
Linux随笔-鸟哥Linux基础篇学习总结(全)
Linux随笔-鸟哥Linux基础篇学习总结(全)
修改Linux系统语系:LANG-en_US,如果我们想让系统默认的语系变成英文的话我们可以修改系统配置文件:/etc/sysconfig/i18n
[root@localhost ~]# cat /etc/sysconfig/i18n
LANG="en_US.UTF-8"
SYSFONT="latarcyrheb-sun16"
[root@localhost scripts]# ll
total 8
-rw-r--r-- 1 root root 1896 Jun 26 17:48 passwd
第一个字符代表档案是【目录、档案或者链接文件等】
-:档案
d:目录
l:链接
b:块设备,比如硬盘光驱等设备
c:字符设备,比如猫、鼠标、键盘等串口设备(一次性读取设备)
s:接口文件(sockets)
p:数据传输文件(pipe)
然后是文件的权限
权限对于文件的属性的意义:
r (read):可读取此一文件的实际内容,如读取文本文件的文字内容等;
w (write):可以编辑、新增或者是修改该文件的内容(但是不能删除该档案);
x (eXecute):该文件具有可以被系统执行的权限。
权限对于目录的意义:
r:表示具有读取该目录接口列表的权限,所以当你具有读取(r)一个目录的权限时,表示你可以查询该目录下的文件名数据。也就是说你可以通过ls命令列出目录里的内容。
w:表示你可以建立、删除、更名、移动该目录下的文件或目录。
x:表示你可以进入该目录,也就是通过cd命令可以切换到该目录。
注意:目录的r和x权限必须同时具备,否则可能会出现这种情况:你能进入到该目录,但是不能查看该目录里的内容;你能查看该目录的内容,却不能进入到该目录内。
Linux目录配置依据-FHS(filesystem Hierarchy Standard);目录树(directory tree):在Linux下,所有的文件和目录都是由跟目录开始的。根是所有目录和文件的源头,然后再一个个分支下来,有点像树枝状,因此,我们也称这种目录配置方式为:目录树。
目录树特征有:
1.目录树的起始点为根目录(/);
2.每一个目录不值能使用本段的partition的文件系统,也可以使用网络上的filesystem。比如可以利用NFS服务器挂载某特定目录;
3.每个档案在此目录树中的文件名(包含完整)
Linux特殊目录
.:代表当前目录
..:代表上层目录
-:代表前一个工作目录
~:代表account这个用户的家目录
cd:变换目录
pwd:显示当前目录(Print Working Directory)
-P:显示出真实路径,而非使用链接路径
mkdir:建立一个新的目录
-p:帮助你直接建立所需要的上层目录,递归建立。
-m:配置文件的权限,而不用依据umask:mkdir -m 755 test1.sh
rmdir:删除一个空的目录
$PATH:关于执行文件路径的变量:echo $PATH查看环境所定义的目录
PATH="$PATH":/root:将/root目录加入到执行文件搜索路径PATH中
ls:文件与目录的视察命令。
-a:查看所有文件
-d:仅列出目录本身,而不是列出目录内的档案数据。
-l:以长数据串输出,,包括文件的属性与权限等数据。
-i:列出inode号码。
-F:根据文件、目录等信息,给予附加数据结构。*代表可执行文件;/代表目录;=代表socket文件;|代表FIFO文件。
-S:以文件容量大小排序,而不是用默认的档案名排序。
-t:按照时间排序。
cp:复制文件或目录
-a:相当于-pdr
-i:若目标文件已经存在,在负载时会先询问动作是否进行
-p:连通档案的属性一起复制过去,而非使用默认属性(备份常用)
-r:递归复制,用于复制目录
-d:若来源文件为链接文件的属性,则复制被链接文件的属性,而非链接文件本身
-f:强制,若目标档案已经存在且无法开启,则移除后再尝试一次。
-u:若目标文件比源文件新才更新源文件
-s:复制成为符号链接文件。
rm:移除文件或目录
-f:强制,忽略不存在的文件,不会出现警告信息
-i:人机互动模式(默认别名加入了)
-r:递归删除,常用在目录的删除
我们在删除文件时文件名最好不要含有“-”,因为“-”后面接的是选项,当我们删除文件名为“-aa”时,我们可以用:rm -- -aa这样才行
mv:目录或文件的移动或更名
-f:强制,目标存在不会询问,而直接覆盖
-i:人机互动
-u:若源文件更新才会覆盖久的目标文件
basename:取得路径的文件名
dirname:取得路径的目录名
文件内容查阅:详细用法:man
cat:由第一行开始显示文件内容;
tac:从最后一行开始显示;
nl:显示的时候,顺道输出行号;
more:一页一页的显示档案内容;
less:与more类似,但是比more更好用,可以往前翻页;
head:只看头几行;
tail:只看尾巴几行;
od:以二进制的方式读取档案内容。
touch:修改文件时间或建立新的文件
mtime:当文件内容变更时,就会更新这个时间。
ctime:当文件状态改变时,就会更新这个时间。像权限属性被修改时。
atime:当文件的内容被读取时,就会更新这个时间,比如当你用cat /etc/passwd,此时就会更新该文件的atime了。
我们可以通过:ls -l --time=atime/ctime/mtime来查看相应的时间变化。而默认情况下ls显示出来的mtime时间。
-a:修改access time
-m:修改modification time
-d:后面可以接欲修订的日期而不用目前的时间。
umask:默认权限设定
关于umask的设定可以参考/etc/bashrc这个档案的内容。
除了rwx权限我,文件还有隐藏属性我们可以通过chattr来查看配置文件隐藏属性。
chattr
-a:当设定a之后,这个档案将只能增加数据,而不能删除也不能修改数据,只有root才能设定这个属性。
-c:当设定c之后,将会自动的将此文件压缩,在读取的时候将会自动解压缩。
-d:当dump程序被执行的时候,设定d属性将可使该文件(或目录)不会被dump备份。
-i:可以让一个文件无法删除、改名、设定软硬链接、写入,只有root才能设定这个属性。
-s:当这个文件被删除后,他将会被完全的移除出这个影片,无法利用工具恢复过来。
-u:这个与s属性相反,当使用u来配置文件档案时,如果被删除,则可以恢复回来。
lsattr:显示文件隐藏属性
-a:显示隐藏文件的属性
-d:如果接的是目录,仅列出目录本身的属性而非目录内的文件名
-R:联通子目录的数据也显示出来。
文件特殊权限:SUID(4)、SGID(2)、SBIT(1)
SUID:当s这个标志出现在文件拥有者的x权限上,例如我们提到的/usr/bin/passwd
意思是当执行这个文件的时候,你将以这个文件所有者身份去执行。
[root@localhost ~]# ll /usr/bin/passwd
-rwsr-xr-x 1 root root 27936 Aug 11 2010 /usr/bin/passwd
SUID的限制于作用:
1.SUID权限仅对二进制程序(binary program)有效
2.执行者对于该程序需要具有x的可执行权限
3.本权限仅在执行改程序的过程中有效(run-time)
4.执行者将具有该程序拥有者(owner)的权限
SGID:当s标识在群组的x位时称为SGID,例如文件:/usr/bin/locate
意思是当执行这个文件的时候,你将以这个文件所属组的身份去执行。
[root@localhost ~]# ll /usr/bin/locate
-rwx--s--x 1 root slocate 28184 Sep 3 2009 /usr/bin/locate
SGID对于文件的作用:
1.SGID对二进制程序有用
2.程序执行对于该程序来说,需具备x的权限
3.执行者在执行的过程中将会获得该程序群组的支持
SGID对于目录的作用:
1.用于若对于此目录具有r与x的权限时,该用户能够进入此目录
2.用户在目录下的有效群组(effective group)将会变成该目录的群组
3.用途:若用户在此目录下具有w的权限,则使用者所建立的新档案,该新档案的群组与此目录的劝阻相同。
SBIT:只针对目录有效,比如/tmp目录
[root@localhost ~]# ll -d /tmp
drwxrwxrwt 8 root root 4096 Jun 27 04:38 /tmp
SBIT对于目录的作用:
1.当用户对于此目录具有wx权限时,亦具有写入的权限
2.当用于在该目录下建立文件或目录时,仅有自己与root才有权力删除
file:查看文件类型
which:根据PATH环境变量定义的路径去搜寻文件,默认仅显示第一个搜索到的,-a选项则列出所有的。
where和locate:这两个都是根据系统预先建立好的数据库去搜索
where
-b:只找binary格式的文件
-m:只找说明文件manual路径下的文件
-s:只找source来源文件
-u:搜寻不在上述三个选项当中的其他特殊文件
locate
-i:忽略大小写的差异
-r:后面可接正则表达式的显示
我们可以通过手工更新数据库,默认情况下是每天更新一次,使用命令:updatedb,updatedb指令会去读取/etc/updatedb.conf这个配置文件的设定,然后再去硬盘里面进行搜寻文件名的动作,最后就更新整个数据库文件,此时updatedb会搜寻硬盘。
find
1.与实践有关选项:-atime、-ctime、-mtime
-mtime n:意义为在n天之前的整一天之内被更改过的内容;
-mtime +n:意义在n天之前不包含第n天被更改过内容的文件;
-mtime -n:意义在n天之内包含第n天被更改过内容的文件;
-mtime -newer file:file为一个存在的文件,列出比file还要新的文件;
n=0表示在过去24小时内有更改内容的文件
2.与使用者或组名有关的选项:
-uid n、-gid n、-user name、-group name、-nouser:搜索不属于该拥有者的人、-nongroup
3.与文件权限及名称有关的参数:
-name filename、-size [+-]SIZE:c代表byte,k代表kb,所以要找比50KB还要大的文件,就用:-sieze +50k
-type TYPE:代表搜寻文件的类型为TYPE,类型主要有:一般文件(f)、装备文件(b、c),目录(d)、连接文件(l)、socket(s)及FIFO(p)等属性。
-perm mode:搜寻文件权限刚好等于mode的档案,这个mode为类似chmod的属性值,举例来说,-rwsr-xr-x的属性为4744。
-perm +mode:搜寻档案权限【包含任一mode的权限】的文件
4.额外可进行的动作
-exec command:command为其他指令,-exec后面可再接额外的指令来处理搜寻结果
-print:将结果打印到屏幕上,这个动作是预设动作
比如:find的特殊功能就是能够进行额外的动作(action),我们通过如下的例子:
find / -perm + 7000 -exec ls -l () \;
该范例中特殊的地方有{}以及\;还有-exec这个关键词,这些意义为:
1.{}代表的是由find找到的内容,如上面所示,find的结果会被放置到{}位置中;
2.-exec一直到\;是关键词,代表find额外动作的开始(-exec)到结束(\;),在这中间的就是find指令内的额外动作。来本例中就是ls -l {}咯!
3.因为;bash环境下是有特殊意义的,因此利用反斜杠来跳脱。
磁盘基本知识
1.扇区(Sector)为最小的物理存储单元,每个扇区为512bytes;
2.将扇区组成一个圆,那就是磁柱(Cylinder),磁柱是分隔槽(partition)的最小单位;
3.第一个扇区最重要,里面有:(1)、主要开级区(Master boot record,MBR)及分割表(partition table)其中MBR占有446bytes,而partition table则占有64bytes。
磁盘分区即指定分隔槽的起始与结束磁柱,并且分隔槽信息记录在partition table中,最多只能记录四笔分隔槽的记录,这四笔记录我们称为主要(primary)或扩展(extended)分隔槽,其中扩展分隔槽还可以再分割出逻辑分隔槽(logical),并且只有主分区与逻辑分区能被格式化。每种操作系统所设定的文件属性/权限并不相同,为了存放这些档案所需要的数据,因此就需要将分隔槽进行格式化,以成为操作系统能够利用的文件系统格式(filesystem)。目前利用LVM与软件磁盘阵列(software raid),可以将一个分隔槽格式化为多个文件系统,所以目前我们在格式化时已经不再说针对partition来格式化了,通常我们可以称呼一个可被挂载的数据为一个文件系统而不是分隔槽。Linux会把权限与属性放置到inode中,一个文件占用一个inode,同时记录此档案的数据所在的block号码,实际数据存放到data block区块中,超级区块(superblock)会记录整个文件系统的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息。我们将inode/block这种资料存取的方式叫做索引式文件系统(indexed allocation)。而FAT这种格式的文件系统并没有inode存在,所以FAT没有办法将这个档案的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,必须要一个一个的将block读取出来后,才会知道下一个block在何处。我们常听到的碎片整理,这是因为档案写入的block太过于离散了,此时读取的效果变得很差,利用碎片整理将同一个档案所属的blocks汇整在一起。
ext2文件系统示意图:
我们可以看到在文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序,因此我们就可以将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的MBR,因此我们能够制作多重引导环境。
Data Block
Ext2文件系统所支持的block大小为1K、2K、4K。
Ext2 Block文件系统的限制:
1.blcok大小与数量在格式化完就不能够再改变了。
2.每个block内最多能够存放一个档案的数据。
3.如果档案大于block的大小,则一个档案会占用多个block数量。
4.若档案小于block,则该block的剩余容量就不能够再被使用了(磁盘空间就会被浪费掉)。
Inode table
记录档案的属性以及档案实际数据是放置在几号block内的,如下所示:
1.该档案的存取模式(rwe)
2.该档案的拥有者与所属组(owner/group)
3.该档案的用量
4.该档案建立或状态改变的时间(ctime)
5.最近一次的读取时间(atime)
6.最近修改的时间(mtime)
7.定义档案特性的flag:如SUID、SGID、SBIT
8.该档案真正内容的指向(pointer)
inode特点:
1.每个inode大小均固定为128bytes
2.每个档案都仅会占用一个inode
3.文件系统能够建立的档案数量与inode的数量有关
4.系统读取档案时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
indoe结构示意图: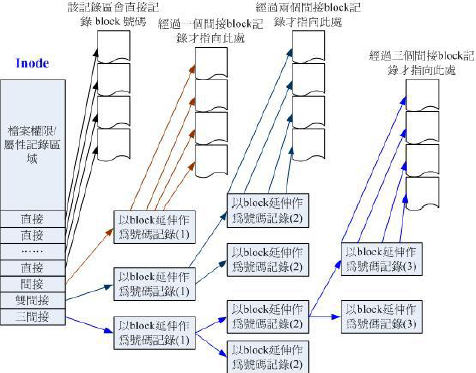
inode的大小为128字节,而其记录一个block要花掉4字节,假如我们一个档案有400MB且,每个block为4K,需要十万笔block号,吓!日狗!inode哪有这么多可记录的信息,因此系统很聪明的将inode记录block号码的区域定义为12个直接,一个间接,一个双间接与一个三间接。1个block能存储256个block
假设block大小为1K
12个直接指向:12*1K=12K
1个间接:256*1K=256K
1个双间接:256*256*1K=256²K
1个三间接:256*256*256*1K=256³K
这样总共大小为16GB。
Superblock
superblock是记录整个filesystem相关信息的地方,其记录的信息主要有:
1.block与inode的总量
2.未使用与已使用的inode/block数量
3.block与inode的大小(block为1,2,4K,inode为128bytes)
4.filesystem的挂载时间、最近一次写入数据的时间、最近一次检查磁盘(fsck)的时间等
5.一个valid bit数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1.
文件系统的基本信息都存放在这里,superblock的大小为1024字节,有关superblock的信息我们可以通过dumpe2fs指令来查看。此外每个block group可能含有superblock哦,事实除了第一个block group内会含有superblock之外,后续的block group'不一定含有superblock,若含有也仅做第一个block gruop的备份。
Filesystem Description
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock、bitmap、inodemap、data block)分别介于哪一个block号码之间。我们可以通过dumpe2fs来观察。
Block bitmap
透过block bitma我们可以知道哪些block是空的,如果你删除某些档案时,那么那些档案原本占用的block号码就得要释放出来,此时在block bitmap当中对应的block号码就被标志位“未使用中”。
Inode bitmap
功能与blcok类似,用来记录使用与未使用的inode号码。
dumpe2fs的使用示例:
[root@localhost ~]# dumpe2fs /dev/sda1
dumpe2fs 1.39 (29-May-2006)
Filesystem volume name: /boot //这个是文件系统的名称(Label)
Last mounted on: <not available>
Filesystem UUID: 1fec8e2d-7465-4b92-958a-262279faa304
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super
Default mount options: user_xattr acl //预设挂载的参数
Filesystem state: clean //这个文件系统是没问题的clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 26104 //inode的数量
Block count: 104388 //block的数量
Reserved block count: 5219
Free blocks: 88021 //block的剩余量
Free inodes: 26069 //inode的剩余量
First block: 1
Block size: 1024 //block的大小
Fragment size: 1024
Reserved GDT blocks: 256
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2008
Inode blocks per group: 251
Filesystem created: Fri Jun 26 17:05:36 2015
Last mount time: Mon Jun 29 01:57:43 2015
Last write time: Mon Jun 29 01:57:43 2015
Mount count: 7
Maximum mount count: -1
Last checked: Fri Jun 26 17:05:36 2015
Check interval: 0 (<none>)
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128 //每个inode的大小
Journal inode: 8
Default directory hash: tea
Directory Hash Seed: 6e0ec7b5-624c-4451-9421-59b08b8d0f64
Journal backup: inode blocks
Journal size: 4114k
Group 0: (Blocks 1-8192) //第一个data group内容,包含block的起始/结束号码
Primary superblock at 1, Group descriptors at 2-2 //超级区块在1号block中
Reserved GDT blocks at 3-258
Block bitmap at 259 (+258), Inode bitmap at 260 (+259)
Inode table at 261-511 (+260) //indoe table所在的block
1023 free blocks, 1990 free inodes, 2 directories //block的剩余量
Free blocks: 5984-7006 //剩余未使用的block
Free inodes: 19-2008 //剩余未使用的inode
Group 1: (Blocks 8193-16384)
Backup superblock at 8193, Group descriptors at 8194-8194
Reserved GDT blocks at 8195-8450
Block bitmap at 8451 (+258), Inode bitmap at 8452 (+259)
Inode table at 8453-8703 (+260)
2810 free blocks, 1991 free inodes, 1 directories
Free blocks: 13537-13824, 13833-14336, 14344-14848, 14856-15360, 15370-15872, 15880-16384
Free inodes: 2026-4016
Group 2: (Blocks 16385-24576)
Block bitmap at 16385 (+0), Inode bitmap at 16386 (+1)
Inode table at 16387-16637 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 16638-24576
Free inodes: 4017-6024
Group 3: (Blocks 24577-32768)
Backup superblock at 24577, Group descriptors at 24578-24578
Reserved GDT blocks at 24579-24834
Block bitmap at 24835 (+258), Inode bitmap at 24836 (+259)
Inode table at 24837-25087 (+260)
7681 free blocks, 2008 free inodes, 0 directories
Free blocks: 25088-32768
Free inodes: 6025-8032
Group 4: (Blocks 32769-40960)
Block bitmap at 32769 (+0), Inode bitmap at 32770 (+1)
Inode table at 32771-33021 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 33022-40960
Free inodes: 8033-10040
Group 5: (Blocks 40961-49152)
Backup superblock at 40961, Group descriptors at 40962-40962
Reserved GDT blocks at 40963-41218
Block bitmap at 41219 (+258), Inode bitmap at 41220 (+259)
Inode table at 41221-41471 (+260)
7681 free blocks, 2008 free inodes, 0 directories
Free blocks: 41472-49152
Free inodes: 10041-12048
Group 6: (Blocks 49153-57344)
Block bitmap at 49153 (+0), Inode bitmap at 49154 (+1)
Inode table at 49155-49405 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 49406-57344
Free inodes: 12049-14056
Group 7: (Blocks 57345-65536)
Backup superblock at 57345, Group descriptors at 57346-57346
Reserved GDT blocks at 57347-57602
Block bitmap at 57603 (+258), Inode bitmap at 57604 (+259)
Inode table at 57605-57855 (+260)
7681 free blocks, 2008 free inodes, 0 directories
Free blocks: 57856-65536
Free inodes: 14057-16064
Group 8: (Blocks 65537-73728)
Block bitmap at 65537 (+0), Inode bitmap at 65538 (+1)
Inode table at 65539-65789 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 65790-73728
Free inodes: 16065-18072
Group 9: (Blocks 73729-81920)
Backup superblock at 73729, Group descriptors at 73730-73730
Reserved GDT blocks at 73731-73986
Block bitmap at 73987 (+258), Inode bitmap at 73988 (+259)
Inode table at 73989-74239 (+260)
7681 free blocks, 2008 free inodes, 0 directories
Free blocks: 74240-81920
Free inodes: 18073-20080
Group 10: (Blocks 81921-90112)
Block bitmap at 81921 (+0), Inode bitmap at 81922 (+1)
Inode table at 81923-82173 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 82174-90112
Free inodes: 20081-22088
Group 11: (Blocks 90113-98304)
Block bitmap at 90113 (+0), Inode bitmap at 90114 (+1)
Inode table at 90115-90365 (+2)
7939 free blocks, 2008 free inodes, 0 directories
Free blocks: 90366-98304
Free inodes: 22089-24096
Group 12: (Blocks 98305-104387)
Block bitmap at 98305 (+0), Inode bitmap at 98306 (+1)
Inode table at 98307-98557 (+2)
5830 free blocks, 2008 free inodes, 0 directories
Free blocks: 98558-104387
Free inodes: 24097-26104
目录
我们在Linux下创建的目录时,ext2会分配一个inode与至少一块block给该目录。其中inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的文件名与该文件占用的inode号码数据。也就是说目录所占用的block内容在记录如下的信息:
以上信息可以通过ls -li来查看,我们可以看一下根目录下:
[root@localhost /]# ls -li
total 162
359041 drwxr-xr-x 2 root root 4096 Jun 26 18:46 bin
2 drwxr-xr-x 4 root root 1024 Jun 26 17:15 boot
1189 drwxr-xr-x 13 root root 4420 Jun 29 01:58 dev
261121 drwxr-xr-x 106 root root 12288 Jun 29 01:57 etc
2056321 drwxr-xr-x 3 root root 4096 Jun 26 17:37 home
522241 drwxr-xr-x 11 root root 4096 Jun 26 18:46 lib
1762561 drwxr-xr-x 8 root root 4096 Jun 26 18:45 lib64
11 drwx------ 2 root root 16384 Jun 26 17:05 lost+found
391681 drwxr-xr-x 2 root root 4096 Jun 29 01:57 media
14002 drwxr-xr-x 2 root root 0 Jun 29 01:58 misc
554881 drwxr-xr-x 2 root root 4096 May 11 2011 mnt
14006 drwxr-xr-x 2 root root 0 Jun 29 01:58 net
1925761 drwxr-xr-x 3 root root 4096 Jun 26 17:07 opt
1 dr-xr-xr-x 109 root root 0 Jun 29 01:56 proc
1272961 drwxr-x--- 14 root root 4096 Jun 27 03:29 root
1991041 drwxr-xr-x 2 root root 12288 Jun 26 18:46 sbin
722 drwxr-xr-x 4 root root 0 Jun 29 01:56 selinux
2513281 drwxr-xr-x 2 root root 4096 May 11 2011 srv
1 drwxr-xr-x 11 root root 0 Jun 29 01:56 sys
1403521 drwxr-xr-x 3 root root 4096 Jun 26 17:12 tftpboot
3394561 drwxrwxrwt 8 root root 4096 Jun 29 03:03 tmp
2350081 drwxr-xr-x 3 root root 4096 Jun 26 17:47 uestc
2807041 drwxr-xr-x 15 root root 4096 Jun 26 17:07 usr
2709121 drwxr-xr-x 25 root root 4096 Jun 26 17:20 var
在此强调目录的block内容存放的是文件或目录名与其对应的inode。
目录树读取
当我们要读取某个档案时,就务必会经过目录的inode与block,然后才能够找到那个待读取档案的inode号码,才能找到那个待读取档案的inode号码,最终才会读到正确的档案的block内的数据。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode号码(通常一个filesystem的最顶层inode号码会由2号开始),此时就能够得到根目录的inode内容,并依据该inode内的文件名数据,再一层一层的往下读到正确的档名。
[root@localhost /]# ls -ldi / /etc /etc/passwd
2 drwxr-xr-x 26 root root 4096 Jun 29 01:57 /
261121 drwxr-xr-x 106 root root 12288 Jun 29 01:57 /etc
263484 -rw-r--r-- 1 root root 1896 Jun 26 17:37 /etc/passwd
比如读取/etc/passwd这个文件,系统的读取顺序如下:
1./的inode:透过挂载点的信息找到/dev/sda1的inode号为2的根目录inode,且inode规范的权限与我们可以读取该block的内容(rx)
2./的block:经过上个步骤取得block号码,并找到该内容有etc/目录的inode号码(261121)
3.etc/的inode:读取261121号inode得知root具有r与x的权限,因此读取etc/的block内容
4.etc/的block:经过上个步骤取得block号码,并找到该内容有passwd文件的inode为263484
5.passwd的inode:读取263484得知root具有r的权限,因此可以读取passwd的block内容
6.passwd的block:将存放在block内容的数据读出来。
filesystem大小与磁盘读写效能
如果filesystem太大的话,那么当一个档案分别记录在这个文件系统是的最前面与最后面的block号码中。此时会造成硬盘的机械手臂移动幅度过大,也会造成数据读取效能的低落。而且读取头再搜索整个filesystem时,也会花费比较多的时间去搜寻,因此,partition的规划并不是越大越好,要针对主机用途来规划。另外如果写入的block分的很散的话,此时就会有所谓的档案数据离散的问题发生了,这样会发生读取效率低落的问题,解决办法是将该filesystem重新格式化,再将数据复制回去。
Ext2/Ext3档案的存取与日志式文件系统的功能
我们进行新增一个档案时,此时文件系统的行为是:
1.先确定用户对于欲新增档案的目录是否具有w与x的权限,若有的话才能新增。
2.根据inode bitmap找到没有使用的inode号码,并将新的档案的权限/属性写入。
3.根据block bitmap找到没有使用的block号码,并将实际的数据写入block中,且更新inode的block指向数据。
4.将刚刚写入的inode与block数据同步更新inode bitmap与block bitmap,并且更新superblock的内容。
一般来说,我们将inode table与data block称为数据存放区域,至于其他例如superblock、block bitmap与inode bitmap等区段就被成metadatea(中介资料),因为superblock、inode bitmap、block bitmap的数据时经常变动的,每次新增、移除、编辑时都有可能会影响到这三个部分的数据,因此才被称为中介数据。
数据的不一致(Inconsistent)状态:当你的档案在写入文件系统时,因为不知名原因导致系统中断(停电、系统的核心发生错误),写入的数据仅仅有inode table与data block,而最后的同步中介数据步骤没有完成,此时就会发生metadate的内容与实际数据存放的区产生不一致的情况。对于早期的Ext2文件系统,如果发生这个问题,那么在系统重启的时候,就是根据superblock中记录的valid bit(是否有挂载)与filesystem state(clean与否)来判断是否强制进行属于一致性的检查,我们可以通过手工调用e2fsck来进行手工检查。
日志式文件系统(Journaling filesystem)
为了避免上述提到的文件系统不一致的情况发生,Ext3引入了Journaling Filesystem,其大致过程为:
1.预备:当系统要写入一个档案时,会现在日志区块中记录某个档案准备要写入的信息。
2.实际写入:开始写入档案的权限与数据;开始更新metadate的数据。
3.结束:完成数据与metadata的更新后在日志记录区块中完成该档案的记录。
我们使用dumpe2fs查看时有关Journal的记录信息:
Journal inode: 8
Journal backup: inode blocks
Journal size: 4114k
透过inode 8号记录journal区块的block指向,而且具有4M的容量。
Linux文件系统的运作
Linux使用异步处理(asynchronously)的方式:当系统加载一个档案到内存后,如果该档案没有被更该过,那么在内存区段中该档案数据会被设定为干净(clean)。一旦内存中的数据被更改,此时内存中的数据被设定为脏(dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中,系统会不定时的将内存中设定为dirty的数据写回磁盘,以保持磁盘与内存数据的一致性。我们通过sync指令来手动写入。
挂载(Mount)
每个filesystem都有独立的inode/block/superblock等这个文件系统要能够链接到目录树才能被我们使用。注意:古仔点一定是目录,该目录为进入该文件系统的入口。
Linux VFS(Virtual Filesystem Switch)
我们知道Linux支持多种文件系统,那么Linux的核心是如何管理这些不同的文件系统的呢?其实,整个Linux都是透过一个叫做VFS的核心功能读取filesystem的。其VFS文件系统的示意图: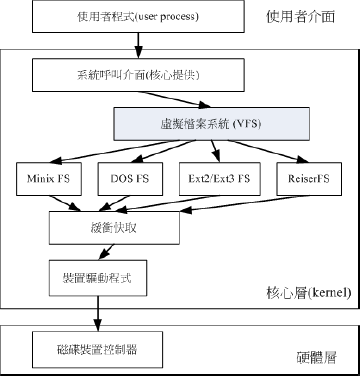
磁盘与目录的容量
df:列出文件系统的整体磁盘使用量
du:评估文件系统的磁盘使用量
df
-a:列出所有的文件系,包括系统特有的/proc等文件系统
-k -m -h则是以人们比较易读的方式进行显示
-H:以1000进制代替1024
-i:不用磁盘容量,而以inode的数量来显示
du
-a:勒出所有的档案与目录容量,默认仅统计目录底下的档案量而已。
-s:列出总容量,而不是列出每个个别的目录占用容量。
-S:不包括子目录下的总计。
du与df容量显示不一致
1.若有进程在占用某个文件,而且他进程把这个文件删掉,只会删除起在磁盘中的标记,而不会释放其占用的磁盘空间,直到访问该文件的进程退出为止;
2.df是从内核中获取磁盘占用情况数据的,读的是superblock的内容。而du是统计当前磁盘文件大小的结果,由于磁盘标记已被删掉,因此du不会计算上述被删除文件的空间,导致df与du的结果不一致。
我们的解决办法:
1.把占用文件的相关进程关闭
可以通过以下命令得到这些已被删除,但未释放空间的文件和进程信息:
lsof | grep deleted 找到这些进程后,在安全的情况下把其关闭,空间会自动释放
2.以清空的方式替代删除
归根到底,产生问题的额原因是:访问该文件的文件指针(句柄),在rm动作后,因为进程仍在访问,因此,仍处在文件里面(中间或结尾处)。所以,如果用清空的方式,把文件指针重置,该文件所占用的空间也会马上释放出来。
echo > /tmp/test.iso
ln实体链接与符号链接
我们知道:1.每个档案都会占用一个inode,档案内容由inode的记录来指向;
2.想要读取该档案,必须要经过目录记录的文件名来指向到正确的inode号码才能读取。
Hard Link(实体链接,硬式链接)
[root@localhost /]# ll -i /etc/passwd /uestc/passwd
263484 -rw-r--r-- 2 root root 1896 Jun 26 17:37 /etc/passwd
263484 -rw-r--r-- 2 root root 1896 Jun 26 17:37 /uestc/passwd
一般来说使用硬链接时,磁盘的空间与inode数目改变,并且硬链接有具有以下限制:
1.不能跨文件系统
2.不能够链接目录
不能夸文件系统还好理解,为什么不能够链接目录呢?这是因为如果使用hard link链接到目录时链接的数据需要连同被链接目录底下的所有数据都要建立链接,这样造成了环境相当大的复杂度。
下图是硬链接文件读取的示意图:

Symbolic Link(符号链接,亦成为快捷方式)
软链接就是建立在一个独立的档案,而这个档案会让数据读取指向他link的那个档案的档名,由于只是利用档案名来做为指向的动作,所有symbolic link的档案会打不开。
[root@localhost /]# ll -i /etc/shadow /uestc/shadow
263483 -r-------- 1 root root 1213 Jun 26 17:37 /etc/shadow
2350084 lrwxrwxrwx 1 root root 11 Jun 29 05:54 /uestc/shadow -> /etc/shadow
我们可以看出两个档案指向不同的inode号码,而且软链接的重要内容是它会写上目标档案的文件名。我们可以看出链接文件的大小为11字节,这是因为:”/etc/shadow“为11字节。
下图是符号链接档案读取示意图:
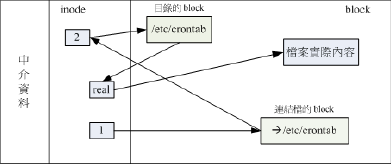
总结:当我们以hard link进行文件的链接时,可以发现文件的链接数增加1,如果建立目录其link数量会是多少?我们先看一下空目录都存在什么?
[root@localhost test]# ll -a
total 16
drwxr-xr-x 2 root root 4096 Jun 29 06:02 .
drwxr-xr-x 27 root root 4096 Jun 29 06:02 ..
我们发现有"." ".." "."与/test目录是一样的,而/test..则是上层目录,我们此时发现根目录的链接数多1
[root@localhost /]# ll -di
2 drwxr-xr-x 27 root root 4096 Jun 29 06:02 .
[root@localhost /]# rm -rf test
[root@localhost /]# ll -di
2 drwxr-xr-x 26 root root 4096 Jun 29 06:04 .
磁盘的分割、格式化、检验与挂载
当我们新增加一块硬盘时,我们需要采取以下措施才能够使用硬盘:
1.对磁盘进行分割,以建立可用的partiton。
2.对该partition进行格式化(format),以建立系统可用的filesystem。
3.若想要仔细一点,则可对刚刚建立好的filesystem记性检查
4.在Linux系统上,需要建立挂载点(亦即是目录),并将他挂载上来。
fdisk:磁盘分区
-l:输出后面接的装置所有的partition内容。
/dev/sda(没有数字):此时会进入分区模式 按下m后会看到底下这些指令的介绍
删除分割槽:
1.fdisk /dev/sda :先进入fdisk画面;
2.p:先看一下分隔槽的信息,假设要删除/dev/sda1
3.d:这个时候会要你选择一个partition,就先1
4.w(or)q:按w可存储到磁盘数据表中,并离开fdisk;当然,如果不限删除了按q就可以取消。
磁盘格式化:使用mkfs(make filesystem)
-t:可以接文件系统格式,比如ext3,ext2,vfat等
mkfs -t ext3 /dev/sda1
mkfs其实是个综合指令而已,事实上当我们使用mkfs -t ext3的时候,系统会呼叫mkfs.ext3这个指令来进行格式化的动作。
使用mkfs没有详细的指定文件系统的细部项目,因此系统会使用默认值来进行格式化,如果想设定系统的Label、block、inode等,我们就要用到mke2fs这个指令
mke2fs
-b:可以设定每个block的大小
-i:多少容量基于一个inode
-c:检查磁盘错入,仅下达一次-c,会进行快速检查测试,下达两次-c -c的话,会测试读写
-L:设定labe,这个label会很有用,e2label指令会介绍
-j:本来mke2fs是ext2,加上-j后,会主动加入journal而成为ext3.
磁盘检查:fsck,badblocks
磁盘的挂载与卸载
mount挂载
-a:依照配置文件/etc/fstab的素具将所有未挂载磁盘都挂载上来。
-l:只输入mount会显示目前挂载的信息,加上-l后可以出label名称。
-t:与mkfs的选型类似,可以加上文件系统种类来指定欲挂载的类型。
-n:默认情况下,系统会将实际挂载的情况写入/etc/mtab中,加上-n会可以不写入。
-L:除利用装置的文件名(/dev/sda1)之外,还可以利用文件系统的标头名称(label)来进行挂载。
-o:后面可以接一些挂载时额外加上的参数,比如说账号、密码、读写权限等。
比如:挂载光盘:mount -t iso9660 /dev/cdrom /media/cdrom
挂载优盘,我们先利用fdisk -l找出优盘文件名,然后在进行挂载
重新挂载:mount -o remount,rw,auto /,这个非常有用,尤其当你进入单用户模式时,你的根目录被系统挂载为只读,这时这个指令就非常重要了。
umount(将装置档案卸载)
-f:强制卸载!可用在类似NFS无法读到的情况下
-n:不更新/etc/mtab情况下卸载
可下载装置名或者挂载点都可以。
umount /dev/sda1
umount /media/cdrom
也可以Label来进行挂载:
首先找出/dev/sda1的label name:dumpe2fs -h /dev/sda1
然后:mount -L "/root" /mnt/sda1
mknod - make block or character special files
b:设定装置名称为一个周边存储装备档案,例如硬盘
c:设定装置名称称称为一个周边输入装备档案,例如鼠标/键盘等。
p:设定装置名称称为一个FIFO档案。
Major:主要装置代码;
Minor:次要装置代码;
开机挂载/etc/fstab 及 /etc/mtab
压缩
常见压缩文件扩展名:
*.Z 非常老,已经淘汰
*.gz
gzip不能保留源文件
-d:解压缩decompress
-t:检验压缩文件是否损坏test
-v:显示出原档案/压缩文件的压缩比等信息verbose
-r:递归压缩recursive
-#(-1--9):-1最快,压缩比低;-9最慢,但压缩比最好;预设值为-6
zcat a.log.gz用于查看压缩的文件
*.bz2
gzip2
-d:解压decompress
-k:保留源文件keep
-v:显示源文档/压缩文件的压缩比等信息
-#:同gzip一样,用于计算压缩比
*.tar
-c:创建打包档案,可以-v来观察打过过程中被打包的文件名
-t:查看打包档案的内容有哪些文件名。
-x:解打包
-j:透过bzip2的支持进行压缩/解压缩
-z:透过gzip的支持进行压缩/解压缩
-v:在压缩/解压缩的过程中,将正在处理的文件名显示出来。
-f:后面要立即接要被粗粒的文件名。建议-f单独写一个选项。
-C:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查 询:tar -jtv -f filename.tar.gz2
解压缩:tar -jxv -f filename.tar.bz2 -C:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。
*.tar.gz
*.tar.bz2
打包压缩:tar -zcvf filename.tar.gz /etc 或者 tar -cvfj filename.tar.bz2
解压缩解包:tar -zxv filename.tar.gz 或者 tar -xvj filename.tar.bz2
--exclude="file"的动作,我们可以将几个特殊的档案或目录移除在打包之列。
我们可以使用find找出比/etc/passwd更新的文件:find /etc -newer /etc/passwd
基本名称:tarfile(直接进行打包后的文件*.tar) tarball(进行打包和压缩后的文件*.tar.gz)
dump:完整备份工具
dump的功能颇强,他除了可以备份整个文件系统之外,还可以指定等级。假设你的/home是独立的一个文件系统,那你第一次进行dump后,再进行第二次dump时,你可以指定不同的备份等级,假如指定等级为1时,此时新备份的数据只会记录与第一次备份所有差异的档案而已。
dump运作的等级(Level)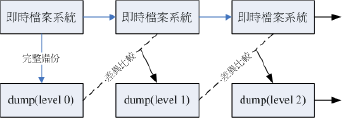
上面的实时文件系统是一直随着时间而变化的数据,而底下的方块则是dump备份起来的数据,第一次备份时使用的是level 0,这个等级也是完整的备份,等到第二次备份,此时第二次备份时,实时文件系统内的数据已经与level 0不一样了,而level1仅只是比较目前的文件系统与level0之间的差异后,备份有变化过的档案而已。至于level 2则是与level 1进行比较啦。
dump支持整个文件系统或者是单一个别目录,但是对于目录的支持是比较不足的,这也是dump的限制所在。简单的说,如果想要备份的数据如下,则有不同的限制情况:
-当待备份的资料为单一文件系统:
如果是单一文件系统(filesystem),那么该文件系统可以使用完整的dump功能,包括利用0-9的数个level来备份,同时,备份时可以使用挂载点或者是装置文件名(/dev/sda1之类的装置文件名)来进行备份。
-待备份的数据只是目录,并非单一文件系统:
例如你仅想备份/home/danbo/,但是该目录并非独立的文件系统时。此时备份就有限制。包括:
1.所有的备份数据都必须改目录(本例为:/home/danbo/)底下;
2.且仅能使用level0,亦即仅支持完整备份而已;
3.不支持-u选项,亦即无法建立/etc/dumpdates这个各别level备份的时间记录文件;
dump
-S:仅列出后面的待备份数据需要多少磁盘空间才能够备份完毕;
-u:将这次dump的时候基隆路到/etc/dumpdates档案中;
-v:将dump的档案过程显示出来;
-j:加入bzip2的支持!将数据进行压缩,默认bzip2压缩等级为2
-level:就是我们谈到的等级,从-0~-9共十个等级;
-f:有点类似tar,后面接产生的档案,亦可接例如:/dev/sda1装置文件名
-W:列出在/etc/fstab里面的具有dump设定的partition是否有备份过。
比如我们要对/boot文件夹做dump备份,则使用如下命令 dump -0u -f /uestc/boot.dump /boot
[root@localhost uestc]# cat /etc/dumpdates
/dev/sda1 0 Mon Jun 29 11:21:02 2015 -0400
加上-u的选项,因此/etc/dumpdates该档案的内容会被更新,注意,这个档案仅有在dump完整的文件系统时才有支持主动更新的功能。
1.此时我们在/boot文件下建立一个大约为10MB的档案:
dd if=/dev/zero of=/boot/testing.img bs=1M count=10
2.开始建立差异备份档,此时我们使用level1:
dump -1u -f /uestc/boot.dump.1 /boot
用dump备份非文件系统亦即单一目录的方法:
举例我们来处理一个/etc的dump备份,因为/etc并非一个文件系统,它只是一个目的而已。所以依据限制的说明,-u,level是1~9都不适用的。我们只能够使用level0的完整备份将/etc 给他dump下来。dump下来。
dump -0j -f /root/etc/dump.bz2 /etc
一般来说dump不会使用包含压缩的功能,不过如果你想要将备份的空间降低的话,那个-j的选项是可以使用得。
restore
这个命令是用于dump的复原使用的,我们只需要记住以下常用的:
-t:此模式用来在查看dump起来的备份文件中包含有什么重要的数据!
-C:此模式可以将dump内的数据拿出来跟实际的文件系统做比较,最终列出来在dump档案内有记录,且目前文件系统不一样的档案;
-i:进入互动模式,可以仅还原部分档案,用在dump目录时的还原。
-h:查看完整备份数据中的inode与文件系统label等信息
-f:后面就接你要处理的那个dump档案
-D:与-C搭配,可以查出后面接的挂载点与dump内有不同的档案。
-r:将整各filesystem还原的一种模式,用在还原针对文件系统的dump备份;
看使进行文件系统与备份文件之间的差异:
[root@localhost boot]# mv symvers-2.6.18-398.el5.gz /uestc
[root@localhost boot]# restore -C -f /uestc/boot.dump
Dump date: Mon Jun 29 11:21:02 2015
Dumped from: the epoch
Level 0 dump of /boot on localhost.localdomain:/dev/sda1
Label: /boot
filesys = /boot
restore: unable to stat ./symvers-2.6.18-398.el5.gz: No such file or directory
Some files were modified! 1 compare errors
对整个文件系统进行还原:restore -r -f /uestc/boot.dump
仅还原部分档案的restore互动模式:restore -i -f /uestc/etc/dump
mkisofs:简历映像档
用于刻录CD或者DVD所使用的命令
mkisofs [-o 镜像] [-rv] [-m file] 待备份文件.. [-V vol] -graft-point isodir=systemdir ...
-o:后面接你想要产生的那个镜像文件名
-r:透过Rock Ridge产生支持Unix/Linux的档案数据,可记录较多的信息(比如:UID/GID与权限)
-v:显示建置ISO档案的过程
-m file:-m为排除档案(exclude)的意思,后面的档案不备份到映像档中
-V vol:建立Volume(卷),有点像Windows在资源管理器内看到CD title的东西
-graft-point:graft转嫁或移植。例如:/movies/=/srv/movies/(在Linux的/srv/movies内的档案,加至镜像文件中的/movies/目录)
例如:我们想要将/root,/home,/etc等目录内的数据统统刻录起来,命令:
mkisofs -r -v -o /tmp/system.img /root /home /etc
这样的话数据就通通放置到了镜像文件的最顶层目录
然后我们mount -o loop /uestc/backup.img /mnt,然后ll -h /mnt看到/root /home /etc的数据通通的放在镜像文件的最顶层目录中,尤其由于/root/etc的存在 ,导致那个/etc的数据没有被包含进来,我们这里可以使用-graft-point来处理
mkisofs -r -V 'Linux_file' -o /uestc/system.img -m /home/lost+found -graft-point /root=/root /home=/home /etc=/etc
然后我们观察/mnt目录
[root@localhost uestc]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
14G 3.7G 9.3G 29% /
/dev/sda1 99M 23M 71M 25% /boot
tmpfs 2.0G 0 2.0G 0% /dev/shm
/uestc/system.img 124M 124M 0 100% /mnt
[root@localhost uestc]# cd /mnt
[root@localhost mnt]# ls
etc home root
cdrecord:关盘客户工具
cdrecord -scanbus dev=SATA //查询刻录机位置
cdrecord -v dev=SATA:x,y,z blank=[fast|all] //擦除重复读写片
cdrecord -v dev=SATA:x,y,z -format //格式化DVD+RW
cdrecord -v dev=SATA:x,y,z file.iso
选项与参数:
-scanbus:用在扫描磁盘总线并找出可用的刻录机,夏侯旭的装置为SATA借口
-v:在cdrecord运作的过程中,显示过程而已。
dev=SATA:x,y,z:后续的x,y,z为你系统上刻录机所在的位置
blank=[fast|all]:blank为抹掉可重复写入的CD/DVD-RW,使用fast较快all较完整
-format:仅针对DVD+RW这种格式的DVD而已
-data:指定后面的档案以数据格式写入,不是以CD音轨(-audio)方式写入
speed=X:指定刻录速度,speed=40为40倍。
-eject:当光盘刻录完毕后自动弹出光盘
fs=Ym:指定多少缓冲存储器。预设为4M,一般建议增加到8M
常见压缩与备份工具
dd:可以读取磁盘装置的内容(几乎是直接读取扇区“Sector”),然后将整个装置备份成一个档案。
用法:dd if="input_file" of="output_file" bs="block_size" count="number"
范例一:[root@localhost ~]# dd if="/etc/passwd" of="/uestc/passwd.backup"
3+1 records in
3+1 records out
1896 bytes (1.9 kB) copied, 6.8e-05 seconds, 27.9 MB/s
解释:/etc/passwd档案大小为1896字节,因为我们没有预设bs,所以系统默认为512bytes,以及未满的一个block,所以共占用3+1个block。
范例二:将自己的的磁盘的第一个扇区备份下来
dd if="/dev/sda1" of="/uestc/mbr.backup" bs=512 count=1
[root@localhost ~]# dd if="/dev/sda1" of="/uestc/mbr.backup" bs=512 count=1
1+0 records in
1+0 records out
512 bytes (512 B) copied, 8e-05 seconds, 6.4 MB/s
cpio可以被备份任何东西,包括装置设备档案。不过cpio有一个大问题,就是不会主动的去找档案来备份,要配合使用类似find等可以找到文件名的指令来告知cpio该备份的数据在哪?
例如:透过find我们可以找到/boot底下应该要存在的档名,包括档案与目录
find /boot | cpio -ocvB > /uestc/boot.cpio
备份完毕后解压到当前目录:cpio -idvc < /uestc/boot.cpio
VIM编辑器
vi三种模式的互相关系:
常用的插入命令:
a:在光标后附加文本
A:在本行行末附加文本
i:在光标前插入文本
I:在本行开始插入文本
o:在光标下插入新行
O:在光标上插入新行
常用定位命令
h:左移一个字符
j:下移一行
k:下移一行
l:右移一个字符
$:移至行尾
0:移至行首
H:移至屏幕上端
M:移至命令中央
L:移至屏幕下端
:set nu:设置行号
:set nonu:取消行号
gg:到第一行
G:到最后一行
nG:到第n行
:n到第n行
常用删除命令
x:删除光标所在处字符
nx:删除光标所在处后n个字符
dd:删除光标所在行,ndd删除n行
dG:删除光标所在行到末尾的内容
D:删除光标所在处到行尾
:n1,n2d:删除指定范围的行
复制和剪切
yy、Y:复制当前行
nyy、nY:复制当前行以下n行
dd:剪切当前行
ndd:剪切当前行一下n行
p、P:粘贴在当前光标所在行下或行上
替换和取消命令
r:取代光标所在处字符
R:从光标所在处开始替换字符,按Esc结束
u:取消上异步操作
搜索和替换命令
/string:向前搜索指定字符串;搜索时忽略大小写:set ic
n:搜索指定字符串的下一个出现位置。
:%s/old/new/g:全文替换指定字符串;c替换之前会进行询问。
:n1,n2s/old/new/g:在一定范围内替换指定字符串。
保存退出:
:w:保存或者shift+z+z
:wq:保存退出
:wq!:强制保存退出,只有文件所有者或管理员才能使用该命令
导入文件:r 文件名
在Vi中执行命令:! 命令
定义快捷键:map 快捷键 触发命令
例如:map ^P I#<ESC> 注意^号是ctrl+v+p显示出来的
连续行注释:n1,n2s/^/#/g
替换:ab sammail danbo@gmail.com
以上信息如果我们想要保存的话,即下次重启还能用的话,我们就应该进入家目录下的配置文件去修改
vi /root/.vimrc或者vi /home/danbo/.vimrc保存退出
Bash Shell
只要能够操作应用程序的接口都能称为壳程序。
bash具有记忆指令的功能,这些历史指令被记录在家目录的.bash_history里面
type:用于区分指令是来自外部指令还是bash内置命令
-t:有三种类型:file、alias、buildin
变量的取用与设定:echo,变量设定规则,unset
version=$(uname -r) 等于 version=`uname -r`
env:用来观察环境变量与常见环境变量
产生0-9的随机数:declare -i number=$RANDOM*10/32768; echo $number
set:用来观察所有变量(含有环境变量与自定义变量)
PS1:提示字符的设定,默认的配置为:PS1='[\u@\h \W]\$ '
$:代表目前这个Shell的线程代号,亦是所谓的PID(Process ID)。我们可以通过echo $$显示当前shell的PID
?:关于上一个执行指令的回传值:0表示上一个命令运行成功,非0则表示运行不成功。
export:自定义变量转换成环境变量
环境变量与自定义变量的差别主要在:该变量是否会被子程序所继续应用。
当你登入Linux并取得一个bash之后,你的bash就是一个独立的程序,被称为PID的就是,接下来你在这个bash底下所下达的任何指令都是由这个bash所衍生出来的,那些被下达的指令就被称为子程序。如下图所示为父进程与子进程的区别:
如上图所示:我们在原本的bash底下执行另一个bash,结果操作的环境接口会跑到第二个bash去(就是子程序),那原本的bash就是在暂停的情况(就是sleep)。整个指令运作的环境是粗线部分,要回到原本的bash去,就只有将第二个bash结束掉(exit或logout)。注意:子进程仅会继承父进程的环境变量,子进程不会继承父进程的自定义变量,所以你原本bash中的自定义变量在进入子进程后就会消失不见,一直到你离开子进程并回到原本父进程后才会出现。
没错,这里就用到export 变量名或者declare -x "变量名"
我们可以使用export查看系统所有的环境变量。
locale:查看系统语系设置
[root@localhost uestc]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
我们可以通过vim /etc/sysconfig/i18n来编辑
为什么环境变量的数据可以被子程序所引用呢?
1.当的启动一个shell,操作系统会分配一记忆区块给shell使用,此内存内的变量可让子进程取用
2.若父进程利用expor功能,可以让自定义变量的内容写到上述的记忆区块当中(环境变量)
3.当加载另一个shell时(即启动子进程,而离开原本的父进程),子shell可以将父shell的环境变量所在的记忆块导入自己的环境变量区块当中。
变量键盘读取、数组与宣告:read, array, declare
read
-p:后面可以接提示字符。
-t:后面接等待的秒数,超时后自动退出。
declare
-a:将后面变量定义为数组(array)类型
-i:将后面变量定义为整数数字(interger)类型
-x:用法与export一样,就是讲后面的变量编程环境变量
-r:将变量设定成为readonly类型,该变量不可被更改内容,也不能unset
[zhangm@localhost topfcc]$ sum=100+200+300
[zhangm@localhost topfcc]$ echo $sum
100+200+300
[zhangm@localhost topfcc]$ declare -i sum=100+200+300
[zhangm@localhost topfcc]$ echo $sum
600
由于在默认的情况下,bash对于变量有几个基本的定义:
-变量类型默认为字符串,所以若不指定变量类型,则1+2为一个字符串而不是计算式。所以才会出现以上的情况。
-bash环境中的数值运算,预设最多仅能到达整数形态,所以1/3结果是0。
数组(array)变量类型
var[index]=content
目前bash默认提供的是一维数组
[zhangm@localhost topfcc]$ var[1]="welcome"
[zhangm@localhost topfcc]$ var[2]=
[zhangm@localhost topfcc]$ var[2]="to"
[zhangm@localhost topfcc]$ var[3]="UESTC"
[zhangm@localhost topfcc]$ echo "${var[1]},${var[2]},${var[3]}"
welcome,to,UESTC
与文件系统内及程序的限制关系:ulimit
默认情况下我们使用的bash是可以限制用户的某些系统资源的,包括可以开启的档案数量,可以使用的CPU时间,可以使用的内存总量等等。我们可以通过ulimit -a来显示目前系统所有限制资料的数值
通过man ulimit来进行查看选项的使用。
单一filesystem能够支持的单一档案大小与block的大小有关。例如block的size为1024byte时,单一档案可达16GB。但是我们可以用ulimit来限制使用者可以建立的档案大小。利用ulimit -f就可以来设定。
path=${PATH}
echo $path
变量内容的删除与取代
${string:position} :从$position之后开始提取,也就是从postion+1的位置开始取
${string:position:length}:从$position之后开始提取长度为length的字串
${string#substring}:从$string开头开始删除最短匹配substring字串
${string##substring}:从$string开头开始删除最长匹配substring字串
${string%substring}:从$string结尾开始删除最短匹配substring字串
${string%%substring}:从$string结尾开始删除最长匹配substring字串
${string/substring/replace}:使用replace来代替第一个匹配substring
${string/#substring/replace}:如果$string前缀匹配$substring,就用$replace来代替substring
${string/%substring/replace}:如果$string后最匹配$substring,就用$replace来代替substring
注意最长匹配与最短匹配的区别:
[root@localhost uestc]# echo ${PATH}
/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@localhost uestc]# echo ${PATH#*:}
/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@localhost uestc]# echo ${PATH##*:}
/root/bin
[root@localhost uestc]# echo ${PATH%:*bin}
/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
[root@localhost uestc]# echo ${PATH%%:*bin}
/usr/kerberos/sbin
变量的测试与内容替换
${string:-word}:如果变量string存在且非空,则返回变量的值。否则,返回word字符串
其用法举例如下:
[root@localhost uestc]# echo $username
[root@localhost uestc]# username=${username:-danbo}
[root@localhost uestc]# echo $username
danbo
[root@localhost uestc]# username=root
[root@localhost uestc]# echo $username
root
${string:=word}:如果变量string存在且非空,则返回变量的值。否则,将word的值赋值给string,然后返回word
${string:?word}:如果变量string不存在时,则string的测试结果直接显示word,否则将消息word送到标准错误输出。
使用示例:
[root@localhost uestc]# str="uestc";var=${str?error}
[root@localhost uestc]# echo var="$var",str="$str"
var=uestc,str=uestc <==因为str存在,所以var等于str的内容。
命令别名设定:alias,unalias
设定别名:alias rm='rm -i'
查看系统已经设定的别名:alias
alias cp='cp -i'
alias l.='ls -d .* --color=tty'
alias ll='ls -l --color=tty'
alias ls='ls --color=tty'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
删掉系统的别名恢复默认命令:unalias rm
history显示最近输入的命令历史:
n:要列出最近的n笔命令
-c:将目前的shell中的所有history内容全部清除
-a:将目前新增的history明林新增入histfiles中,若没有加histfiles,则预设写入~/.bash_history
-r:将histfiles的内容读到目前这个shell的history记忆中
-w:将目前的history记忆内容写入histfiles中
这个默认存1000个记录,这个是在系统的环境变量文件中进行编辑。/etc/profile的HISTSIZE,我们可以通过set | grep HIST进行查看设定的值。
我们可以通过!number或者!command来直接运行history中的命令
!!:执行上一个指令。
当我们同时开好几各bash接口,这些bash的身份都是root,这样会有~/.bash_history的写入错误,因为这些bash在同时以root的身份登入,因此所有的bash都有自己的1000笔记录在内存中,因为等到注销时才会更新记录文件,所以了最后注销的bash才会写入数据。
解决办法是:可以用单一的bash登入,再用工作控制(job control)来切换不同工作。这样就可以记录下来。
无法记录时间。
那就是无法记录指令下达时间。不过我们可以透过~/.bash_logout来进行history的记录,并加上date来增加时间参数。
当我们下达指令的时候其顺序 :
1.以相对/绝对路径执行指令,例如:/bin/ls或ls
2.由alias找到该指令来执行
3.有bash内建的指令来执行
4.透过$PATH这个变量的顺序搜寻到的第一个指令来执行。
bash的进站与欢迎讯息: /etc/issue, /etc/motd
issue内的各代码意义:
\d 本地端时间的日期;
\l 显示第几个终端机接口;
\m 显示硬件的等级 (i386/i486/i586/i686...);
\n 显示主机的网络名称; \o 显示 domain name;
\r 操作系统的版本 (相当亍 uname -r)
\t 显示本地端时间的时间;
\s 操作系统的名称;
\v 操作系统的版本。
还有一个/etc/issue.net,这个是供给telnet这个远程登录程序使用的。
如果想让登录这登录后看到一些信息则需要修改/etc/motd文件了。
bash的环境配置文件
当我们一进入bash就取得一堆有用的变量,这是因为系统有一些环境配置文件的存在,让bash在启动时直接读取这些配置文件,以规划好bash的操作环境。
login与non-login shell
记住一些常用命令的用法:
cut
grep
sort
wc
uniq
双向重导向:tee
其原理图如下: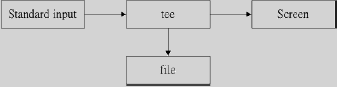
tee -a file
-a:以累加的方式,将数据加入file当中
字符转换命令:tr、col、join、paste、expand
由于DOS与Unix的断行字符不同,我们可以使用dos2unix、unix2dos来完成转换。
tr:可以用来删除一段信息当中的文字,或者是进行文字信息的替换(translate、delete)
-d:删除信息当中的SET1这个字符:tr -d SET1
-s:取代掉重复的字符
last | tr '[a-z]' '[A-Z]' //将所有的小写字符转换为大小字符。
cat /etc/passwd | tr -d ':' //将输出信息中的:删除
col
-x:将tab键转化成对等的空格键盘
-b:在文字内有反斜杠/时,仅保保留反斜杠最后接的那个字符
cat /etc/man.config | col -x | more这样的话tab键会被转换成空格,输出就美观了。
linux中文本文件中tab键是会以^I来表示的
join:是处理两个档案之间的数据,而且,主要是处理两个档案中有“相同数据”的那一行,才能将他加在一起。
例如:join [-ti12] file1 filew
-t:join默认以空格符分割数据,并且对比第一个字段的数据,如果两个档案相同,则将两笔数联成一行,且第一个字段放在第一个!
-i:忽略大小写的差异
-1:这个数字的1, 代表第一个档案要用那个字段来分析的意思
-2:代表第二个档案要用那个字段来分析的意思
具体实例看鸟哥基础篇
paste:相对join必须要比对两个档案的数据相关性,paste就直接将两行贴在一起,且中间一tab键隔开。
-d:后面可以接分割符。预设是以tab键来分割。
-:如果file部分携程-,表示来自standard input的资料的意思。
expand:
-t:后面可以接数字,一般来说,一个tab按键可以用8个空格键取代。我们也可以自行定义个tab键代表多少个字符
比如:讲/etc/man.config内行首为MANPATH的字样就去除,仅取出前三行。
grep '^MANPATH' /etc/man.config | head -3 | expand -t 6 | cat -A
以上命令我们将tab键换成6个字符
split:分割命令,将大的文档按照文件的大小或者是行来进行分割。
-b:后面可接分割成的档案大小,可加单位,b、k、m
l:以行数来进行分割。
PREFIX:代表前导符的意思,可作为分割档案的前导文件。
[root@localhost ~]# ll -h /etc/termcap
-rw-r--r-- 1 root root 789K Jan 6 2007 /etc/termcap
[root@localhost ~]# cd /tmp;split -b 300k /etc/termcap termcap
[root@localhost tmp]# ll -k termcap*
-rw-r--r-- 1 root root 300 Jul 1 15:51 termcapaa
-rw-r--r-- 1 root root 300 Jul 1 15:51 termcapab
-rw-r--r-- 1 root root 189 Jul 1 15:51 termcapac
xargs:参数代换
x是加减乘除的乘号,args则是arguments(参数)的意思,所以说,其作用是在产生某个指令的参数的意思,xargs可以读入stdin的数据,并且以空格键或断行符作为分辨,将stdin的资料分割成为arguments。因为是以空格符作为分割,所有可能会误判
-0:如果输入的stdin含有特殊字符,例如`,\,空格等字符时,这个-0参数可以将它还原成一般字符。
-e:这个是EOF(end of file)的意思,后面可以接一个字符串,当xargs分析这个字符串时,就会停止继续工作。
-p:在执行每个指令的argument时,都会询问使用者的意思。
-n:后面接次数,每次commond指令执行时,要使用几个参数的意思。
当xargs后面没有使用任何的指令时,默认是以echo来进行输出的。
比如:将/etc/passwd内的第一栏取出,仅取三行,使用finger这个指令将每个账号内容show出来。
cut -d ":" -f1 /etc/passwd | head -3 | xargs finger
finger account可以取得该账号的相关说明内容。
-:例如:tar -cvf /home | tar -xvf -
上面的作用是:我们将/home里面的档案打包,但打包的数据并不是记录到档案,而是传送到stdout;经过管线后,将tar -zcvf -/home 传送给后面的tar -zxvf -。后面的这个-则是取用前一个指令的stdout,因此,我们就不需要使用file了。-:管线命令在bash的连续处理的程序中是相当重要的,在log file的分析当中也是相当重要的一环,所以请特留意,在管线命令中,常常会使用到前一个指令的stdout作为这次的stdin,因此我们就不需要使用file了。
正则表达式 LALALAALALALAAAAAAAAAAALALALALLALALALALLALLALALLALLAALLALA
grep常用选项与参数:
-a:将binary档案以text档案的方式搜索数据
-c:计算找到“搜寻字符串”的次数
-i:忽略大小写的不同,所以大小写视为相同
-n:顺便输出行号
-v:反向选择,亦即显示出没有“搜寻字符串”内容的那一行
grep [-A] [-B] [--color=auto] '搜寻字符串' filename
-A:后面可加数字,为after的意思,除了列出该行外,后续的n行业列出来。
-B:后面可加数字,为before的意思,除了列出该行外,前面的n行也列出来。
同时grep也可以搜寻含有关键字的指定行:grep -n "root" /etc/passwd
此时同时也可以用正则表达式来指定搜索的关键字
常用的特殊字符:
[:alnum:]:代表英文大小写字符及数字,亦即0-9,A-Z,a-z
[:alpha:]:代表任何英文大小写字符,即A-Z,a-z
[:blank:]:代表空格键与[Tab]按键两者
[:cntrl:]:代表键盘上面的控制按键,亦即包括CR,LF,Tab,Del...等等
[:digit:]:代表数字,即0-9
[:graph:]:除了空格符与Tab键外的其他所有按键
[:lower:]:代表小写字符,即a-z
[:print:]:代表任何可以被打印出来的字符
[:punct:]:代表标点符号(punctuation symbol),即:"'?!;:#$..
[:upper:]:代表大写字符。即A-Z
[:space:]:任何会产生空白的字符,包括空格符,Tab,CR等等
[:xdigit:]:代表16进制的数字类型,包括:0-9,A-F,a-f
Windows下的断行字符(^M$),Linux下的断行字符为($)
grep -n "^$" regular_express.txt:用来打印哪一行是空白行。
grep -v "^#" regular_express.txt:去掉文本中的注释行。
我们知道通配符*可以用来代表任意0个或多个字符,在正则表达式中*代表重复前一个0到无穷多次。
.代表一定匹配一个任意的字符
限定连续RE字符范围{},但是{与}在shell具有特殊的意义,我们在使用的时候需要使用在“\”跳脱字符来让他失去特殊意义。
^word:匹配字符串word在行首。
word$:匹配字符串word在行尾。
sed:流编辑工具
-n:使用安静模式,只有经过sed特殊处理的那一行才会被列出。
-e:直接在指令列模式上进行sed的动作编辑
-f:直接将sed的动作写在一个档案内,-f filename则可以执行filename内的sed动作。
-r:sed的动作支持的是延伸型增则表达式。
-i:直接修改读取的档案内容,而不是由屏幕输出
动作:
n1,n2:指定处理的行范围
a:新增,a后面可以接字符串,而这些字符串会在新的一行出现(目前行的下一行)
c:取代,c后面可以接字符串,而这些字符串可以取代n1,n2之间的行
i:插入,i后面可以接字符串,而这些字符串可以插入到当前行的上一行
p:打印,将某些选择的数据印出。
s:取代,在行中取代,比如1,20s/old/new/g就是啦
比如取出本机的IP地址:ifconfig eth0 | grep "inet addr" | sed 's/.*addr://g' | sed 's/ Bcast:.*//g'
扩展的正则表达式:
例如:grep -v '^$' gegular_express.txt | grep -v '^#'。基础正则表达式需要用到管线命令来搜寻两次。
扩展正则表达式:egrep -v '^$|^#' regular_express.txt 或者使用grep -E
常见的示例:
egrep -n 'go+d' regular_express.txt +:重复一个或多个前一个字符
egrep -n 'go?d' regular_express.txt ?:零个或一个前一个字符
egrep -n 'gd|good' regular_express.txt |:用或的方式找出数个字符串
egrep -n 'g(la|oo)d' regular_express.txt ():找出群组字符串
echo 'AxyzxyzxyzxyzC' | egrep 'A(xyz)+C' ()+:找出开头是A结尾是C,中间有一个以上的“xyz”字符串的意思
格式打印:printf
\" double quote
\NNN character with octal value NNN (1 to 3 digits)
\\ backslash
\a alert (BEL)
\b backspace
\c produce no further output
\f form feed
\n new line
\r carriage return
\t horizontal tab
\v vertical tab
\xHH byte with hexadecimal value HH (1 to 2 digits)
\uHHHH Unicode (ISO/IEC 10646) character with hex value
HHHH (4 digits)
\UHHHHHHHH
Unicode character with hex value HHHHHHHH (8 digits)
%% a single %
%b ARGUMENT as a string with ‘\’ escapes interpreted,
except that octal escapes are of the form \0 or
\0NNN
awk:好用的数据处理工具
通用模式:awk '条件类型1{动作1} 条件类型2{动作2} ..' filename
awk的处理流程:
1.读入第一行,并将第一行的资料填入$0,$1,$2...等变数当中;
2.依据“条件类型”的限制,判断是否需要进行后面的“动作”;
3.做完所有的动作与条件类型;
4.若还有后续的行的数据,则重复上面1~3的步骤,直到所有的数据都读完为止。
经过这样的步骤,你就会知道,awk是以行为一次处理的单位,而以字段为最小的处理单位,那么awk怎么知道我到底这个数据有几行,有几栏呢,这就需要awk的内建变量的帮忙
NF:每一行($0)拥有的字段总数。
NR:目前awk所处理的是第几行数据
FS:目前的分割字符,默认是空格键
比如我们利用last -n 5的来例子来做说明。
-列出每一行的账号(就是$1)
-列出目前处理的行数(就是awk内部的NR变量)
-并且说么给你,改行有多少字段(就是awk内的NF变量
awk使用的时候我们要注意一下事项:
-awk的指令间隔:所有awk的动作, 亦即在{}内的动作,如果需要多个指令辅助时,可以利用分号;,或以Enter按键来隔开每个指令。
-逻辑运算当中,如果等于的情况,则务必使用两个等号==
-格式化输出时,在printf的格式设定当中个,务必加上\n,才能进行分行。
-与bash shell的变量不同,=在awk当中个,变量可以直接使用,不需加上$符号。
档案的对比工具:diff
diff就是用在对比两个档案之前的差异的,并且是以单位来对比的,一般是用在ASCII纯文本档的对比上。由于是以行为对比的单位的,因此diff通常是用在同一档案的喜酒版本上
其用法:
diff [-bBi] from-file to-file
from-file:一个档名,作为原始对比档案的档名
to-file:一个档名,作为目的对比档案的档名
-b:忽略一行当中仅有多个空白的差异
-B:忽略空白行
-i:忽略大小写的不同
cmp也是对比两个档案的不同,但是cmp是以字节单位去对比。而diff则是以行为单位对比
-s:将所有的不同点的字节处都列出来。因为cmp预设仅会输出第一个发现的不同点。
patch:将旧的档案升级为新的档案。其操作流程为:先比较新旧版本的差异,并且将差异档执着为补丁档,再有补丁档更新旧档案。
-p:后面可以接[取消几层目录]的意思。
-R:代表还原,将新的文件还原原来旧的版本。
Shell Scripts
此部分单独出来一片shell脚本学习的文章
Linux账户管理域ACL权限设定
我们看一下passwd,shadow,gpasswd,gshadow
passwd:
[root@localhost ~]# head -4 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
我们发现每行用:隔开,总共有7个东东:
1.账户名称,用来对应UID,例如root的UID对应就是0
2.密码位:真实的密码存在/etc/shadow当中
3.UID:这个就是使用者的标识符,通常来说0为root用户;1-999为系统账号;1000-65535为一般使用者。
4.GID:这个与/etc/group有关,其实/etc/group的观念与/etc/passwd差不多,只是他是用来规范组名与GID的对应而已
5.用户信息说明栏:用来解释这个账号的意义。如果您提供使用finger的功能,这个字段可以提供更过的信息。可以使用chfn来解释这里的说明
6.家目录:root的家目录在/root,其他的在/home/目录下
7.Shell:默认bash,有一个shell可以用来替代成让账号无法取得shell环境的登入动作,就是/sbin/nologin
/etc/shadow档案内容:
[root@localhost ~]# head -4 /etc/shadow
root:$1$UfuVzZGV$duqTQOf8lWRmKkneB3DSZ1:16612:0:99999:7:::
bin:*:16612:0:99999:7:::
daemon:*:16612:0:99999:7:::
adm:*:16612:0:99999:7:::
1.账户名称:这个必须与/etc/passwd相同的。
2.密码: 这个是经过加密的密码。MD5的值,当这个位数长度变化后,该密码就会失效,我们可以透过这个功能,在此字段前面加上!或*改变密码字段的长度,这就会让密码暂时失效。
3.最近更更懂密码的日期:不过这个时间是以1970年1月1日作为起始累加日期。
4.密码不可被更改的天数:与第3字段相比
5.密码需要重新变更的天数
6.密码需要变更期限前的警告天数
7.密码过期后账号宽限的时间(密码失效日)
8.账号失效日期
9.保留
关于群组
/etc/group档案结构
[root@localhost ~]# head -4 /etc/group
root:x:0:root
bin:x:1:root,bin,daemon
daemon:x:2:root,bin,daemon
sys:x:3:root,bin,adm
1.组名:就是组名
2.群组密码:通常不需要设定,通常是给群组管理员使用。同样真是密码存在于/etc/gshadow
3.GID:就是群组ID,我们/etc/passwd第四个字段使用的GID对应的群组名
4.此群组支持的账号名称
有效群组(effective group)与初始群组(initial group)
初始群组:就是/etc/passwd第四栏的GID,代表此用户一登入系统,立即就拥有这个群组的相关权限。
groups:有效与支持群组的观察
[root@localhost ~]# groups
root bin daemon sys adm disk wheel
第一个输出的即为有效群组(effective group)。
我们使用newgrp users来进行优先群组的切换。
只要我的用户有支持的群组就是能够切换成为有效群组,我们如何让一个账号加入不同的群组呢?哟两种方式:
1.透过root利用usermod加入。
2.透过群组管理员以gpasswd加入他管理的劝阻中。
我们来观察一下/etc/gshadow这个
[root@localhost ~]# head -4 /etc/gshadow
root:::root
bin:::root,bin,daemon
daemon:::root,bin,daemon
sys:::root,bin,adm
1.组名
2.密码位
3.群组管理员账号
4.该群组的所属账号
以root的角度来说,gshadow最大的功能就是建立群组管理员。由于目前有类似sudo之类的工具,我们目前很少会用到gshadow了。
新增与移除使用者:useradd,相关配置文件,passwd、usermod、userdel
useradd:新建用户
useradd [-u UID] [-g 初始群组] [-G 次要群组] [-mM] [-c 说明栏] [-d 家目录绝对路径] [-s shell] 使用者账户名
-u:后面接的是UID,是一组数字,直接指定一个特定的UID给这个账号
-g:初始组的GID。
-G:后面接这个账号的支持群组
-M:强制不要建立用户家目录(系统账号么默认值)
-m:强制要建立用户家目录
-c:这个就是/etc/passwd的第5栏的说明内容。
-d:制定某个目录称为家目录,而不要使用默认值,必须使用绝对目录
-r:建立一个系统的账号,这个账号的UID会有限制。
-s:后面接一个shell,若没有指定则预设是/bin/bash
-e:后面接一个日期,格式为YYYY-MM-DD此项目可写入shadow第8字段,即指账号失效日期的设定项目。
-f:后面接shadow的第7个字段,指定密码是否失效。0为立即失败,-1为永远失效(密码只会过期而请强制于登入时重新设定而已)
当我们使用useradd增加用户后,CentOS会处理一下几个项目:
1.在/etc/passwd里面增加一行与账号相关的数据,包括建立UID/GID/家目录
2.在/etc/shadow里面增加此账号的密码相关参数填入。但此时没有密码;
3.在/etc/group里面加入一个账号名称一模一样的组名
4.在/home底下建立一个与账号同名的目录作为用户家目录,且权限为700
useradd底下的默认值可以使用底下的方法呼叫出来:
[root@localhost ~]# useradd -D
GROUP=100
HOME=/home
INACTIVE=-1 //密码过期后是否会失效的设定(0代表密码过期立即失效,-1表示永不失效,30表示30天后失效)
EXPIRE= //账号失效的日期
SHELL=/bin/bash
SKEL=/etc/skel //这个是用户家目录参考的基准目录
CREATE_MAIL_SPOOL=yes //建立使用者的mailbox
以上信息其实是存在于/etc/default/useradd当中的。
当我们使用useradd程序在建立Linux上的账号时,至少会参考:
1./etc/default/useradd
2./etc/login.defs
3./etc/skel/*
passwd命令常用选项
--stdin:可以透过来自前一个管线的数据,作为密码输入,对shell script有帮助;
例如:echo “fuckuestc” | passwd --stdin root
-l:是Lock的意思,会将/etc/shadow第二栏最前面加上!是密码失效;
-u:与-l相对,是Unlock的意思
-S:列出密码相关参数,亦即shadow档案内的大部分信息。
-n:后面接天数,shadow第4字段,多久不可以修改密码的天数
-x:shadow第5字段,多久内必须要更改密码
-w:shadow第6字段,密码过期前的警告天数
-i:shadow第7字段,密码失效日期
usermod
除了使用passwd -S之外,我们还可以使用chage来显示更详细的密码参数显示功能。
[root@localhost ~]# passwd -S root
root PS 2015-06-25 0 99999 7 -1 (Password set, MD5 crypt.)
[root@localhost ~]# chage
Usage: chage [options] user
Options:
-d, --lastday LAST_DAY set last password change to LAST_DAY
-E, --expiredate EXPIRE_DATE set account expiration date to EXPIRE_DATE
-h, --help display this help message and exit
-I, --inactive INACTIVE set password inactive after expiration
to INACTIVE
-l, --list show account aging information
-m, --mindays MIN_DAYS set minimum number of days before password
change to MIN_DAYS
-M, --maxdays MAX_DAYS set maximim number of days before password
change to MAX_DAYS
-W, --warndays WARN_DAYS set expiration warning days to WARN_DAYS
usermod:如果当我们使用useradd的时候加入了错误的设定,当我们想进一步修改的时候,可以使用usermod来设置。
-b, --base-dir BASE_DIR base directory for the new user account
home directory
-c, --comment COMMENT set the GECOS field for the new user account
-d, --home-dir HOME_DIR home directory for the new user account
-D, --defaults print or save modified default useradd
configuration
-e, --expiredate EXPIRE_DATE set account expiration date to EXPIRE_DATE
-f, --inactive INACTIVE set password inactive after expiration
to INACTIVE
-g, --gid GROUP force use GROUP for the new user account
-G, --groups GROUPS list of supplementary groups for the new
user account
-h, --help display this help message and exit
-k, --skel SKEL_DIR specify an alternative skel directory
-K, --key KEY=VALUE overrides /etc/login.defs defaults
-m, --create-home create home directory for the new user
account
-l, do not add user to lastlog database file
-M, do not create user's home directory(overrides /etc/login.defs)
-r, create system account
-o, --non-unique allow create user with duplicate
(non-unique) UID
-p, --password PASSWORD use encrypted password for the new user
account
-s, --shell SHELL the login shell for the new user account
-u, --uid UID force use the UID for the new user account
-Z, --selinux-user SEUSER use a specific SEUSER for the SELinux user mapping
userdel:删除用户
-r:连同用户的家目录也一起删除。
finger:这个finger可以查阅很多用户相关的信息,大部分都是在/etc/passwd这个档案里面的信息。
finger -s username //仅列出用户的账号、全名、终端机代号与登入时间等等;
finger -m username //列出与后面接的账号相同者,而不是利用部分对比(包括全名部分)
chfn:这点类似:change finger的意思。
-f:后面接完整的大名;
-o:您办公室的房间号码;
-p:办公室的电话号码;
-h:家里的电话号码!
chsh:
-l:列出目前系统上面可用的shell,其实就是/etc/shells的内容
-s:设定修改自己的shell
id [username]
可以查阅root自己的相关ID信息
[root@localhost ~]# id danbo
uid=1000(danbo) gid=1000(danbo) groups=1000(danbo)
移除用户组用groupadd
-g:后面接某个特定的GID,用来直接设定GID
-r:建立系统群组,与/etc/login.defs内的GID_MIN
[root@localhost ~]# cat /etc/login.defs | grep -v "^#"
MAIL_DIR /var/spool/mail
PASS_MAX_DAYS 99999
PASS_MIN_DAYS 0
PASS_MIN_LEN 5
PASS_WARN_AGE 7
UID_MIN 1000
UID_MAX 60000
SYS_UID_MIN 201
SYS_UID_MAX 999
GID_MIN 1000
GID_MAX 60000
SYS_GID_MIN 201
SYS_GID_MAX 999
CREATE_HOME yes
UMASK 077
USERGROUPS_ENAB yes
ENCRYPT_METHOD SHA512
groupmod
这个是修改group相关参数的修改
-g:修改既有的GID数字;
-n:修改既有的组名;
groupdel:删除群组
gpasswd:修改群组管理员功能。
其参数:
-A:将groupname的主控权交由后面的使用者管理(/etc/gshadow)
-M:将某些账号计入这个群组当
-r:将groupname的密码移除
-R:让goupname的密码栏失效
gpasswd -a user groupname
-a:将某位使用者加入到groupname这个群组当中
-d:将某位使用者移除groupname这个群组当中。
ACL
Access Control List的缩写,主要目的是在提供传统的owner,group,others的read,write,execute权限之外的细部权限设定。ACL可以针对单一使用者,单一档案或目录来进行r,w,x的权限规。
使用者(user):可以针对使用者来设定设定。
群组(group):针对群组为对象来设定其权限
默认属性(mask):还可以针对在该目录下载建立新档案/目录时,规范新数据的默认权限
acl的设定技巧:getfacl,setfacl
getfacl:取得某个档案/目录的ACL设定项目;
setfacl:设定某个目录/档案的ACL规范
setfacl [-bkRd] [{-m|-x} acl 参数] 目标文件名 (set file access control lists)
-m, --modify=acl modify the current ACL(s) of file(s) //设定后续的acl参数给档案使用,不可与-x合用;
-M, --modify-file=file read ACL entries to modify from file
-x, --remove=acl remove entries from the ACL(s) of file(s) //删除后续的acl参数,不可与-m合用;
-X, --remove-file=file read ACL entries to remove from file
-b, --remove-all remove all extended ACL entries //移除所有的ACL设定参数
-k, --remove-default remove the default ACL //移除所有预设的ACL参数
--set=acl set the ACL of file(s), replacing the current ACL
--set-file=file read ACL entries to set from file
--mask do recalculate the effective rights mask
-n, --no-mask don't recalculate the effective rights mask
-d, --default operations apply to the default ACL
-R, --recursive recurse into subdirectories //递归设定acl,亦即包括次目录都会被设定起来
-L, --logical logical walk, follow symbolic links
-P, --physical physical walk, do not follow symbolic links
--restore=file restore ACLs (inverse of `getfacl -R')
--test test mode (ACLs are not modified)
-v, --version print version and exit
-h, --help this help text
getfacl (get file access control lists)
Usage: getfacl [-dRLPvh] file ...
--access display the file access control list only
-d, --default display the default access control list only
--omit-header do not display the comment header
--all-effective print all effective rights
--no-effective print no effective rights
--skip-base skip files that only have the base entries
-R, --recursive recurse into subdirectories
-L, --logical logical walk, follow symbolic links
-P --physical physical walk, do not follow symbolic links
--tabular use tabular output format
--numeric print numeric user/group identifiers
--absolute-names don't strip leading '/' in pathnames
-v, --version print version and exit
-h, --help this help text
su:是最简单的身份切换指令,他可以进行任何身份的切换
-:代表使用login-shell的变量档案读取方式来接入系统;
-l:与-类似,但是后面需要加欲切换的使用者账号,也是login-shell的方式
-m:-m与-p是一样的,表示目前的环境设定,而不读取新的使用者的配置文件。
-c:仅进行一次指令,所以-c后面可以加上指令。
单纯使用su切换成为root的身份,读取的变量设定方式为non-login shell的方式,这种方式原本的变量不会被改变,尤其是我们之前谈过甚多此的PATH变量。因此很多root命令需要使用绝对路径来运行。还有此时收到的MAIL还是原来用户的。
如果仅想要执行一次root的指令,可以利用su - -c "command"的方式来处理;
sudo:相当于su需要了解新切换的用户密码(常常是需要root的密码),sudo的执行仅需要自的密码即可,甚至可以设定不需要密码即可执行sudo,由于sudo可以让你一其他用户的身份执行指令(通常使用root的身份来执行),因此并非所有人都可以执行sudo,仅有规范到/etc/sudoers内的用户才能够执行sudo这个指令。
sudo
-b:将后续的指令放到背景中让系统自行执行,而不是与当前的shell产生影响
-u:后面可以接欲切换的使用者,若无此项则代表切换身份为root
sudo指令的过程
1.当用户执行sudo时,系统于/etc/sudoers档案中搜寻该使用者是否有执行sudo的权限;
2.若使用者具有可执行sudo的权限后,便让使用者[输入用户自己的密码]来确定;
3.若密码输入成功,便开始进行sudo后续的指令(但root执行sudo时,不需要输入密码)
4.若欲切换的身份与执行者相同,那也不需要输入密码
visudo与/etc/sudoers
除了root之外的其他账号,若想要使用sudo执行属于root的权限指令,则root需要先使用visudo去修改/etc/sudoers,让该账号能够使用全部或部分的root指令功能。为什么要使用visudo呢?这是因为/etc/sudoers是由设定语法的,如果设定错误那会造成无法使用sudo指令的不良后果。因此才会使用visudo去修改,并在结束离开修改画面时,系统会去检查/etc/sudoers的语法就是了
/sbin/nologin
查询使用者w、who、last、lastlog
lastlog命令会去读取/var/log/lastlog
使用者对谈:write、mesg、wall
write 使用用这账号 [用户所在终端接口,这个通过who来查看]
[root@localhost ~]# write root pts/1
Message from root@localhost.localdomain on pts/1 at 05:57 ...
welcome to uestc
welcome to uestc
EOF
mesg的功能对root传送来的信息没有任何抵抗能力,所以如果是root传送信息,danbo必须要收下。但是如果root的mesg是n的,那么danbo写给root的信息是:write:root has messages disabled。可以通过mesg -y来解锁
使用wall与write必须使用者在线才能看到,mail则不需要
[root@localhost ~]# mail root -s "Hello"
Hello
byby
. <==结束时,最后一行输入小数点。
Cc: 639188185@qq.com <==这里所谓的副本,即需要寄给其他人。
我们同时也可以实现编写好文件,利用重定向的方式来传输即可
我们如何去收信呢?同样是使用mail
[root@localhost ~]# mail
Mail version 8.1 6/6/93. Type ? for help.
"/var/spool/mail/root": 13 messages 13 new
>N 1 logwatch@localhost.l Fri Jun 26 18:41 42/1589 "Logwat"
N 2 logwatch@localhost.l Sat Jun 27 04:02 98/3136 "Logwat"
N 3 logwatch@localhost.l Sat Jun 27 04:36 98/3136 "Logwat"
N 4 logwatch@localhost.l Sun Jun 28 04:02 115/3803 "Logwat"
N 5 logwatch@localhost.l Sun Jun 28 05:04 107/3622 "Logwat"
N 6 logwatch@localhost.l Mon Jun 29 03:03 101/3492 "Logwat"
N 7 logwatch@localhost.l Mon Jun 29 04:02 101/3492 "Logwat"
N 8 logwatch@localhost.l Tue Jun 30 04:02 260/8780 "Logwat"
N 9 logwatch@localhost.l Tue Jun 30 05:04 252/8599 "Logwat"
N 10 logwatch@localhost.l Wed Jul 1 08:32 109/3393 "Logwat"
N 11 logwatch@localhost.l Thu Jul 2 06:35 100/3495 "Logwat"
N 12 root@localhost.local Fri Jul 3 06:02 18/631 "Hello"
N 13 MAILER-DAEMON@localh Fri Jul 3 06:02 68/2494 "Return"
& ?
Mail Commands
t <message list> type messages
n goto and type next message
e <message list> edit messages
f <message list> give head lines of messages
d <message list> delete messages //删除后续接的信件号码,删除单封邮件是d10
s <message list> file append messages to file
u <message list> undelete messages
R <message list> reply to message senders
r <message list> reply to message senders and all recipients
pre <message list> make messages go back to /usr/spool/mail
m <user list> mail to specific users
q quit, saving unresolved messages in mbox
x quit, do not remove system mailbox
h print out active message headers
! shell escape
cd [directory] chdir to directory or home if none given
A <message list> consists of integers, ranges of same, or user names separated
by spaces. If omitted, Mail uses the last message typed.
A <user list> consists of user names or aliases separated by spaces.
Aliases are defined in .mailrc in your home directory.
pwck:这个指令在检查/etc/passwd这个账号配置文件内的信息 ,与实际的家目录是否存在等信息。还可对比/etc/passwd 、/etc/shadow的信息是否一致,另外,如果/etc/passwd内的数据字段错误时,会提示修订信息
相对应的群组检查可以使用grpck这个指令。
pwconv:这个指令主要的目的是在将/etc/passwd内的账号与密码,移动到/etc/shadow当中
pwunconv:将/etc/shadow内的密码栏数据写回/etc/passwd当中个,并且删除/etc/shadow档案。注意此时会将/etc/shadow删除,如果忘记备份的话,则必须使用pwconv进行转化。
chpasswd:他可以[读入未加密前的密码,并且经过加密后,将加密后的密码吸入/etc/shadow当中],这个指令很常被使用在大量建置账号的情况中,它可以有Stdin读入数据,每笔格式是:username:password。
举例来说,我的系统当中账号为:danbo,我想要更新他的密码(update),假如他的密码是abcdefg的话,我们可以这样做:
echo "danbo:abcdefg" | chpasswd -m
chpasswd使用的是DES加密方式来加密,我们可以使用chpasswd -m来转换为MD5加密方式
不过我们通常使用passwd -stdin的方式。echo "abc123456" | passwd --stdin root
当我们新建一个账户的时候其动作是一下方式:
1.先建立所需要的群组(vi /etc/group)
2.将/etc/group与/etc/gshadow同步化(grpconv)
3.简历账号的各个属性(vi /etc/passwd)
4.将/etc/passwd与/etc/shadow同步化(pwconv)
5.建立该账号的密码(passwd accountname)
6.建立用户家目录(cp -a /etc/skel /home/accountname)
7.更改用户家目录的属性(chown -R accountname.group /home/accountname)
大量创建账号的模板(使用passwd --stdin选项)
其脚本编写如下:
#!/bin/bash
#功能:检查account.txt是否存在,并将该档案内的账号取出,建立上述的账号;将账号的面膜修改为第一次进入需要修改密码
#检查account.txg是否存在
if [ ! -f account.txt ]; then
echo "account.txt is not exits ,Pls Create this file"
exit 1
fi
usernames=${cat account.txt}
for username in $uaernames
do
useradd $username
echo $username | passwd --stdin $username
chage -d 0 username
done
我们只需要建立account.txt这个文档,然后然后在account.txt目录下执行这个shell脚本即可。
另一个大量建立账号的范例,有一下四个要求
#!/bin/bash
echo ""
echo "例如我们电子科技大学的学号为:2012043020022"
echo "所属级为:2012"
echo "所属学院04"
echo "所属专业30"
echo "所属班级为20"
echo "所属班级学号为22"
echo ""
read -p "您属于哪一级" username_year
read -p "所属学院" username_school
read -p "所属专业" username_major
read -p "所属班级" username_class
read -p "班级学号" username_num
if [ ""$username_year ]; then
echo "妈的不输入年级,老子哪里晓得你属于哪一届" ; exit 1
fi
#判断输入的是否为数字
testing0=$(echo $username_year | grep '[^0-9]')
testing1=$(echo $username_school | grep '[^0-9]')
testing2=$(echo $username_major | grep '[^0-9]')
testing3=$(echo $username_class | grep '[^0-9]')
testing4=$(echo $username _num | grep '[^0-9]')
if ["$testing0" !="" -o "$testing1" !="" -o "$testing2" !=""]; then
echo "妈的,你傻逼的学号不是数字?";exit 1
fi
#开始输入账号与密码档案!
[ -f "$accountfile" ] && mv $accountfile "accountfile"$(date +%Y%m%d)
...
参考Linux Script的部分。
磁盘阵列&磁盘配额&crontab(计划任务)
最重要的是shell脚本,参考shell脚本笔记。

