

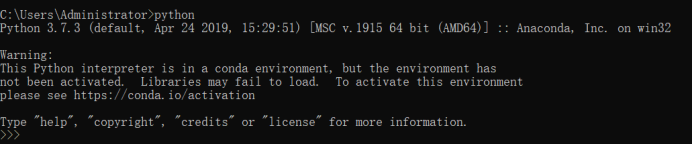
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
Python环境:
pip list截图:
2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
P1机器学习概论:
1机器学习概念
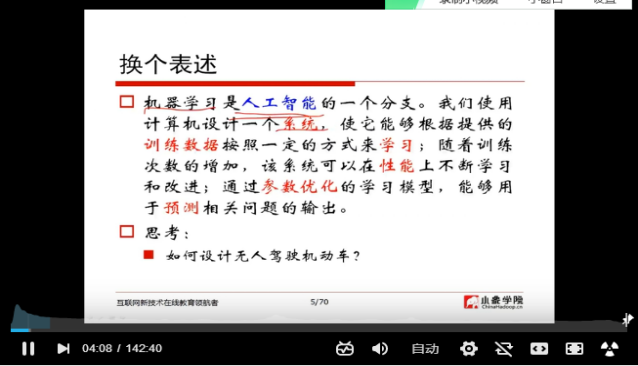
2学习分类

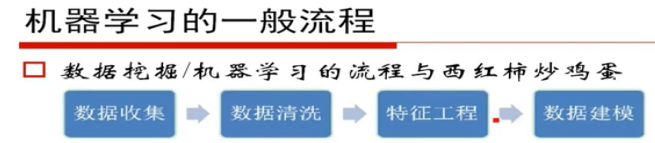
3流程
4示例
5算法

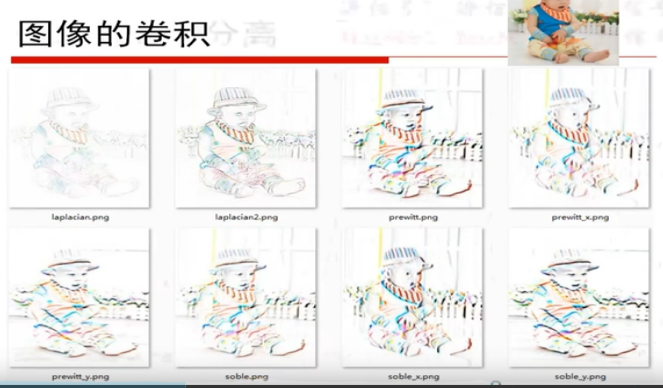
P4python基础:
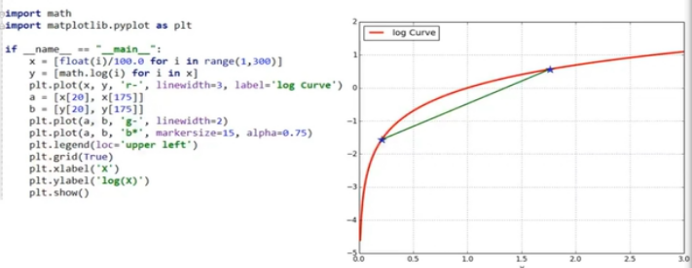
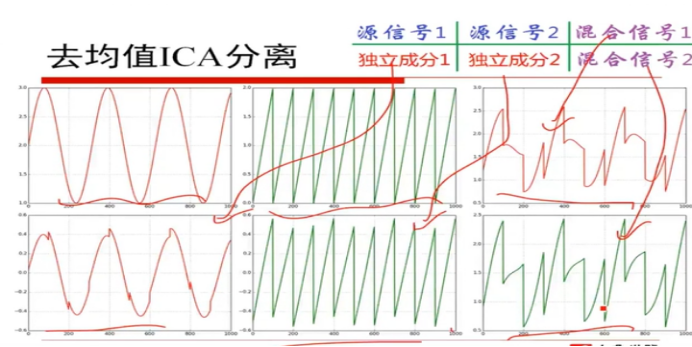
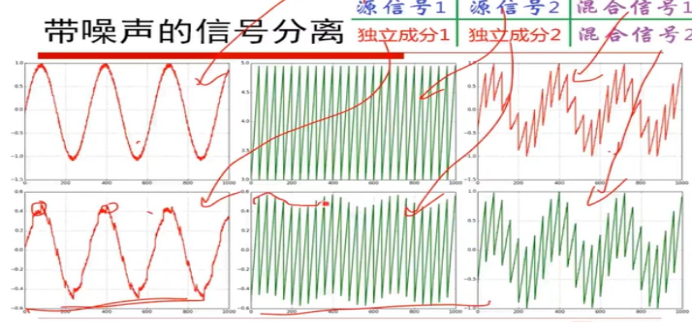
认真学习视频,学习绘图,画出高斯分布函数,损失函数。。。。下面是绘图的示例。
(1)高斯分布函数 (2)损失函数
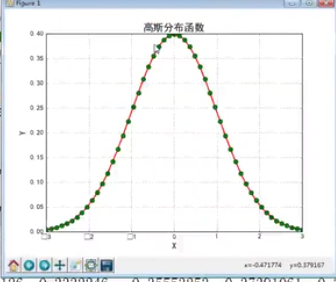
(3)x^x

(4)胸型线
(5)Bar
(6)心型线

(7)

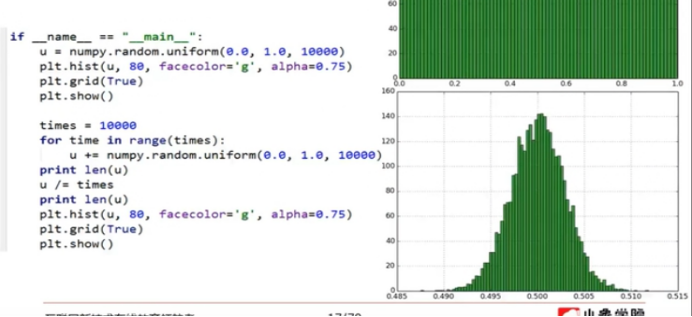
(8)其他分布的中心极限定理
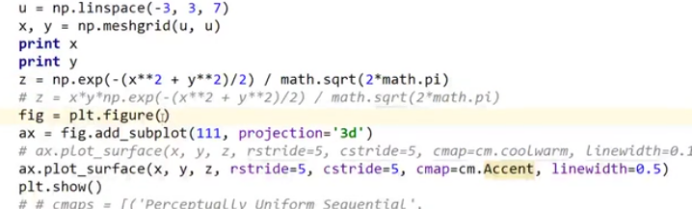
(9)三维
(10)暴力模拟,直接计算,严格计算。
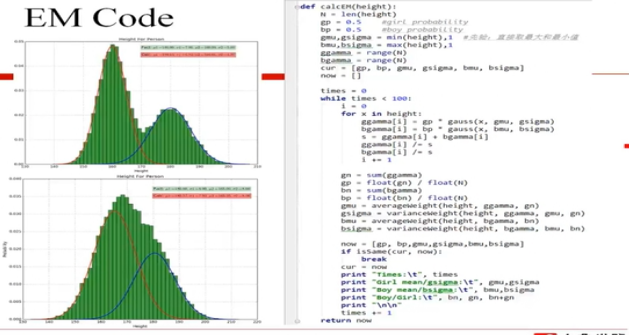
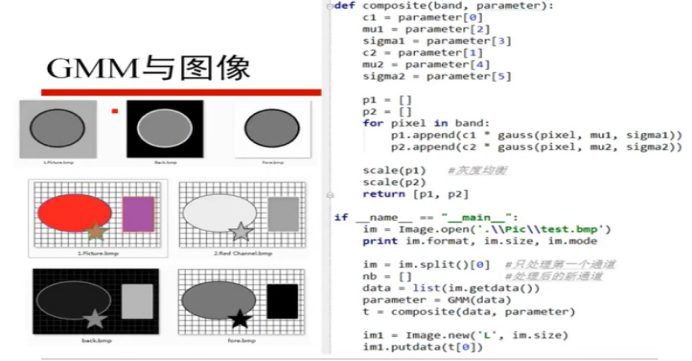
还有很多的知识,在后续的学习中,再来回顾。
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习是人工智能的分支。我们使用的计算机计算机设计-一个系统,使它能够根据提供的训练数据桉照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。和人类的学习方式差不多,只不过比人类学的量更多更快,机器学习不是仅输入规则和数据,它能够再规则的条件下再判断,再学习强化的。
目前机器学习主流分为:监督学习,无监督学习,增强学习。前面说了,机器学习和人类学习差不多,我们可以通过人类的学习来比拟机器学习。
监督学习:
监督学习可分为“回归”和“分类”问题。
在回归问题中,我们会预测一个连续值。也就是说我们试图将输入变量和输出用一个连续函数对应起来;而在分类问题中,我们会预测一个离散值,我们试图将输入变量与离散的类别对应起来。总的来说呢监督学习就是通过学习许多有标签的样本,然后对新的数据做出预测。
就跟我们人类小孩看月亮一样,第一次看到第一个月亮,就问

大人,“这是什么呀”,大人回是月亮。第二次看到第二个月亮又问是什么,又说是月亮。第三次看到第三个月亮又问是什么,又回答是月亮。第四次看到这样的月亮,孩子就大声的喊出来,是月亮,是月亮。所以我们可以使用机器算法帮助我们准确识别新照片上的水果或者预测二手房的售价。
无监督学习:
在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。数据点没有相关的标签。相反,无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构。这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。
比如说,一个小孩,没有人告诉他“阅兵”是一个词,但是在他通过电视的大量数据分析,他得出了阅兵这个词,监督学习是有标签的,就是每个X都有对应的Y,无监督学习是没有标签的,都是X数据,没有对应的数据。
增强学习:
强化学习就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大。如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。
比如说走路,踢球。没人告诉你应该怎样做,而是在你不断的尝试和锻炼还有得到奖励在这过程中学会的。简单来说就是给你一只小白鼠在迷宫里面,目的是找到出口,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。强化学习的典型案例就是阿尔法狗。

