【Python实战】Scrapy豌豆荚应用市场爬虫
对于给定的大量APP,如何爬取与之对应的(应用市场)分类、描述的信息?且看下面分解。
1. 页面分析
当我们在豌豆荚首页搜索框输入微信后,会跳转到搜索结果的页面,其url为http://www.wandoujia.com/search?key=%微信。搜索结果一般是按相关性排序的;所以,我们认为第一条搜索结果为所需要爬取的。紧接着,点进去后会跳转到页面http://www.wandoujia.com/apps/com.tencent.mm,我们会发现豌豆荚的APP的详情页,是www.wandoujia.com/apps/ + APP package组成。
让我们退回到搜索结果页面,分析页面元素,如图:

所有搜索结果在<ul>无序列表标签中,每一个搜索结果在<li>标签中。对应地,CSS选择器应为
'#j-search-list>li::attr(data-pn)'
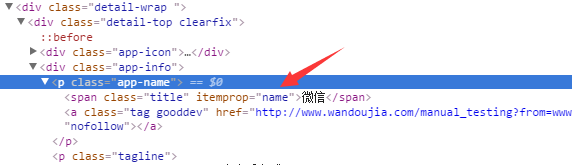
接下来,我们来分析APP的详情页,APP的名称所对应的HTML元素如图:
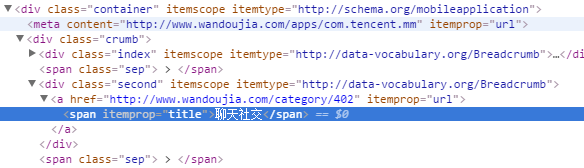
APP类别的如图:
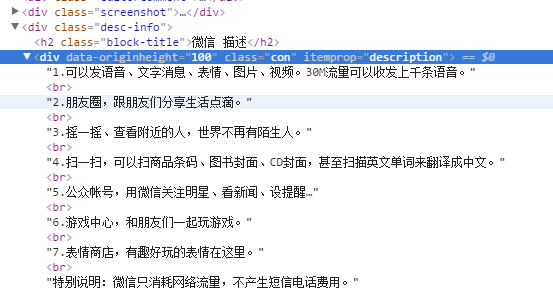
APP描述的如图:
不难得到这三类元素所对应的CSS选择器
.app-name>span::text
.crumb>.second>a>span::text
.desc-info>.con::text
通过上面的分析,确定爬取策略如下:
- 逐行读取APP文件,拼接搜索页面URL;
- 分析搜索结果页面,跳转到第一条结果对应的详情页;
- 爬取详情页相关结果,写到输出文件
2. 爬虫实现
分析完页面,可以coding写爬虫了。但是,若裸写Python实现,则要处理下载间隔、请求、页面解析、爬取结果序列化。Scrapy提供一个轻量级、快速的web爬虫框架,并很好地解决了这些问题;中文doc有比较详尽的介绍。
数据清洗
APP文件中,可能有一些名称不规整,需要做清洗:
# -*- coding: utf-8 -*-
import re
def clean_app_name(app_name):
space = u'\u00a0'
app_name = app_name.replace(space, '')
brackets = r'\(.*\)|\[.*\]|【.*】|(.*)'
return re.sub(brackets, '', app_name)
URL处理
拿清洗后APP名称,拼接搜索结果页面URL。因为URL不识别中文等字符,需要用urllib.quote做URL编码:
# -*- coding: utf-8 -*-
from appMarket import clean
import urllib
def get_kw_url(kw):
"""concatenate the url for searching"""
base_url = u"http://www.wandoujia.com/search?key=%s"
kw = clean.clean_app_name(kw)
return base_url % (urllib.quote(kw.encode("utf8")))
def get_pkg_url(pkg):
"""get the detail url according to pkg"""
return 'http://www.wandoujia.com/apps/%s' % pkg
爬取
Scrapy的爬虫均继承与scrapy.Spider类,主要的属性及方法:
- name,爬虫的名称,
scrapy crawl命令后可直接跟爬虫的名称,即可启动该爬虫 - allowed_domains,允许爬取域名的列表
- start_requests(),开始爬取的方法,返回一个可迭代对象(iterable),一般为scrapy.Request对象
- parse(response),既可负责处理response并返回处理的数据,也可以跟进的URL(以做下一步处理)
items为保存爬取后数据的容器,类似于Python的dict,
import scrapy
class AppMarketItem(scrapy.Item):
# define the fields for your item here like:
kw = scrapy.Field() # key word
name = scrapy.Field() # app name
tag = scrapy.Field() # app tag
desc = scrapy.Field() # app description
豌豆荚Spider代码:
# -*- coding: utf-8 -*-
# @Time : 2016/6/23
# @Author : rain
import scrapy
import codecs
from appMarket import util
from appMarket.util import wandoujia
from appMarket.items import AppMarketItem
class WandoujiaSpider(scrapy.Spider):
name = "WandoujiaSpider"
allowed_domains = ["www.wandoujia.com"]
def __init__(self):
self.apps_path = './input/apps.txt'
def start_requests(self):
with codecs.open(self.apps_path, 'r', 'utf-8') as f:
for app_name in f:
yield scrapy.Request(url=wandoujia.get_kw_url(app_name),
callback=self.parse_search_result,
meta={'kw': app_name.rstrip()})
def parse(self, response):
item = AppMarketItem()
item['kw'] = response.meta['kw']
item['name'] = response.css('.app-name>span::text').extract_first()
item['tag'] = response.css('.crumb>.second>a>span::text').extract_first()
desc = response.css('.desc-info>.con::text').extract()
item['desc'] = util.parse_desc(desc)
item['desc'] = u"" if not item["desc"] else item["desc"].strip()
self.log(u'crawling the app %s' % item["name"])
yield item
def parse_search_result(self, response):
pkg = response.css("#j-search-list>li::attr(data-pn)").extract_first()
yield scrapy.Request(url=wandoujia.get_pkg_url(pkg), meta=response.meta)
APP文件里的应用名作为搜索词,也应被写在输出文件里。但是,在爬取时URL有跳转,如何在不同层级间的Request传递变量呢?Request中的meta (dict) 参数实现了这种传递。
APP描述.desc-info>.con::text,extract返回的是一个list,拼接成string如下:
def parse_desc(desc):
return reduce(lambda a, b: a.strip()+b.strip(), desc, '')
结果处理
Scrapy推荐的序列化方式为Json。Json的好处显而易见:
- 跨语言;
- Schema明晰,较于'\t'分割的纯文本,读取不易出错
爬取结果有可能会有重复的、为空的(无搜索结果的);此外,Python2序列化Json时,对于中文字符,其编码为unicode。对于这些问题,可自定义Pipeline对结果进行处理:
class CheckPipeline(object):
"""check item, and drop the duplicate one"""
def __init__(self):
self.names_seen = set()
def process_item(self, item, spider):
if item['name']:
if item['name'] in self.names_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.names_seen.add(item['name'])
return item
else:
raise DropItem("Missing price in %s" % item)
class JsonWriterPipeline(object):
def __init__(self):
self.file = codecs.open('./output/output.json', 'wb', 'utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
还需在settings.py中设置
ITEM_PIPELINES = {
'appMarket.pipelines.CheckPipeline': 300,
'appMarket.pipelines.JsonWriterPipeline': 800,
}
分配给每个类的整型值,确定了他们运行的顺序,按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。

