




朋友问到这样一个问题,需要实现如下功能
1、 打开一家航空运输公司的查询网页,如http://www.skyteamcargo.com/en/tracking/,该页面有两个文本框,供用户输入业务代码,如180-36898035,

2、 然后单击“Go”按钮后,下一个页面显示查询出来的结果
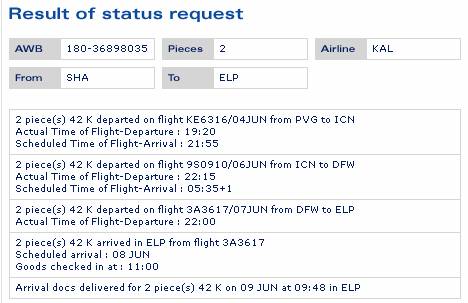
现在要求以上步骤都用程序自动实现,并把查询结果提取出来,以备后面进一步处理。
要完成这样的功能,首先要解决以下几个问题:
l 能够用程序在后台将数据Post到目标网页
l 能接收到对方返回的HTML结果页面
l 能够分析该页面,并将需要的结果提取出来
1. 用程序将指定数据Post到目标网页,并接收结果网页
我先用一个网络嗅探器来捕获用IE手工查询时浏览器和对方网页的HTTP协议交互过程,这里推荐用Ultra Network Sniffer,它有个Connection Monitor功能,可以监视某个程序的所有连接,这样就避免了其他无关数据包的干扰。如图

当在查询页面里输入数据后,点击“Go”按钮,嗅探器捕捉到的数据包如下图

请注意第三行,有一个Post数据包,这个就是我们需要的,
它所发送的网页地址为:http://www.skyteamcargo.com/en/tracking/tra_result.php
它所Post的数据为:awbpre=180&awbnum=36898035&x=17&y=9
很显然,180和36898035是可以替换的,而且要注意的是发送的目标网页不再是我们在浏览器里直接输入的初始页面http://www.skyteamcargo.com/en/tracking/了
下面我们用程序来发送这段数据,代码如下
public static string GetPage(string url, string postData,string encodeType,out string err)
{
Stream outstream = null;
Stream instream = null;
StreamReader sr = null;
HttpWebResponse response = null;
HttpWebRequest request = null;
Encoding encoding = Encoding.GetEncoding(encodeType);
// 准备请求...
try
{
// 设置参数
request = WebRequest.Create(url) as HttpWebRequest;
CookieContainer cookieContainer = new CookieContainer();
request.CookieContainer = cookieContainer;
request.AllowAutoRedirect = true;
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = data.Length;
outstream = request.GetRequestStream();
outstream.Write(data,0,data.Length);
outstream.Close();
response = request.GetResponse() as HttpWebResponse;
//直到request.GetResponse()程序才开始向目标网页发送Post请求
instream = response.GetResponseStream();
sr = new StreamReader( instream, encoding );
//返回结果网页(html)代码
string content = sr.ReadToEnd();
err = string.Empty;
return content;
}
catch(Exception ex)
{
err = ex.Message;
return string.Empty;
}
}
上面的代码很好懂,就不多费口水了,只谈几点要注意的问题:
如果你的程序需要保留SessionID,如ASP.NET中的那个SessionID。比如说自动登录后,可能还要后继的处理,则你需要在向下一个页面发送请求之前将前一个request返回的cookieContainer赋值给新的request,因为在cookieContainer中保留了一个叫做ASPNETSessionID的Cookie。
如果你Post的目标页面是ASP.NET页面,则一般在要提交的Form里都有一个__ViewState隐藏Input字段,一个服务器返回的网页源码的ViewState的例子如下,
<form name="Form1" method="post" action="login.aspx" id="Form1">
<input type="hidden" name="__VIEWSTATE"
value="dDwtMzg4MDA0NzA
<input name="UserName" type="text" id="UserName" />
<input name="Password" type="text" id="Password" />
<input type="submit" name="Submit" value="Button" id="Submit" />
</form>
然而在嗅探器中捕捉到的Post数据是:
__VIEWSTATE=dDwtMzg4MDA0NzA
请大家注意,这里ViewState的数据和前面的有点不一样,差别是其中的”+/=”等符号都被转成了%2B,%
当然,如果你只需要对页面做一次性访问,则大可不必理会这些,只用根据嗅探器捕获的结果来发送数据就可以了,但是如果你需要根据页面返回的ViewState值动态处理,则需要注意这一点。
2. 从HTML网页代码中提取信息
要从HTML网页中提取信息,首先得将网页代码格式化成XML形式的文件,然后可以用XPath很方便的提取出自己想要的信息,要将HTML格式化为XML形式,目前有几个选择
1、 Chris Lovett的SgmlReader:
http://www.gotdotnet.com/Community/UserSamples/Details.aspx?SampleGuid=b90fddce-e60d
2、 Simon Mourier的.NET Html Agility Pack
http://blogs.msdn.com/smourier/archive/2003/06/04/8265.aspx
我选择了SgmlReader, 通过实际使用,发现SgmlReader也不是尽善尽美,格式化出来的XML有时候嵌套关系会搞错,但即使这样,根据他格式化出来的文本,用来提取数据也足够了。
public static DataSet ParsePage(string pageContent, string xpath, out string err)
{
err = string.Empty;
string pageContent = this.tbHTML.Text;
StreamReader streamReader = null;
StringWriter strWriter = null;
SgmlReader sgmlReader = null;
XmlTextWriter xmlWriter = null;
try
{
sgmlReader = new SgmlReader();
sgmlReader.DocType = "HTML";
sgmlReader.InputStream = new StringReader(pageContent);
strWriter = new StringWriter();
xmlWriter = new XmlTextWriter(strWriter);
xmlWriter.Formatting = Formatting.Indented;
{
if (sgmlReader.NodeType != XmlNodeType.Whitespace)
{
xmlWriter.WriteNode(sgmlReader, true);
}
}
string wellFormedHTML = strWriter.ToString();
this.tbHTML.Text = wellFormedHTML;
string xpath = this.tbXPath.Text;
XPathDocument doc = new XPathDocument(new StringReader(wellFormedHTML));
XPathNavigator nav = doc.CreateNavigator();
XPathNodeIterator nodes = nav.Select(xpath);
while (nodes.MoveNext())
{
this.tbResult.Text += nodes.Current.Value+"\n";
}
catch (Exception exp)
{
string err = exp.Message;
MessageBox.Show("错误:"+err);
}
}
}
根据上面的代码来看,目前主要的问题就是要设置正确的XPath了,Code Project上有篇文章提供了一个简单的XPath查询工具,我对其作了一些修改,主要增加了在节点的正文中搜索某个字符串的功能,方便大家根据获得的HTML页面查询XPath

Debugging XPath Queries : http://www.codeproject.com/dotnet/xpath_visualizer.asp
例如下面是一个根据查询出来的结果格式化后的XML文本片断,该信息的XPath为
//div[@class=”content”]/DIV[@id=”tblwithbck”]/TABLE/TR/TD/TABLE/TR/TD/DIV[@class=”data”]
需要注意的是XPath中的每个路径是大小写敏感的,我就是一开始没注意这个问题,犯了些错误。
<div class="content">
<DIV id="tblwithbck">
<TABLE border="0" cellspacing="0" cellpadding="0" width="452">
<TR>
<TD bgcolor="#d5d5d5">
<TABLE border="0" cellspacing="1" cellpadding="0" width="452">
<TR>
<TD bgcolor="#ffffff">
<DIV class="data">
2 piece(s) 42 K departed on flight KE6316/04JUN from PVG to ICN
<BR />
Actual Time of Flight-Departure : 19:20
<BR />
Scheduled Time of Flight-Arrival : 21:55
</DIV>
</TD>
</TR>
<TR>
<TD bgcolor="#ffffff">
<DIV class="data">
2 piece(s) 42 K departed on flight 9S0910/06JUN from ICN to DFW
<BR />
Actual Time of Flight-Departure : 22:15
<BR />
Scheduled Time of Flight-Arrival : 05:35+1
</DIV>
</TD>
</TR>
<TR>
<TD bgcolor="#ffffff">
<DIV class="data">
2 piece(s) 42 K departed on flight
<BR />
Actual Time of Flight-Departure : 22:00
</DIV>
</TD>
</TR>
<TR>
<TD bgcolor="#ffffff">
<DIV class="data">
2 piece(s) 42 K arrived in ELP from flight
<BR />
Scheduled arrival : 08 JUN
<BR />
Goods checked in at : 11:00
</DIV>
</TD>
</TR>
<TR>
<TD bgcolor="#ffffff">
<DIV class="data">
Arrival docs delivered for 2 piece(s) 42 K on 09 JUN at 09:
</DIV>
</TD>
</TR>
</TABLE>
</TD>
</TR>
</TABLE>
</DIV>
</div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号