
网络爬虫
这次去杭州参加阿里巴巴的离线大数据处理暑期课,得到一个思路。
之前一直纠结于没有数据要怎么训练我的旅行个性化推荐。毕设木有头绪啊,做不粗来要人命呀!
现在觉得可以在网上爬一些数据下来,看看能不能分析出各个景点之间的关系。
现在 开贴记录自己的工作。
2013.7.24
使用urllib。(3.0以后urllib2就整合到urllib中了,见【这里】)
import urllib.request c = urllib.request.urlopen('http://www.baidu.com') contents = c.read() print(contents[0:50])
代码参考自《集体智慧编程》,然后根据python3.2做了一些改动。
可以看到爬下来的一些东西

除了爬虫以外,我们还需要HTML和XML的解析器。
http://www.crummy.com/software/BeautifulSoup/bs4/doc/
安装好以后,我们试一下beautiful soup 4

现在安装一下python和mysql的连接器。地址见 http://dev.mysql.com/downloads/connector/python/
链接数据库的方法见 http://smilejay.com/2013/03/python3-mysql-connector/
过滤字母和数字
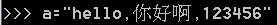

之前的构想是打算滤掉字母、数字、空白标示符、HTML标签,只留下中文字符和最基本的标点符号。今早醒来想一想,觉得这样不行,因为滤掉的这些部分其实含有丰富的信息。比如a标签的路径和内容都是文章与其他网页的重要关联。h标签和em标签也是同理。而且css部分,看似无用,其实可以用来判断这个站点是否够新鲜(通过它使用的css技术,例如是否使用了自适应、声明的doc类型是否够潮。当然,站点的新鲜程度与内容的重要程度是不太有关系的)。总之,今天需要做一些改动,把完整的网页信息保存下来,而不是只保存文本的部分。以后要用到哪些,再拿来分析和提取。
————————————————————
2013.7.26 代码备份


#2013-7-26 import mysql.connector import sys, os from bs4 import BeautifulSoup from urllib.request import urlopen from html.parser import HTMLParser import re #数据库相关操作 class DBconnector: user = 'root' pwd = 'root' host = '127.0.0.1' db = 'test' cnx = mysql.connector.connect(user=user, password=pwd, host=host, database=db) cursor = cnx.cursor() def __init__(self): pass def __del__(self): self.cursor.close() self.cnx.close() def createTable(): create_table_sql = "CREATE TABLE IF NOT EXISTS testpages ( \ url varchar(100) , \ title varchar(50), content varchar(10000) ) \ CHARACTER SET utf8" try: self.cursor.execute(create_table_sql) except mysql.connector.Error as err: print("create table 'pages' failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def insert(self,url, title, content): sql = "REPLACE INTO pages (url, title, content) VALUES ('{}', '{}', '{}')".format(url, title, content) try: self.cursor.execute(sql) except mysql.connector.Error as err: print("replace into table 'pages' - failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() #从html中删去标签 class MLStripper(HTMLParser): def __init__(self): super().__init__() self.reset() self.fed = [] def handle_data(self, d): self.fed.append(d) def get_data(self): return ''.join(self.fed) def strip_tags(html): s = MLStripper() s.feed(html) return s.get_data() class Crawler: initURL = "http://lvyou.baidu.com/" conn = DBconnector() def webCapture(self): c = urlopen(self.initURL).read() c1 = "你好啊fdfdafd123456,.fdle)(" soup = BeautifulSoup(c) links = soup('a') links.append(self.initURL) for link in links: c_temp = urlopen(link.href).read() print(link.href) soup = BeautifulSoup(c_temp) temp_links = soup('a') links += temp_links template = re.compile(r'\d|[a-z]|[A-Z]|\\|\/|<.*>|{|}|\s|-|#|"|\'') #body = template.sub('',strip_tags(c)) body = template.sub('',str(soup.body)) print(body) self.conn.insert(link, soup('title'), body) crawler = Crawler() crawler.webCapture()
————————————————————
2013.7.27
今天更新了一些代码
#20130727 import mysql.connector import sys, os from bs4 import BeautifulSoup from urllib.request import urlopen from html.parser import HTMLParser import re import hashlib #数据库相关操作 class DBconnector: user = 'root' pwd = 'root' host = '127.0.0.1' db = 'test' cnx = mysql.connector.connect(user=user, password=pwd, host=host, database=db) cursor = cnx.cursor() def __init__(self): pass def __del__(self): self.cursor.close() self.cnx.close() def createTable(): create_table_sql = "CREATE TABLE IF NOT EXISTS testpages ( \ url varchar(100) , \ title varchar(50), content varchar(10000) ) \ CHARACTER SET utf8" try: self.cursor.execute(create_table_sql) except mysql.connector.Error as err: print("create table 'pages' failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def insert(self,url, title, content): sql = "REPLACE INTO pages (url, title, content) VALUES ('{}', '{}', '{}')".format(url, title, content) try: self.cursor.execute(sql) except mysql.connector.Error as err: print("replace into table 'pages' - failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def select(self, url): select_sql = "select content from pages where url ='{}'".format(url) try: self.cursor.execute(select_sql) for content in self.cursor: return content except mysql.connector.Error as err: print("query table 'mytable' failed.") print("Error: {}".format(err.msg)) sys.exit() #从html中删去标签 class MLStripper(HTMLParser): def __init__(self): super().__init__() self.reset() self.fed = [] def handle_data(self, d): self.fed.append(d) def get_data(self): return ''.join(self.fed) def strip_tags(html): s = MLStripper() s.feed(html) return s.get_data() class Crawler: conn = DBconnector() #判断一个页面是否已经爬过 def pageExist(self, url): charge = self.conn.select(url) print('---charge---',charge) if charge: return True else: return False #将页面内容写入文件中,以url的sha256命名,并返回文件名 def writeToFile(self, url, content): location = 'G:\\pages\\' m = hashlib.sha256() m.update(url.encode('utf-8')) f = open(location + m.hexdigest(),'wb') f.write(content) f.close print('writing file: ' + url) return m.hexdigest() #将路径、网页标题、文件名存入数据库中 def writeToDB(self, conn, url, title, filename): self.conn.insert(url, title, filename) #解析网页,分析出标题、链接、内容,并返回 def parsePage(self, url): content = urlopen(url,timeout=5000).read() soup = BeautifulSoup(content) links = [] tempLinks = [soup.a['href'],] print('--tempLinks--',tempLinks) for tempLink in tempLinks: if self.pageExist(tempLink): continue else: #判断是否是一条完整的路径 print('tempLink->' + tempLink) protocol = re.findall(r'http|https',tempLink) if len(protocol) == 0: print('none protocal has found') #从8开始找是因为https://的最后一个/刚好在第七位 end = url.find('/',8) domain = url[0:end + 1] tempURL = ''.join(domain + tempLink) else: tempURL = tempLink print('tempURL->' + tempURL) links += [''.join(tempURL),] title = soup.title return (title, links, content) def webCapture(self): links = ['http://www.cnblogs.com',]#"http://xian.cncn.com/" for link in links: print("current link->" + link) #解析页面 (title, addlinks, content) = self.parsePage(link) links += addlinks #将页面内容写入文件 filename = self.writeToFile(link, content) #将url、标题、页面对应的文件名写入数据库中 self.writeToDB(self.conn, link, title, filename) crawler = Crawler() crawler.webCapture()
————————————————————
2013.7.29
今天的爬虫,因为编码的原因整得人焦头烂额
1、URL open timeout 是一种常态,一定要写try catch来处理这种情况,不能让爬虫因为链接超时而退出
2、urllib的urlopen貌似只接受ascii型的参数,查了半天也没找到什么好办法, 最后还是进python33/lib/http/下面改了
client.py文件的953行
request.encode('ascii')为request.encode('utf-8')才终于跑起来了……
今天更新的代码:(PS:晚上待着实验室真是一种喂蚊子的节奏……T_T)
#2013.7.29 import mysql.connector import sys, os from bs4 import BeautifulSoup import urllib from urllib.request import urlopen from html.parser import HTMLParser import re import hashlib import socket import imp #数据库相关操作 class DBconnector: user = 'root' pwd = 'root' host = '127.0.0.1' db = 'test' cnx = mysql.connector.connect(user=user, password=pwd, host=host, database=db) cursor = cnx.cursor() def __init__(self): pass def __del__(self): self.cursor.close() self.cnx.close() def createTable(): create_table_sql = "CREATE TABLE IF NOT EXISTS testpages ( \ url varchar(100) , \ title varchar(50), content varchar(10000) ) \ CHARACTER SET utf8" try: self.cursor.execute(create_table_sql) except mysql.connector.Error as err: print("create table 'pages' failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def insert(self,url, title, content): sql = "REPLACE INTO pages (url, title, content) VALUES ('{}', '{}', '{}')".format(url, title, content) try: self.cursor.execute(sql) except mysql.connector.Error as err: print("replace into table 'pages' - failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def select(self, url): select_sql = "select content from pages where url ='{}'".format(url) try: self.cursor.execute(select_sql) for content in self.cursor: return content except mysql.connector.Error as err: print("query table 'mytable' failed.") print("Error: {}".format(err.msg)) sys.exit() #从html中删去标签 class MLStripper(HTMLParser): def __init__(self): super().__init__() self.reset() self.fed = [] def handle_data(self, d): self.fed.append(d) def get_data(self): return ''.join(self.fed) def strip_tags(html): s = MLStripper() s.feed(html) return s.get_data() class Crawler: conn = DBconnector() #判断一个页面是否已经爬过 def pageExist(self, url): charge = self.conn.select(url) if charge: return True else: return False #将页面内容写入文件中,以url的sha256命名,并返回文件名 def writeToFile(self, url, content): location = 'G:\\pages\\' m = hashlib.sha256() m.update(url.encode('utf-8')) f = open(location + m.hexdigest(),'wb') f.write(content) f.close print('writing file: ' + m.hexdigest()) return m.hexdigest() #将路径、网页标题、文件名存入数据库中 def writeToDB(self, conn, url, title, filename): self.conn.insert(url, title, filename) #解析网页,分析出标题、链接、内容,并返回 def parsePage(self, url): socket.setdefaulttimeout(2) try: content = urlopen(url).read() except urllib.error.URLError: print('URL open time out!') return None, None, None except socket.timeout: print('socket time out!') return None, None, None soup = BeautifulSoup(content) links = [] tempLinks = [] atags = soup.findAll('a', attrs={'href': re.compile("^http://|https://")}) print('len of atags->', len(atags)) #从a标签中提取出路径放入tempLinks中 for atag in atags: tsoup = BeautifulSoup(str(atag)) turl = tsoup.a['href'] if turl in tempLinks: continue else: tempLinks += [turl] for tempLink in tempLinks: if self.pageExist(tempLink): continue else: #判断是否是一条完整的路径 #print('tempLink->' + tempLink) protocol = re.findall(r'http|https',tempLink) if len(protocol) == 0: #从8开始找是因为https://的最后一个/刚好在第七位 end = url.find('/',8) domain = url[0:end + 1] tempURL = ''.join(domain + tempLink) else: tempURL = tempLink links += [''.join(tempURL),] title = soup.title return (title, links, content) def webCapture(self): links = ['http://lvyou.baidu.com/xian',]#"http://xian.cncn.com/" for link in links: #print("current link->" + link) #解析页面 (title, addlinks, content) = self.parsePage(link) if title == None and addlinks == None and content == None: continue else: links += addlinks #将页面内容写入文件 filename = self.writeToFile(link, content) #将url、标题、页面对应的文件名写入数据库中 temp = re.compile(r'<.*>') title = temp.sub('',str(title)) self.writeToDB(self.conn, link, title, filename) crawler = Crawler() crawler.webCapture()
————————————————————
2013.7.31
今天重写了links循环的部分,抓网页的量也上去了。不过抽查一部分抓到的网页发现,基本上全被ajax占领了。最后纪念一下这些天的代码。明天改用Scrapy框架来抓。
#20130731 import mysql.connector import sys, os from bs4 import BeautifulSoup import urllib from urllib.request import urlopen from html.parser import HTMLParser import re import hashlib import socket import imp #数据库相关操作 class DBconnector: user = 'root' pwd = 'root' host = '127.0.0.1' db = 'test' cnx = mysql.connector.connect(user=user, password=pwd, host=host, database=db) cursor = cnx.cursor() def __init__(self): pass def __del__(self): self.cursor.close() self.cnx.close() def createTable(): create_table_sql = "CREATE TABLE IF NOT EXISTS testpages ( \ url varchar(100) , \ title varchar(50), filename varchar(64) ) \ CHARACTER SET utf8" try: self.cursor.execute(create_table_sql) except mysql.connector.Error as err: print("create table 'pages' failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def insert(self,url, title, filename): sql = "REPLACE INTO pages (url, title, filename) VALUES ('{}', '{}', '{}')".format(url, title, filename) try: self.cursor.execute(sql) except mysql.connector.Error as err: print("replace into table 'pages' - failed.") print("Error: {}".format(err.msg)) sys.exit() self.cnx.commit() def select(self, url): select_sql = "select filename from pages where url ='{}'".format(url) try: self.cursor.execute(select_sql) for filename in self.cursor: return filename except mysql.connector.Error as err: print("query table 'pages' failed.") print("Error: {}".format(err.msg)) sys.exit() #从html中删去标签 class MLStripper(HTMLParser): def __init__(self): super().__init__() self.reset() self.fed = [] def handle_data(self, d): self.fed.append(d) def get_data(self): return ''.join(self.fed) def strip_tags(html): s = MLStripper() s.feed(html) return s.get_data() class Crawler: conn = DBconnector() #判断一个页面是否已经爬过 def pageExist(self, url): charge = self.conn.select(url) if charge: return True else: return False #将页面内容写入文件中,以url的sha256命名,并返回文件名 def writeToFile(self, url, filename): location = 'G:\\pages\\' m = hashlib.sha256() m.update(url.encode('utf-8')) f = open(location + m.hexdigest(),'wb') f.write(filename) f.close print('writing file: ' + m.hexdigest()) return m.hexdigest() #将路径、网页标题、文件名存入数据库中 def writeToDB(self, conn, url, title, filename): self.conn.insert(url, title, filename) #解析网页,分析出标题、链接、内容,并返回 def parsePage(self, url): socket.setdefaulttimeout(2) try: content = urlopen(url).read() except urllib.error.URLError: print('URL open time out!') return None, None, None except socket.timeout: print('socket time out!') return None, None, None except ConnectionAbortedError: print('socket time out!') return None, None, None soup = BeautifulSoup(content) links = [] tempLinks = [] atags = soup.findAll('a', attrs={'href': re.compile("^http://|https://")}) print('len of atags->', len(atags)) #从a标签中提取出路径放入tempLinks中 for atag in atags: tsoup = BeautifulSoup(str(atag)) turl = tsoup.a['href'] if turl in tempLinks: continue else: tempLinks += [turl] while len(tempLinks) != 0: tempLink = tempLinks.pop() if self.pageExist(tempLink): continue else: #判断是否是一条完整的路径 #print('tempLink->' + tempLink) protocol = re.findall(r'http|https',tempLink) if len(protocol) == 0: #从8开始找是因为https://的最后一个/刚好在第七位 end = url.find('/',8) domain = url[0:end + 1] tempURL = ''.join(domain + tempLink) else: tempURL = tempLink links += [''.join(tempURL),] title = soup.title return (title, links, content) def webCapture(self): links = ['http://lvyou.baidu.com/search?word=%E8%A5%BF%E5%AE%89&type=1']#"http://xian.cncn.com/" while len(links) != 0: link = links[0] print('links array length:',len(links)) addlinks = self.handlePage(link) del links[0] if addlinks != None: links += addlinks def handlePage(self,link): (title, addlinks, content) = self.parsePage(link) if title == None and addlinks == None and content == None: return None else: #将页面内容写入文件 filename = self.writeToFile(link, content) #将url、标题、页面对应的文件名写入数据库中 temp = re.compile(r'<.*>') title = temp.sub('',str(title)) self.writeToDB(self.conn, link, '', filename) return addlinks crawler = Crawler() crawler.webCapture()
现在爬虫的带处理网页list有链接7W多条

之前最高有大到26W。不过爬到的质量太差,有很多被挂马的、广告的,还有很头疼的ajax的。哎,有点伤感。还是用框架吧。时间来不及精雕细琢一个自己的爬虫了。
——————————————
2013.08.01
今天换上scrapy。 方式参考其官网。
发现scrapy是不能自动解析ajax的。还需要一个模拟人类操作的东东。叫selenium RC。安装和测试的方式见 oscarxie的博客 http://www.cnblogs.com/oscarxie/archive/2008/07/20/1247004.html
【这边】还有老外 wynbennett 写的一段爬带有js代码网页的代码。
——————————————
2013.08.02
selenium RC python下的【手册】
_______________________
2013.8.3
今天的代码,完全跟以前不一样了。selenium真是一个深藏功与名的爬虫利器啊。
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Keys import hashlib import random class ScrapyPages: #网页内容保存目录 contentDir = "G:\\pages\\" #网页链接保存目录 atagsDir = "G:\\atags\\" #保存网页与文件名对应关系的文件 mappingFile = "G:\\mapping" #已处理的链接 handledLinks = [] #待处理的链接 unhandledLinks = [] #打开浏览器驱动,默认为火狐 def openPage(self, url): driver = webdriver.Firefox() driver.get(url) return driver #根据url获得文件名 def urlToFilename(self, url): m = hashlib.sha256() m.update(url.encode('utf-8')) filename = m.hexdigest() tfile = open(self.mappingFile, 'wb+') tfile.write(filename + ', ' + url + '\n') return filename #保存页面内容(仅文字) def savePageContent(self, filename, content): tfile= open(self.contentDir + filename,'wb') tfile.write(content) print('writing file-',filename) tfile.close() #处理页面中的a标签: #1、将a标签存入相应的文件中 #2、将其更新如links中 def handleAnchor(self, filename, anchors): hrefs = self.extractHrefFromAnchor(anchors) self.addHrefsToLinks(hrefs) self.saveAnchor(filename, hrefs) #将新提取到的链接(未出现过的)加入待处理链接中 def addHrefsToLinks(self, hrefs): for href in hrefs: if href in self.handledLinks or href in self.unhandledLinks: continue else: self.unhandledLinks += [href] #保存页面链接 def saveAnchor(self, filename, hrefs): afile= open(self.atagsDir + filename,'wb') afile.write('\n'.join(hrefs)) afile.close() #从a标签中提取链接 def extractHrefFromAnchor(self, anchors): hrefs = [] for anchor in anchors: try: href = anchor.get_attribute('href').encode('utf-8') if href in hrefs: continue else: hrefs += [href] except AttributeError: pass except selenium.common.exceptions.StaleElementReferenceException: pass return hrefs #爬取网页的入口函数 def scrapy(self, initURL): self.unhandledLinks += [initURL] while len(self.unhandledLinks) != 0: pos = random.randint(0,len(self.unhandledLinks) - 1) print('-pos-',pos) link = self.unhandledLinks[pos] del self.unhandledLinks[pos] driver = self.openPage(link) content = str(driver.find_element_by_xpath(".//html").text.encode('utf-8')) if len(content) > 2*1024: atags = driver.find_elements_by_tag_name("a") filename = self.urlToFilename(link) self.handleAnchor(filename, atags) self.savePageContent(filename,link + '\n' + content) driver.close() pageScrapy = ScrapyPages() pageScrapy.scrapy('http://lvyou.baidu.com/notes/36b629d671563fe1e8927d6a')
selenium爬出来的质量那是杠杠的。就是每次都要打开火狐代理会有些慢。没事,挂机吧!
除了改用selenium以外,在算法上还有2个改动。
1、以前每次取当次要处理的link时,都是从待选link list的第一个取出。这样很容易爬到什么登陆界面啊,广告链接啊之类的。后来想,如果从中间取会不会好一点?毕竟网页的中间一般都是有用的内容,可谁知,还有很多引用图片的网页,完全陷入图片的沼泽中了,姐要的是文字文字呀!后来一拍脑袋,哎,用随机不就好了
2、对爬到的网页的文字部分的长度做判断,小于2k的就直接舍弃了,毕竟真正有用的文章怎么会那么小。这样做有一大损失,就是网页直接的若链接被打断了。但也有一大好处,不会老是爬到广告页上了!不过若链接的损失也蛮痛惜的
等等!似乎可以限制路径的范围,在几个固定的网站里,这样就可以调低接受的字符长度从而获得站内的若链接了!!
回宿舍前再记录一下这灵机一动的改变:
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Keys import hashlib import random class ScrapyPages: #网页内容保存目录 contentDir = "G:\\pages\\" #网页链接保存目录 atagsDir = "G:\\atags\\" #保存网页与文件名对应关系的文件 mappingFile = "G:\\mapping" #已处理的链接 handledLinks = [] #待处理的链接 unhandledLinks = [] #打开浏览器驱动,默认为火狐 def openPage(self, url): driver = webdriver.Firefox() driver.get(url) return driver #根据url获得文件名 def urlToFilename(self, url): m = hashlib.sha256() m.update(url.encode('utf-8')) filename = m.hexdigest() tfile = open(self.mappingFile, 'wb+') tfile.write(filename + ', ' + url + '\n') return filename #保存页面内容(仅文字) def savePageContent(self, filename, content): tfile= open(self.contentDir + filename,'wb') tfile.write(content) print('writing file-',filename) tfile.close() #处理页面中的a标签: #1、将a标签存入相应的文件中 #2、将其更新如links中 def handleAnchor(self, filename, anchors): hrefs = self.extractHrefFromAnchor(anchors) self.addHrefsToLinks(hrefs) self.saveAnchor(filename, hrefs) #将新提取到的链接(未出现过的)加入待处理链接中 def addHrefsToLinks(self, hrefs): for href in hrefs: if href in self.handledLinks or href in self.unhandledLinks: continue else: if href.find('http://lvyou.baidu.com') != -1: self.unhandledLinks += [href] #保存页面链接 def saveAnchor(self, filename, hrefs): afile= open(self.atagsDir + filename,'wb') afile.write('\n'.join(hrefs)) afile.close() #从a标签中提取链接 def extractHrefFromAnchor(self, anchors): hrefs = [] for anchor in anchors: try: href = anchor.get_attribute('href').encode('utf-8') if href in hrefs: continue else: hrefs += [href] except AttributeError: pass except selenium.common.exceptions.StaleElementReferenceException: pass return hrefs #爬取网页的入口函数 def scrapy(self, initURL): self.unhandledLinks += [initURL] while len(self.unhandledLinks) != 0: pos = random.randint(0,len(self.unhandledLinks) - 1) print('-pos-',pos) link = self.unhandledLinks[pos] del self.unhandledLinks[pos] driver = self.openPage(link) content = str(driver.find_element_by_xpath(".//html").text.encode('utf-8')) if len(content) > 512: atags = driver.find_elements_by_tag_name("a") filename = self.urlToFilename(link) self.handleAnchor(filename, atags) self.savePageContent(filename,link + '\n' + content) driver.close() pageScrapy = ScrapyPages() pageScrapy.scrapy('http://lvyou.baidu.com/xian')
数据是从百度旅游爬的,只是做毕设,希望百度不要把我ip加入黑名单…… 23:15
__________________________
2013.8.4
昨晚虽然没有设定最长等待时间,导致在挂机的时候被一个图片页面卡住了,不过还是收集到了一些网页。今晚改进后,再继续爬好了。
今天进入分词阶段。在网上搜了一下python下面的分词工具,一个叫“结巴”的映入眼帘,一看是挂着github上的就很有好感,嘿嘿。
先随便拿一个昨天爬下来的网页试试。
文件1.txt
http://lvyou.baidu.com/notes/2b55cfda9f42fb3bf11afb27 登录 | 注册 目的地|游记 百度一下 首页 目的地指南 攻略下载 游记 画册 首页 >游记攻略 >长沙凤凰张家界9日之旅 长沙凤凰张家界9日之旅 满园含香 2013年07月出发 从上海到 张家界 9天 人均:1000-3000(元) 分享到: 回 复 3 | 浏 览 47 0 0 发表游记攻略 互动交流 只看游记 游记大图 选中文字,就可以引用到回复中,试试吧:) 满园含香 前言 长沙 - 凤凰 - 张家界 - 天门山 - 猛洞河漂流 - 芙蓉镇之旅 第一天:张家界游记之第一站--长沙完美终结篇 长沙 - 岳麓书院 - 橘子洲 第二天:张家界游记第二站---凤凰古城之浪漫魅惑篇 凤凰 - 虹桥 - 杨家宅 - 陈斗南故居 - 沱江 第三天:张家界游记之第三站--作别凤凰挺进张家界篇 凤凰沱江 - 张家界大成山水 第四天:张家界游记之第四天--金鞭溪边画中游篇 张家界国家森林公园 - 金鞭溪 第五天: 张家界游记之第五天--天子山景区唯美篇 老屋场 - 神兵聚会 - 天子山景区'贺龙公园` - 十里画廊 - 黄龙洞 - 宝峰湖 选中文字加入计划 随时收集有效信息 只看楼主 | 回复 关注 满园含香 发表于2013-08-04 02:37 前言 长沙- 凤凰- 张家界- 天门山- 猛洞河漂流- 芙蓉镇之旅 1楼 7/13.1)上航FM9395 上海虹桥9:05起飞,10:45到达长沙 到达长沙后在大厅集合,一共8人,先到酒店登记入住,放行李。 入住锦江之星(长沙火车站店)地址:长沙市芙蓉区车站北路46号(近长沙火车站) 酒店电话:0731-88316888. 阿波罗广场是大巴去凤凰的集合点,我们住的酒店离阿波罗广场非常近,步行100米左右。 2) 坡子街----火宫殿,品味长沙小吃 1-2.长沙火车站到坡子街:可以坐旅3路(至坡子街站下),368路(至解放西路口站下步行300M左右到坡子街),112路(至解放西路口站下步行260M左右到坡子街)。约30-40分钟。 长沙火车站到南门口:可以乘坐202路、108路在南门口下。约30分钟。 3.这两个地方距离不远,都离黄兴步行街很近。123路就3站,10分钟左右。建议天气不晒可以选择步行。 实际上我们后来没有去坡子街,看完岳麓书院,橘子洲头,就顺路找了一家在湘江边的饭店,一边欣赏烟花一边吃晚饭,倒也不错。 3) 中国四大名亭之一—爱晚亭,远眺指点江山的橘子洲头,岳麓书院 4) 游轮畅游湘江。(周六晚湘江有烟火) PS: 提前定第二天到凤凰的车票 ,我们去凤凰的票是在网上订的,只是定个位子,上车再付钱,感觉比较放心。导游提前一天电话通知我集合时间及地点。 7/14 1)一早乘旅游大巴到凤凰,估计5.5小时。我们是早上7点半发车,下午2点才到凤凰。晚上入住凤凰江天旅游度假村,酒店地址:沱江镇虹桥路2号(古城内,近虹桥)也是在艺龙上定的。 我们入住后发现这家酒店位置非常好,就在虹桥头,属于闹中取静的位置,第二天导游集合的地点就在我们这家酒店,说明咱选的位置好呀。 2)晚饭后,欣赏凤凰古城的夜景 7/15 1) 清晨的凤凰一定不能错过,在凤凰吃过中饭后,采购食物,出发到张家界。 2)在凤凰县城北汽车站乘车,大约4小时,到张家界。实际上我们是早8点半发车,下午2点半才到张家界。一路上颠簸不停,没有走高速,我还晕车,非常的难受。 这里说明一下,酒店可以预定凤凰到张家界的长途车票,这样可以保证第二天到了汽车站就走,不会落空。票价70元。 3)晚上入住张家界大成山水国际大酒店,酒店地址:张家界市大庸西路,酒店电话:0744-8889999。大成山水是5星级酒店,可以在艺龙,携程上预定酒店的限时限购优惠,我们酒店在7月的旺季,才419元一间,可谓超值。当然要早下手。 7/16 1)在酒店享用一顿丰盛的早餐,和张家界客栈老板碰头,开始4天的张家界之旅, 2)具体行程安排有张老板制定,张老板的电话是150-744-23210挺实诚的土家汉子 一早带我们去张家界森林公园,沿着金鞭溪一直走,走到白龙天梯,上袁家界,看哈利路亚山,之后乘环保车到天子山丁香榕,他的客栈就在那里,晚上我们入住他的客栈。民居,挺有家的感觉,坐在院落里吃西瓜,吃晚饭,用WIFI看快本,还是很不错的。山上的居住条件一般,大家不要想象的有多好,只是住一晚而已。 7/17 早上5点我们到老屋场看日出,神兵点将,空中田园,我们给了他包车费200元,貌似他也没赚,直接给了包车的司机。一大早陪我们看日出,辛苦了。 在他家吃过早饭后,我们乘环保车到贺龙公园。游览天子山的十里画廊,下午去了黄龙洞,宝峰湖,这一天的行程可谓安排的紧凑呀。晚上回到张家界市区,住在天门山索道对面的纬地酒店,挂4星,是张老板定的房间。 7/18 因为酒店就在天门山景区的对面,所以不用赶早,吃过酒店的自助早餐之后再上山。,天门山门票包含大索道的费用,它这个索道有上站,中站,下站。张导建议我们先乘索道到上站,看玻璃栈道,之后乘上站索道下行至中站,乘景区环保车去天门洞,爬999级台阶上到天门洞,之后乘环保车到中站,乘索道到下站。我们因为有他领路没走冤枉路。在景区碰到一对自助游的夫妻俩,多买了小索道的往返票,还走了好多路。晚上接着住在纬地酒店。 7/19 一早张导包车带我们去猛洞河漂流,中午在芙蓉镇吃饭,顺便到芙蓉镇看看。本来不报太大希望,去了以后才发现这个景点还是很不错的。大人80元一张,小孩不要钱。 到这里张导就完成了历史使命了,他本来送我们到火车站,一来我们的火车是第二天下午13点钟的,再一个张家界的出租车很便宜也好叫,所以我们就不麻烦他了,让他早点回家见他的小女儿吧。 说明一下,我们和他谈的价钱是1人1600元,4天3晚的行程,包吃包住包车包门票,小孩的门票也是退还我们的。所以我们8个人实际支出11472元。之前看网上都说导游会把我们散团转卖给其他的团,还好,我们张导一直陪着我们, 晚上入住张家界逸尘国际大酒店。酒店地址:永定区滨河路188-186号。酒店电话:0744-8222222. 这家酒店是来之前我在艺龙上定的,4星,319元一间。 7/20 睡到自然醒,享受酒店的丰盛早餐,外出采购火车上的食物,下午13点乘火车到上海。我们住的酒店附近有一家卖进口食品的超市,东西都比上海便宜,品质也是一样一样的。 7/21 中午时分抵达上海南站,回到温馨的家,结束张家界和凤凰之旅。 以上就是我们长沙凤凰张家界一行的住宿旅游行程单,我负责订酒店订机票订车票订导游,总之一切和钱打交道的事;含烟负责花枝招展,一切小资的事情,我们行程游记也是她一路记载一路上传,她写得那么好,我就不用班门弄斧了。 看下段游记 | 只看楼主 | 回复 关注 0 0 共10篇帖子 | 回复(3) | 浏览(47) 分享到: 回复 您尚未登录哦,请登录后回复。 登录 | 注册 发布 评论 0 0 分享到 快速导航 相关目的地 张家界 相关游记 烟雨凤凰——遇见,就是一生的眷恋(&张家界,黄龙洞,长沙) 78113 pichai_305 2012至2013两个2B青年的凤凰、张家界时光记忆 31123 爱旅行的y小姐 【湖了个南】张家界-凤凰-长沙漫画游记~重磅回归,勿容错过··· 40832 貓火火 如何写出精华游记 关注微博 下载APP ©2013 Baidu 使用百度前必读 百度旅游用户协议 联系我们 【免费】台湾9日自由行,美景美食美人,应有尽有
借助“结巴”写的分词测试代码
# -*- coding: utf-8 -*- import jieba import jieba.analyse from collections import Counter jieba.load_userdict('dict.txt') handler = open('1','r') content = handler.read() handler.close() seg_list = jieba.cut(content) after = '\n'.join(seg_list).encode('utf-8') wfile = open('2','wb') wfile.write(after) wfile.close() tags = jieba.analyse.extract_tags(content,100) counts = [] countTags = '' splitAfter = after.split('\n') tfile = open('count','wb+') for tag in tags: words = tag.encode('utf-8') count = splitAfter.count(words) tfile.write('{},{}\n'.format(words,count)) tfile.close()
使用的自定义词典 dict.txt
阿波罗广场 5 坡子街 5 黄兴步行街 3 橘子洲头 3 爱晚亭 1 城北汽车站 2 大成山水国际大酒店 2 大庸西路 2 哈利路亚山 3 宝峰湖 2 纬地酒店 2 天门山景区 2 逸尘国际大酒店 1
分词并排序后的结果 count.txt
张家界,30 凤凰,21 酒店,21 游记,16 我们,30 长沙,12 坡子街,6 索道,7 入住,7 天子山,4 环保车,4 长沙火车站,4 张导,4 2013,4 天门山,4 回复,6 行程,5 导游,4 虹桥,4 黄龙洞,3 艺龙,3 含香,3 10,3 芙蓉镇,4 晚上,6 之旅,4 金鞭,3 猛洞河,3 岳麓书院,3 登录,4 步行,4 第二天,5 满园,3 景区,4 攻略,3 包车,3 地址,4 下午,5 电话,5 漂流,3 老板,4 客栈,3 湘江,3 车票,3 百度,3 门票,3 早餐,3 旅游,4 目的地,3 可以,7 阿波罗广场,2 纬地酒店,2 点半,2 橘子洲头,2 日之旅,2 宝峰湖,2 口站,2 凤凰古城,2 上定,2 47,2 30,2 13,2 0744,2 一早,3 上海,5 分享,3 老屋,2 这家,3 楼主,2 发车,2 第五天,2 大巴,2 分钟,3 神兵,2 沱江,2 首页,2 第四天,2 贺龙,2 画廊,2 不错,3 门洞,2 选中,2 前言,2 吃晚饭,2 丰盛,2 之后,4 饭后,2 日出,2 西路,2 位置,3 十里,2 说明,3 预定,2 山水,2 大成,2 一路上,2 火车,2 小孩,2 欣赏,2 集合,2
在自己的问题域内定义个词典还是挺有用的,不然很多词会被拆掉。python的list.count()还是相当给力的。本来有个Counter函数应该更厉害的,不过试了一下,似乎是只能统计字母的个数,忧伤……

