
七. 高级方法
高级方法
-
apply()
apply()是一个非常常用并且好用的方法,它允许我们自定义一个函数并且应用到我们的数据中。
比如我们现在有这样的需求,求出每一列数据的最大值与最小值的差,可以这样使用。

默认情况,是以0轴方向应用的这个函数,但是我们可以指定1轴,这时候,我们求得就是每一行的最大值与最小值的差
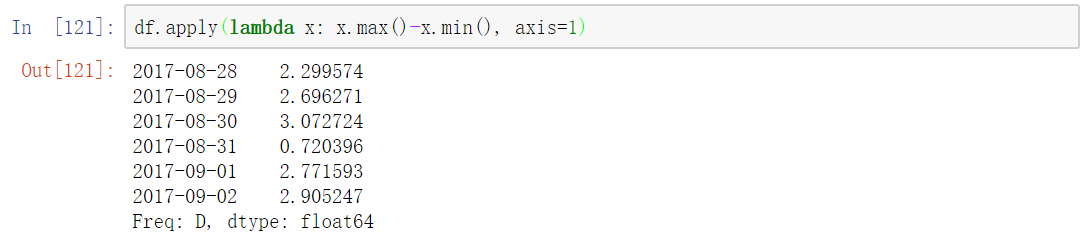
在函数比较复杂的情况下,你也可以单独的定义一个函数,而不是使用lambda表达式。

-
applymap()
applymap()与apply()区别在于,applymap()是以数据里面的每一个元素为单位,传给apply里面的函数,而apply()则是以行或者列为单位。比如,我们想让我们全部的数据每一个都加上5。

-
agg()
对一组数据进行多种统计操作,比如求和,均值,计数,只需要将需要的函数名放在一个列表里面。df = pd.DataFrame(np.random.randn(5,4), columns=['value1', 'value2', 'value3', 'value4']) df.agg(['mean', 'max', 'min'])
-
pivot_table()
相当于excel里面的数据透视表
首选创建一组示例数据df = pd.DataFrame({'key1':['a','b','b','b','a'], 'key2':['one','two','one','two','one'], 'value1':np.random.randn(5), 'value2':np.random.randn(5)}) df使用数据透视表

df.pivot_table(['value1'], index='key1', columns='key2')
同样是上面的数据,还可以进行分项汇总
df.pivot_table(index='key1', columns='key2', margins=True)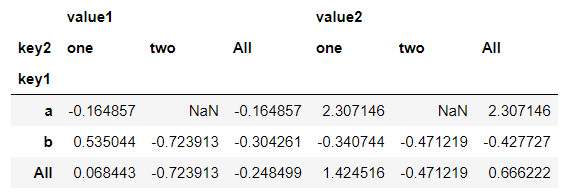
-
cross_tab()
交叉表,可以按照指定的行和列统计分组频数pd.crosstab(index = df.key1, columns = df.key2, margins=True)
-
map()
使用字典,Series或者函数,将Series里面的数据做一个映射。train['Sex_male'] = train.Sex.map({'female':0, 'male':1})通过以上的变换,就可以讲Sex这一列的数据中的female映射成0,male映射成1.
-
get_dummies()
一位有效数字(one-hot)编码, 下面是将泰坦尼克号的港口进行编码。Embarked_dummies = pd.get_dummies(train.Embarked, prefix='Embarked') Embarked_dummies.head()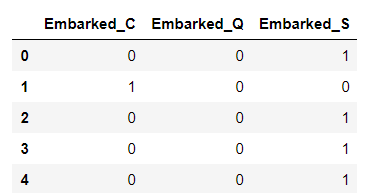
在编码之后,我们可以配合contact()方法将编码的结果合并到原来的数据上。
train = pd.concat([train, Embarked_dummies], axis=1)另外,使用contact()方法还可以将DataFrame类型进行编码。
pd.get_dummies(train, columns=['Sex', 'Embarked'])需要注意的是,以上的方法将会删除train中Sex和Embarked列,返回一个train的拷贝。

