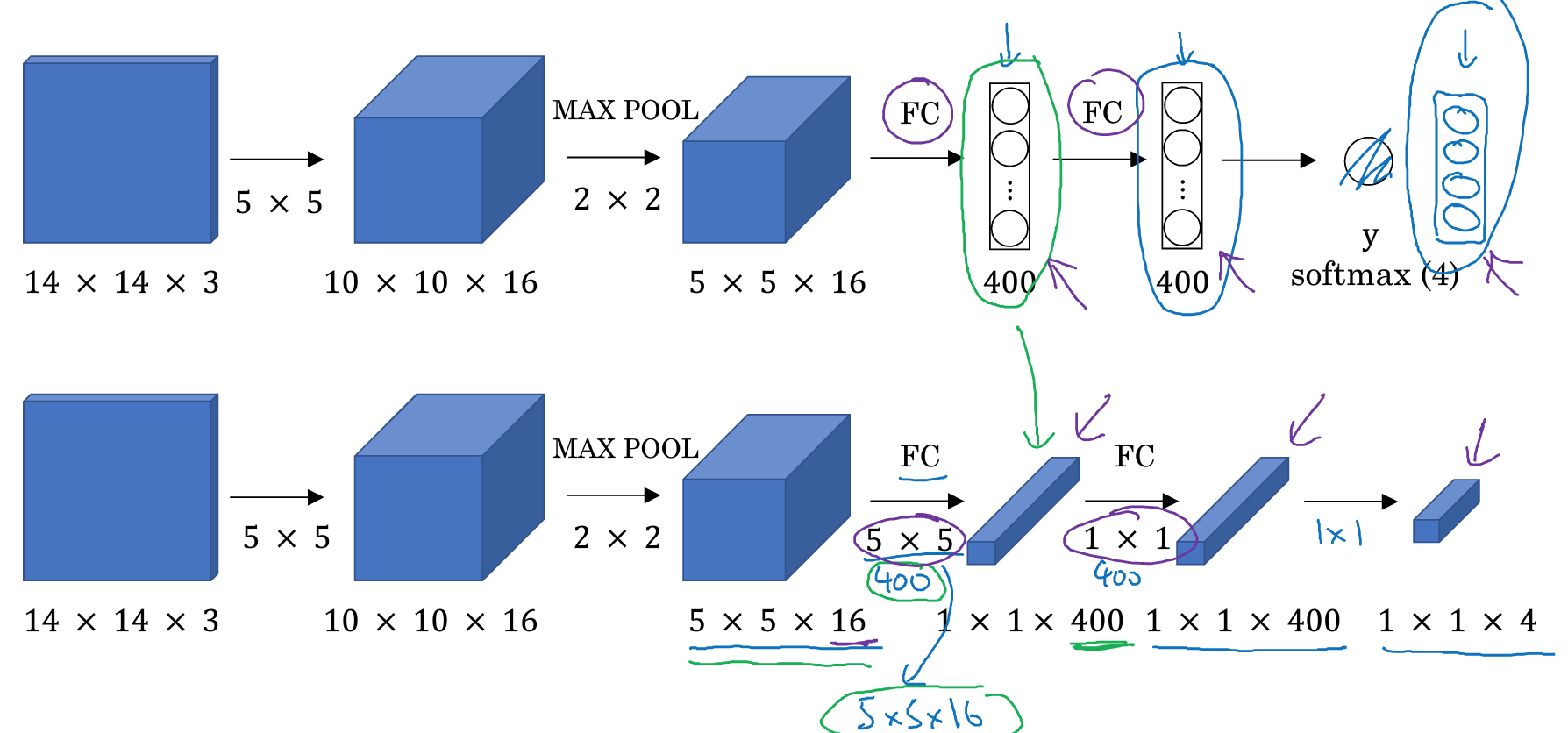
上面的图,显示如何通过cnn进行分类,14*14*3是裁剪的小图片,通过conv层,pool层,然后FC层,最后softmax
为了优化,我们可以把整个分类的过程,都转化成conv层
比如,第一层FC,5*5*16,全连接到400的节点
我们也可以用400个5*5*16的filter,进行卷积,最终得到1*1*400,同样的效果
这样第二层FC,我们用400个1*1*16的filter来代替
最后softmax,用4个1*1*16的filter来代替
这称为,convolutional implementation
这样的好处,我们可以把遍历裁剪图片分类这个过程,通过一遍cnn计算搞定

比如,输入图片16*16*3,裁剪大小是14*14*3,如果遍历输入图片会产生4个小图片
这里我们不用对每个小图片分别采用conv计算,如果这样做会产生大量的重复计算
而只要整体的做一遍conv计算,如下图,最终得到2*2*4的输出,即一下输出4个裁剪小图片的结果,效率大大提高
但这个方法,我们仍然需要指定裁剪size,
但这样只能判断object是否在小图片中,无法给出更精确的位置信息;并且很有可能object无法完整的被任何裁剪小图包含
Yolo(you only look once)
Yolo的思路,既然上面单纯的分类无法找到精确边界,那我们加上classification and localization的部分
对每个图片同时给出分类和边界数据,
既然我们可以得到精确的边界,所以就没有必要用sliding window,直接用grid把图片切分就可以
对于下面的例子,我们把图片用3*3的grid划分,最终就得到3*3*8的结果
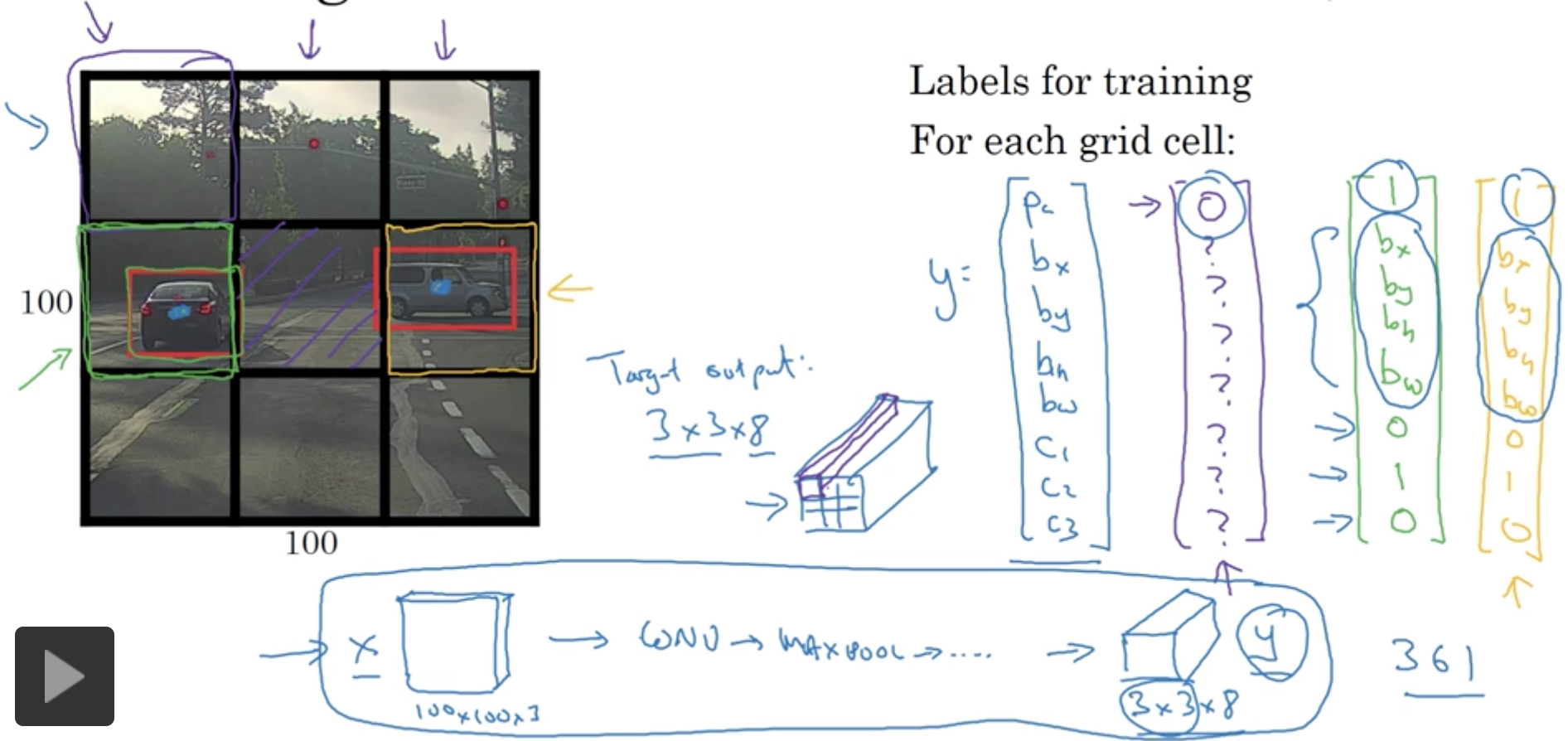
训练这个模型,我们也要按照这个格式给出训练集,比如上图中,给出绿色框和黄色框的数据作为实例
由于这里也用convolutional implementation的方式,使得计算非常高效,
所以训练集中,x表示输入图片,100*100*3,输出就是3*3*8
ok,这里明显的问题是
如果一个grid里面两个objects,怎么办?这个通过用小grid来降低概率,比如用19*19
反之,如果一个object比较大,占好几个grid怎么办?
我们只看,object的中心点,bx,by落在哪个grid,那么就认为object属于这个grid,即Pc为1,其他的grid仍然认为没有object
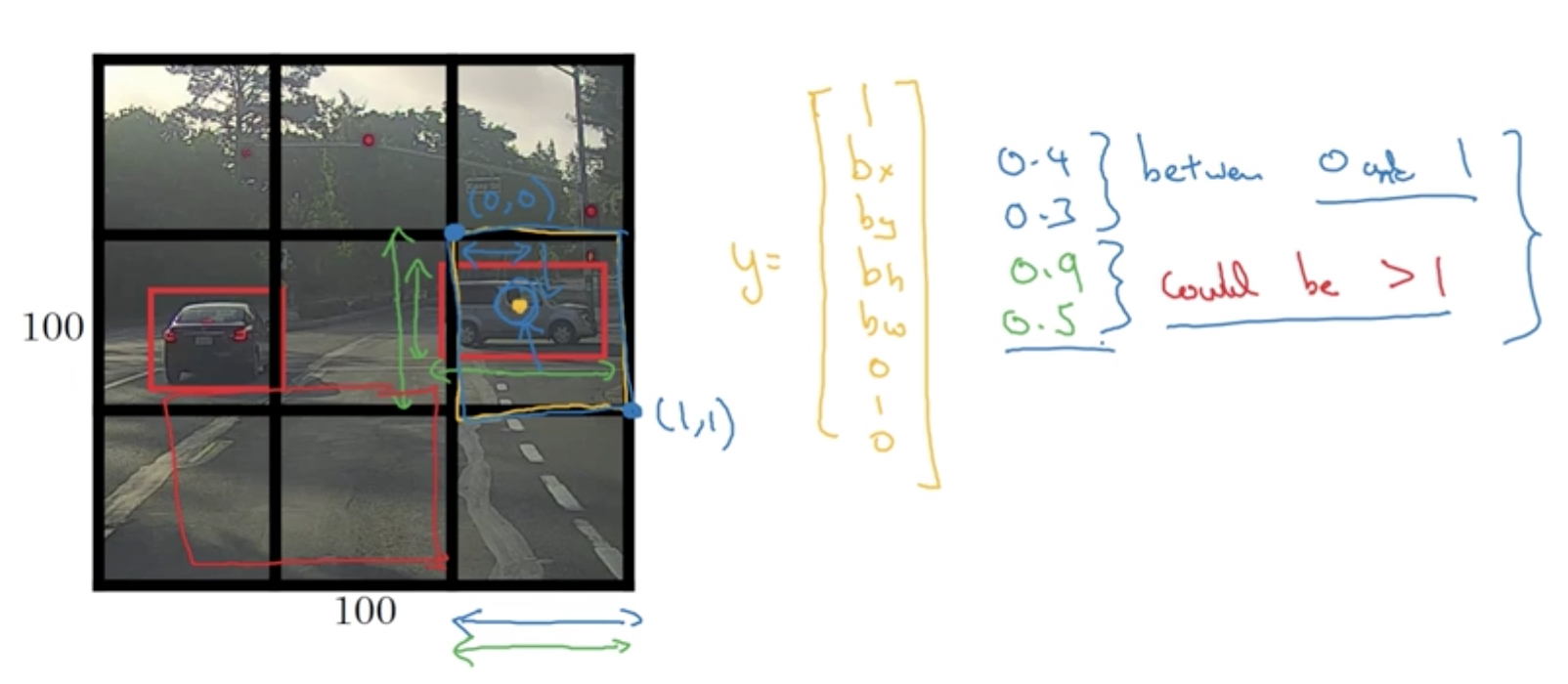
所以bx,by一定落在grid内,所以bx,by都是小于1的(grid的边界从0,0到1,1)
但是由于object是可能占多个格子的,所以bh,bw可能是大于1的
Intersection over union (IOU)
如何判断算出的bounding是否精确?
很简单,交并比
下图,红框是精确的bounding box,而紫色的算出的bounding box,想判断紫色的bounding box是否足够精确

Non-max suppression
用yolo算法的时候,
在准备训练集的时候,我们可以把一个车根据中心点放到一个grid中
但是在predict的时候,会有不止一个grid认为车在自己的grid中如图,并用Pc来表示概率

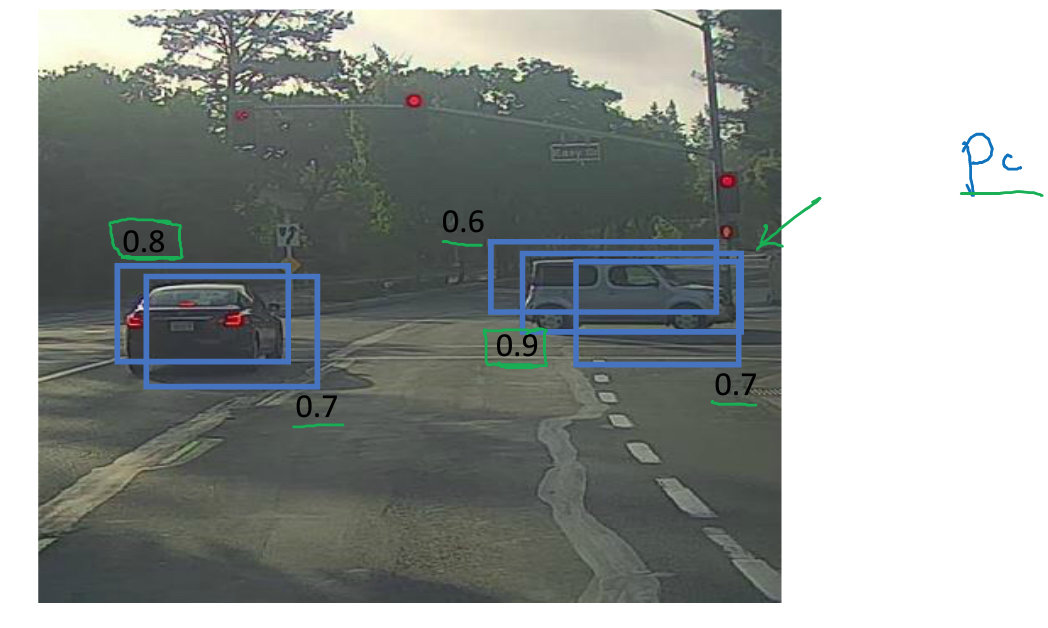
那么直接的想法,既然Pc表示概率,我们就选概率最大的,其他的都discard掉,就好了
如果图片中只有一个object,这个方法是可以的
但是如果有多辆车,我怎么知道哪些grid的bounding box是描述的同一辆车?
这里就要用到交并比,如果两个bounding box的IOU大于0.5,我们就认为是同一辆车
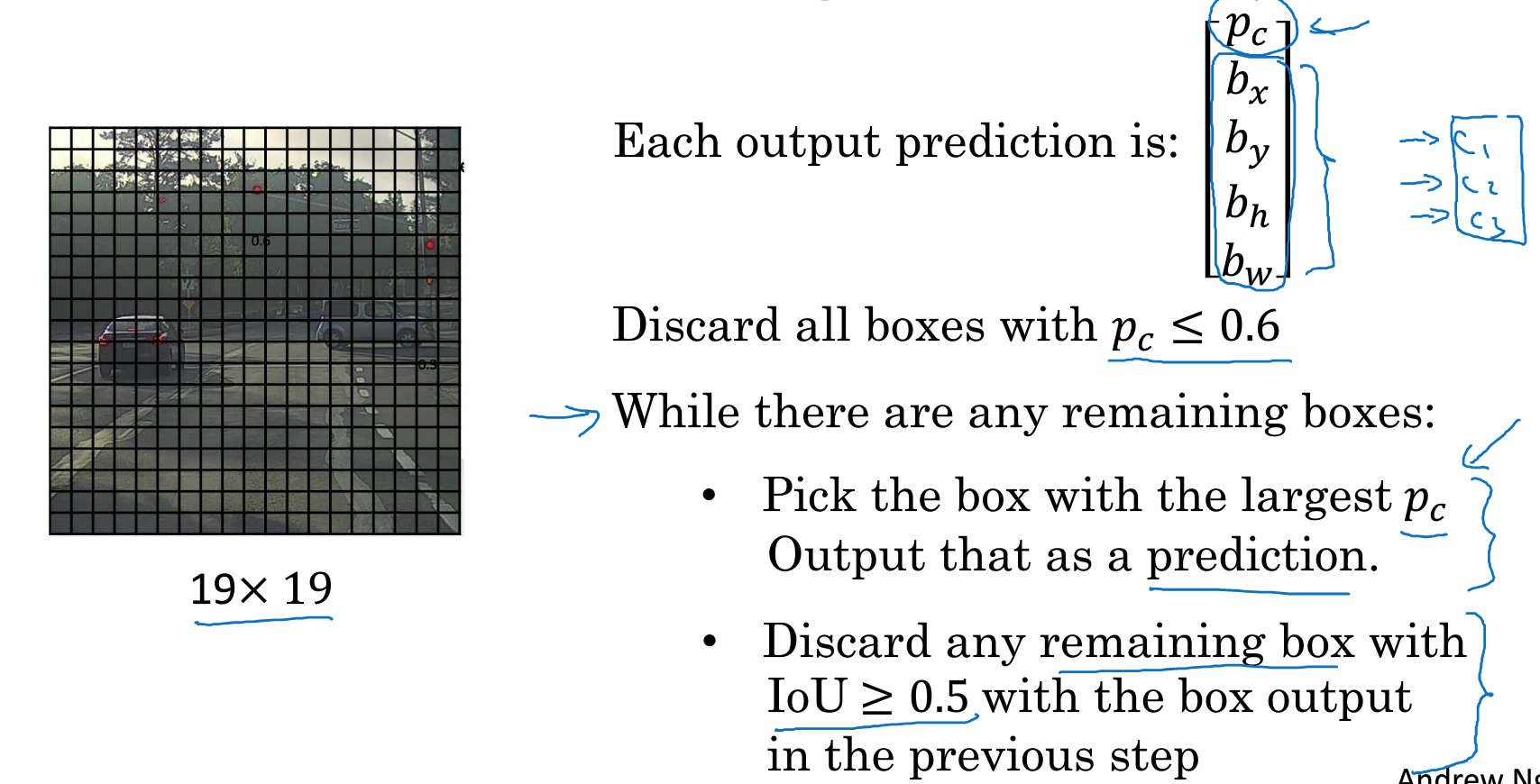
所以得到下面的方法,
首先discard掉所以Pc较小的grid
然后找到最大的Pc,然后删掉所有和它的IOU大于0.5的grid,这样一个object就保留了一个Pc最大的grid
如果还有grid剩下,说明有其他的object,再重复上面的过程一一找出
Anchor boxes
前面说了当用很小grid的时候,一个grid中有多个object的概率是很小的
但如果要在一个grid中detect两个object应该怎么做?
直接的想法是,我用8位的输出来detect一个object
那如果要detect两个,就用16位输出,分别表示两个object
比如下图,图片中人和车都在一个grid中,所以我们就用前8位表示人,后8位表示车
这样讲人可以理解,机器不行
所以我们要用机器可以理解的概念来定义人和车,
这里就是用anchor box,anchor box可以人手工设计,也可以用k-means去统计,比如人的平均边界,车的的平均边界
如下图,我们就用anchor box1代表人,anchor box2代表车
那么一个object到底是算哪个box?还是用交并比,和谁的交并比大就算谁

这个方法用起来比较麻烦,detect两个object就用16位输出,如果要detect多个object就要更多位的输出
而且还要指定和设计anchor box
然后如果grid中出现多于假设个数的object,就没办法处理
或者两个object的anchor box类似,也很难处理
Region proposals
除了,Yolo,还有另外一个思路来加速sliding windows object detection

region-cnn,思路就是对于sliding windows object detection,我们要遍历所有的裁剪图片去做分类,但是某些裁剪图片明显是没有任何东西的
所以,region-cnn会对图片做分块,segmentation,如最右图,这样只需要对不同的色块做分类即可
那么执行分类的candidate变少,性能就提高了
Face Recognition
Recognition可以分解成verification的问题,如果解决了verification的问题,那么Recognition只是遍历的问题
这里要注意的是,如果要在Recognition达到一定精度,verification的精度要提高几个量级
因为如果verification的精度99%,但库里面有100张图片,所以每次误差的叠加就会很高

One-shot training
在很多场景下,你不会有很多关于某个人的图片,可能只有一张图片作为训练集,当这个人再次出现时,你要能够认出他
这个用传统的cnn就无法解决,首先训练集太少,无法得到有效的网络
再者如果要识别的对象增加,比如新员工入职,你需要从新训练网络
所以采用的方法是,
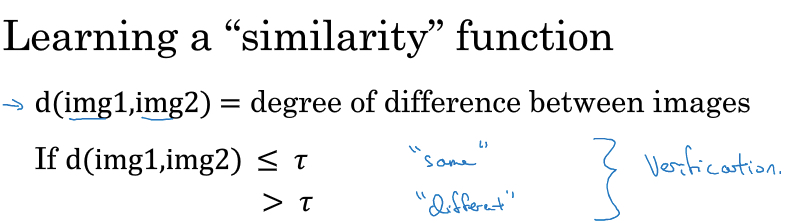
Siamese network
具体的做法,就是通过cnn对图片进行encoding,比如下图,一张图片会编码成128位的向量(往往成为embedding)
那么训练目标,就是相同人的图片得到的embedding间的距离比较小,反之

Triplet loss
Triplet,顾名思义,一个训练集中有3个图片,anchor作为baseline,一个positive,和一个negative
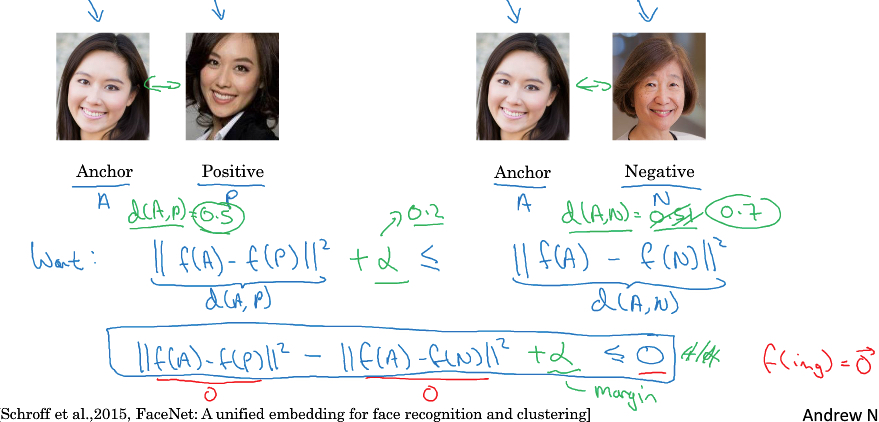
很明显,
我们的目的就是,让d(A,P)小于d(A,N),d是距离
光小于不够,要远小于,所以加上margin超参数alpha
形式化,

A和P的选择很简单,
对于N的选择,我们应该尽量选择和A相近的N,这样算法效率会更高,如果我们随机选择N,会让上面的约束很容易达到,会大大降低训练效率
除了triplet loss,也有其他的方法训练,siamese network ,比如下面的方法,把两个图片的embedding,作为logistics回归的输入,变成一个分类问题去训练

Neural sytle transfer
sytle transfer要做的如下图,
给出一张content图片C,一张style图片S,要的效果就是生成G
所以优化目标,J(G),由两部分组成,
J(C,G),表示G和C在content上的相似度
J(S,G),表示G和S在style上的相似度

下面就分别来定义这两个目标函数,
content cost function
判断内容是否相似比较直观,和前面脸部识别一样,我们只要把图片encoding成embedding,然后比较相似度就好
实际做,
找一个pre-trained的ConNet,选一层l的输出作为embedding,通常l不会太浅也不会太深,这样可以比较好的代表图片的内容
剩下的就是计算两个embedding的相似度

style cost function
关键是要找出,style是什么?
这里给出的定义是,对于某个layer,style是各个channel的相关系数
cnn中,某一层的各个channel是由不同的filter生成,filter可以理解代表某一种特征
直观理解,如果两个channel相关性高,说明其filters所代表的特征常常会同时出现,比如下图,中竖线和橘色两种特征
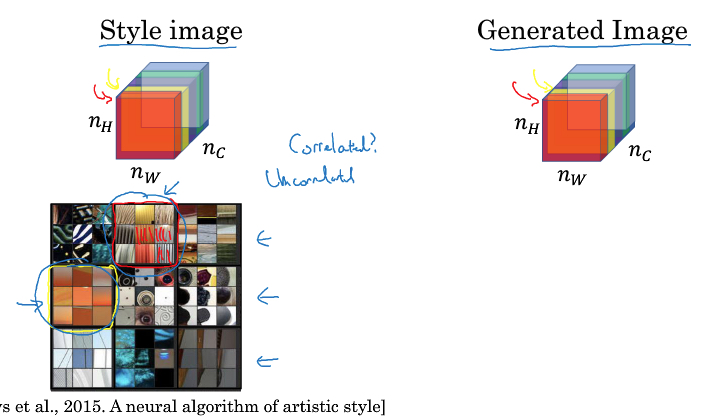
形式化定义,我们用style matrix,G[l],来表示图片在第l层的风格,
G用来表示每个channel之间的关系,所以nc*nc大小的
k层channel和k‘层channel的相关系数,就是两层对应的每个位置数据的乘积和,也称为gram矩阵
直观上简化一下,如果数据只有0,1,如果两层不相干,乘积和会为0,只有相关才会同时出现1,这样相关系数才会大

那么上面就给出在l层上,S和G的style的cost function,其实就是计算S和G的style matrix的差异
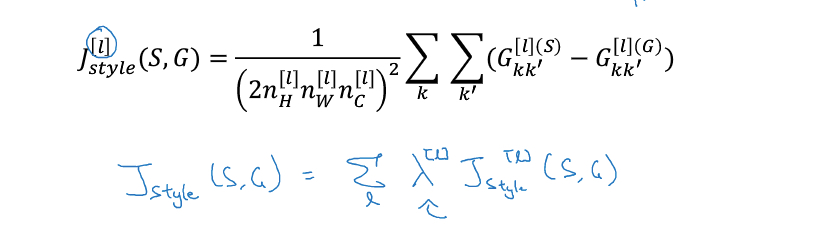
最终J(S,G)会考虑所有layer上的风格矩阵的差异

