
Lenet 神经网络-实现篇(2)
Lenet 神经网络在 Mnist 数据集上的实现,主要分为三个部分:前向传播过程(mnist_lenet5_forward.py)、反向传播过程(mnist_lenet5_backword.py)、
测试过程(mnist_lenet5_test.py)。
第一,前向传播过程(mnist_lenet5_forward.py)实现对网络中参数和偏置的初始化、定义卷积结构和池化结构、定义前向传播过程。
#coding:utf-8 import tensorflow as tf #每张图片分辨率为28*28 IMAGE_SIZE = 28 #Mnist数据集为灰度图,故输入图片通道数NUM_CHANNELS取值为1 NUM_CHANNELS = 1 #第一层卷积核大小为5 CONV1_SIZE = 5 #卷积核个数为32 CONV1_KERNEL_NUM = 32 #第二层卷积核大小为5 CONV2_SIZE = 5 #卷积核个数为64 CONV2_KERNEL_NUM = 64 #全连接层第一层为 512 个神经元 FC_SIZE = 512 #全连接层第二层为 10 个神经元 OUTPUT_NODE = 10 #权重w计算 def get_weight(shape, regularizer): w = tf.Variable(tf.truncated_normal(shape,stddev=0.1)) if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w)) return w #偏置b计算 def get_bias(shape): b = tf.Variable(tf.zeros(shape)) return b #卷积层计算 def conv2d(x,w): return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') #最大池化层计算 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') def forward(x, train, regularizer): #实现第一层卷积 conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_NUM], regularizer) conv1_b = get_bias([CONV1_KERNEL_NUM]) conv1 = conv2d(x, conv1_w) #非线性激活 relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b)) #最大池化 pool1 = max_pool_2x2(relu1) #实现第二层卷积 conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_NUM, CONV2_KERNEL_NUM],regularizer) conv2_b = get_bias([CONV2_KERNEL_NUM]) conv2 = conv2d(pool1, conv2_w) relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b)) pool2 = max_pool_2x2(relu2) #获取一个张量的维度 pool_shape = pool2.get_shape().as_list() #pool_shape[1] 为长 pool_shape[2] 为宽 pool_shape[3]为高 nodes = pool_shape[1] * pool_shape[2] * pool_shape[3] #得到矩阵被拉长后的长度,pool_shape[0]为batch值 reshaped = tf.reshape(pool2, [pool_shape[0], nodes]) #实现第三层全连接层 fc1_w = get_weight([nodes, FC_SIZE], regularizer) fc1_b = get_bias([FC_SIZE]) fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b) #如果是训练阶段,则对该层输出使用dropout if train: fc1 = tf.nn.dropout(fc1, 0.5) #实现第四层全连接层 fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer) fc2_b = get_bias([OUTPUT_NODE]) y = tf.matmul(fc1, fc2_w) + fc2_b return y
1)定义前向传播过程中常用到的参数。
图片大小即每张图片分辨率为 28*28,故 IMAGE_SIZE 取值为 28;Mnist 数据集为灰度图,故输入图片通道数 NUM_CHANNELS 取值为 1;
第一层卷积核大小为 5,卷积核个数为 32,故 CONV1_SIZE 取值为 5,CONV1_KERNEL_NUM 取值为 32;
第二层卷积核大小为 5,卷积核个数为 64,故 CONV2_SIZE 取值为 5,CONV2_KERNEL_NUM为 64;
全连接层第一层为 512 个神经元,全连接层第二层为 10 个神经元,故FC_SIZE 取值为 512,OUTPUT_NODE 取值为 10,实现 10 分类输出。
2)把前向传播过程中,常用到的方法定义为函数,方便调用。
在 mnist_lenet5_forward.py 文件中,定义四个常用函数:
权重 w 生成函数、偏置 b 生成函数、卷积层计算函数、最大池化层计算函数,
其中,权重 w 生成函数和偏置 b 生成函数与之前的定义相同。
√①卷积层计算函数描述如下:
tf.nn.conv2d(输入描述[batch,行分辨率,列分辨率,通道数],
卷积核描述[行分辨率,列分辨率,通道数,卷积核个数],
核滑动步长[1,行步长,列步长,1],
填充模式 padding)
例如:
tf.nn.conv2d(x=[100,28,28,1], w=[5,5,1,6], strides=[1,1,1,1],
padding='SAME')
本例表示卷积输入 x 为 28*28*1,一个 batch_size 为 100(一次输入100张图片),卷积核大小为 5*5,卷积核个数为 6,垂直方向步长为 1,水平方向步长为 1,填充方式为全零填充。
②最大池化层计算函数描述如下:
tf.nn.max_pool(输入描述[batch,行分辨率,列分辨率,通道数],
池化核描述[1,行分辨率,列分辨率,1],
池化核滑动步长[1,行步长,列步长,1],
填充模式 padding)
例如:
tf.nn.max_pool(x=[100,28,28,1],ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding='SAME')
本例表示卷积输入 x 为 28*28*1,一个 batch_size 为 100,池化核大小用 ksize,第一维和第四维都为 1,池化核大小为 2*2,垂直方向步长为 1,水平方向步长
为 1,填充方式为全零填充。
3)定义前向传播过程
①实现第一层卷积 conv1_w =get_weight([CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,
CONV1_KERNEL_NUM],regularizer)
conv1_b = get_bias([CONV1_KERNEL_NUM])
根据先前定义的参数大小,初始化第一层卷积核和偏置项。
conv1 = conv2d(x, conv1_w)
实现卷积运算,输入参数为 x 和第一层卷积核参数。
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
第一层卷积的输出值作为非线性激活函数的输入值,首先通过 tf.nn.bias_add()对卷积后的输出添加偏置,并过 tf.nn.relu()完成非线性激活。
pool1 = max_pool_2x2(relu1)
根据先前定义的池化函数,将第一层激活后的输出值进行最大池化 。
√tf.nn.relu()用来实现非线性激活,相比 sigmoid 和 tanh 函数,relu 函数可
以实现快速的收敛。
②实现第二层卷积
conv2_w =get_weight([CONV2_SIZE,CONV2_SIZE,CONV1_KERNEL_NUM,
CONV2_KERNEL_NUM],regularizer)
conv2_b = get_bias([CONV2_KERNEL_NUM])
初始化第二层卷积层的变量和偏置项,该层每个卷积核的通道数要与上一层卷积核的个数一致。
conv2 = conv2d(pool1, conv2_w)
实现卷积运算,输入参数为上一层的输出 pool1 和第二层卷积核参数。
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
实现第二层非线性激活函数。
pool2 = max_pool_2x2(relu2)
根据先前定义的池化函数,将第二层激活后的输出值进行最大池化。
③将第二层池化层的输出 pool2 矩阵转化为全连接层的输入格式即向量形式:
pool_shape = pool2.get_shape().as_list()
根据.get_shape()函数得到 pool2 输出矩阵的维度,并存入 list 中。其中,pool_shape[0]为一个 batch 值。nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
从 list 中依次取出矩阵的长宽及深度,并求三者的乘积,得到矩阵被拉长后的长度。
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
将 pool2 转换为一个 batch 的向量再传入后续的全连接。
get_shape 函数用于获取一个张量的维度,并且输出张量每个维度上面的值。
例如:
A = tf.random_normal(shape=[3,4])
print A.get_shape()
输出结果为:(3,4)
④实现第三层全连接层:
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
初始化全连接层的权重,并加入正则化。
fc1_b = get_bias([FC_SIZE])
初始化全连接层的偏置项。
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_w) + fc1_b)
将转换后的 reshaped 向量与权重 fc1_w 做矩阵乘法运算,然后再加上偏置,最后再使用 relu 进行激活。
if train: fc1 = tf.nn.dropout(fc1, 0.5)
如果是训练阶段,则对该层输出使用 dropout,也就是随机的将该层输出中的一半神经元置为无效,是为了避免过拟合而设置的,一般只在全连接层中使用。
⑤实现第四层全连接层的前向传播过程:
fc2_w = get_weight([FC_SIZE, OUTPUT_NODE], regularizer)
fc2_b = get_bias([OUTPUT_NODE])
初始化全连接层对应的变量。
y = tf.matmul(fc1, fc2_w) + fc2_b
将转换后的 reshaped 向量与权重 fc2_w 做矩阵乘法运算,然后再加上偏置。第二,反向传播过程(mnist_lenet5_backward.py),完成训练神经网络的参数。
具体代码如下所示:mnist_lenet5_backward.py
#coding:utf-8 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import mnist_lenet5_forward import os import numpy as np #batch的数量 BATCH_SIZE = 100 #初始学习率 LEARNING_RATE_BASE = 0.005 #学习率衰减率 LEARNING_RATE_DECAY = 0.99 #正则化 REGULARIZER = 0.0001 #最大迭代次数 STEPS = 50000 #滑动平均衰减率 MOVING_AVERAGE_DECAY = 0.99 #模型保存路径 MODEL_SAVE_PATH="./model/" #模型名称 MODEL_NAME="mnist_model" def backward(mnist): #卷积层输入为四阶张量 #第一阶表示每轮喂入的图片数量,第二阶和第三阶分别表示图片的行分辨率和列分辨率,第四阶表示通道数 x = tf.placeholder(tf.float32,[ BATCH_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS]) y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE]) #前向传播过程 y = mnist_lenet5_forward.forward(x,True, REGULARIZER) #声明一个全局计数器 global_step = tf.Variable(0, trainable=False) #对网络最后一层的输出y做softmax,求取输出属于某一类的概率 ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)) #向量求均值 cem = tf.reduce_mean(ce) #正则化的损失值 loss = cem + tf.add_n(tf.get_collection('losses')) #指数衰减学习率 learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY, staircase=True) #梯度下降算法的优化器 #train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) train_step = tf.train.MomentumOptimizer(learning_rate,0.9).minimize(loss, global_step=global_step) #采用滑动平均的方法更新参数 ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) ema_op = ema.apply(tf.trainable_variables()) #将train_step和ema_op两个训练操作绑定到train_op上 with tf.control_dependencies([train_step, ema_op]): train_op = tf.no_op(name='train') #实例化一个保存和恢复变量的saver saver = tf.train.Saver() #创建一个会话 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) #通过 checkpoint 文件定位到最新保存的模型,若文件存在,则加载最新的模型 ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) for i in range(STEPS): #读取一个batch数据,将输入数据xs转成与网络输入相同形状的矩阵 xs, ys = mnist.train.next_batch(BATCH_SIZE) reshaped_xs = np.reshape(xs,( BATCH_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS)) #读取一个batch数据,将输入数据xs转成与网络输入相同形状的矩阵 _, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys}) if i % 100 == 0: print("After %d training step(s), loss on training batch is %g." % (step, loss_value)) saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) def main(): mnist = input_data.read_data_sets("./data/", one_hot=True) backward(mnist) if __name__ == '__main__': main()
1)定义训练过程中的超参数
规定一个 batch 的数量为 100,故 BATCH_SIZE 取值为 100;设定初始学习率为0.005.学习率衰减率为 0.99;最大迭代次数为 50000,故 STEPS 取值为 50000;
滑动平均衰减率设置为 0.99,并规定模型保存路径以及保存的模型名称。
2)完成反向传播过程
①给 x, y_是占位
x = tf.placeholder(tf.float32,[
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None,mnist_lenet5_forward.
OUTPUT_NODE])
x, y_是定义的占位符,指定参数为浮点型。由于卷积层输入为四阶张量,故 x的占位符表示为上述形式,
第一阶表示每轮喂入的图片数量,第二阶和第三阶分别表示图片的行分辨率和列分辨率,第四阶表示通道数。
x = tf.placeholder(dtype,shape,name=None)
tf.placeholder()函数有三个参数,dtype 表示数据类型,常用的类型为
tf,float32,tf.float64 等数值类型,shape 表示数据形状,namen 表示名称。
②调用前向传播过程
y = mnist_lenet5_forward.forward(x,True, REGULARIZER)
调用前向传播网络得到维度为 10 的 tensor。
③求含有正则化的损失值
global_step = tf.Variable(0, trainable=False)
声明一个全局计数器,并输出化为 0
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,
labels=tf.argmax(y_, 1))
对网络最后一层的输出 y 做 softmax,求取输出属于某一类的概率,结果为一个num_classes 大小的向量,再将此向量和实际标签值做交叉熵,返回一个向量值。
cem = tf.reduce_mean(ce)
通过 tf.reduce_mean()函数对得到的向量求均值,得到 loss。
loss = cem + tf.add_n(tf.get_collection('losses'))
添加正则化中的 losses 值到 loss 中。
sparse_softmax_cross_entropy_with_logits(_sentinel=None,
labels=None,
logits=None,
name=None)
此函数的参数 logits 为神经网络最后一层的输出,它的大小为[batch_size,num_classes],参数 labels 表示实际标签值,大小为[batch_size,num_classes]。
第一步是先对网络最后一层的输出做一个 softmax,输出为属于某一属性的概率向量;再将概率向量与实际标签向量做交叉熵,返回向量。
tf.reduce_mean( input_tensor,
reduction_indices=None,
keep_dims=False,
name=None)
此函数表示对得到的向量求取均值。参数 input_tensor 表示要减少的张量;参数 reduction_indices 表示求取均值的维度;
参数 keep_dims 含义为:如果为 true,则保留长度为 1 的缩小尺寸。name 表示操作的名称。
例如:
x = tf.constant([[1., 1.], [2., 2.]])
tf.reduce_mean(x) #表示对向量整体求均值 1.5
tf.reduce_mean(x, 0) #表示对向量在列上求均值[1.5, 1.5]
tf.reduce_mean(x, 1) #表示对向量在行上求均值[1., 2.]
④实现指数衰减学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step, mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
tf.train.exponential_decay 函数中参数 LEARNING_RATE_BASE 表示初始学习率,参数 LEARNING_RATE_DECAY 表示学习率衰减速率。
实现指数级的减小学习率,可以让模型在训练的前期快速接近较优解,又可以保证模型在训练后期不会有太大波动。
其中,当 staircase=True 时,为阶梯形衰减,(global_step/decay_steps)则被转化为整数;
当 staircase=False 时,为曲线形衰减,以此根据 staircase 来选择不同的衰减方式。
计算公式为:
decayed_learning_rate=learining_rate*decay_rate^(global_step/decay_steps)
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
此函数的参数 learning_rate 为传入的学习率,构造一个实现梯度下降算法的优化器,再通过使用 minimize 更新存储要训练的变量的列表来减小 loss。
⑤实现滑动平均模型
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
ema_op = ema.apply(tf.trainable_variables())
tf.train.ExponentialMovingAverage 函数采用滑动平均的方法更新参数。此函数的参数 MOVING_AVERAGE_DECAY 表示衰减速率,用于控制模型的更新速度;
此函数维护一个影子变量,影子变量初始值为变量初始值。
影子变量值的更新方式如下:shadow_variable = decay * shadow_variable + (1-decay) * variable。
其中,shadow_variable 是影子变量,variable 表示待更新的变量,decay 为衰减速率。decay 一般设为接近于 1 的数(0.99,0.999),decay 越大模型越稳定。
⑥将 train_step 和 ema_op 两个训练操作绑定到 train_op 上
with tf.control_dependencies([train_step, ema_op]): train_op = tf.no_op(name='train')
⑦实例化一个保存和恢复变量的 saver,并创建一个会话
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
创建一个会话,并通过 python 中的上下文管理器来管理这个会话,初始化
计算图中的变量,并用 sess.run 实现初始化。
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
通过 checkpoint 文件定位到最新保存的模型,若文件存在,则加载最新的
模型。
for i in range(STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(
BATCH_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.IMAGE_SIZE,
mnist_lenet5_forward.NUM_CHANNELS))
读取一个 batch 数据,将输入数据 xs 转成与网络输入相同形状的矩阵。
_, loss_value, step = sess.run([train_op, loss, global_step],
feed_dict={x: reshaped_xs, y_: ys})
喂入训练图像和标签,开始训练。
if i % 100 == 0:
print("After %d training step(s), loss on training batch is %g." %
(step, loss_value))
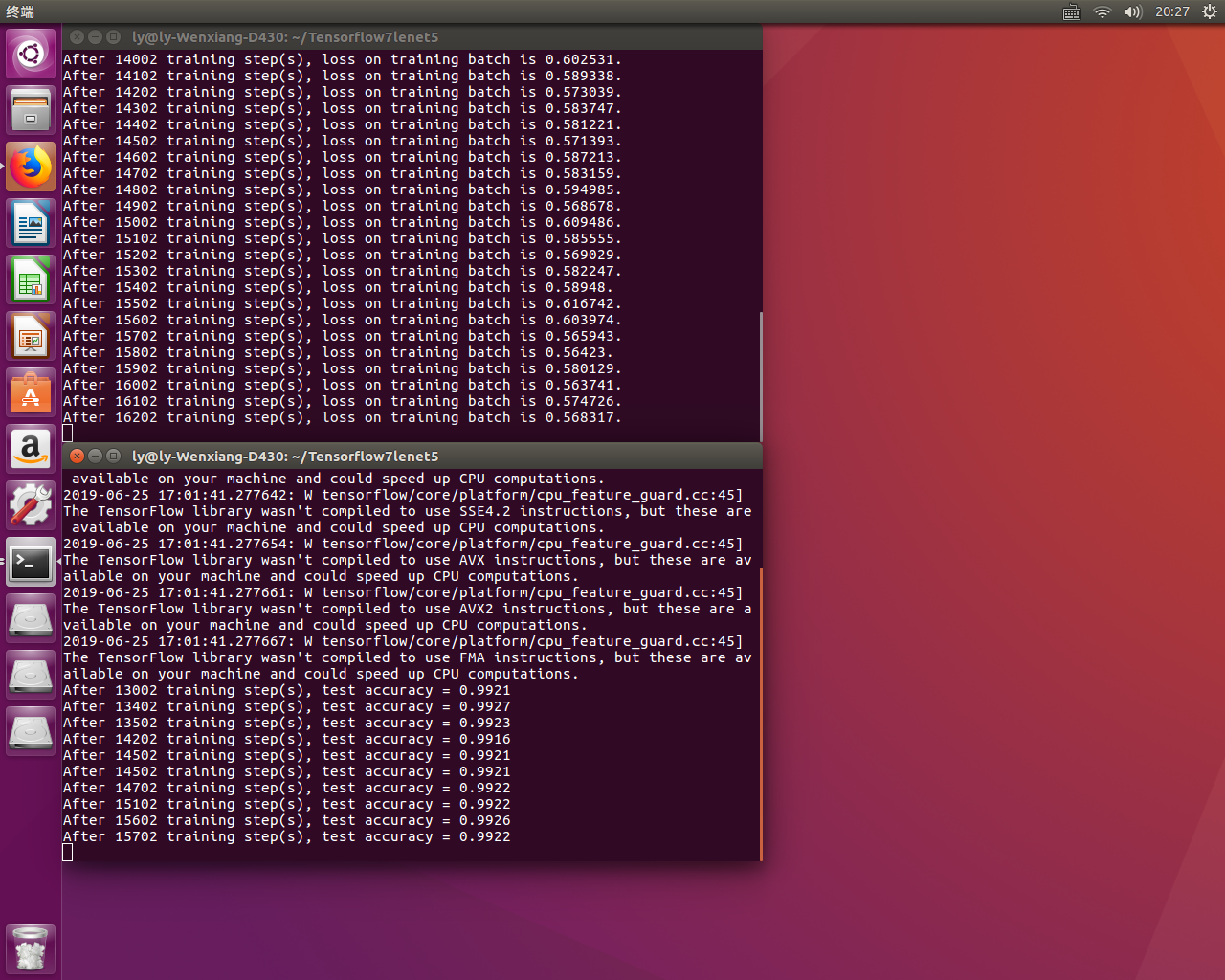
每迭代 100 次打印 loss 信息,并保存最新的模型。训练 Lenet 网络后,输出结果在最前面图中
由运行结果可以看出,损失值在不断减小,且可以实现断点续训。
第三,测试过程(mnist_lenet5_test.py),对 Mnist 数据集中的测试数据进行预测,测试模型准确率。具体代码如下所示:
#coding:utf-8 import time import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import mnist_lenet5_forward import mnist_lenet5_backward import numpy as np TEST_INTERVAL_SECS = 5 #创建一个默认图,在该图中执行以下操作 def test(mnist): with tf.Graph().as_default() as g: x = tf.placeholder(tf.float32,[ mnist.test.num_examples, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS]) y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OUTPUT_NODE]) #训练好的网络,故不使用 dropout y = mnist_lenet5_forward.forward(x,False,None) ema = tf.train.ExponentialMovingAverage(mnist_lenet5_backward.MOVING_AVERAGE_DECAY) ema_restore = ema.variables_to_restore() saver = tf.train.Saver(ema_restore) #判断预测值和实际值是否相同 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) ## 求平均得到准确率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) while True: with tf.Session() as sess: ckpt = tf.train.get_checkpoint_state(mnist_lenet5_backward.MODEL_SAVE_PATH) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) # 根据读入的模型名字切分出该模型是属于迭代了多少次保存的 global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1] reshaped_x = np.reshape(mnist.test.images,( mnist.test.num_examples, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS)) #利用多线程提高图片和标签的批获取效率 coord = tf.train.Coordinator()#3 threads = tf.train.start_queue_runners(sess=sess, coord=coord)#4 accuracy_score = sess.run(accuracy, feed_dict={x:reshaped_x,y_:mnist.test.labels}) print("After %s training step(s), test accuracy = %g" % (global_step, accuracy_score)) #关闭线程协调器 coord.request_stop()#6 coord.join(threads)#7 else: print('No checkpoint file found') return time.sleep(TEST_INTERVAL_SECS) def main(): mnist = input_data.read_data_sets("./data/", one_hot=True) test(mnist) if __name__ == '__main__': main()
1)在测试程序中使用的是训练好的网络,故不使用 dropout,而是让所有神经元都参与运算,从而输出识别准确率。
2)correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
√tf.equaf(x,y)
此函数用于判断函数的两个参数 x 与 y 是否相等,一般 x 表示预测值,y 表示实际值。
3)accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
求平均得到预测准确率。
注:本文章通过观看北京大学曹健老师的Tensorflow视频,笔记总结而来的。

