聊聊Postgres中的IPC之SI Message Queue
在 PostgreSQL中,每一个进程都有属于自己的共享缓存(shared cache)。例如,同一个系统表在不同的进程中都有对应的Cache来缓存它的元组(对于RelCache来说缓存的是一个RelationData结构)。同一个系统表的元组可能同时被多个进程的Cache所缓存,当其中某个Cache中的一个元组被删除或更新时 ,需要通知其他进程对其Cache进行同步。在 PostgreSQL的实现中,会记录下已被删除的无效元组 ,并通过SI Message方式(即共享消息队列方式)在进程之间传递这一消息。收到无效消息的进程将同步地把无效元组(或RelationData结构)从自己的Cache中删除。
1.无效消息(Invalid Message)概述
当前系统支持传递6种无效消息:
第一种是使给定的catcache中的一个元组无效;
第二种是使给定的系统表的所有catcache结构全部失效;
第三种是使给定的逻辑表的Relcache中RelationData结构无效;
第四种是使给定的物理表的SMGR无效(表物理位置发生变化时,需要通知SMGR关闭表文件);
第五种是使给定的数据库的mapped-relation失效;
第六种是使一个已保存的快照失效。
可以看出这六种消息对应的影响范围越来越大。
PostgreSQL使用以下所示的结构体来存储无效消息。
typedef union
{
int8 id; /* type field --- must be first */
SharedInvalCatcacheMsg cc;
SharedInvalCatalogMsg cat;
SharedInvalRelcacheMsg rc;
SharedInvalSmgrMsg sm;
SharedInvalRelmapMsg rm;
SharedInvalSnapshotMsg sn;
} SharedInvalidationMessage;
其中,id为:
- 0或正数表示一个CatCache元组;
- -1表示整个CatCahe缓存;
- -2表示RelCache;
- -3表示SMGR;
- -4表示mapped-relation mapping;
- -5表示Snapshot
当id为0或正数时 ,它同时也表示产生该Invalid Message的CatCache的编号。
具体我们可以看注释:
src/include/storage/sinval.h
* * invalidate a specific tuple in a specific catcache
* * invalidate all catcache entries from a given system catalog
* * invalidate a relcache entry for a specific logical relation
* * invalidate an smgr cache entry for a specific physical relation
* * invalidate the mapped-relation mapping for a given database
* * invalidate any saved snapshot that might be used to scan a given relation
进程通过调用函数CachelnvalidateHeapTuple()对Invalid Message进行注册,主要包括以下几步:
-
- 注册SysCache无效消息。
-
- 如果是对pg_class系统表元组进行的更新/删除操作,其 relfilenode或 reltablespace可能发生变化,即该表物理位置发生变化,需要通知其他进程关闭相应的SMGR。这时首先设置relationid和databaseid,然后注册SMGR无效消息;否则转而执行步骤3。
-
- 如果是对pg_attribute或者pg_index系统表元组进行的更新/删除操作,则设置relationid和 dalabaseid,否则返回。
-
- 注册RelCache无效消息(如果有的话)。
-
- 事务结束时注册mapped-relation mapping和snapshot无效消息(如果有的话)。
当一个元组被删除或者更新时,在同一个SQL命令的后续执行步骤中我们依然认为该元组是有效的,直到下一个命令开始或者亊务提交时改动才生效。在命令的边界,旧元组变为失效,同时新元组置为有效。因此当执行heap_delete或者heap_update时,不能简单地刷新Cache。而且,即使刷新了,也可能由于同一个命令中的请求把该元组再次加载到Cache中。
因此正确的方法是保持一个无效链表用于记录元组的delete/update操作。事务完成后,根据前述的无效链表中的信息广播该事务过程中产生的Invalid Message,其他进程通过SI Message队列读取Invalid Message对各自的Cache进行刷新。当子事务提交时,只需要将该事务产生的Invalid Message提交到父事务,最后由最上层的事务广播Invalid Message。
需要注意的是,若涉及对系统表结构的改变,还需要重新加载pg_internal.init文件,因为该文件记录了所有系统表的结构。
2.SI Message全景
以下是相关的函数,写在前面,先混个脸熟:
CreateSharedInvalidationState() /* Create and initialize the SI message buffer
SharedInvalBackendInit() /* 每个backend初始化时要初始化在 SI message buffer 中的Per-backend invalidation state,procState[MaxBackends]
CleanupInvalidationState() /*每个backend shutdown时在调用on_shmem_exit()函数清空对应的procState[i]
SICleanupQueue() /* Remove messages that have been consumed by all active backends
* Possible side effects of this routine include marking one or more
* backends as "reset" in the array, and sending PROCSIG_CATCHUP_INTERRUPT
* to some backend that seems to be getting too far behind. We signal at
* most one backend at a time, for reasons explained at the top of the file.
SendSharedInvalidMessages() /* Add shared-cache-invalidation message(s) to the global SI message queue.
那么整个SI Message队列工作的流程大致如下:
- SI message 队列的初始化。这个是由postmaster在启动服务器时做的,作为共享内存的一部分,由postmaster初始化。此时,SI message为空,因为此时还没有Invalid Message产生。
- 每个backend初始化(我们知道这些Invalid Message是由于我执行了SQL文对数据库进行了修改才产生的,那么很显然我们执行SQL文的途径是前端发送SQL文,后端启动一个backend进程去处理)时,需要初始化自己的共享内存并且向SI message注册自己。注册的目的有两个,一个是声明自己作为Invalid Message的生产者的身份,另一个表示自己也需要接受其他backend的Invalid Message。
- 每个backend执行SQL文,产生Invalid Message,其他backend接收该Invalid Message,当然,这个过程复杂点,会在后面细说。那么每个backend接收和发送Invalid Message的时机是什么呢?
当然啦,你每次执行SQL的时候,是一个好时机,在执行SQL文的开头和结尾,backend都会去check SI message队列中的无效消息。以下是调用栈:
exec_simple_query
->start_xact_command
->StartTransactionCommand /* 事务开始
->StartTransaction
->AtStart_Cache
->AcceptInvalidationMessages
->ReceiveSharedInvalidMessages /* consume SI message
->SIGetDataEntries
-> do query
->finish_xact_command
->CommitTransactionCommand /* 事务结束
->CommitTransaction
->AtEOXact_Inval
->SendSharedInvalidMessages /* send SI message
->SIInsertDataEntries
->SICleanupQueue
那么,难道我不执行SQL文,我的backend就不刷新无效消息么?
我们看一段注释:
/*
* Because backends sitting idle will not be reading sinval events, we
* need a way to give an idle backend a swift kick in the rear and make
* it catch up before the sinval queue overflows and forces it to go
* through a cache reset exercise. This is done by sending
* PROCSIG_CATCHUP_INTERRUPT to any backend that gets too far behind.
*
* The signal handler will set an interrupt pending flag and will set the
* processes latch. Whenever starting to read from the client, or when
* interrupted while doing so, ProcessClientReadInterrupt() will call
* ProcessCatchupEvent().
*/
没有错,要是某个backend长时间不读取SI Message或者backend落后太多,超过了SI Message队列可以接受的最大长度,那么就向该backend发送SIGUSR1,唤醒该backend让其做适当的操作。
3.实现细节
为了实现SI Message的这一功能,PostgreSQL在共享内存中开辟了shmInvalBuffer记录系统中所发出的所有Invalid Message以及所有进程处理无消息的进度。shmInvalBuffer是一个全局变量,其数据结构如下:
typedef struct SISeg
{
/*
* General state information
*/
int minMsgNum; /* oldest message still needed */
int maxMsgNum; /* next message number to be assigned */
int nextThreshold; /* # of messages to call SICleanupQueue */
int lastBackend; /* index of last active procState entry, +1 */
int maxBackends; /* size of procState array */
slock_t msgnumLock; /* spinlock protecting maxMsgNum */
/*
* Circular buffer holding shared-inval messages
*/
SharedInvalidationMessage buffer[MAXNUMMESSAGES];
/*
* Per-backend invalidation state info (has MaxBackends entries).
*/
ProcState procState[FLEXIBLE_ARRAY_MEMBER];
} SISeg;
在shmInvalBuffer中,Invalid Message存储在由Buffer字段指定的定长数组中(其长度MAXNUMMESSAGES预定义为4096),该数组中每一个元素存储一个Invalid Message,也可以称该数组为无效消息队列。无效消息队列实际是一个环状结构,最初数组为空时,新来的无效消息从前向后依次存放在数组中,当数组被放满之后,新的无效消息将回到Buffer数组的头部开始插人。minMsgNum字段记录Buffer中还未被所有进程处理的无效消息编号中的最小值,maxMsgNum字段记录下一个可以用于存放新无效消息的数组元素下标。实际上,minMsgNum指出了Buffer中还没有被所有进程处理的无效消息的下界,而maxMsgNum则指出了上界,即编号比minMsgNmn小的无效消息是已经被所有进程处理完的,而编号大于等于maxMsgNum的无效消息是还没有产生的,而两者之间的无效消息则是至少还有一个进程没有对其进行处理。因此在无效消息队列构成的环中,除了 minMsgNum和maxMsgNum之间的位置之外,其他位置都可以用来存放新增加的无效消息。
PostgreSQL在shmInvalBuffer中用一个ProcState数组(procState字段)来存储正在读取无效消息的进程的读取进度,该数组的大小与系统允许的最大进程数MaxBackends有关,在默认情况下这个
数组的大小为100 (系统的默认最大进程数为100,可在postgresql.conf中修改)。ProcState的结构如数据结构如下所示。
/* Per-backend state in shared invalidation structure */
typedef struct ProcState
{
/* procPid is zero in an inactive ProcState array entry. */
pid_t procPid; /* PID of backend, for signaling */
PGPROC *proc; /* PGPROC of backend */
/* nextMsgNum is meaningless if procPid == 0 or resetState is true. */
int nextMsgNum; /* next message number to read */
bool resetState; /* backend needs to reset its state */
bool signaled; /* backend has been sent catchup signal */
bool hasMessages; /* backend has unread messages */
/*
* Backend only sends invalidations, never receives them. This only makes
* sense for Startup process during recovery because it doesn't maintain a
* relcache, yet it fires inval messages to allow query backends to see
* schema changes.
*/
bool sendOnly; /* backend only sends, never receives */
/*
* Next LocalTransactionId to use for each idle backend slot. We keep
* this here because it is indexed by BackendId and it is convenient to
* copy the value to and from local memory when MyBackendId is set. It's
* meaningless in an active ProcState entry.
*/
LocalTransactionId nextLXID;
} ProcState;
在ProcSlate结构中记录了PID为procPid的进程读取无效消息的状态,其中nextMsgNum的值介于 shmlnvalBuffer 的 minMsgNum 值和 maxMsgNum 值之间。
如下图所示,minMsgmun和MaxMsgmim就像两个指针,它们区分出了哪些无效消息已经被所有的进程读取以及哪些消息还在等待某些进程读取。在minMsgnum之前的消息已经被所有进程读完;maxMsgnum之后的区域尚未使用;两者之间的消息是还没有被所有进程读完的。当有进程调用函数SendSharedlnvalidMessage将其产生的无效消息添加到shmInvalBuffer中时,maxMsgnum就开始向后移动。SendSharedlnvalidMessage中将调用SIInsertDataEntries来完成无效消息的插人。
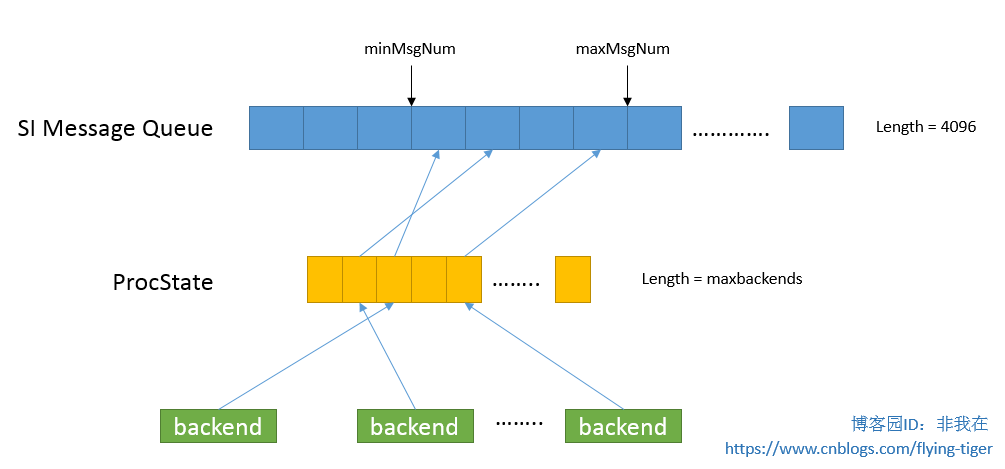
在向SI Message队列中插入无效消息时,可能出现可用空间不够的情况(此时队列中全是没有完全被读取完毕的无效消息),需要清空一部分未处理无效消息,这个操作称为清理无效消息队列,只有当当前消息数与将要插人消息数之和超过shmInvalBuffer中nextThreshold时才会进行清理操作。这时,那些还没有处理完SI Message队列中无效消息的进程将收到清理通知,然后这些进程将抛弃其Cache中的所有元组(相当于重新载人Cache的内容)。
显然,让所有进程重载Cache会导致较高的I/O次数。为了减少重载Cache的次数,PostgreSQL会在无效消息队列中设置两个界限值lowbound和minsig,其计算方式如下:
• lowbound=maxMsgNum-MAXNUMMESSAGES+minFree,其中 minFree 为需要释放的队列空间的最小值(minFree指出了需要在无效消息队列中清理出多少个空位用于容纳新的无效消息)。
• minsig = maxMsgNum-MAXNUMMESSAGES/2,这里给出的是minsig的初始值,在进程重载过程中minsig会进行调整。
SICleanupQueue
/*
* Recompute minMsgNum = minimum of all backends' nextMsgNum, identify the
* furthest-back backend that needs signaling (if any), and reset any
* backends that are too far back. Note that because we ignore sendOnly
* backends here it is possible for them to keep sending messages without
* a problem even when they are the only active backend.
*/
min = segP->maxMsgNum;
minsig = min - SIG_THRESHOLD;
lowbound = min - MAXNUMMESSAGES + minFree;
可以看到,lowbound实际上给出了此次清理过程中必须要释放的空间的位置,这是一个强制性的限制,nextMsgNum值低于lowbound的进程都将其resetState字段置为真,这些进程将会自动进行重载Cache的工作。对于那些nextMsgNum值介于lowbound和minaig之间的进程,虽然它们并不影响本次淸理,但是为了尽量避免经常进行清理操作,会要求这些进程加快处理无效消息的进度(CatchUp)。淸理操作会找出这些进程中进度最慢的一个,向它发送SIGUSR1信号。该进程接收到SIGUSR1后会一次性处理完所有的无效消息,然后继续向下一个进度最慢的进程发送SIGUSR1让它也加快处理进度。
清理无效消息队列的工作由函数SICleanupQueue实现,该函数的minFree参数给出了这一次淸理操作至少需要释放出的空间大小。该函数的流程如下:
SICleanupQueue
->SendProcSignal
1)计算 lowbound 和 minsig 的值。
-
对每一个进程的ProcState结构进行检査,将nextMsgNum低于lowbound的进程resetState字段设置为true,并在nextMsgNum介于lowboumi和minsig之间的进程中找出进度最慢的一个。
-
重新计算nextThreshoW参数。
-
向步骤2中找到的进度最慢的进程发送SIGUSR1信号。
Postgres进程通过函数ProcessCatchupInterrupt来处理SIGUSR1信号,该函数最终将调用ReceiveSharedlnvalidMessages来处理所有未处理的无效消息,最后调用SICleanupQueue (minFree参数为0)向下一个进度最慢的进程发送SIGUSR1信号(调用栈如下)。
ProcessCatchupInterrupt
->AcceptInvalidationMessages
->ReceiveSharedInvalidMessages
->SICleanupQueue
每个进程在需要刷新其Cache时也会调用ReceiveSharedInvalidMessages函数用于读取并处理无效消息,函数参数为两个函数指针:
-
invalFunction:用于处理一条无效消息。
-
resetFunction:将该后台进程的Cache元组全部抛弃。
对于resetState设置为真的进程,函数ReceiveSharedInvalidMessages会调用resetFunction抛弃其所有的Cache元组。否则,ReceiveSharedInvalidMessages将从消息队列中读取每条无效消息并调用invalFunction对消息进行处理。如果该进程是根据SIGUSR1信号调用该函数,那么还将调用SICleanupQueue函数将这个信号传给比它进度慢的进程。
4.其他
在PMsignal.c中,包含后台进程向Postmaster发送信号的相关函数。在实现中,后台进程是这样通知Postmaster的:
-
首先在共享内存中开辟一个数组PMSignalFlags(PMsignal.c),数组中的每一位对应一个信号。
-
然后如果后台进程希望向Postmaster发送一个信号,那么后台首先将信号在数组PMSignalFlags中相应的元素置1 (逻辑真),然后调用kill函数向Postmaster发送SIGUSR1信号。
-
当Postmaster收到SIGUSR1后首先检测共享存储中PMSignalFlags,确认具体的信号是什么。同时将信号在数组PMSignalFlags中相应的元素置0 (逻辑假)然后作出相应反应。
每一个后台进程都有一个结构PGPROC存储在共享内存中。Procarray.c在共享内存中分配ProcArrayStruct类型的数组procArray,统一管理这些PGPROC结构。PGPROC结构中包含很多的信息,Procarray.c中的函数主要处理 PGPROC中的 pid、databaseld、roleld、xmin、xid、subxids 等字段。这些函数的功能或是统计事务的信息,或是通过databaseId统计有多少个pid (也就是多少个后台进程)与指定数据库相连接等统计信息。
IPC负责的清除工作有两个方面:一个是与共享内存相关的清除,另一个是与各个后台进程相关的清除工作。与共享内存相关的淸除并不是将共享内存丢弃,而是重新设置共享内存。清除工作的流程可以描述如下:首先在申请资源的时候,系统会同时为该资源注册一个清除函数,当要求做清除操作时,系统将会调用对应的淸除函数。
IPC的内容还有不少,本次只是大致说了下关于SI Message共享队列的处理,其它的以后有时间再去写写吧。

