

🐒 进化计算
© Andrew Kirillov 2006, Conmajia 2012
安德鲁·基里洛夫 著,Conmajia 译
作者简介:

安德鲁·基里洛夫是一名高级软件工程师。安德鲁是著名的图像、数学、神经网络编程框架 AForge.NET 的作者。
原文链接:点击访问
演示DEMO:点击下载
源代码:点击下载
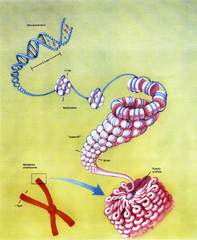

简介
人们在进化计算领域进行了非常多的研究工作,总结出了大量的进化算法。研究者对这些方法进行了广泛的钻研,并尝试将它们应用到众多不同领域的任务中。有一个众所周知的事实,那就是许多科研问题使用传统方法,都不可能在一个合理的时间范围内得出准确的结果。也有许多问题没有一个形式化的解决方法,这使得人们很难——甚至是不可能——用传统方法来解决这些问题。一个典型的例子就是“旅行商问题”(Traveling Salesman Problem,TSP)。TSP要求在给定数量的城市之间找到一条最短的路径,使得旅行商能访问所有的城市,并且每个城市只访问一次,最后回到出发的城市。对于这样的问题,很多时候我们可以使用进化计算方法,在可以接受的时间范围内得到一个较好的解。使用进化计算方法,并不能保证得到问题的精确解,而是找到一个最接近最佳答案的“足够好”的解。这就是为什么这类方法越来越多的被用于解决很多不同的问题——这些问题往往是不能(或者很难)用传统方法求解的。
本文讨论了一个用C#实现的进化计算类库。该类库实现了数个流行的进化算法,如遗传算法(GA)、遗传编程(GP)和基因表达式编程(GEP)。该类库可以用于求解多种不同的实际问题,其用法通过以下4个例子进行演示:
- 函数优化
- 符号回归计算
- 时间序列预测
- 旅行商问题
该类库的设计思想是保证其灵活性和可重用性,以便能将其用于解决不同的问题。本文不会讨论进化算法的详细内容,取而代之地,本文简要介绍了相关的算法,并在文后提供了一系列参考资料,以便感兴趣的读者深入研究。
进化计算
遗传算法的历史始于20世纪60年代,John Holland在他的工作中首先提出了基于进化的遗传算法(GA)思想。从那时开始,许多研究者开始加入到进化计算领域,由此产生了很多不同的算法[1]。这些算法被广泛地研究,并应用于大量不同问题求解。到了今时今日,人们仍在各自领域中继续研究这些算法,也使得这些算法能够解决更多的新的问题。
GA算法基于达尔文关于生物繁殖和遗传的自然选择法则,如交叉(重组)和变异。该方法处理一定量种群的个体(染色体),其中每一个都编码有问题的可能解。GA染色体是由固定长度的串组成(一组二进制位、数字,等等),这使得遗传算子实现起来非常简单。染色体初始化数量是随机的,但之后就开始用交叉、变异、选择等遗传算子进行进化。
最简单的交叉算子是单点交叉——在两个染色体中随机选择一点进行交叉(交换剩余部分):
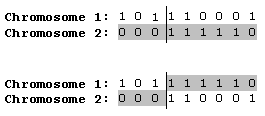
另一个著名的交叉算子是两点交叉——选择染色体中两个随机点,并交换两点间的部分。事实上,根据求解的问题不同,除了这两种常用的交叉算子外,GA算法中还有很多其他的交叉算子。需要注意的一个问题是,上述两种经典交叉算子完全不能直接应用于问题求解中,应用时需要使用它们各自针对不同问题的特定变体。
变异算子处理单一的染色体,仅是简单地随机改变该染色体。单点变异算子只改变染色体中的一个基因:
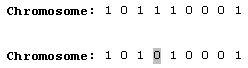
如同交叉算子,变异算子同样拥有大量针对特定问题和类型的变体。
所以,在初始人口创建之后,GA算法的每次迭代都包括有以下步骤:
- 交叉——选择随机个体并应用交叉算子
- 变异——选择随机个体并对其应用变异算子
- 计算每个个体的适合度
- 选择——为下一代选择个体
该算法可能在指定数量的迭代之后,或是找到一个足够好的解之后停止。计算染色体的适合度和具体问题相关——适合度表示该染色体“好”的程度。染色体适合度越高,表示其越“好”,也就越有可能被选入下一代(生存几率更高——译注)。
有几种选择算子,其主要思想就是给予适合度高的优秀个体更多机会来选择个体进入下一代。其中最为著名的是Elitism算法(精英算法)——选择一定数量的最优染色体进入下一代。
1992年John Koza提出了一项具有重大意义的新成果——遗传编程(GP)[2]。在GP中,单个人口成员(染色体)不再像GA中那样,是编码了问题可能解的固定长度线性字符串,而是可以执行并求解问题的程序。这些程序在GP中被表示成不同大小和形状的解析树,这样使得这些方法可以更加灵活地应用于求解多种问题。染色体的表现差异可以说是GP算法和GA算法最主要甚至是唯一的差别之处。GP算法中,基本的达尔文适者生存思想仍然相同,但在变异算子、交叉算子以及适合度计算方面则和GA算法相比,有一定的变化。在GP算法中,变异算子并非通过改变某一个体的基因实现,而是重新生成一个树节点,以此作为染色体树上某一子树。交叉算子也是如此——染色体互相交换子树(可能在尺寸、形状上均不相同),而非交换同样长度的两部分。然而,仍旧需要对染色体进行相同的检查以确保它们不会生长得太长。
在GP算法中计算适合度,并不是仅仅将染色体作为参数传递给某个计算适合度的算法就完了,而是执行代表染色体的程序,然后根据程序输出来计算适合度。
2001年Candida Ferreira介绍了另一种被称为基因表达式编程(GEP)的方法[3]。该方法和遗传编程以及遗传算法均有相似之处。一方面,该方法仍旧采用输出求解结果的程序操作,就如GP算法一般。但在程序的表现上,GEP有所不同。染色体在该方法中不再表示成树,而是和GA算法一样采用固定长度的线性表示。这种染色体表现形式上的变化,使得类似变异和交叉这样的遗传算子更加简单。但是会使用一些很小的约束来确保算子的安全。
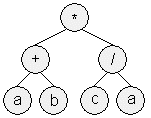 * + / a b c a
* + / a b c a
染色体表现形式 (a) GP算法 (b) GEP算法
上图展示了GP算法和GEP算法中染色体的不同表现形式。两个染色体都编码了相同的程序——算数表达式(a+b)*(c/a)。GP算法中是以解析树的形式表示的,而GEP算法则以从左上到右下的顺序线性表示的解析字符串。可以很容易的把GEP字符串转换回一颗解析树,然后仍按照从左上到右下的顺序加以填充,并确定每个函数的参数数量。
使用类库
类库基于灵活、可重用的思想设计,可以用于求解多种问题。类库的代码不依赖于任何特定问题,而是实现了进化计算以及遗传算法、遗传编程和基因表达式编程等相关算法的通用概念。进化计算中的实体如人口、染色体、选择方法和适合度函数是作为单独的类(Class)实现的,以便能方便的进行组合来求解特定问题。大多数情况下,类库的使用者只需要为其待求解问题定义一个适合度计算函数,然后定义染色体类型、选择算法和一些其他参数,如人口大小、变异和交叉概率,等等。如果待求解问题需要一些特殊的染色体或遗传算子的变体,如变异和交叉,使用者可以通过实现IChromosome接口实现自己的染色体类,或是通过继承已有的染色体类达到此目的。选择算法和适合度计算函数与此类似——通过实现ISelectionMethod和IFitnessFunction接口创建自定义选择算法和适合度计算函数。使用者通过上述方法创建的自定义类,扩展了类库功能,和原有类一起,用于求解特定问题。

为了演示类库的使用方法,下面给出4个使用不同进化计算算法的例子:
- 函数优化(遗传算法)
- 符号回归计算(遗传编程和基因表达式编程)
- 时间序列预测(遗传编程和基因表达式编程)
- 旅行商问题(遗传算法)
函数优化
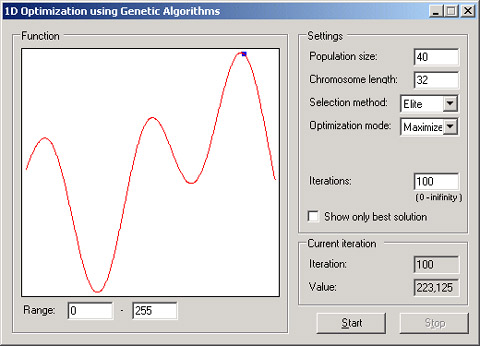
函数优化是演示遗传算法的经典问题。使用本文介绍的类库求解该类问题,你只需要在优化范围内定义一个优化函数,然后创建一个遗传种群(人口——译注),指定进化算法所需的参数:
1 // 定义优化函数 2 public class UserFunction : OptimizationFunction1D 3 { 4 public UserFunction( ) : 5 base( new DoubleRange( 0, 255 ) ) { } 6 7 public override double OptimizationFunction( double x ) 8 { 9 return Math.Cos( x / 23 ) * Math.Sin( x / 50 ) + 2; 10 } 11 } 12 ... 13 // 创建遗传种群 14 Population population = new Population( 40, 15 new BinaryChromosome( 32 ), 16 new UserFunction( ), 17 new EliteSelection( ) ); 18 // 运行一代 19 population.RunEpoch( );
上面的例子创建了一个数量为40的染色体种群,每个染色体是长度为32bit的二进制串,使用了针对一维的精英选择方法和适合度计算函数。在上述(以及其他)的例子中,没有针对遗传算法(或其他某种算法)的明确的区别,他们之间具有很多共同之处。比如,种群创建的方法在所有本文提到的遗传算法中都是相同的。染色体是使用何种类型算法的决定因素,它定义了问题解的表现形式以及遗传算子的实现方式。
符号回归计算(近似解)
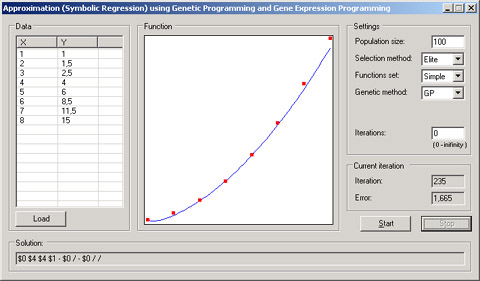
符号回归问题的目的是找到针对输入数据的最佳近似函数。通常人们利用遗传编程或基因表达式编程算法来解决这类问题。使用这两种算法都可以找到一个函数,该函数以X值和一些常数为参数,输出一个接近真实值的Y值。
实际解题的代码和上一个例子的代码非常相似,其中种群类和选择方法类都是一样的。很显然,由于染色体不同,这两个例子唯一不同的部分就是适合度计算函数。在解题时,如果使用遗传编程算法,则在代码中用GPTreeChromosome类创建染色体。如果使用基因表达式编程算法,则用GEPChromosome类。
1 // 需要近似求解的函数(输入数据) 2 double[,] data = new double[5, 2] { 3 {1, 1}, {2, 3}, {3, 6}, {4, 10}, {5, 15} }; 4 // 创建种群 5 Population population = new Population( 100, 6 new GPTreeChromosome( new SimpleGeneFunction( 6 ) ), 7 new SymbolicRegressionFitness( data, new double[] { 1, 2, 3, 5, 7 } ), 8 new EliteSelection( ), 9 0.1 ); 10 // 运行一代 11 population.RunEpoch( );
在上面的例子中,需要近似求解的函数是用二位数组来表示(X,Y)值对的。一个有趣的现象是,上面例子中Population类构造函数的最后一个参数——该参数的值表示10%(即0.1——译注)的新种群由随机的染色体组成,而剩余的90%则为当前代的成员。
时间序列预测

时间序列预测问题创建了一个基于函数历史值来预测函数未来值的模型。为了完成这个任务,使用训练数据来创建(训练)该模型,直到其开始基于训练集产生符合要求的结果。该模型用于预测函数未来值。
1 // 需要预测的时间序列 2 double[] data = new double[13] { 1, 2, 4, 7, 11, 16, 22, 29, 37, 46, 56, 67, 79 }; 3 // 常数 4 double[] constants = new double[10] { 1, 2, 3, 5, 7, 11, 13, 17, 19, 23 }; 5 // 滑动窗大小 6 int windowSize = 5; 7 // 创建种群 8 Population population = new Population( 100, 9 new GPTreeChromosome( new SimpleGeneFunction( windowSize + constants.Length ) ), 10 new TimeSeriesPredictionFitness( data, windowSize, 1, constants ), 11 new EliteSelection( ) ); 12 // 运行一代 13 population.RunEpoch( );
可以看到,时间序列预测问题的代码几乎和符号回归计算问题代码完全一致——只是修改了适合度计算函数和算法的一些参数。这说明本文提出的类库使用简单,具有高度可重用性。
旅行商问题
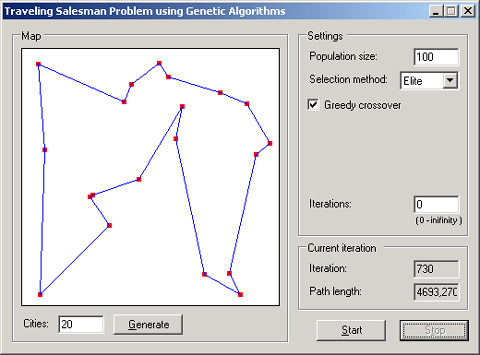
旅行商问题目标是在城市之间找到一条最短路径,使得旅行商从一个城市出发,不重复地访问每一个城市,最后回到起点。这类问题也被称为NP困难问题。如果使用传统方法进行求解,在城市数量较大的情况下,解题可能花费极长的时间。然而,可以使用遗传算法,在合理的时间范围内得到该问题的一个相当接近准确解的结果。
1 // 创建种群 2 Population population = new Population( populationSize, 3 new PermutationChromosome( citiesCount ), 4 new TSPFitnessFunction( map ), 5 new EliteSelection( ) 6 );
值得注意的是,作为类库的组成部分,PermutationChromosome类要求创建新的适合度计算函数(TSPFitnessFunction)并使用现有代码其余部分来求解新的问题。然而该算法的性能还有进一步提高的余地。默认的通用PermutationChromosome类可以得到问题解,但是使用从该类派生的新类并重写交叉算子可以获得更好的性能。自定义的TSPChromosome类(参考源代码)实现了所谓的贪婪交叉算法,允许在更短时间内找到更好的问题解。
多年来,遗传算法总是能为旅行商问题解出最佳的结果。旅行商问题非常有名且流行,每年还会专门举办求解该问题的竞赛,以期找到更好的算法。众所周知,20世纪90年代末,出现了另一种性能更好的旅行商问题求解算法。新算法基于蚁群思想,同样来自人工智能领域的研究成果。(参考蚂蚁系统和蚁群系统算法)
结论
以上的4个例子展示了本文类库的最初目标——灵活、可扩展、可重用,并且使用简单。尽管不能覆盖进化计算的各个方面,也仍有许多工作需要完善,但是该类库已经可以用于许多不同问题的求解,而且非常容易就可以扩展该类库以求解新的问题。通过研究设计该类库,我不禁对进化算法有了更深入的了解,而且帮助我更好的研究了遗传编程和基因表达式编程算法。
参考文献
[1] Ajith Abraham, Nadia Nedjah and Luiza de Macedo Mourelle, Evolutionary Computation: from Genetic Algorithms to Genetic Programming // Genetic Systems Programming: Theory and Experiences, volume 13 of Studies in Computational Intelligence, pages 1-20. Springer, Germany, 2006.
[2] John R. Koza, Genetic Programming // Version 2 – Submitted August 18, 1997 for Encyclopedia of Computer Science and Technology.
[3] Ferreira, Gene Expression Programming: A new adaptive algorithm for solving problems // Complex Systems, Vol. 13, No. 2, pp. 87–129, 2001.
历史
[4.8.2012] - 完成翻译
[2.8.2012] - 开始翻译本文
[16.10.2006] - 发表本文
许可证
本文及其附属的任何源代码和文件均以GNU General Public License(GPLv3)许可证发布。
(全文完)
© Andrew Kirillov 2006, Conmajia 2012
if(jQuery('#no-reward').text() == 'true') jQuery('.bottom-reward').addClass('hidden');

