
集群故障处理之处理思路以及听诊三板斧(三十三)
前言
本篇主要分享一些处理故障和问题绝招,比如听诊三板斧:
1)查看日志
2)查看资源详情和事件
3)查看资源配置(YAML)
如果还是不太好分析,那就祭出神器——kubectl-debug。
最后,仅需根据问题对症下药即可。
目录
-
进一步诊断分析——听诊三板斧
-
容器调测
-
对症下药
进一步诊断分析——听诊三板斧
在初诊阶段,我们往往只能获得一些表面的信息,比如节点挂了,Pod崩溃了,网络不通等等,这时,我们需要根据我们初诊的方向和范围使用一些工具以及结合日志进行具体的诊断。
这里笔者推崇听诊三板斧:
-
查看日志
-
查看资源详情和事件
-
查看资源配置
查看日志
大部分情况下,想要获得具体的病因,查看日志是最为直接的方式,因此,我们需要学会如何查看日志。
1.使用journalctl查看服务日志
主流的Linux系统基本上都采用Systemd来集中管理和配置系统,如果使用的是Systemd机制,我们可以使用journalctl命令来查看服务日志:
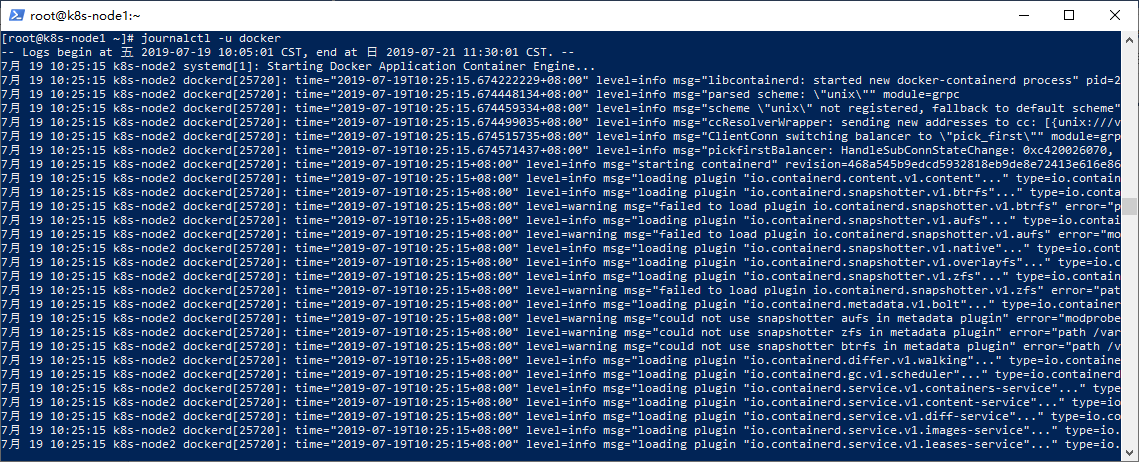
比如docker:
journalctl -u docker
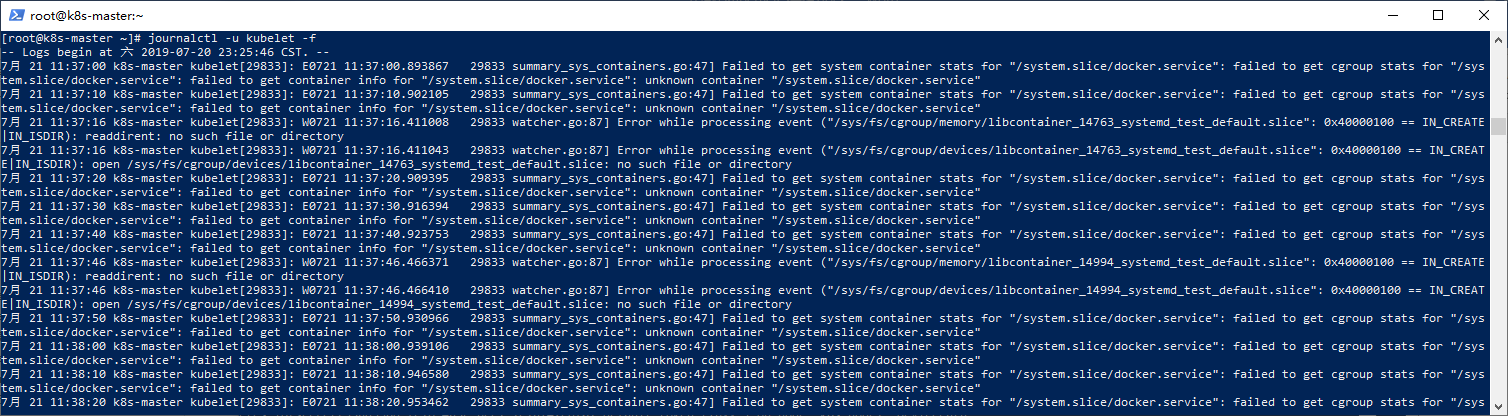
查看并追踪kubelet的日志:
journalctl -u kubelet -f
2.使用“kubectl logs”查看容器日志
我们的应用运行在Pod之中,以及k8s的一些组件,例如kube-apiserver、coredns、etcd、kube-controller-manager、kube-proxy、kube-scheduler等,也都运行在Pod之中(静态Pod),那么如何查看这些组件以及应用的日志呢?这里就要用到前面提到的“kubectl logs”命令。
语法如下所示:
kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER] [options]
主要的参数说明如下表所示:
|
参数 |
说明 |
|
-f, --follow |
是否持续追踪日志,默认为false,指定了之后会持续输出日志。 |
|
-p, --previous |
输出Pod中曾经运行过,但目前已终止的容器的日志。 |
|
-c, --container |
容器名称。 |
|
--since |
仅返回相对时间范围(如5s、2m或3h)内的日志。默认返回所有日志。 |
|
--since-time |
仅返回指定时间之后的日志,默认返回所有。只能同时使用since和since-time中的一种。 |
|
--tail |
要显示的最新的日志条数,默认为-1,显示所有。 |
|
--timestamps |
输出的日志中包含时间戳。 |
|
-l, --selector |
使用Label选择器过滤 |
了解了主要的参数和说明,我们查看几个示例:
-
查看Pod“mssql-58b6bff865-xdxx8”的日志
kubectl logs mssql-58b6bff865-xdxx8
-
查看24小时内的日志
kubectl logs mssql-58b6bff865-xdxx8 --since 24h
-
根据Pod标签查看日志
kubectl logs -lapp=mssql
-
查看指定命名空间下的Pod日志(注意系统组件的命名空间为“kube-system”)
kubectl logs kube-apiserver-k8s-master -f -n kube-system
查看资源实例详情
除了查看日志之外,有时候我们需要查看资源实例详情以帮助我们解决问题。这就需要用到我们上面提到过的“kubectl describe”命令。
“kubectl describe”命令用于查看一个或多个资源的详细情况,包括相关资源和事件。语法如下所示:
kubectl describe (-f FILENAME | TYPE [NAME_PREFIX | -l label] | TYPE/NAME)
主要的参数说明如下表所示:
|
参数 |
说明 |
|
-A,--all-namespaces |
查看所有命名空间下的资源 |
|
-f, --filename |
根据资源描述文件、目录、Url来查看 |
|
-R, --recursive |
以递归方式查看-f指定的所有资源 |
|
-l, --selector |
使用Label选择器过滤 |
|
--show-events |
显示事件 |
了解了主要的参数和说明,我们通过示例来进行解说:
1.查看节点
查看指定节点:
kubectl describe nodes k8s-node1
查看所有节点:
kubectl describe nodes
查看指定节点以及事件:
kubectl describe nodes k8s-node1--show-events
注意,如果Node状态为NotReady,通过查看节点事件可以有助于我们排查问题。
2.查看Pod
查看指定Pod:
kubectl describe pods gitlab-84754bd77f-7tqcb
查看指定文件描述的所有资源
kubectl describe -f teamcity.yaml
查看资源以及配置
很多应用的出错往往都是我们的配置导致的,那么如何查看已部署资源的配置呢?这就需要用到强大的“kubectl get”命令了。
“kubectl get”命令我们经常使用,在这之前我们经常用其来查询资源,那么如何使用它来查看资源配置呢?我们先来看其语法:
kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columns-file=...|go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...] (TYPE[.VERSION][.GROUP] [NAME | -l label] | TYPE[.VERSION][.GROUP]/NAME ...) [flags] [options]
如上述语法所示,“kubectl get”拥有强大的格式化输出能力,支持“json”、“yaml”等,在上面的kubectl一节中我们已经讲解过了,这里我们就主要用到“-o”来查看资源配置,具体如以下实例所示:
-
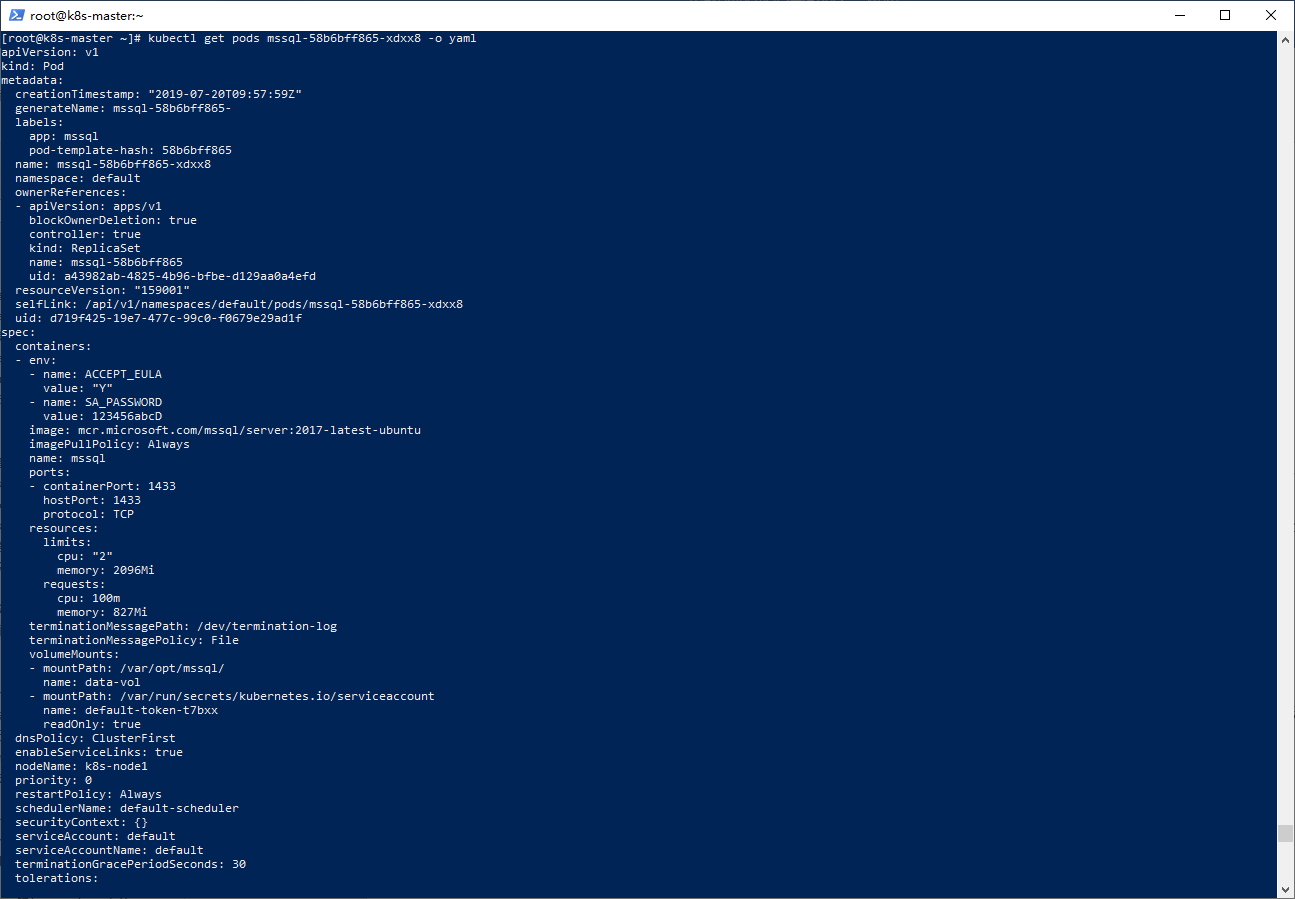
查看指定Pod配置
kubectl get pods mssql-58b6bff865-xdxx8 -o yaml
-
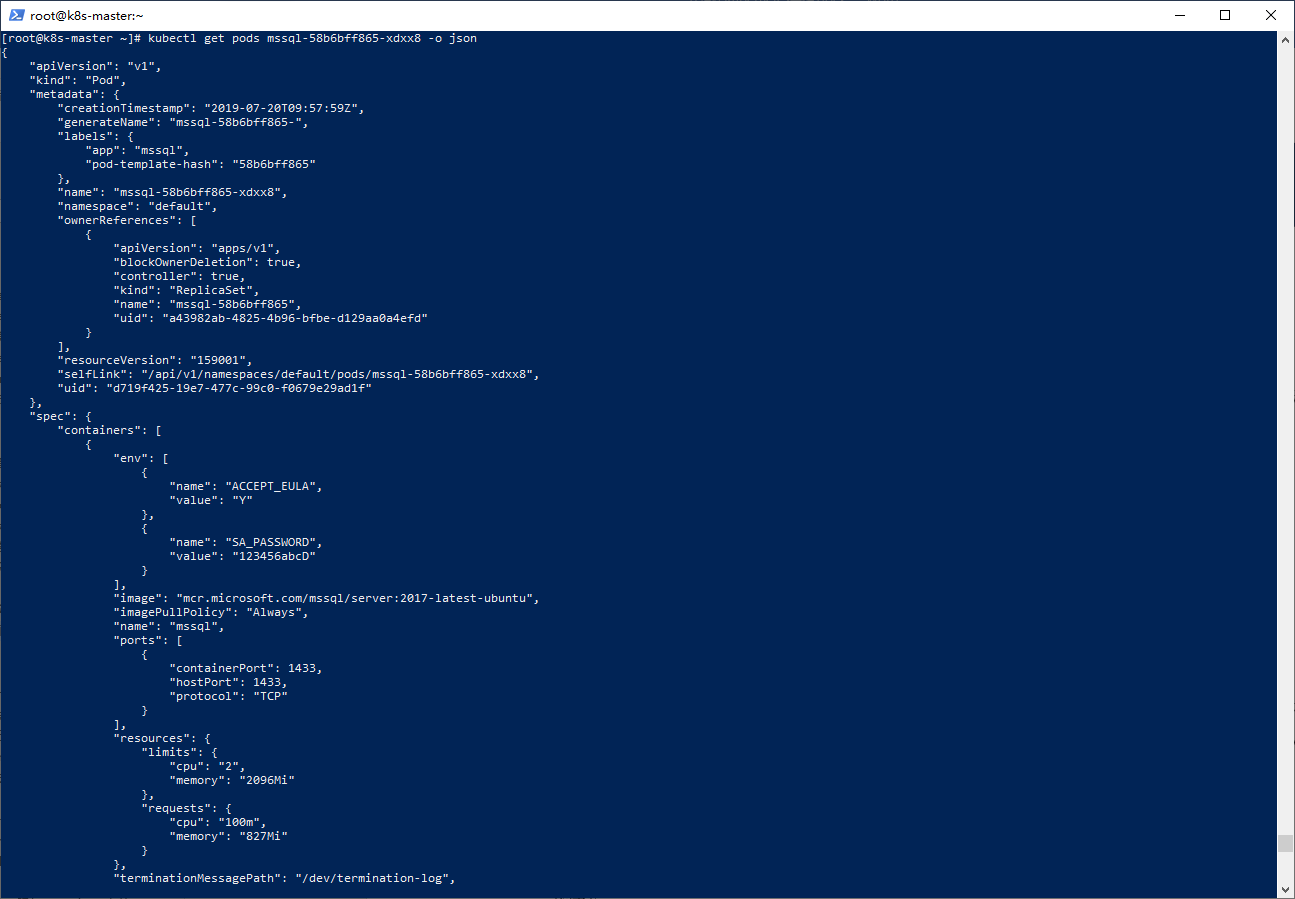
yaml奴家看不惯,想看JSON版的:
-
想看所有的:
kubectl get pods -o json
-
查看服务配置
kubectl get svc mssql -o yaml
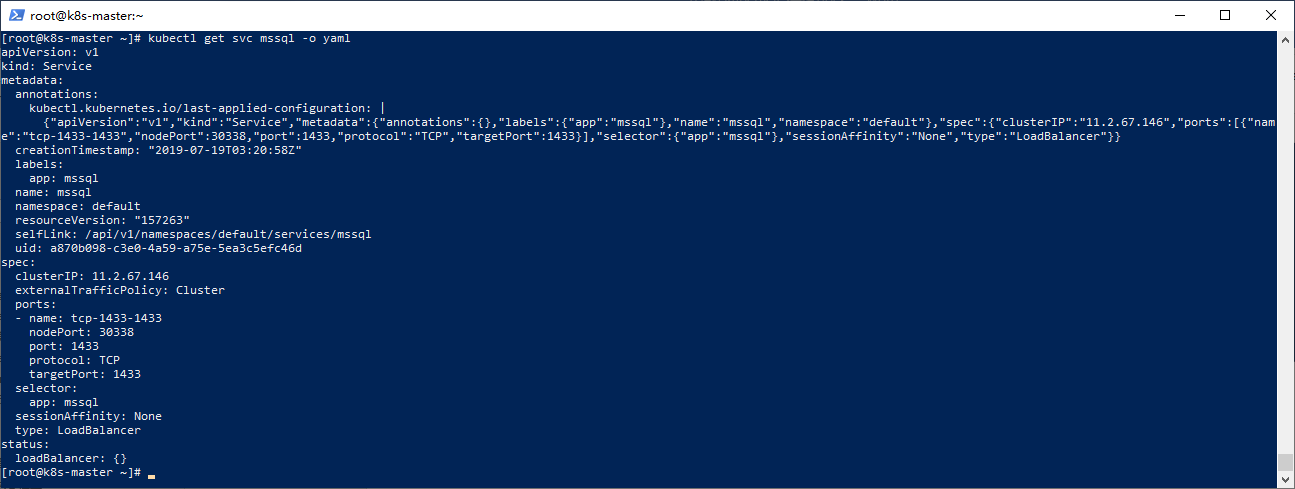
-
查看部署(deployment)配置
kubectl get deployments mssql -o yaml

注意:“-o”用得好,再也不用担心yaml不会写了。
容器调测
有时候光看日志还没发给出具体诊断,可能得动刀子或者进行进一步检查调测才能论证我们的猜想。笔者推荐使用以下方案:
使用“kubectl exec”进入运行中的容器进行调测
我们可以使用“kubectl exec”进入运行中的容器进行调测。这个命令和“docker exec”很类似,具体语法如下所示:
kubectl exec (POD | TYPE/NAME) [-c CONTAINER] [flags] -- COMMAND [args...] [options]
主要的参数说明如下表所示:
|
参数 |
说明 |
|
-c, --container |
指定容器名称 |
|
-i, --stdin |
启用标准输入 |
|
--tty , -t |
分配伪TTY(终端设备) |
接下来我们结合示例说明:
-
进入容器查看配置
kubectl exec mssql-58b6bff865-xdxx8 -- cat /etc/resolv.conf

-
进入容器分配终端并将标准输入流转到bash
kubectl exec mssql-58b6bff865-xdxx8 -it bash

如上图所示,我们进入MSSQL数据库的容器之后,使用sqlcmd工具执行了一个查询。这块操作如有疑问,请参阅数据库容器化一节。
使用kubectl-debug工具调测容器
kubectl-debug 是一个简单的开源的kubectl 插件, 可以帮助我们便捷地进行 Kubernetes 上的 Pod 排障诊断,背后做的事情很简单: 在运行中的 Pod 上额外起一个新容器, 并将新容器加入到目标容器的 pid, network, user以及 ipc namespace中, 这时我们就可以在新容器中直接用 netstat, tcpdump 这些熟悉的工具来诊断和解决问题了, 而旧容器可以保持最小化, 不需要预装任何额外的排障工具.
GitHub地址:https://github.com/aylei/kubectl-debug
安装脚本如下(CentOS 7):
export PLUGIN_VERSION=0.1.1 # linux x86_64,下载文件 curl -Lo kubectl-debug.tar.gz https://github.com/aylei/kubectl-debug/releases/download/v${PLUGIN_VERSION}/kubectl-debug_${PLUGIN_VERSION}_linux_amd64.tar.gz #解压 tar -zxvf kubectl-debug.tar.gz kubectl-debug #移动到用户的可执行文件目录 sudo mv kubectl-debug /usr/local/bin/
为了调试更快更方便,我们还需安装debug-agent DaemonSet,安装命令如下:
kubectl apply -f https://raw.githubusercontent.com/aylei/kubectl-debug/master/scripts/agent_daemonset.yml
使用起来非常简单,以下是常用的使用示例:
# 输出帮助命令 kubectl debug -h # 启动Debug kubectl debug (POD | NAME) # 假如 Pod 处于 CrashLookBackoff 状态无法连接, 可以复制一个完全相同的 Pod 来进行诊断 kubectl debug (POD | NAME) --fork # 假如 Node 没有公网 IP 或无法直接访问(防火墙等原因), 请使用 port-forward 模式 kubectl debug (POD | NAME) --port-forward --daemonset-ns=kube-system --daemonset-name=debug-agent
接下来,我们使用该工具调试一个已有Pod,如下所示:
kubectl debug teamcity-5997d4fc7f-ldt8w
执行该命令后,会自动拉取相关镜像并创建容器开启tty并进入容器内部,并且自带一些常用工具。这里我们使用nslookup命令来测试Pod内的外网域名(比如xin-lai.com)解析:

如上图所示,这样就不用每次为了调测网络问题、应用问题而且安装各种工具了,费时费力不说,有时候网络不通就比较伤了。
对症下药
根据“听诊”步骤,我们需要获得具体的情报才能对症下药。比如Pod为啥没有调度,是资源(CPU、内存等)不足,还是所有节点均不满足调度要求(比如指定了“nodeName”要求Pod强制调度到某个节点,而该节点宕机)。只有知道了具体原因,我们才能针对情况进行调整和处理,直到解决问题。
一般来说,大家遇到的Pod问题比较多,这里笔者做个经验总结。
-
Pod一直处于Pending状态,经诊断为资源不足
Pending一般情况下表示这个pod没有被调度到一个节点上。通常这是因为资源不足引起的。
解决方案有:
-
添加工作节点
-
移除部分Pod以释放资源
-
降低当前Pod的资源限制
-
Pod一直处于Waiting状态,经诊断为镜像拉取失败
如果一个pod卡在Waiting状态,则表示这个pod已经调试到节点上,但是没有运行起来。
解决方案有:
-
检查网络问题,如果是网络问题,则保障网络通畅,可以考虑使用代理或国际网络(部分域名在国内网络无法访问,比如“k8s.gcr.io”)
-
如果是拉取超时,可以考虑使用镜像加速器(比如使用阿里云或腾讯云提供的镜像加速地址),也可以考虑适当调整超时时间
-
尝试使用docker pull <image>来验证镜像是否可以正常拉取
-
Pod一直处于CrashLoopBackOff状态,经检查为健康检查启动超时而退出
CrashLoopBackOff 状态说明容器曾经启动了,但又异常退出了。通常此Pod的重启次数是大于0的。
解决方案有:
-
重试设置合适的健康检查阈值
-
优化容器性能,提高启动速度
-
关闭健康检查
出处:http://www.cnblogs.com/codelove/
沟通渠道:编程交流群<85318032> 产品交流群<897857351>
如果喜欢作者的文章,请关注【麦扣聊技术】订阅号以便第一时间获得最新内容。本文版权归作者和湖南心莱信息科技有限公司共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
静听鸟语花香,漫赏云卷云舒。


