
Spark处理日志文件常见操作
spark有自己的集群计算技术,扩展了hadoop mr模型用于高效计算,包括交互式查询和
流计算。主要的特性就是内存的集群计算提升计算速度。在实际运用过程中也当然少不了对一些数据集的操作。下面将通过以下练习来深化对spark的理解,所有练习将使用python完成,java、scala版本将后续完成。
操作一、使用RDDS操作数据集(这个练习将会在spark的交互式终端下完成,通过一个简单的文本文件,然后使用spark探索和变换Apache Web服务器的输出日志,所使用的数据集来至Loudacre公司)。
1、 创建rdd,然后查看数据集行数。
file=file:///home/training/training_materials/data/weblogs/* myrdd=sc.textFile(file) myrdd.count() //对文本文档的行数进行统计
#输出结果:1079931 myrdd.take(4)#取出数据集中的前4行
# 输出结果: ['213.158.179.231 - 24704 [03/Mar/2014:00:00:00 +0100] "GET /meetoo_1.0_sales.html HTTP/1.0" 200 1567 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 2.0"', '213.158.179.231 - 24704 [03/Mar/2014:00:00:00 +0100] "GET /theme.css HTTP/1.0" 200 15447 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 2.0"', '213.158.179.231 - 24704 [03/Mar/2014:00:00:00 +0100] "GET /code.js HTTP/1.0" 200 519 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 2.0"', '213.158.179.231 - 24704 [03/Mar/2014:00:00:00 +0100] "GET /meetoo_1.0.jpg HTTP/1.0" 200 18640 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 2.0"']
1、 创建一个新的RDD,只包含数据集含有JPG文件的
myrdd.filter(lambda x:".jpg" in x).take(10)
输出结果:
['213.158.179.231 - 24704 [03/Mar/2014:00:00:00 +0100] "GET /meetoo_1.0.jpg HTTP/1.0" 200 18640 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 2.0"',
'14.7.25.113 - 106082 [02/Mar/2014:23:59:23 +0100] "GET /titanic_deckchairs.jpg HTTP/1.0" 200 7701 "http://www.loudacre.com" "Loudacre Mobile Browser Titanic 2500"',
'100.226.80.124 - 56952 [02/Mar/2014:23:55:57 +0100] "GET /meetoo_3.0.jpg HTTP/1.0" 200 7009 "http://www.loudacre.com" "Loudacre Mobile Browser MeeToo 3.1"']
2、有时我们并不需要对数据集的操作所产生的数据存储在一个变量中,在这种情况下,我们可以简化代码,比如,你想对数据集中包含jpg的行数进行统计。
sc.textFile(file).filter(lambda x:".jpg" in x).count()
输出结果:
64978
3、对日志文件中的每一行进行一个长度的计算,取前10行。
myrdd.map(lambda s:len(s)).take(10)
输出结果:
[163, 152, 148, 157, 171, 151, 148, 163, 159, 152]
4、使用map,将RDD中的每一行数据按空格拆分,形成一个新的map映射。
myrdd.map(lambda s:s.split()).take(2)
查看输出结果:
输出结果: [['213.158.179.231', '-', '24704', '[03/Mar/2014:00:00:00', '+0100]', '"GET', '/meetoo_1.0_sales.html', 'HTTP/1.0"', '200', '1567', '"http://www.loudacre.com"', '"Loudacre', 'Mobile', 'Browser', 'MeeToo', '2.0"'], ['213.158.179.231', '-', '24704', '[03/Mar/2014:00:00:00', '+0100]', '"GET', '/theme.css', 'HTTP/1.0"', '200', '15447', '"http://www.loudacre.com"', '"Loudacre', 'Mobile', 'Browser', 'MeeToo', '2.0"']]
从上面的输出结果中可以看出,我们将日志文件按空格拆了之后,IP地址,usrid,访问时间,地址信息,组成了一个新的列表。现在取出前10条记录的IP地址字段。
myrdd.map(lambda s:s.split()[0]).take(10)
查看部分输出结果:
['213.158.179.231', '213.158.179.231', '213.158.179.231', '213.158.179.231', '14.7.25.113', '14.7.25.113', '14.7.25.113', '14.7.25.113', '182.66.255.22', '182.66.255.22']
尽管take和collect操作方式可以帮助我们查看RDD中的内容,但是有时候其输出的可读性较差,所以我们可以通过迭代方式查看。注:(由于数据集已超过百万级,请小伙伴们在单台计算机下执行以下命令时,谨慎!!!!)
for ip in myrdd.map(lambda s:s.split()[0]).collect(): print(ip)
部分输出结果:
213.158.179.231 213.158.179.231 213.158.179.231 213.158.179.231 14.7.25.113 14.7.25.113 14.7.25.113 14.7.25.113 182.66.255.22 182.66.255.22 30.94.103.67 30.94.103.67 160.91.247.104 160.91.247.104
操作二、使用Pair RDDS 去Join两个数据集。
在先前使用的weblogs数据集中包含了每一天所产生的日志,所以在下面的练习中我们选择部分进行分析。
1、 对选取的数据集中的userid进行统计分析,统计userid出现的次数
file="file:///home/training/training_materials/data/weblogs/*6.log" myrdd=sc.textFile(file) myrdd.map(lambda l:(l.split()[2],1)).reduceByKey(lambda x,y:x+y).take(10)
查看输出结果:
输出结果:
[('35521', 6),
('19472', 8),
('63625', 4),
('63177', 2),
('24789', 4),
('66481', 4),
('96168', 2),
('61988', 2),
('67067', 2),
('109319', 6)]
如果有时候我们想打输出结果变成value-key呢?
myrdd.map(lambda l:(l.split()[2],1)).reduceByKey(lambda x,y:x+y).map(lambda x:(x[1],x[0])).take(10)
输出结果: [(6, '35521'), (8, '19472'), (4, '63625'), (2, '63177'), (4, '24789'), (4, '66481'), (2, '96168'), (2, '61988'), (2, '67067'), (6, '109319')]
1、 创建一个RDD,提取日志中的ip和usreid字段,对相同id的不同ips进行汇总统计
myrdd.map(lambda l:(l.split()[2],l.split()[0])).distinct().groupByKey().take(10)
执行结果如下:
[('35521', <pyspark.resultiterable.ResultIterable at 0x7f2770057160>),
('19472', <pyspark.resultiterable.ResultIterable at 0x7f2770057320>),
('63177', <pyspark.resultiterable.ResultIterable at 0x7f2770057828>),
此时发现urseid是可以读取的,但是对于用户访问过的ip需要迭代才能查看
for (usreid,ips) in data.collect(): msg='person has the same post number {0}'.center(100,'=').format(usreid) print(msg) print(usreid) for ip in ips: print("\t"+ip)
执行结果: ================================person has the same post number 35521================================= 35521 160.16.102.247 214.79.71.112 210.241.247.198 ================================person has the same post number 19472================================= 19472 43.233.80.155 204.176.198.31 1.73.115.79 154.203.235.227
代码还是太长了,短点儿吧!!!
for(usreid,ips) in myrdd.map(lambda l:(l.split()[2],l.split()[0])).distinct().groupByKey().collect(): msg='person has the same post number {0}'.center(100,'=').format(usreid) print(msg) print(usreid) for ip in ips: print("\t"+ip)
执行结果一样
3、 对第二个数据集进行操作,取出usreid,姓和名
myrdd2=sc.textFile("file:///home/training/training_materials/data/static_data/accounts") myrdd2.take(10)
部分运行结果: ['32441,2012-07-06 12:35:29.0,\\N,Peter,Zachary,1891 Jessie Street,Long Beach,CA,90743,5628719002,2014-03-18 13:30:46.0,2014-03-18 13:30:46.0', '32442,2012-08-18 00:08:07.0,\\N,Duane,Ruiz,1023 Simpson Street,Pasadena,CA,91051,6262472463,2014-03-18 13:30:46.0,2014-03-18 13:30:46.0', '32443,2012-09-09 04:15:32.0,\\N,Desiree,Beall,4830 Davis Place,Reno,NV,89468,7758006922,2014-03-18 13:30:46.0,2014-03-18 13:30:46.0',
取出我们需要的字段
data=myrdd2.map(lambda x:x.split(',')).map(lambda y:(y[0],y[3],y[4])).take(10)
结果:
[('32441', 'Peter', 'Zachary'),
('32442', 'Duane', 'Ruiz'),
('32443', 'Desiree', 'Beall'),
('32444', 'Molly', 'Pinder'),
('32445', 'Melissa', 'Carlson'),
('32446', 'Oliver', 'Olson'),
('32447', 'Ben', 'McFarlane'),
('32448', 'Barbara', 'McClure'),
('32449', 'Christina', 'Smith'),
('32450', 'Jake', 'Weber')]
对两个数据集进行join操作
ydata=(myrdd.map(lambda l:(l.split()[2],1)).reduceByKey(lambda x,y:x+y)).join(data2) mydata.take(10)
for (usreid,(ts,names)) in mydata.collect(): print(usreid ,ts,names)
运行部分结果: 19108 6 Penny 94430 2 Tamala 118 134 Charles 89848 2 Patricia 25804 4 Crystal 85055 8 Fred 22867 2 Walter 1129 2 Ryan 96543 6 Alfred 41135 2 Joanne 88561 2 Daniel
4、 对第二个数据集进行操作,取出分别取出第8,第3,4字段进行分级排序超作
abc=myrdd2.map(lambda l:(l.split(',')[8],(l.split(',')[3],l.split(',')[4]))).groupByKey().distinct() abc.take(10)
运行部分结果:
[('94515', <pyspark.resultiterable.ResultIterable at 0x7f3d03231a90>),
('94286', <pyspark.resultiterable.ResultIterable at 0x7f3d03231588>),
('89727', <pyspark.resultiterable.ResultIterable at 0x7f3d03231b00>),
('85605', <pyspark.resultiterable.ResultIterable at 0x7f3d032316a0>),
('85112', <pyspark.resultiterable.ResultIterable at 0x7f3d03352c18>),
('94416', <pyspark.resultiterable.ResultIterable at 0x7f3d033affd0>),
('90831', <pyspark.resultiterable.ResultIterable at 0x7f3d033af630>),
('85334', <pyspark.resultiterable.ResultIterable at 0x7f3d03352da0>),
('96029', <pyspark.resultiterable.ResultIterable at 0x7f3d0339d278>),
('94915', <pyspark.resultiterable.ResultIterable at 0x7f3d03543128>)]
进行遍历:
for (k,vs) in abc.take(100): msg='person has the same post number {0}'.center(100,'=').format(k) print(msg) print('-----'+k) for v in vs: print('\t'+v[0],v[1])
运行部分结果:

操作三,对特殊文档的操作需要得到如下结果

sc.textFile("file:///home/training/training_materials/data/devicestatus.txt").take(100)
执行结果:

我们发现在此数据集中,单行数据的分割符是相同的,所以我们在对数据进行处理时可以按照其规律,进行编码。
devstatus=sc.textFile("file:///home/training/training_materials/data/devicestatus.txt") cleanstatus = devstatus.map(lambda line: line.split(line[19:20])).filter(lambda values: len(values) == 14) cleanstatus.take(3)
部分运行结果: [['2014-03-15:10:10:20', 'Sorrento F41L', '8cc3b47e-bd01-4482-b500-28f2342679af', '7', '24', '39', 'enabled', 'disabled', 'connected', '55', '67', '12', '33.6894754264', '-117.543308253'],
取出我们需要的字段
devicedata = cleanstatus.map(lambda values: (values[0], values[1].split(' ')[0], values[2], values[12], values[13])) evicedata.take(3)
部分运行结果:
[('2014-03-15:10:10:20',
'Sorrento',
'8cc3b47e-bd01-4482-b500-28f2342679af',
'33.6894754264',
'-117.543308253'),
('2014-03-15:10:10:20',
'MeeToo',
'ef8c7564-0a1a-4650-a655-c8bbd5f8f943',
'37.4321088904',
'-121.485029632'),
('2014-03-15:10:10:20',
'MeeToo',
'23eba027-b95a-4729-9a4b-a3cca51c5548',
'39.4378908349',
'-120.938978486')]
把新生成的数据转存到其他位置
devicedata.map(lambda values: ','.join(values)).saveAsTextFile("/loudacre/devicestatus_etl")
操作四,对xml格式log文档的操作,实验要求取出<account-number>和<model>标签中的值。结果如图所示:
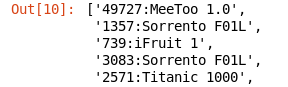
1、通过linux终端查看activations数据集。

查看某天的xml数据
import xml.etree.ElementTree as ElementTree def getActivation(s): fileTree=ElementTree.fromstring(s) return fileTree.getiterator('activation') def getAccount_number(b): data=b.find('account-number').text return data def getModel(c): return c.find('model').text file=file:///home/training/training_materials/data/activations/*.xml myrdd=sc.wholeTextFiles(file) data=myrdd.flatMap(lambda l:getActivation(l[1])).map(lambda s:getAccount_number(s)+":"+getModel(s)) data.take(100)
部分输出结果:
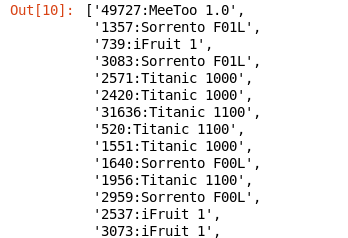
将提取的数据存放成新的文件
data.saveAsTextFile('file:///home/training/training_materials/data/activations/test')
操作五:利用正则表达式提取access.log文件中的ip地址、时间戳、请求头、cookie值
原文件部分数据如下:

from pyspark.sql import SparkSession from pyspark.sql.functions import split,regexp_extract spark=SparkSession.builder.appName("First Spark DataFrame").getOrCreate() file="file:///home/training/training_materials/data/access.log" df=spark.read.text(file) df.select(regexp_extract('value',r'^([\d.]+)',1).alias('ipaddr'),regexp_extract('value',r'\[(.*?)\]',1).alias('timestamp'), regexp_extract('value',r'\"(.*?)\"',1).alias('http'),regexp_extract('value',r'.*\d+ \"(.*?)\"',1).alias('reff'), regexp_extract('value',r'.*\"SESSIONID=(\d+)\"',1).cast('bigint').alias('cookie')).show()
运行结果:

操作五,用spark 程序实现一个校验空行个数的程序
方法一:
sc.textFile(“file:///home/training/training_materials/data/2014-03-15.log”) map(lambda x:(len(x)==0,1)).reduceByKey(lambda x,y:x+y).take(2)
代码解析:1、创建rdd;2、对rdd的每一个recode进行检索,通过pythen中len()方法,去判断每一行是不是为空,如果为空返回True,不为空返回False;3、利用reduceByKey()进行统计。4、因为结果集中只有两种情况,所以我们取出2条就好了。
执行结果
[(False, 7097), (True, 9)]
Linux终端下执行结果
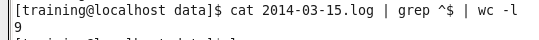
方法二:
用spark累加器实现
sum =sc.accumulator(0) def blankline(x): global sum if len(x)==0: sum+=1 return sum sc.textFile("file:///home/training/training_materials/data/2014-03-15.log").foreach(blankline) print(sum)
执行结果:
9
在linux终端下用spark-submit提交,并对JVM进行调优

文件blankline.py中的代码
from pyspark import SparkContext sc=SparkContext() file="file:///home/training/training_materials/data/2014-03-15.log" myrdd=sc.textFile(file) xx=myrdd.map(lambda x:(len(x)==0,1)).reduceByKey(lambda x,y:x+y).collect() print(xx)
在linux终端下执行
spark-submit --conf spark.eventlog.enabled=false --conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" blankline.py
执行结果:
17/03/28 01:52:11 INFO scheduler.DAGScheduler: Job 0 finished: collect at /home/training/blankline.py:7, took 1.534097 s
[(False, 7097), (True, 9)]
17/03/28 01:52:12 INFO spark.SparkContext: Invoking stop() from shutdown hook
17/03/28 01:52:12 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
写博客没有多久,请多多指教,其余的操作将后续更新!thanks!!!!!!!!!!

