

netty中的ByteBuf
网络数据的基本单位总是字节。Java NIO 提供了 ByteBuffer 作为它 的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。
Netty 的 ByteBuffer 替代品是 ByteBuf,一个强大的实现,既解决了 JDK API 的局限性, 又为网络应用程序的开发者提供了更好的 API。
一、ByteBuf 的 API
Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interface ByteBufHolder。
下面是一些 ByteBuf API 的优点:
- 它可以被用户自定义的缓冲区类型扩展;
- 通过内置的复合缓冲区类型实现了透明的零拷贝;
- 容量可以按需增长(类似于 JDK 的 StringBuilder);
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法;
- 读和写使用了不同的索引;
- 支持方法的链式调用;
- 支持引用计数;
- 支持池化。
其他类可用于管理 ByteBuf 实例的分配,以及执行各种针对于数据容器本身和它所持有的 数据的操作。我们将在仔细研究 ByteBuf 和 ByteBufHolder 时探讨这些特性。
二、ByteBuf 类——Netty 的数据容器
因为所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的。 Netty 的 ByteBuf 实现满足并超越了这些需求。让我们首先来看看它是如何通过使用不同的索引 来简化对它所包含的数据的访问的吧。
2.1、它是如何工作的
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。当你从 ByteBuf 读取时, 它的 readerIndex 将会被递增已经被读取的字节数。同样地,当你写入 ByteBuf 时,它的 writerIndex 也会被递增。图 5-1 展示了一个空 ByteBuf 的布局结构和状态。

要了解这些索引两两之间的关系,请考虑一下,如果打算读取字节直到 readerIndex 达到 和 writerIndex 同样的值时会发生什么。在那时,你将会到达“可以读取的”数据的末尾。就 如同试图读取超出数组末尾的数据一样,试图读取超出该点的数据将会触发一个 IndexOutOfBoundsException。
ByteBuf是一个抽象类,内部全部是抽象的函数接口,AbstractByteBuf这个抽象类基本实现了ByteBuf,下面我们通过分析AbstractByteBuf里面的实现来分析ByteBuf的工作原理。
ByteBuf都是基于字节序列的,类似于一个字节数组。在AbstractByteBuf里面定义了下面5个变量:
//源码 int readerIndex; //读索引 int writerIndex; //写索引 private int markedReaderIndex;//标记读索引 private int markedWriterIndex;//标记写索引 private int maxCapacity;//缓冲区的最大容量
ByteBuf 与JDK中的 ByteBuffer 的最大区别之一就是:
(1)netty的ByteBuf采用了读/写索引分离,一个初始化的ByteBuf的readerIndex和writerIndex都处于0位置。
(2)当读索引和写索引处于同一位置时,如果我们继续读取,就会抛出异常IndexOutOfBoundsException。
(3)对于ByteBuf的任何读写操作都会分别单独的维护读索引和写索引。maxCapacity最大容量默认的限制就是Integer.MAX_VALUE。
2.2、ByteBuf 的使用模式
JDK中的Buffer的类型 有heapBuffer和directBuffer两种类型,但是在netty中除了heap和direct类型外,还有composite Buffer(复合缓冲区类型)。
2.2.1、Heap Buffer 堆缓冲区
这是最常用的类型,ByteBuf将数据存储在JVM的堆空间,通过将数据存储在数组中实现的。
1)堆缓冲的优点是:由于数据存储在JVM的堆中可以快速创建和快速释放,并且提供了数组的直接快速访问的方法。
2)堆缓冲缺点是:每次读写数据都要先将数据拷贝到直接缓冲区再进行传递。
这种模式被称为支撑数组 (backing array),它能在没有使用池化的情况下提供快速的分配和释放。这种方式,如代码清单 5-1 所示,非常适合于有遗留的数据需要处理的情况。
ByteBuf heapBuf = ...; if (heapBuf.hasArray()) { byte[] array = heapBuf.array(); int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); int length = heapBuf.readableBytes(); handleArray(array, offset, length); }
2.2.2、Direct Buffer 直接缓冲区
NIO 在 JDK 1.4 中引入的 ByteBuffer 类允许 JVM 实现通过本地调用来分配内存。这主要是为了避免在每次调用本地 I/O 操作之前(或者之后)将缓冲区的内容复 制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)。
Direct Buffer在堆之外直接分配内存,直接缓冲区不会占用堆的容量。事实上,在通过套接字发送它之前,JVM将会在内部把你的缓冲 区复制到一个直接缓冲区中。所以如果使用直接缓冲区可以节约一次拷贝。
(1)Direct Buffer的优点是:在使用Socket传递数据时性能很好,由于数据直接在内存中,不存在从JVM拷贝数据到直接缓冲区的过程,性能好。
(2)缺点是:相对于基于堆的缓冲区,它们的分配和释放都较为昂贵。如果你 正在处理遗留代码,你也可能会遇到另外一个缺点:因为数据不是在堆上,所以你不得不进行一 次复制。
虽然netty的Direct Buffer有这个缺点,但是netty通过内存池来解决这个问题。直接缓冲池不支持数组访问数据,但可以通过间接的方式访问数据数组:
ByteBuf directBuf = ...; if (!directBuf.hasArray()) { int length = directBuf.readableBytes(); byte[] array = new byte[length]; directBuf.getBytes(directBuf.readerIndex(), array); handleArray(array, 0, length); }
不过对于一些IO通信线程中读写缓冲时建议使用DirectByteBuffer,因为这涉及到大量的IO数据读写。对于后端的业务消息的编解码模块使用HeapByteBuffer。
2.2.3、Composite Buffer 复合缓冲区
第三种也是最后一种模式使用的是复合缓冲区,它为多个 ByteBuf 提供一个聚合视图。在 这里你可以根据需要添加或者删除 ByteBuf 实例,这是一个 JDK 的 ByteBuffer 实现完全缺 失的特性。
Netty 通过一个 ByteBuf 子类——CompositeByteBuf——实现了这个模式,它提供了一 个将多个缓冲区表示为单个合并缓冲区的虚拟表示
Netty提供了Composite ByteBuf来处理复合缓冲区。例如:一条消息由Header和Body组成,将header和body组装成一条消息发送出去。下图显示了Composite ByteBuf组成header和body: 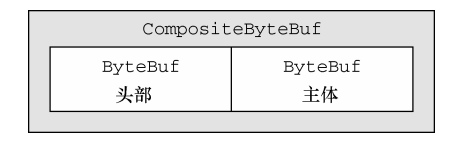
如果使用的是JDK的ByteBuffer就不能简单的实现,只能通过创建数组或则新的ByteBuffer,再将里面的内容复制到新的ByteBuffer中,下面给出了一个CompositeByteBuf的使用示例:
//组合缓冲区 CompositeByteBuf compBuf = Unpooled.compositeBuffer(); //堆缓冲区 ByteBuf heapBuf = Unpooled.buffer(8); //直接缓冲区 ByteBuf directBuf = Unpooled.directBuffer(16); //添加ByteBuf到CompositeByteBuf compBuf.addComponents(heapBuf, directBuf); //删除第一个ByteBuf compBuf.removeComponent(0); Iterator<ByteBuf> iter = compBuf.iterator(); while(iter.hasNext()){ System.out.println(iter.next().toString()); } //使用数组访问数据 if(!compBuf.hasArray()){ int len = compBuf.readableBytes(); byte[] arr = new byte[len]; compBuf.getBytes(0, arr); }
Netty使用了CompositeByteBuf来优化套接字的I/O操作,尽可能地消除了 由JDK的缓冲区实现所导致的性能以及内存使用率的惩罚。( 这尤其适用于 JDK 所使用的一种称为分散/收集 I/O(Scatter/Gather I/O)的技术,定义为“一种输入和 输出的方法,其中,单个系统调用从单个数据流写到一组缓冲区中,或者,从单个数据源读到一组缓冲 区中”。《Linux System Programming》,作者 Robert Love(O’Reilly, 2007)) 这种优化发生在Netty的核心代码中, 因此不会被暴露出来,但是你应该知道它所带来的影响。
2.3、ByteBuf 字节级操作
2.3.1、随机访问索引getByte(i),i是随机值
ByteBuf提供读/写索引,从0开始的索引,第一个字节索引是0,最后一个字节的索引是capacity-1,下面给出一个示例遍历ByteBuf的字节:
public static void main(String[] args) { //创建一个16字节的buffer,这里默认是创建heap buffer ByteBuf buf = Unpooled.buffer(16); //写数据到buffer for(int i=0; i<16; i++){ buf.writeByte(i+1); } //读数据 for(int i=0; i<buf.capacity(); i++){ System.out.print(buf.getByte(i)+", "); } } /***output: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, */
这里有一点需要注意的是:通过那些需要一个索引值参数的方法(getByte(i))之一索引访问byte时不会改变真实的读索引和写索引,我们可以通过ByteBuf的readerIndex()或则writerIndex()函数来分别推进读索引和写索引。
2.3.2、顺序访问索引
@Override public ByteBuf writeByte(int value) { ensureAccessible();//检验是否可以写入 ensureWritable0(1); _setByte(writerIndex++, value);//这里写索引自增了 return this; } @Override public byte readByte() { checkReadableBytes0(1); int i = readerIndex; byte b = _getByte(i); readerIndex = i + 1;//这里读索引自增了 return b; }
虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuffer 却只有一个索引,这 也就是为什么必须调用 flip()方法来在读模式和写模式之间进行切换的原因。
首先图 5-3 展示了 ByteBuf 是如何被它的两个索引划分成 3 个区域的
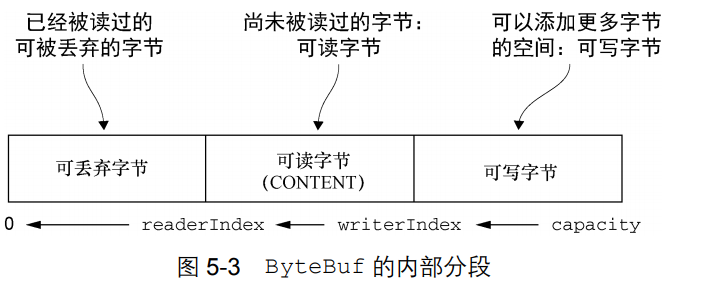
2.3.3、ByteBuf索引分区
2.3.3.1、可丢弃字节
对于已经读过的字节,我们需要回收,通过调用ByteBuf.discardReadBytes()来回收已经读取过的字节,discardReadBytes()将回收从索引0到readerIndex之间的字节。调用discardReadBytes()方法之后会变成如下图所示;

虽然你可能会倾向于频繁地调用 discardReadBytes()方法以确保可写分段的最大化,但是 请注意,很明显discardReadBytes()函数很可能会导致内存的复制,它需要移动ByteBuf中可读字节到开始位置,所以该操作会导致时间开销。说白了也就是时间换空间。
2.3.3.2、可读字节
ByteBuf 的可读字节分段存储了实际数据。新分配的、包装的或者复制的缓冲区的默认的 readerIndex 值为 0。任何名称以 read 或者 skip 开头的操作都将检索或者跳过位于当前 readerIndex 的数据,并且将它增加已读字节数。
当我们读取字节的时候,一般要先判断buffer中是否有字节可读,这时候可以调用isReadable()函数来判断:源码如下:
@Override public boolean isReadable() { return writerIndex > readerIndex; }
2.3.3.3、可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。新分配的缓冲区的 writerIndex 的默认值为 0。任何名称以 write 开头的操作都将从当前的 writerIndex 处 开始写数据,并将它增加已经写入的字节数。如果写操作的目标也是 ByteBuf,并且没有指定 源索引的值,则源缓冲区的 readerIndex 也同样会被增加相同的大小。
其实也就是判断 读索引是否小于写索引 来判断是否还可以读取字节。在判断是否可写时也是判断写索引是否小于最大容量来判断。
@Override public boolean isWritable() { return capacity() > writerIndex; }
清除缓冲区
清除ByteBuf来说,有两种形式,第一种是clear()函数:源码如下:
@Override
public ByteBuf clear() {
readerIndex = writerIndex = 0;
return this;
}- 1
- 2
- 3
- 4
- 5
很明显这种方式并没有真实的清除缓冲区中的数据,而只是把读/写索引值重新都置为0了,这与discardReadBytes()方法有很大的区别。
标记Mark和重置reset
从源码可知,每个ByteBuf有两个标注索引,
private int markedReaderIndex;//标记读索引
private int markedWriterIndex;//标记写索引- 1
- 2
可以通过重置方法返回上次标记的索引的位置。
衍生的缓冲区
调用duplicate()、slice()、slice(int index, int length)等方法可以创建一个现有缓冲区的视图(现有缓冲区与原有缓冲区是指向相同内存)。衍生的缓冲区有独立的readerIndex和writerIndex和标记索引。如果需要现有的缓冲区的全新副本,可以使用copy()获得。
4. 创建ByteBuf的方法
前面我们也讲过了,ByteBuf主要有三种类型,heap、direct和composite类型,下面介绍创建这三种Buffer的方法:
(1)通过ByteBufAllocator这个接口来创建ByteBuf,这个接口可以创建上面的三种Buffer,一般都是通过channel的alloc()接口获取。
(2)通过Unpooled类里面的静态方法,创建Buffer
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
ByteBuf heapBuf = Unpooled.buffer(8);
ByteBuf directBuf = Unpooled.directBuffer(16); - 1
- 2
- 3
还有一点就是,ByteBuf里面的数据都是保存在字节数组里面的:
byte[] array;- 1
5. ByteBuf与ByteBuffer的对比:
先来说说ByteBuffer的缺点:
(1)下面是NIO中ByteBuffer存储字节的字节数组的定义,我们可以知道ByteBuffer的字节数组是被定义成final的,也就是长度固定。一旦分配完成就不能扩容和收缩,灵活性低,而且当待存储的对象字节很大可能出现数组越界,用户使用起来稍不小心就可能出现异常。如果要避免越界,在存储之前就要只要需求字节大小,如果buffer的空间不够就创建一个更大的新的ByteBuffer,再将之前的Buffer中数据复制过去,这样的效率是奇低的。
final byte[] hb;// Non-null only for heap buffers- 1
(2)ByteBuffer只用了一个position指针来标识位置,读写模式切换时需要调用flip()函数和rewind()函数,使用起来需要非常小心,不然很容易出错误。
下面说说对应的ByteBuf的优点:
(1)ByteBuf是吸取ByteBuffer的缺点之后重新设计,存储字节的数组是动态的,最大是Integer.MAX_VALUE。这里的动态性存在write操作中,write时得知buffer不够时,会自动扩容。
(2) ByteBuf的读写索引分离,使用起来十分方便。此外ByteBuf还新增了很多方便实用的功能。
6. ByteBuf的引用计数类AbstractReferenceCountedByteBuf分析
看类名我们就可以知道,该类主要是对引用进行计数,有点类似于JVM中判断对象是否可回收的引用计数算法。这个类主要是根据ByteBuf的引用次数判断ByteBuf是否可被自动回收。下面来看看源码:
成员变量
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater;
//静态代码段初始化refCntUpdater
static {
AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> updater =
PlatformDependent.newAtomicIntegerFieldUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
if (updater == null) {
updater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
}
refCntUpdater = updater;
}
private volatile int refCnt = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
首先我们能看到refCntUpdater这个变量,这是一个原子变量类AtomicIntegerFieldUpdater,她是一个静态变量,而且是在static代码段里面实例化的,这说明这个类是单例的。这个类的主要作用是以原子的方式对成员变量进行更新操作以实现线程安全(这里线程安全的保证也就是CAS+volatile)。
然后是定义了refCnt变量,用于跟踪对象的引用次数,使用volatile修饰解决原子变量可视性问题。
对象引用计数器
那么,对对象的引用计数与释放是怎么实现的呢?核心就是两个函数:
//计数加1
retain();
//计数减一
release();- 1
- 2
- 3
- 4
- 5
下面分析这两个函数源码:
每调用一次retain()函数一次,引用计数器就会加一,由于可能存在多线程并发使用的情景,所以必须保证累加操作是线程安全的,那么是怎么保证的呢?我们来看一下源码:
public ByteBuf retain() {
return retain0(1);
}
public ByteBuf retain(int increment) {
return retain0(checkPositive(increment, "increment"));
}
/** 最后都是调用这个函数。
*/
private ByteBuf retain0(int increment) {
for (;;) {
int refCnt = this.refCnt;
final int nextCnt = refCnt + increment;
// Ensure we not resurrect (which means the refCnt was 0) and also that we encountered an overflow.
if (nextCnt <= increment) {
throw new IllegalReferenceCountException(refCnt, increment);
}
if (refCntUpdater.compareAndSet(this, refCnt, nextCnt)) {
break;
}
}
return this;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在retain0()函数中, 通过for(;;)来实现了自旋锁。通过自旋来对引用计数器refCnt执行加1操作。这里的加一操作是通过原子变量refCntUpdater的compareAndSet(this, refCnt, nextCnt)方法实现的,这个通过硬件级别的CAS保证了原子性,如果修改失败了就会不停的自旋,直到修改成功为止。
下面再看看释放的过程:release()函数:
private boolean release0(int decrement) {
for (;;) {
int refCnt = this.refCnt;
if (refCnt < decrement) {
throw new IllegalReferenceCountException(refCnt, -decrement);
}
if (refCntUpdater.compareAndSet(this, refCnt, refCnt - decrement)) {
if (refCnt == decrement) {
deallocate();
return true;
}
return false;
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里基本和retain()函数一样,也是通过自旋和CAS保证执行的正确的将计数器减一。这里需要注意的是当refCnt == decrement 也就是引用对象不可达时,就需要调用deallocate();方法来释放ByteBuf对象。
7. UnpooledHeapByteBuf源码分析
从类名就可以知道UnpooledHeapByteBuf 是基于堆内存的字节缓冲区,没有基于对象池实现,这意味着每次的IO读写都会创建一个UnpooledHeapByteBuf对象,会造成一定的性能影响,但是也不容易出现内存管理的问题。
成员变量
有三个成员变量,各自的含义见注释。
//缓冲区分配器,用于UnpooledHeapByteBuf的内存分配。在UnpooledHeapByteBuf构造器中实例化
private final ByteBufAllocator alloc;
//字节数组作为缓冲区
byte[] array;
//实现ByteBuf与NIO中ByteBuffer的转换
private ByteBuffer tmpNioBuf;- 1
- 2
- 3
- 4
- 5
- 6
动态扩展缓冲区
在说道AbstractByteBuf的时候,ByteBuf是可以自动扩展缓冲区大小的,这里我们分析一下在UnpooledHeapByteBuf中是怎么实现的。
public ByteBuf capacity(int newCapacity) {
ensureAccessible();
if (newCapacity < 0 || newCapacity > maxCapacity()) {
throw new IllegalArgumentException("newCapacity: " + newCapacity);
}
int oldCapacity = array.length;
if (newCapacity > oldCapacity) {
byte[] newArray = new byte[newCapacity];
System.arraycopy(array, 0, newArray, 0, array.length);
setArray(newArray);
} else if (newCapacity < oldCapacity) {
byte[] newArray = new byte[newCapacity];
int readerIndex = readerIndex();
if (readerIndex < newCapacity) {
int writerIndex = writerIndex();
if (writerIndex > newCapacity) {
writerIndex(writerIndex = newCapacity);
}
System.arraycopy(array, readerIndex, newArray, readerIndex, writerIndex - readerIndex);
} else {
setIndex(newCapacity, newCapacity);
}
setArray(newArray);
}
return this;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
里面的实现并不复杂:
(1)首先获取原本的容量oldCapacity;
(2)如果新需求容量大于oldCapacity,以新的容量newCapacity创建字节数组,将原来的字节数组内容通过调用System.arraycopy(array, 0, newArray, 0, array.length);复制过去,并将新的字节数组设为ByteBuf的字节数组。
(3)如果新需求容量小于oldCapacity就不需要动态扩展,但是需要截取出一段新缓冲区。
8. PooledDirectByteBuf 内存池原理分析
PooledDirectByteBuf基于内存池实现的,具体的内存池的实现原理,比较复杂,我没分析清楚,具体的只知道,内存池就是一片提前申请的内存,当需要ByteBuf的时候,就从内存池中申请一片内存,这样效率比较高。
PooledDirectByteBuf和UnPooledDirectByteBuf基本一样,唯一不同的就是内存分配策略。
创建字节缓冲区实例
由于PooledDirectByteBuf基于内存池实现的,所以不能通过new关键字直接实例化一个对象,而是直接从内存池中获取,然后设置引用计数器的值。看下源码:
static PooledDirectByteBuf newInstance(int maxCapacity) {
PooledDirectByteBuf buf = RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}- 1
- 2
- 3
- 4
- 5
通过RECYCLER对象的get()函数从内存池获取PooledDirectByteBuf对象。然后在buf.reuse(maxCapacity); 函数里面设置引用计数器为1。

