传统数据仓库项目的优化手段 (针对 Oracle+DataStage )
普通手段
分区,HASH-JOIN,数据仓库函数,物化视图,位图索引等等为大伙在数据仓库常用的技术,
而下面列举的tips为项目中常用的优化手段/技巧,绿色背景highlight的部分属于非常规手段,使用场景较为极端,需谨慎考量。
Oracle并行场景:
- SQL*Loader 的parallel参数
- 事务失败回滚的并行处理 FAST_START_PARALLEL_ROLLBACK参数
- expdp设置parallelism参数,设置多个datapump文件
-
大批量处理+并行处理(parallel),减少select次数,逻辑清晰,尽可能一次select……jion 之后再进行统一分析函数的处理,select/*+ PARALLEL(Table_Name,并行数) */统计函数 sum avgcase when then else endover(partition by order by )分析函数 lead/lag,rank,ratio_to_report,Period-over-period comparisons 等等...fromTable_Namegroup by
rollup ,cube 等等... - 创建索引、rebuild、设置并行参数(譬如大批量ETL全量时,drop索引,ETL之后再create)
- 收集统计信息的 degree参数
- 还有aleter session enable parallel dml;
insert /*+ append parallel(Table_I,并行数) */
into Table_I nologging
select /*+ PARALLEL(A,并行数) PARALLEL(B,并行数) PARALLEL(C,并行数) */
……
nologging 在DML时往往很有用
Insert、update
Insert ,update,delete 场景
1、当然最快的仍然是create table NEW_TAB as select * from OLD_TAB
1、当然最快的仍然是create table NEW_TAB as select * from OLD_TAB
2、delete的时候如果数据量过大,可以权衡考虑全量导出建立:
CREATE TABLE NEW_TAB NOLOGGING PARALLEL as select * from OLD_TAB where 条件<>要delete的数据,再truncate原表,rename重命名新表。
update也可以同理,把update的思路写到select里面再truncate原表,rename新表。
MERGE:(同样可以使用并行,nologging)
减少扫描表的次数,替代insert then update语句
例如:每月计算生产库里的会计科目成本,放入数据仓库的事实表,但有少部分的冲销凭证会影响近几个月的操作。原本的total delete+insert,或是insert新数据+时间范围内update的操作,换为merge where 时间覆盖可能发生冲销的范围即可。
参数:
1、
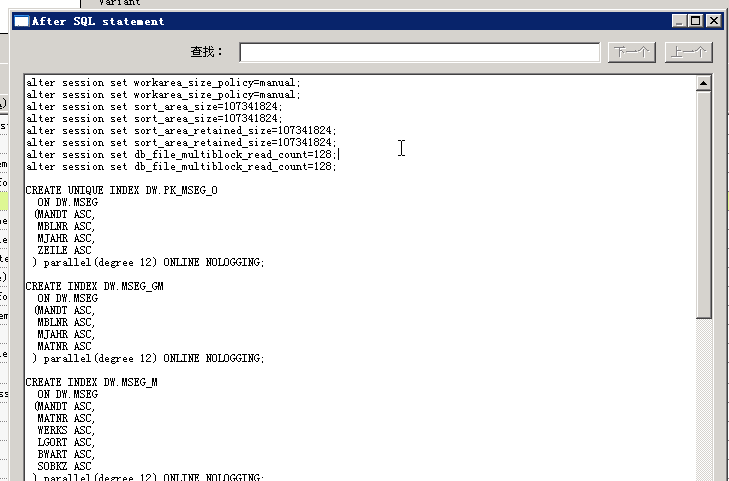
alter session set workarea_size_policy=manual;
alter session set sort_area_size=107341824;
alter session set sort_area_retained_size=107341824;
alter session set db_file_multiblock_read_count=128;
在并行dml、并行select的ETL JOB里可以添加如上参数,10g版本似乎要重复两次才可以生效。
db_file_multiblock_read_count配合32k、16k的大block表空间使用,针对传统SATA盘,FC盘有效,增加单次IO的收益。
同理,有时候反范式冗余多维度与事实表到一块,组成长表,db_file_multiblock_read_count+32K/16K大block的性能也很好,但数据的适用场景就减少了,多数用于临时主题分析,数据集市。
2、
修改参数 _smm_auto_min_io_size 、smm_auto_max_io_size
增大每次hash join 的内存分配大小,提升group by性能,配合大PGA使用。
3、极端环境下(或测试环境,或是同步数据的非关键过渡库),打开参数 alter system set commit_write='batch,nowait'; (10gR2开始才有的特性)使得db在commit的时候,无需等待 LOG BUFFER写出到REDO LOGFILE,即返回commit完成,需要评估灾难时断电带来的风险,如有UPS可考虑打开。
注意:极端环境是指频繁的commit带来的log file sync等待成为瓶颈点的时候才考虑,才考虑!打开参数,多数情况下数据仓库不会有这个问题。
再极端一些,还可以把Online Redo文件加大至1~2G甚至更大,关闭归档,减少日志切换带来的等待,本条需要权衡场景,勿在生产环境随意使用。
外部表
- 不能dml,不能建索引,不支持分区
- 适合只使用一次,无需修改,方便load入数据,可以并行查询,可以Nested_Loop JOIN,可以HASH_JOIN
- 外部表结合MERGE的场景


系统级临时表(无DML锁,无REDO)
TRANSACTION级
SESSION级
direct path insert
物化视图:空间换取时间
表空间迁移
可以传输分区表的分区,属于物理文件级别的传输,不同于SQL级别,属于最高性能,适用于跨地区的分库、子库汇总至中心库的场景。
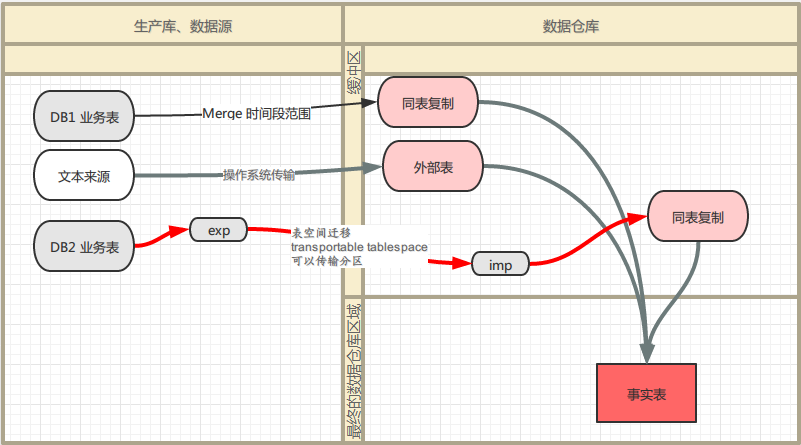
DataStage方面的处理
1、Bulk load方式

读端:设置 enable partitioned reads ,modulus方式分区读取integer(zeile)

写端:oracle connect 选择bulk load方式
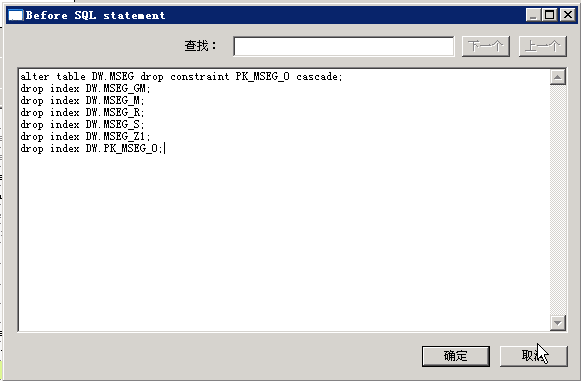
在bulk load写入前把所有索引,主键等drop掉。结束后再重建。
DataStage主机在多CPU的情况下,推荐设置多个并行node进行ETL作业,轻松将IO压到极限。
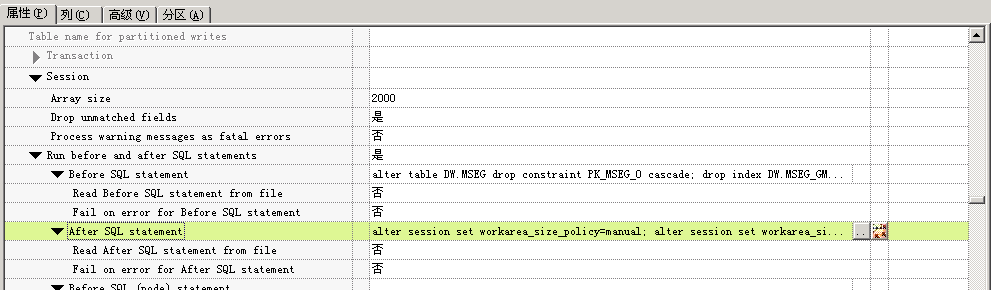
Before SQL Statement
After SQL Statement
Node的设置
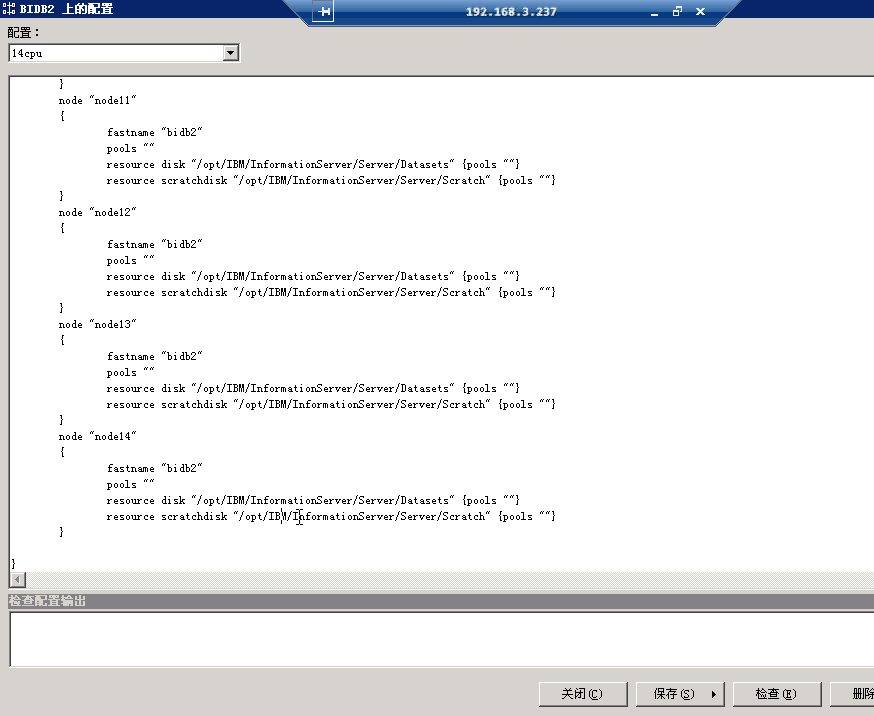
多Node并行的效果如下图:
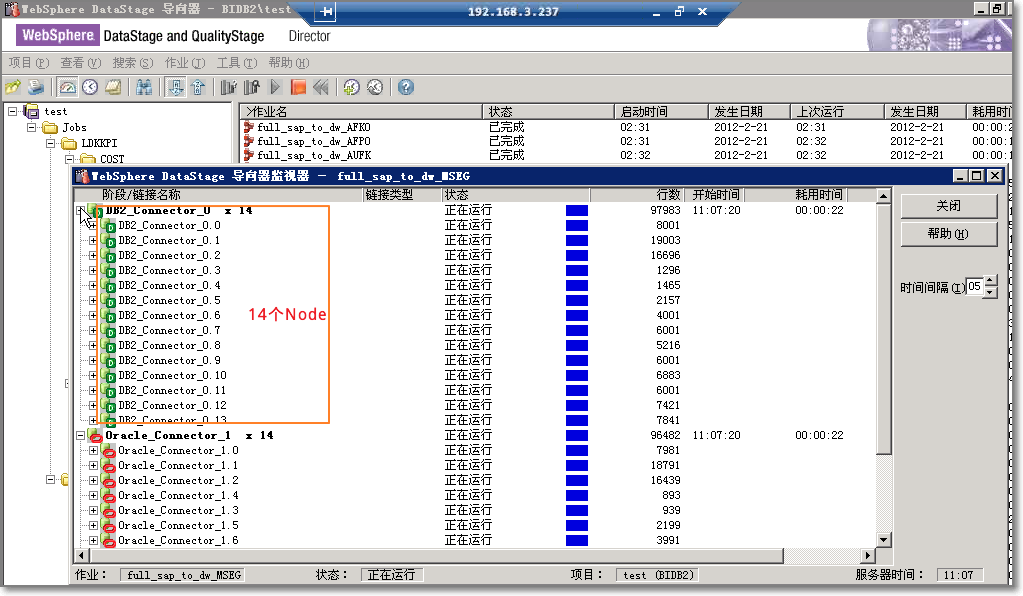

如果在瓶颈在Datastage的Node上
(可以测试下,node的文件建立在linux的tmpfs,即/dev/shm/tmp来提速,避免在ETL过程中数据经过datastage主机的磁盘,增加io瓶颈点,主机的内存要足够大,如64G,需测试!)
# mkdir /dev/shm/tmp
# chmod -R 777 /dev/shm/tmp
# mount --bind /dev/shm/tmp /tmp
像这样就可以直接用/tmp 来做node文件存放使用。
考虑限制用量的情况也可以用 # mount tmpfs /tmp -t tmpfs -o size=512m
限制/tmp挂载的tmpfs只能用512m
同理,大内存主机下Oracle的 temp表空间也可以往这里放,前提是temp表空间的使用情况已经平稳,DBA能预估使用的波动范围,并且关掉自动增长。需严格测试!

