【大数据系列】大数据初识
一、 Hadoop的来源
Hadoop是Google的集群系统的开源实现。
--Google集群系统:GFS(Google File System)、MapReduce、BigTable.
--Hadoop主要由HDFS(Hadoop Distributed File System Hadoop分布式文件系统)、MadReduce和HBase组成。
Hadoop的初衷是为了解决Nutch的海量数据爬去和存储的需要。
Hadoop与于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
名称起源:Dug Cutting儿子的黄色大象玩具的名字。
二、 传统数据VS大数据
传统数据
大数据
数据量
GB->TB
TB->PB以上
速度
数据量稳定,增长不快
持续实时产生数据,年增长率超过60%
多样化
主要为结构化数据
半结构化,非结构化,多维结构
价值
统计和报表
数据挖掘和预测性分析
三、关系型数据库VS Hadoop
并行关系数据库
MPP or Hadoop
多个独立的关系型数据库服务器,访问共享的存储资源池
由大量独立的服务器通过网络互连形成集群,每个服务器带存储
优势:采用多个关系型数据库服务器,多个存储,与原有的架构相比,扩展了存储容量和计算能力
优势:计算与存储融合,支持横向扩展,更好的扩展性
劣势:1、计算与存储分离,数据访问存在竞争和带宽瓶颈
2、支持的惯性型数据库服务数量有限
3、只能向上扩展。不能横向扩展
劣势:解决数据冲突时需要节点间协作
适合复杂的需要事务处理的应用
适用范围:1、数据仓库和离线数据分析(MPP Hadoop/HBase)
2、大规模在线实时应用(单行事务处理能满足的场景)(HBase)
四、Hadoop下载
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0-src.tar.gz
五、Hadoop的子项目
Core:一套分布式文件系统以及支持Map-Reduce的计算框架
Avro:定义了一种用于支持大数据应用的数据格式,并为这种格式提供了不同的编程语言的支持
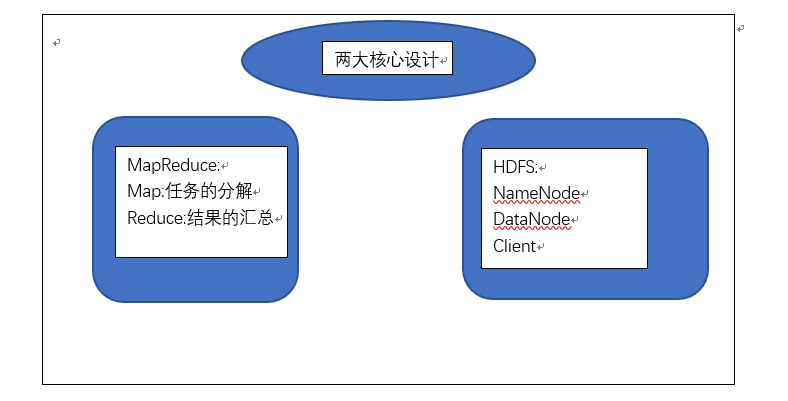
HDFS:Hadoop分布式文件系统
Map/Reduce:是一个使用简易的软件框架,基于它写出来的用用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集
ZooKeeper:是高可用的和可靠的分布式协同系统
Pig:建立于Hadoop Core之上为并行计算环境提供了一套数据工作流语言和执行框架
Hive:是为提供简单的数据操作二设计的下一代分布式数据仓库,他提供了简单的类似SQL的宇哥和HiveQL语言进行数据查询
HBase:建立于Hadoop Core之上提供一个可扩展的数据库系统
Flume:一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据。
Mahout:是一套具有可扩展能力的机器学习类库
Sqoop:是Apache下用于RDMB和HDFS互相导数据的工具。
六、使用Hadoop的公司
- 雅虎背景全球软件研发中心
- 中国移动研究院
- 英特尔研究院
- 金山软件
- 百度
- 腾讯
- 新浪
- 搜狐
- 淘宝
- IBM
- Amazon
- Yahoo!
七、hadoop角色划分
最基本的划分为Master和Slave,即主人与奴隶,第二,从HDFS的角度,将主机划分为NameNode和DataNode,(在分布式文件系统中,目录的管理很重要,管理目录相当于主人,二NameNode就是目录管理者);第三、从MapReduce的角度,将主机划分为JobTracker和TaskTracker(一个Job经常被划分为多个Task)。

