从高级语言到机器语言
众所周知,计算机中运行的指令是由二进制编码的0和1组成,最早的程序员通过在纸带上打孔来编写程序,有孔表示1,无孔表示0,经过光电扫描输入电脑,这种0和1序列我们称之为机器语言。

0和1看的人头都大了,人们厌烦这种复杂且易出错的编码方式,进而发明了汇编语言,汇编语言只是充当一个助记符的作用,但好歹人们不用写010101010,而是可以用mov、add这种人们一看就知道其含义的符号来书写程序,久而久之,人们在汇编语言的基础上又发展了高级语言,也就是我们现在看到的各种语言,如C、C++、Python等,不论是面向对象的还是面向过程的,都可以归结到高级语言。

人们用高级语言来工作、编程,但机器只识别机器语言,这中间肯定就存在一个转换的过程。这个过程平时在我们编程序的过程中并不会注意,我们常用的编程环境如VS、dev c++、Delphi等这种IDE(集成开发环境)都为我们封装好了一切,只要我们点击运行或构建按钮,源程序就会变成可以在机器上运行的机器代码,而这个被忽略的过程就是我们今天的重点。
我们会以C语言的经典程序HelloWorld作为例子,参考《程序员的自我修养——链接、装载和库》的内容,通过实操为读者一步步展现这个过程的具体步骤。
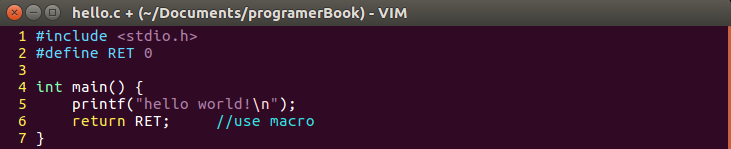
在Linux中,当我们使用GCC来编译该程序时,只需要用最简单的命令
$ gcc hello.c
$ ./a.out
hello world
事实上,这个过程可以分解为4个步骤,分别是预处理(Preprocess)、编译(Compilation)、汇编(Assembly)和链接(Linking)。顺便提一句,转化为机器代码后,当我们运行该程序还涉及到将机器代码加载到内存中执行的过程,这个过程我们称之为装载,但我们本文不进行详细阐述。
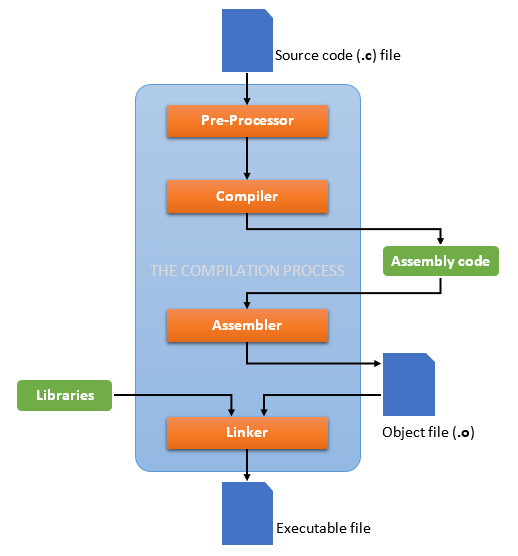
预处理
我们在编写C和C++程序的时候,经常会用到#号开头的语句,如#include、#define、#ifdef等语句,这些语句在预处理过程中就发挥着重要作用。
源文件hello.c和相关的头文件被预编译器cpp预编译为一个后缀为.i的文件
$ gcc -E hello.c -o hello.i
或者
$ cpp hello.c > hello.i
生成结果如下:
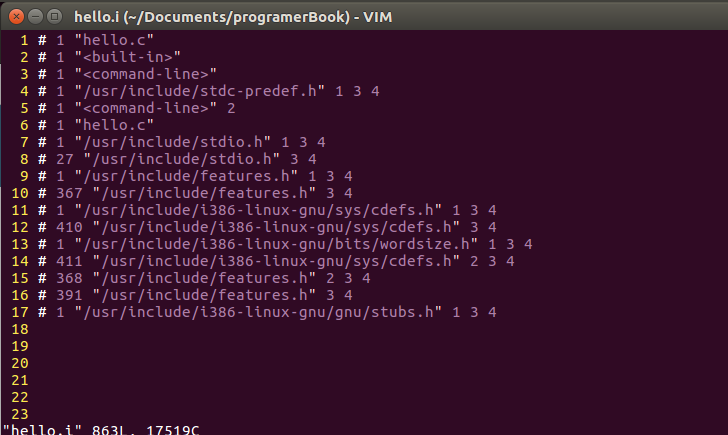
我们可以看到,一个本来不到十行的程序,经过预处理后,已经变成了一个863行的程序,说明预处理器向程序中加了许多的内容,我们原先的几行代码也被放在了最后。
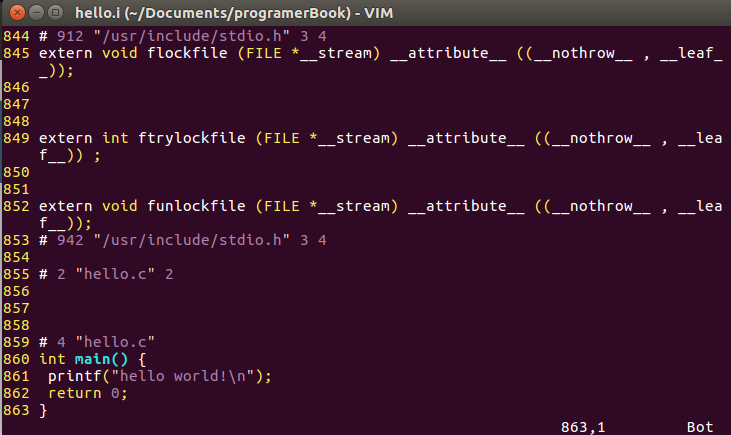
预编译过程主要处理那些源文件中的以"#"开始的预编译指令,主要处理规则如下:
-
将所有的
#define删除,并将所有的宏定义进行展开。程序中我们的RET宏被替换为了0。 -
处理所有的条件预编译指令,比如
#ifdef、#elif等。 -
处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件。

左侧为stdio.h的内容,右侧为hello.i的内容,可以看到stdio.h文件的内容经过预处理后直接拷贝到了hello.i文件中。
-
删除所有的注释"//"和"/* */"。hello.c程序中//use macro这条注释在hello.i中已经消失了。
-
添加行号和文件名标识,比如#2 "hello.c" 2,以便编译时编译器产生调试用的行号信息以及用于编译时产生编译错误或警告时可以显示行号。
-
保留所有的#pragma编译器指令,因为编译器需要使用他们。(比如在vs中我们常用的#pragma warning (disable : 4996)来禁止编译器产生对使用不安全函数的警告)
记得上过的课上又提到过,由于宏的不规范定义会导致一些错误,而预处理后的程序所有宏均被替代,因此可以通过查看预处理后的.i文件来判断宏定义是否正确或头文件包含是否正确。
编译
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编文件。
$ gcc -S hello.i -o hello.s
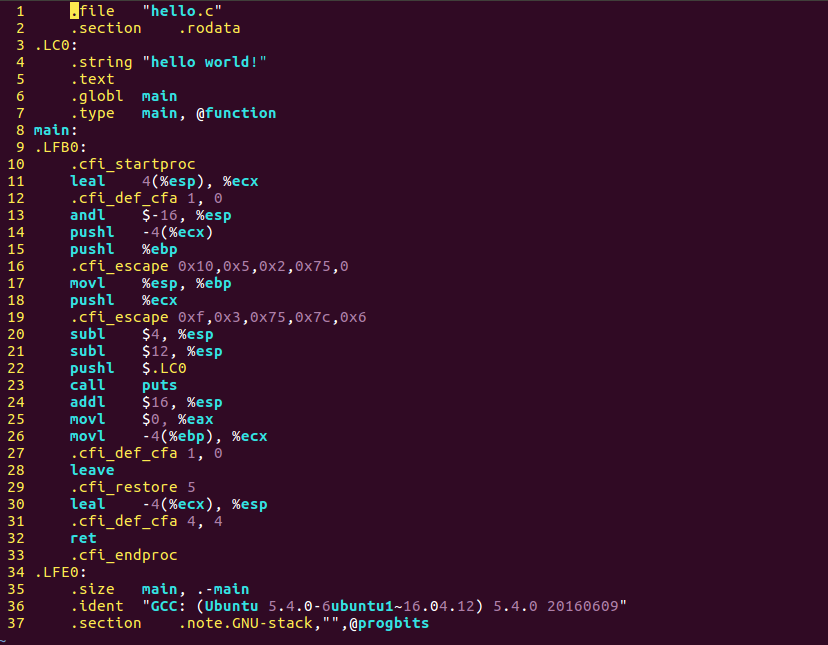
上面的汇编风格为AT&T的,我们可以加些参数将其转换为Intel风格的,且去掉cfi宏。
$ gcc -S hello.i -o hello.s -masm=intel -fno-asynchronous-unwind-tables

可以看到.string后面跟着字符串"hello world!",值得注意的是,生成的汇编代码中函数printf被替换成了puts,这是因为当printf只有一个单一参数时,与puts是十分类似的,于是GCC的优化策略就将其替换以提高性能。
下面我们对编译过程进行详细介绍
编译器实现了从源程序到语义上等价的目标程序的映射,这个映射可以分为两部分:分析部分和综合部份。
分析(analysis)部分将源程序分解为多个组成要素,并在这些要素上加上语法结构,然后利用这个结构创建该源程序的一个中间表示。分析部分还会收集有关源程序的信息,并把信息存放在一个称为符号表(symbol table)的数据结构中,符号表将和中间表示形式一起传送给综合部份。
综合(synthesis)部分根据中间表示和符号表中的信息来构造用户期待的目标程序。
分析部分经常被称为编译器的前端(front end),它和目标机器无关;而综合部份称为后端(back end),与目标机器有关,前端和后端分离导致我们可以更好地开发编译器,编译器开发者便不用为每个CPU架构开发一整套编译器,而是重新编写后端即可,也不用为每一种高级语言开发一整套编译器,只需要更改前端即可。
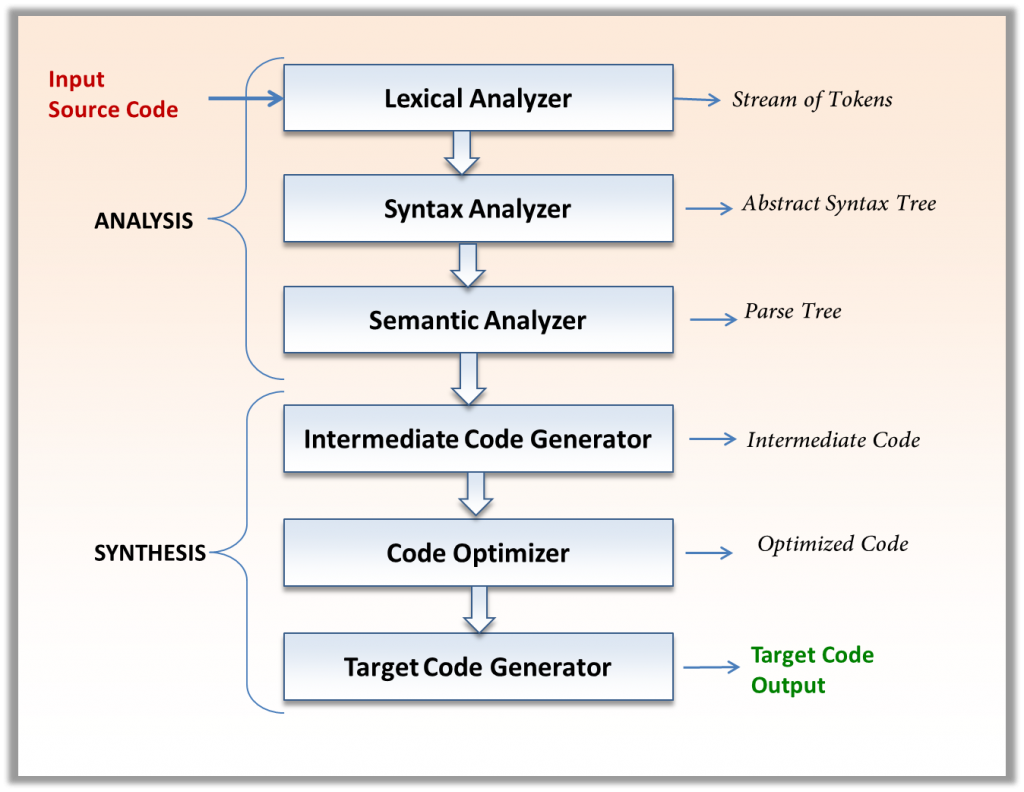
-
词法分析(lexical analysis)
读入组成源程序的字符流,并将它们组织成为有意义的词素(lexeme)序列,对于每个词素,词法分析器产生词法单元(token)作为输出。
-
语法分析(syntax analysis)
使用由词法分析器生成的各个词法单元token来创建树形的中间表示,该中间表示给出了词法分析产生的词法单元流的语法结构,一个常用的表示是语法树(syntax tree),树中的每个内部节点表示一个运算,而该结点的子节点表示该运算的分量。

-
语义分析(semantic analysis)
语法分析仅仅是完成了对表达式语法层面的分析,但是它并不了解这个语句是否真正有意义,比如C语言里面两个指针作乘法运算是没有意义的,但这个语句在语法上是合法的。编译器所能分析的语义是静态语义(Static Sematic),即编译期间可以确定的语义,与之对应的动态语义(Dynamic Sematic)就是只有在运行期才能确定的语义。比如将零作为除数是一个运行期语义错误。
语义分析使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。语义分析的一个重要部分是类型检查(type checking),编译器检查每个运算符是否具有匹配的运算分量。
-
中间代码生成
根据语义分析的输出,生成类机器语言的中间表示,比如三地址码和P-代码。三地址码类似于汇编语言的指令组成(但还不是汇编语言),每个指令具有三个运算分量,每个运算分量都像一个寄存器。这种中间代码一般跟目标机器和运行时环境无关。
比如
a = b + c * (4 + 2)的源代码最后生成的中间代码模样大概为:t0 = 2 + 4 t1 = id3 * t0 t2 = id2 + t1 id1 = t3 -
中间代码优化
改进中间代码,生成更好的目标代码,比如上面的中间代码可以优化为:
t1 = id3 * 6 id1 = id2 + t1中间代码使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换为目标代码。这样对于一些可以跨平台的编译器而言,可以针对不同的平台使用同一个前端和针对不同机器平台的后端。
-
目标代码生成
这个过程非常依赖于目标机器,因为不同的机器有着不同的字长、寄存器等,如果目标语言是x86汇编语言,那么上面的中间代码产生的目标代码可能为:
mov edx, DWORD PTR [ebp - 8] ;[ebp-8]里面为c的值 mov eax, edx ;eax = c add eax, eax ;eax = 2c add eax, edx ;eax = 3c add eax, eax ;eax = 6c mov edx, eax ;edx = 6c mov eax, DWORD PTR [ebp - 12] ;[ebp - 12]里面为b的值 add eax, edx ;eax = b + 6c
汇编
汇编过程就是将汇编语言转换为机器语言。由于汇编指令是机器指令的助记符,每一个汇编语句几乎都对应一条机器指令,所以汇编器的汇编过程相对于编译器来讲比较简单,没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以。
$ gcc -c hello.s -o hello.o
或者
$ as hello.s -o hello.o
此时的目标文件hello.o是一个可重定位目标文件(Relocatable File),如果使用文本编辑器查看hello.o会看到一堆乱码,我们需要采用反汇编技术查看hello.o文件内容
$ objdump -sd hello.o -M intel
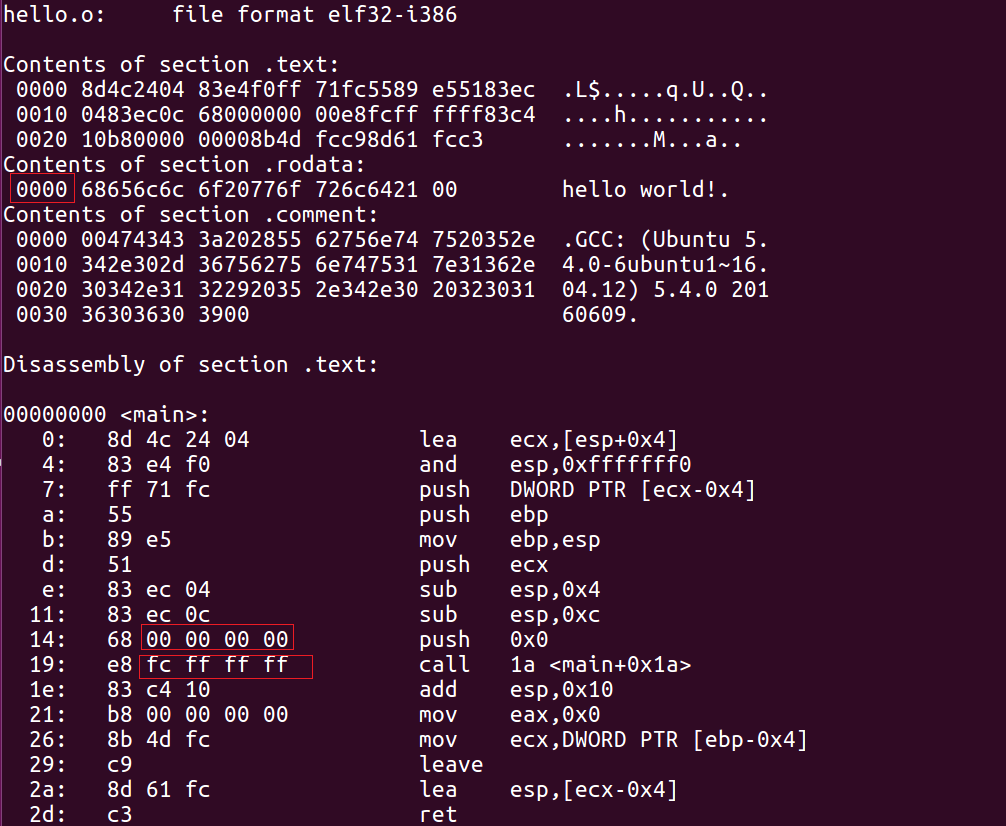
由于还未进行链接,目标文件的符号的虚拟地址无法确定,于是我们看到字符串“hello world!”的地址为0x0000,传给puts函数的参数(即hello world字符串的地址)也为00000000,而call puts机器语言中的0xfffffffc(小端)为-4,表示相对PC寻址,puts函数的地址为0x1e - 4 = 0x1a,我们可以看到0xfffffffc和之前的0x00000000一样,存放的并不是puts函数的地址,只是一个临时的假地址,因为在编译的时候,编译器并不知道puts函数的地址,分配地址的事情交给链接器来做。
链接
链接可以分为静态链接和动态链接两种,GCC默认使用动态链接,添加编译选项"-static"即可指定使用静态链接。,这一阶段将目标文件及其依赖库进行链接,生成可执行文件。功能主要包括
-
地址和空间分配(Address and Storage Allocation)
-
符号绑定(Symbol Binding)
-
重定位(Relocation)
将每一个符号的定义与一个内存地址进行关联,然后修改这些符号的引用,使其指向这个内存地址。
$ gcc hello.o -o hello -static
使用objdump反汇编查看hello文件内容
$ objdump -d hello
(使用书中的这个命令一下子显示出太多内容,于是我自己使用了objdump -d hello | grep '<main>'查看了main的地址,然后最后用objdump -d hello | grep '80488'查看了main函数的反汇编代码。可以看到此时的push和call中的地址都已经修正到了正确的位置。
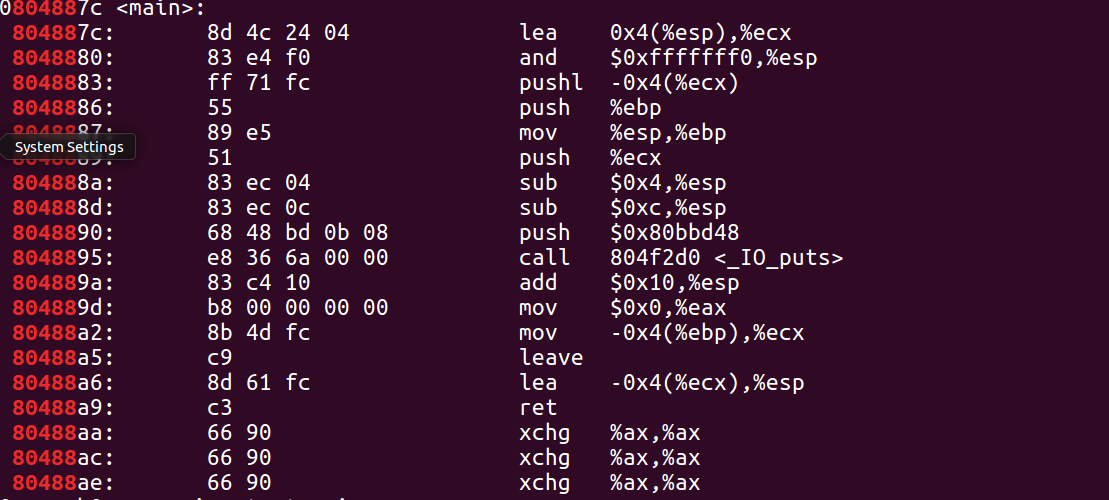
此时程序也就可以被加载到内存中正常执行了。

