
BP 算法之向后传导
0. 前言
上一篇文章我们从十分直观的角度理顺了 BP 算法的流程,总结起来,一次 BP 权值调整的过程是这样的:
-
输入向量从输入节点依次向后传播,我们可以计算出 the activation of all the hidden and output units
-
计算每个输出节点的残差
-
输出节点的残差依次向前传播,由此可以求得各个隐层的残差
-
由隐层的残差可以求得隐层左侧权重的更新
虽然我们理顺了过程,但是残留下来的问题太多了。比如,这里的 “残差” 究竟是什么,为什么由 “残差” 乘以前一节点的 activation 的值累加起来就可以求得权重的更新。这其中说白的就是 partial derivatives 的 chain rule 的应用,在数学推导上非常简单,在很多资料和博客里面都有推导和介绍。但是如果我们用另一种思维来图解向后传导的原理,也是非常意思和有启发性的事情。OK, 我们从最基础的 chain rule 开始说起。
1. Chain Rule
Chain rule (链式法则)是复合函数的求导法则,首先看一下最简单的形式:
若h(x)=f(g(x)),则h’(x)=f’(g(x))g’(x)
很简单哈,但是用一个流程图来表示,事情就开始变得有点意思了:
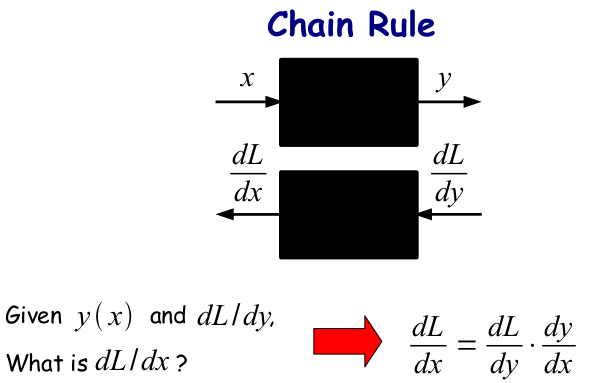
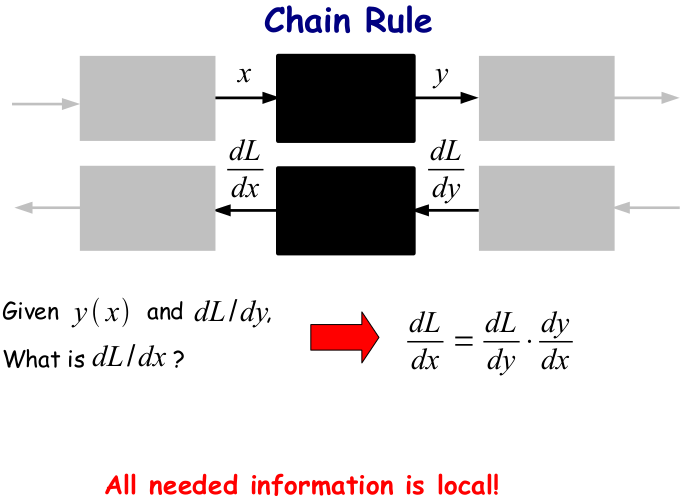
视野扩大一点,我们假设这两个变换只是一连串变换中的两个:
All needed information is local!!!
也就是说,要求某一个节点上的导数,你需要的信息仅仅是在你后面的那个节点的导数与节点本身函数变换的导数之间的乘积。
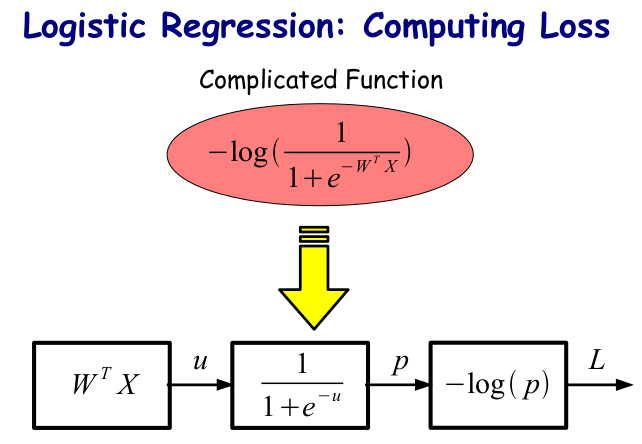
如果把这个思想放到 LR 中,LR 的 Loss function (label 为 1 ,损失函数为概率的负对数)不就是一个复合函数吗?表示成一个流程图就是:
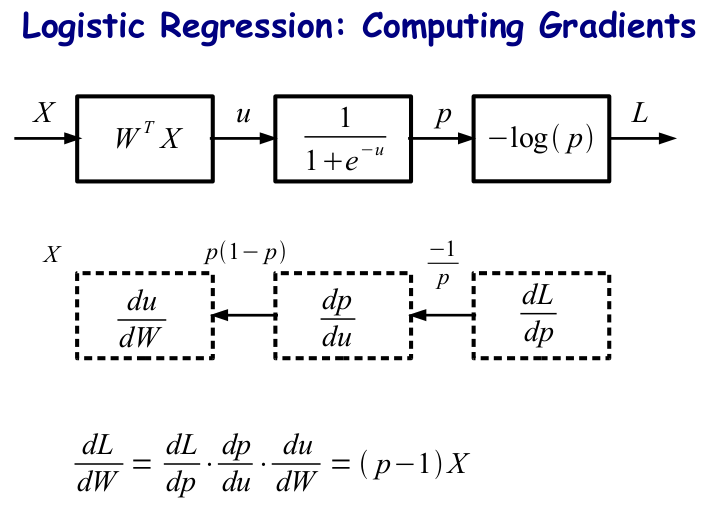
前面我们谈过 logistic regression 的问题,回想一下,我们无非就是想求得第一层与第二层之间的连线 (weights) 的偏导来进行梯度下降以训练模型的,试试用图来表示是个什么样子呢?
PS:可以看到,我们之前的 LR Model 只包含了前面两个框,输出概率 p 就 OK 了。但是在训练模型计算梯度的时候,我们并不关注输出的是什么,我们关注的是你的 Loss Function. 建立的是直接由输出到 Loss Function 的框架, 比我们之前的模型多一个计算损失函数的节点。
2. F-PROP / B-PROP
反向传导的思想可以让我们重新认识线性分类器 LMS (上篇文章有介绍) 和 LR 。但是 BP 算法和它们稍稍有点不同,不同点在于隐层的特性(隐层的值是一个变量, LR 的输入是一个常量)。下面画了一个图,这里我偷了一下懒,并没有非线性的 sigmoid function 单独分离开来,虚线所画的红色框框就是我们下面要讨论的东东:
注: hidden units (图中为 x) 是一个变量,连接的 weights (图中为 ) 也是一个变量
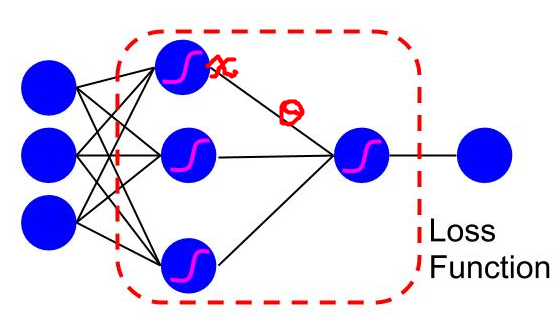
两个变量,对 x 和 theta 分别求偏导就 OK 了,求 x 的偏导的时候把 theta 当成一个常量,由于二者是相乘关系,得到的就是 theta, 对 theta 求偏导得到 x,这就解释了之前为什么要乘以权重或者 x 的问题。
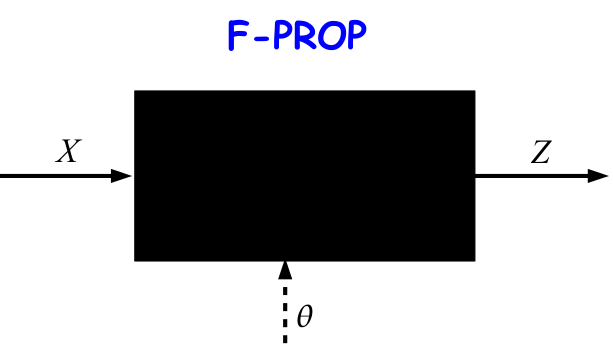
用模型来表示存在两个变量下求偏导的情况,在 F-PROP 阶段:
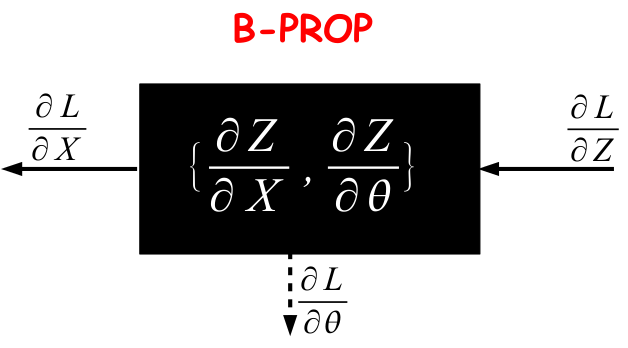
在 B-PROP 阶段:
3. 总结
在 BP 算法中,我们 backpropagation 的残差其实是对偏导或者导数的计算。当然,在数学上,你也可以对每个权重利用 chain rule 进行偏导计算,得到每个权重的 update, 但是这样显然有很多重复计算, 而 BP 在一定程度上解决了这个问题。归根结底, backpropagation technique provide a computationally efficient method for evaluating such derivatives.
参考资料:
[1]: NEURAL NETS FOR VISION CVPR 2012 Tutorial on Deep Learning
[2]: PRML chapter 05, Bishop[3]: BP 算法之一种直观的解释


