
为什么说JAVA中要慎重使用继承 C# 语言历史版本特性(C# 1.0到C# 8.0汇总) SQL Server事务 事务日志 SQL Server 锁详解 软件架构之 23种设计模式 Oracle与Sqlserver:Order by NULL值介绍 asp.net MVC漏油配置总结
为什么说JAVA中要慎重使用继承
这篇文章的主题并非鼓励不使用继承,而是仅从使用继承带来的问题出发,讨论继承机制不太好的地方,从而在使用时慎重选择,避开可能遇到的坑。
JAVA中使用到继承就会有两个无法回避的缺点:
- 打破了封装性,子类依赖于超类的实现细节,和超类耦合。
- 超类更新后可能会导致错误。
继承打破了封装性
关于这一点,下面是一个详细的例子(来源于Effective Java第16条)
public class MyHashSet<E> extends HashSet<E> {
private int addCount = 0;
public int getAddCount() {
return addCount;
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
}这里自定义了一个HashSet,重写了两个方法,它和超类唯一的区别是加入了一个计数器,用来统计添加过多少个元素。
写一个测试来测试这个新增的功能是否工作:
public class MyHashSetTest {
private MyHashSet<Integer> myHashSet = new MyHashSet<Integer>();
@Test
public void test() {
myHashSet.addAll(Arrays.asList(1,2,3));
System.out.println(myHashSet.getAddCount());
}
}运行后会发现,加入了3个元素之后,计数器输出的值是6。
进入到超类中的addAll()方法就会发现出错的原因:它内部调用的是add()方法。所以在这个测试里,进入子类的addAll()方法时,数器加3,然后调用超类的addAll(),超类的addAll()又会调用子类的add()三次,这时计数器又会再加三。
问题的根源
将这种情况抽象一下,可以发现出错是因为超类的可覆盖的方法存在自用性(即超类里可覆盖的方法调用了别的可覆盖的方法),这时候如果子类覆盖了其中的一些方法,就可能导致错误。
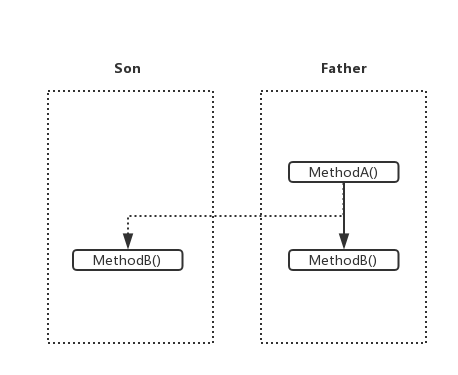
比如上图这种情况,Father类里有可覆盖的方法A和方法B,并且A调用了B。子类Son重写了方法B,这时候如果子类调用继承来的方法A,那么方法A调用的就不再是Father.B(),而是子类中的方法Son.B()。如果程序的正确性依赖于Father.B()中的一些操作,而Son.B()重写了这些操作,那么就很可能导致错误产生。
关键在于,子类的写法很可能从表面上看来没有问题,但是却会出错,这就迫使开发者去了解超类的实现细节,从而打破了面向对象的封装性,因为封装性是要求隐藏实现细节的。更危险的是,错误不一定能轻易地被测出来,如果开发者不了解超类的实现细节就进行重写,那么可能就埋下了隐患。
超类更新时可能产生错误
这一点比较好理解,主要有以下几种可能:
- 超类更改了已有方法的签名。会导致编译错误。
- 超类新增了方法:
- 和子类已有方法的签名相同但返回类型不同,会导致编译错误。
- 和子类的已有方法签名相同,会导致子类无意中复写,回到了第一种情况。
- 和子类无冲突,但可能会影响程序的正确性。比如子类中元素加入集合必须要满足特定条件,这时候如果超类加入了一个无需检测就可以直接将元素插入的方法,程序的正确性就受到了威胁。
设计可继承的类
设计可以用来继承的类时,应该注意:
- 对于存在自用性的可覆盖方法,应该用文档精确描述调用细节。
- 尽可能少的暴露受保护成员,否则会暴露太多实现细节。
- 构造器不应该调用任何可覆盖的方法。
详细解释下第三点。它实际上和 继承打破了封装性 里讨论的问题很相似,假设有以下代码:
public class Father {
public Father() {
someMethod();
}
public void someMethod() {
}
}public class Son extends Father {
private Date date;
public Son() {
this.date = new Date();
}
@Override
public void someMethod() {
System.out.println("Time = " + date.getTime());
}
}上述代码在运行测试时就会抛出NullPointerException :
public class SonTest {
private Son son = new Son();
@Test
public void test() {
son.someMethod();
}
}因为超类的构造函数会在子类的构造函数之前先运行,这里超类的构造函数对someMethod()有依赖,同时someMethod()被重写,所以超类的构造函数里调用到的将是Son.someMethod(),而这时候子类还没被初始化,于是在运行到date.getTime()时便抛出了空指针异常。
因此,如果在超类的构造函数里对可覆盖的方法有依赖,那么在继承时就可能会出错。
结论
继承有很多优点,但使用继承时应该慎重并多加考虑。同样用来实现代码复用的还有复合,如果使用继承和复合皆可(这是前提),那么应该优先使用复合,因为复合可以保持超类对实现细节的屏蔽,上述关于继承的缺点都可以用复合来避免。这也是所谓的复合优先于继承。
如果使用继承,那么应该留意重写超类中存在自用性的可覆盖方法可能会出错,即使不进行重写,超类更新时也可能会引入错误。同时也应该精心设计超类,对任何相互调用的可覆盖方法提供详细文档。
C# 语言历史版本特性(C# 1.0到C# 8.0汇总)
历史版本
C#作为微软2000年以后.NET平台开发的当家语言,发展至今具有17年的历史,语言本身具有丰富的特性,微软对其更新支持也十分支持。微软将C#提交给标准组织ECMA,C# 5.0目前是ECMA发布的最新规范,C# 6.0还是草案阶段,C# 7.1是微软当前提供的最新规范。
这里仅仅列个提纲,由于C# 5.0是具有ECMA标准规范的版本,所以选择C# 5.0作为主要版本学习,并专题学习C# 6.0,7.0版本新特性。
C#语言规范GitHub库参见:https://github.com/dotnet/csharplang
C#语言路线图及开发中的特性参见:
https://github.com/dotnet/roslyn/blob/master/docs/Language%20Feature%20Status.md
| 语言版本 | 发布时间 | .NET Framework要求 | Visual Studio版本 |
|---|---|---|---|
| C# 1.0 | 2002.1 | .NET Framework 1.0 | Visual Studio .NET 2002 |
| C# 1.1\1.2 | 2003.4 | .NET Framework 1.1 | Visual Studio .NET 2003 |
| C# 2.0 | 2005.11 | .NET Framework 2.0 | Visual Studio 2005 |
| C# 3.0 | 2007.11 | .NET Framework 2.0\3.0\3.5 | Visual Studio 2008 |
| C# 4.0 | 2010.4 | .NET Framework 4.0 | Visual Studio 2010 |
| C# 5.0 | 2012.8 | .NET Framework 4.5 | Visual Studio 2012\2013 |
| C# 6.0 | 2015.7 | .NET Framework 4.6 | Visual Studio 2015 |
| C# 7.0 | 2017.3 | .NET Framework 4.6.2 | Visual Studio 2017 |
| C# 7.1 | 2017.6 | .NET Framework | Visual Studio 2017 v15.3预览版 |
| C# 8.0 | 待发布 | .NET Framework 4.7.1 | Visual Studio 2017 v15.7 |
C# 1.0 特性
第1个版本,编程语言最基础的特性。
- Classes:面向对象特性,支持类类型
- Structs:结构
- Interfaces:接口
- Events:事件
- Properties:属性,类的成员,提供访问字段的灵活方法
- Delegates:委托,一种引用类型,表示对具有特定参数列表和返回类型的方法的引用
- Expressions,Statements,Operators:表达式、语句、操作符
- Attributes:特性,为程序代码添加元数据或声明性信息,运行时,通过反射可以访问特性信息
- Literals:字面值(或理解为常量值),区别常量,常量是和变量相对的
C# 2特性 (VS 2005)
- Generics:泛型
- Partial types:分部类型,可以将类、结构、接口等类型定义拆分到多个文件中
- Anonymous methods:匿名方法
- Iterators:迭代器
- Nullable types:可以为Null的类型,该类可以是其它值或者null
- Getter/setter separate accessibility:属性访问控制
- Method group conversions (delegates):方法组转换,可以将声明委托代表一组方法,隐式调用
- Co- and Contra-variance for delegates and interfaces:委托、接口的协变和逆变
- Static classes:静态类
- Delegate inference:委托推断,允许将方法名直接赋给委托变量
C# 3特性 (VS 2008)
- Implicitly typed local variables:
- Object and collection initializers:对象和集合初始化器
- Auto-Implemented properties:自动属性,自动生成属性方法,声明更简洁
- Anonymous types:匿名类型
- Extension methods:扩展方法
- Query expressions:查询表达式
- Lambda expression:Lambda表达式
- Expression trees:表达式树,以树形数据结构表示代码,是一种新数据类型
- Partial methods:部分方法
C# 4特性 (VS 2010)
- Dynamic binding:动态绑定
- Named and optional arguments:命名参数和可选参数
- Generic co- and contravariance:泛型的协变和逆变
- Embedded interop types (“NoPIA”):开启嵌入类型信息,增加引用COM组件程序的中立性
C# 5特性 (VS 2012)
- Asynchronous methods:异步方法
- Caller info attributes:调用方信息特性,调用时访问调用者的信息
C# 6特征 (VS 2015)
- Compiler-as-a-service (Roslyn)
- Import of static type members into namespace:支持仅导入类中的静态成员
- Exception filters:异常过滤器
- Await in catch/finally blocks:支持在catch/finally语句块使用await语句
- Auto property initializers:自动属性初始化
- Default values for getter-only properties:设置只读属性的默认值
- Expression-bodied members:支持以表达式为主体的成员方法和只读属性
- Null propagator (null-conditional operator, succinct null checking):Null条件操作符
- String interpolation:字符串插值,产生特定格式字符串的新方法
- nameof operator:nameof操作符,返回方法、属性、变量的名称
- Dictionary initializer:字典初始化
C# 7 特征 (Visual Studio 2017)
- Out variables:out变量直接声明,例如可以out in parameter
- Pattern matching:模式匹配,根据对象类型或者其它属性实现方法派发
- Tuples:元组
- Deconstruction:元组解析
- Discards:没有命名的变量,只是占位,后面代码不需要使用其值
- Local Functions:局部函数
- Binary Literals:二进制字面量
- Digit Separators:数字分隔符
- Ref returns and locals:引用返回值和局部变量
- Generalized async return types:async中使用泛型返回类型
- More expression-bodied members:允许构造器、解析器、属性可以使用表达式作为body
- Throw expressions:Throw可以在表达式中使用
C# 7.1 特征 (Visual Studio 2017 version 15.3)
- Async main:在main方法用async方式
- Default expressions:引入新的字面值default
- Reference assemblies:
- Inferred tuple element names:
- Pattern-matching with generics:
C# 8.0 特征 (Visual Studio 2017 version 15.7)
- Default Interface Methods 缺省接口实现
- Nullable reference type NullableReferenceTypes 非空和可控的数据类型
- Recursive patterns 递归模式
- Async streams 异步数据流
- Caller expression attribute 调用方法表达式属性
- Target-typed new
- Generic attributes 通用属性
- Ranges
- Default in deconstruction
- Relax ordering of ref and partial modifiers
-
SQL Server事务 事务日志
事务 (SQL Server)
一、事务概念
事务是一种机制、是一种操作序列,它包含了一组数据库操作命令,这组命令要么全部执行,要么全部不执行。因此事务是一个不可分割的工作逻辑单元。在数据库系统上执行并发操作时事务是作为最小的控制单元来使用的。这特别适用于多用户同时操作的数据通信系统。例如:订票、银行、保险公司以及证券交易系统等。
二、事务属性
事务4大属性:
1 原子性(Atomicity):事务是一个完整的操作。
2 一致性(Consistency):当事务完成时,数据必须处于一致状态。
3 隔离性(Isolation):对数据进行修改的所有并发事务是彼此隔离的。
4 持久性(Durability):事务完成后,它对于系统的影响是永久性的。
三、创建事务
T-SQL中管理事务的语句:
1 开始事务: begin transaction
2 提交事务:commit transaction
3 回滚事务: rollback transaction
事务分类:
1 显式事务:用begin transaction明确指定事务的开始。
2 隐性事务:打开隐性事务:set implicit_transactions on,当以隐性事务模式操作时,SQL Servler将在提交或回滚事务后自动启动新事务。无法描述事务的开始,只需要提交或回滚事务。
3 自动提交事务:SQL Server的默认模式,它将每条单独的T-SQL语句视为一个事务。如果成功执行,则自动提交,否则回滚。事务日志 (SQL Server)
每个 SQL Server 数据库都有事务日志,用于记录所有事务以及每个事务所做的数据库修改。
事务日志是数据库的一个关键组件。 如果系统出现故障,你将需要依靠该日志将数据库恢复到一致的状态。
重要
永远不要删除或移动此日志,除非你完全了解执行此操作的后果。
提示
检查点会创建一些正常点,在数据库恢复期间将从这些正常点开始应用事务日志。 有关详细信息,请参阅数据库检查点 (SQL Server)。
事务日志支持的操作
事务日志支持以下操作:
-
恢复个别的事务。
-
在 SQL Server 启动时恢复所有未完成的事务。
-
将还原的数据库、文件、文件组或页前滚至故障点。
-
支持事务复制。
-
支持高可用性和灾难恢复解决方案: AlwaysOn 可用性组、数据库镜像和日志传送。
恢复个别的事务
如果应用程序发出 ROLLBACK 语句,或者数据库引擎检测到错误(例如失去与客户端的通信),使用日志记录回退未完成的事务所做的修改。
在 SQL Server 启动时恢复所有未完成的事务
当服务器发生故障时,数据库可能处于这样的状态:还没有将某些修改从缓存写入数据文件,在数据文件内有未完成的事务所做的修改。 启动 SQL Server 实例时,它将对每个数据库执行恢复操作。 前滚日志中记录的、可能尚未写入数据文件的每个修改。 在事务日志中找到的每个未完成的事务都将回滚,以确保数据库的完整性。
将还原的数据库、文件、文件组或页前滚至故障点
在硬件丢失或磁盘故障影响到数据库文件后,可以将数据库还原到故障点。 先还原上次完整数据库备份和上次差异数据库备份,然后将后续的事务日志备份序列还原到故障点。
还原每个日志备份时,数据库引擎将重新应用日志中记录的所有修改,前滚所有事务。 最后的日志备份还原后,数据库引擎将使用日志信息回退到该点上未完成的所有事务。
支持事务复制
日志读取器代理程序监视已为事务复制配置的每个数据库的事务日志,并将已设复制标记的事务从事务日志复制到分发数据库中。 有关详细信息,请参阅 事务复制的工作原理。
支持高可用性和灾难恢复解决方案
备用服务器解决方案、AlwaysOn 可用性组、数据库镜像和日志传送极大程度上依赖于事务日志。
在 AlwaysOn 可用性组方案中,数据库的每个更新(主要副本)在数据库的完整且独立的副本(次要副本)中直接再现。 主要副本直接将每个日志记录发送到次要副本,这可将传入日志记录应用到可用性组数据库,并不断前滚。 有关详细信息,请参阅 AlwaysOn 故障转移群集实例
在日志传送方案中,主服务器将主数据库的活动事务日志发送到一个或多个目标服务器。 每个辅助服务器将该日志还原为其本地的辅助数据库。 有关详细信息,请参阅 关于日志传送。
在数据库镜像方案中,数据库(主体数据库)的每次更新都在独立的、完整的数据库(镜像数据库)副本中立即重新生成。 主体服务器实例立即将每个日志记录发送到镜像服务器实例,镜像服务器实例将传入的日志记录应用于镜像数据库,从而将其继续前滚。 有关详细信息,请参阅 数据库镜像。
Transaction Log characteristics
SQL Server 数据库引擎 事务日志的特征:
- 事务日志是作为数据库中的单独的文件或一组文件实现的。 日志缓存与数据页的缓冲区高速缓存是分开管理的,因此可在数据库引擎中生成简单、快速和功能强大的代码。 有关详细信息,请参阅事务日志物理体系结构。
- 日志记录和页的格式不必遵守数据页的格式。
- 事务日志可以在几个文件上实现。 通过设置日志的 FILEGROWTH 值可以将这些文件定义为自动扩展。 这样可减少事务日志内空间不足的可能性,同时减少管理开销。 有关详细信息,请参阅 ALTER DATABASE (Transact-SQL)。
- 重用日志文件中空间的机制速度快且对事务吞吐量影响最小。
事务日志截断
日志截断将释放日志文件的空间,以便由事务日志重新使用。 必须定期截断事务日志,防止其占满分配的空间(绝对会!)。 几个因素可能延迟日志截断,因此监视日志大小很重要。 某些操作可以最小日志量进行记录以减少其对事务日志大小的影响。
日志截断可从 SQL Server 数据库的逻辑事务日志中删除不活动的虚拟日志文件,释放逻辑日志中的空间以便物理事务日志重用这些空间。 如果事务日志从不截断,它最终将填满分配给物理日志文件的所有磁盘空间。
为了避免空间不足,除非由于某些原因延迟日志截断,否则将在以下事件后自动进行截断:
-
简单恢复模式下,在检查点之后发生。
-
在完整恢复模式或大容量日志恢复模式下,如果自上一次备份后生成检查点,则在日志备份后进行截断(除非是仅复制日志备份)。
有关详细信息,请参阅本主题后面的 可能延迟日志截断的因素。
备注
日志截断并不减小物理日志文件的大小。 若要减少物理日志文件的物理大小,则必须收缩日志文件。 有关收缩物理日志文件大小的信息,请参阅 Manage the Size of the Transaction Log File。
Factors that can delay log truncation
在日志记录长时间处于活动状态时,事务日志截断将延迟,事务日志可能填满,这一点我们在本主题(很长)前面提到过。
[!IMPORTANT} 有关如何响应已满事务日志的信息,请参阅解决事务日志已满的问题(SQL Server 错误 9002)。
实际上,日志截断会由于多种原因发生延迟。 查询 sys.databases 目录视图的 log_reuse_wait 和 log_reuse_wait_desc 列,了解哪些因素(如果存在)阻止日志截断。 下表对这些列的值进行了说明。
log_reuse_wait 值 log_reuse_wait_desc 值 说明 0 NOTHING 当前有一个或多个可重复使用的虚拟日志文件。 1 CHECKPOINT 自上次日志截断之后,尚未生成检查点,或者日志头尚未跨一个虚拟日志文件移动。 (所有恢复模式)
这是日志截断延迟的常见原因。 有关详细信息,请参阅数据库检查点 (SQL Server)。2 LOG_BACKUP 在截断事务日志前,需要进行日志备份。 (仅限完整恢复模式或大容量日志恢复模式)
完成下一个日志备份后,一些日志空间可能变为可重复使用。3 ACTIVE_BACKUP_OR_RESTORE 数据备份或还原正在进行(所有恢复模式)。
如果数据备份阻止了日志截断,则取消备份操作可能有助于解决备份直接导致的此问题。4 ACTIVE_TRANSACTION 事务处于活动状态(所有恢复模式):
一个长时间运行的事务可能存在于日志备份的开头。 在这种情况下,可能需要进行另一个日志备份才能释放空间。 请注意,长时间运行的事务将阻止所有恢复模式下的日志截断,包括简单恢复模式,在该模式下事务日志一般在每个自动检查点截断。
延迟事务。 “延迟的事务 ”是有效的活动事务,因为某些资源不可用,其回滚受阻。 有关导致事务延迟的原因以及如何使它们摆脱延迟状态的信息,请参阅延迟的事务 (SQL Server)。
长时间运行的事务也可能会填满 tempdb 的事务日志。 Tempdb 由用户事务隐式用于内部对象,例如用于排序的工作表、用于哈希的工作文件、游标工作表,以及行版本控制。 即使用户事务只包括读取数据(SELECT查询),也可能会以用户事务的名义创建和使用内部对象, 然后就会填充 tempdb 事务日志。5 DATABASE_MIRRORING 数据库镜像暂停,或者在高性能模式下,镜像数据库明显滞后于主体数据库。 (仅限完整恢复模式)
有关详细信息,请参阅数据库镜像 (SQL Server)。6 REPLICATION 在事务复制过程中,与发布相关的事务仍未传递到分发数据库。 (仅限完整恢复模式)
有关事务复制的信息,请参阅 SQL Server Replication。7 DATABASE_SNAPSHOT_CREATION 正在创建数据库快照。 (所有恢复模式)
这是日志截断延迟的常见原因,通常也是主要原因。8 LOG_SCAN 发生日志扫描。 (所有恢复模式)
这是日志截断延迟的常见原因,通常也是主要原因。9 AVAILABILITY_REPLICA 可用性组的辅助副本正将此数据库的事务日志记录应用到相应的辅助数据库。 (完整恢复模式)
有关详细信息,请参阅:AlwaysOn 可用性组概述 (SQL Server)。10 — 仅供内部使用 11 — 仅供内部使用 12 — 仅供内部使用 13 OLDEST_PAGE 如果将数据库配置为使用间接检查点,数据库中最早的页可能比检查点 LSN 早。 在这种情况下,最早的页可以延迟日志截断。 (所有恢复模式)
有关间接检查点的信息,请参阅数据库检查点 (SQL Server)。14 OTHER_TRANSIENT 当前未使用此值。 可尽量减少日志量的操作
最小日志记录是指只记录在不支持时间点恢复的情况下恢复事务所需的信息。 本主题介绍在大容量日志恢复模式下(以及简单恢复模式下)按最小方式记录、但在运行备份时例外的操作。
备注
内存优化表不支持最小日志记录。
备注
在完整 恢复模式下,所有大容量操作都将被完整地记录下来。 但是,可以通过将数据库暂时切换到用于大容量操作的大容量日志恢复模式,最小化一组大容量操作的日志记录。 最小日志记录比完整日志记录更为有效,并在大容量事务期间,降低了大规模大容量操作填满可用的事务日志空间的可能性。 不过,如果在最小日志记录生效时数据库损坏或丢失,则无法将数据库恢复到故障点。
下列操作在完整恢复模式下执行完整日志记录,而在简单和大容量日志恢复模式下按最小方式记录日志:
- 批量导入操作(bcp、BULK INSERT 和 INSERT...SELECT)。 有关在何时对大容量导入表按最小方式进行记录的详细信息,请参阅 Prerequisites for Minimal Logging in Bulk Import。
启用事务复制时,将完全记录 BULK INSERT 操作,即使处于大容量日志恢复模式下。
- SELECT INTO 操作。
启用事务复制时,将完全记录 SELECT INTO 操作,即使处于大容量日志恢复模式下。
-
插入或追加新数据时,使用 UPDATE 语句中的 .WRITE 子句部分更新到大型值数据类型。 注意,在更新现有值时没有使用最小日志记录。有关大型值数据类型的详细信息,请参阅数据类型 (Transact-SQL)。
-
在UPDATETEXT 、 nUPDATETEXT 和 UPDATETEXT, nUPDATETEXT, 、 UPDATETEXT 语句。 注意,在更新现有值时没有使用最小日志记录。
重要
不推荐使用 WRITETEXT 语句和 UPDATETEXT 语句,应该避免在新的应用程序中使用这些语句。
-
如果数据库设置为简单或大容量日志恢复模式,则无论是脱机还是联机执行操作,都会按最小方式记录一些索引 DDL 操作。 按最小方式记录的索引操作如下:
-
CREATE INDEX 操作(包括索引视图)。
-
ALTER INDEX REBUILD 或 DBCC DBREINDEX 操作。
重要
不推荐使用“DBCC DBREINDEX 语句”;请不要在新的应用程序中使用该语句。
-
DROP INDEX 新堆重新生成(如果适用)。 ( DROP INDEX 操作期间将 始终 完整记录索引页的释放操作。)
-
-
SQL Server 锁详解
锁是一种防止在某对象执行动作的一个进程与已在该对象上执行的其他进行相冲突的机制。也就是说,如果有其他人在操作某个对象,那么你旧不能在该对象上进行操作。你能否执行操作取决于其他用户正在进行的操作。
通过锁可以防止的问题
锁可以解决以下4种主要问题:
- 脏读
- 非重复性读取
- 幻读
- 丢失更新
1、脏读
如果一个事务读取的记录是另一个未完成事务的一部分,那么这时就发生了脏读。如果第一个事务正常完成,那么就有什么问题。但是,如果前一个事务回滚了呢,那将从数据库从未发生的事务中获取了信息。
2、非重复性读取
很容易将非重复性读取和脏读混淆。如果一个事务中两次读取记录,而另一个事务在这期间改变了数据,就会发生非重复性读取。
例如,一个银行账户的余额是不允许小于0的。如果一个事务读取了某账户的余额为125元,此时另一事务也读取了125元,如果两个事务都扣费100元,那么这时数据库的余额就变成了-75元。有两种方式可以防止这个问题:
- 创建CHECK约束并监控547错误
- 将隔离级别设置为REPEATABLEREAD或SERIALIZABLE
CHECK约束看上去相当直观。要知道的是,这是一种被动的而非主动的方法。然而,在很多情况下可能需要使用非重复性读取,所以这在很多情况下是首选。
3、幻读
幻读发生的概率非常小,只有在非常偶然的情况下才会发生。
比如,你想将一张工资表里所有低于100的人的工资,提高到100元。你可能会执行以下SQL语句:
UPDATE tb_Money SET Salary = 100 WHERE Salary < 100
这样的语句,通常情况下,没有问题。但是如果,你在UPDATE的过程中,有人恰好有INSERT了一条工资低于100的数据,因为这是一个全新的数据航,所以没有被锁定,而且它会被漏过Update。
要解决这个问题,唯一的方法是设定事务隔离级别为SERIALIZABLE,在这种情况下,任何对表的更新都不能放入WHERE子句中,否则他们将被锁在外面。
4、丢失更新
丢失更新发生在一个更新成功写入数据库后,而又意外地被另一个事务重写时。这是怎么发生的呢?如果有两个事务读取整个记录,然后其中一个向记录写入了更新信息,而另一个事务也向该记录写入更新信息,这是就会出现丢失更新。
有个例子写得很好,这里照敲下来吧。假如你是公司的一位信用分析员,你接到客户X打开的电话,说他已达到它的信用额度上限,想申请增加额度,所以你查看了这位客户的信息,你发现他的信用额度是5000,并且看他每次都能按时付款。
当你在查看的时候,信用部门的另一位员工也读取了客户X的记录,并输入信息改变了客户的地址。它读取的记录也显示信用额度为5000。
这时你决定把客户X的信用额度提高到10000,并且按下了Enter键,数据库现在显示客户X的信用额度为10000。
Sally现在也更新了客户X的地址,但是她仍然使用和您一样的编辑屏幕,也就是说,她更新了整个记录。还记得她屏幕上显示的信用额度吗?是5000.数据库现在又一次显示客户X的信用额度为5000。你的更新丢失了。
解决这个问题的方法取决于你读取某数据和要更新数据的这段时间内,代码以何种方式识别出另一连接已经更新了该记录。这个识别的方式取决于你所使用的访问方法。
可以锁定的资源
对于SQL Server来说,有6种可锁定的资源,而且它们形成了一个层次结构。锁的层次越高,它的粒度就越粗。按粒度由粗到细排列,这些资源包括:
- 数据库:锁定整个数据库。这通常发生在整个数据库模式改变的时候。
- 表:锁定整个表。这包含了与该表相关联的所有数据相关的对象,包括实际的数据行(每一行)以及与该表相关联的所有索引中的键。
- 区段:锁定整个区段。因为一个区段由8页组成,所以区段锁定是指锁定控制了区段、控制了该区段内8个数据或索引页以及这8页中的所有数据航。
- 页:锁定该页中的所有数据或索引键。
- 键:在索引中的特定键或一系间上有锁。相同索引页中的其他键不受影响。
- 行或行标识符:虽然从技术上将,锁是放在行标识符上的,但是本质上,它锁定了整个数据行。
锁升级和锁对性能的影响
升级是指能够认识到维持一个较细的粒度(例如,行锁而不是页锁),只在被锁定的项数较少时有意义。而随着越来越多的项目被锁定,维护这些锁的系统开销实际上会影响性能。这会导致所持续更长的时间。
当维持锁的数量达到一定限度时,则锁升级为下一个更高的层次,并且将不需要再如此紧密地管理低层次的锁(释放资源,而且有助于提升速度)。
注意,升级是基于锁的数量,而不是用户的数量。这里的重点是,可以通过执行大量的更新来单独地锁定表-行锁可以升级为页锁,页锁可以升级为表锁。这意味着可能将所有其他用户锁在该表之外。如果查询使用了多个表,则它很可能将每个人锁在这些表之外。
锁定模式
除了需要考虑锁定的资源层次以外,还要考虑查询将要获得的锁定模式,就像需要对不同的资源进行锁定一样,也有不同的锁定模式。一些模式是互相排斥的。一些模式什么都不做,只修改其他的模式。模式是否可以一起使用取决于他们是否是兼容的。
1、共享锁
这是最基本的一种锁。共享锁用于只需要读取数据的时候,也就是说,共享锁锁定时,不会进行改变内容的操作,其他用户允许读取。
共享锁能和其他共享锁兼容。虽然共享锁不介意其他锁的存在,但是有些锁并不能和共享锁共存。
共享锁告诉其他锁,某用户已经在那边了,它们并不提供很多的功能,但是不能忽略它们。然而,共享锁能做的是防止用户执行脏读。
2、排它锁
排它锁顾名思义,排它锁不与其他任何锁兼容。如果有任何其他其他锁存在,则不能使用排他锁,而且当排他锁仍然起作用时,他们不允许在资源之上创建任何形式的新锁。这可以防止两个人同时更新、删除或执行任何操作。
3、更新锁
更新锁是共享锁和排他锁的混合。更新锁是一种特殊的占位符。为了能执行UPDATE,需要验证WHERE子句来指出想要更新的具体的数据行。这意味着只需要一个共享锁,直到真正地进行物理更新。在物理更新期间,需要一个排他锁。
- 第一个阶段指出了满足WHERE子句条件的内容,这是更新查询的一部分,该查询有一个更新锁。
- 第二个阶段是如果决定执行更新,那么锁将升级为排他锁。否则,将把锁转换为共享锁。
这样做的好处是它防止了死锁。死锁本身不是一种锁定类型,而是一种已经形成矛盾的状况,两个锁在互相等待,多个锁形成一个环在等待前面的事务清除资源。
如果没有更新锁,死锁会一直出现。两个更新查询会在共享模式下运行。Query A完成了它的查询工作并准备进行物理更新。它想升级为排他锁,但是不可以这么做,因为Query B正在完成查询。除非Query B需要进行物理更新,否则它会完成查询。为了做到这点,Query B必须升级为排他锁,但是不能这么做,因为Query A正在等待。这样就造成了僵局。
而更新锁阻止建立其他的更新锁。第二个事务只要尝试取得一个更新锁,它们就会进入等待状态,直到超时为止-将不会授予这个锁。如果第一个锁在锁超时之前清除的话,则锁定会授予给新的请求者,并且这个处理会继续下去。如果不清楚,则会发生错误。
更新锁只与共享锁以及意向共享锁相兼容。
4、意向锁
意向锁是什么意思呢?就是说,加入你锁定了某一行,那么同时也加了表的意向锁(不允许其他人通过表锁来妨碍你)。
意向锁是真正的占位符,它用来处理对象层次问题的。假设一下如下情况:已对某一行建立了锁,但是有人想在页上或区段上建立所,或者是修改表。你肯定不想让另一个事务通过达到更高的层次来妨碍你。
如果没有意向锁,那么较高层次的对象将不会知道在较低层次上有锁。意向锁可改进性能,因为SQL Server只需要在表层次上检查意向锁(而不需要检查表上的每个行锁或者页锁),以此来决定事务是否可以安全地锁定整个表。意向锁分为以下3种不同的类型:
- 意向共享锁:该意向锁指已经或者将要在层次结构的一些较低点处建立共享锁。
- 意向排他锁:它与意向共享锁一样,但是将会在低层项上设置排他锁。
- 共享意向排他锁:它指已经或将会在对象层次结构下面建立共享锁,但目的是为了修改数据,所以它会在某个时刻成为意向排它锁。
5、模式锁
模式锁分为以下两种。
- 模式修改锁:对对象进行模式改变。在Sch-M锁期间,不能对对象进行查询或其他CREATE、ALTER或DROP语句的操作。
- 模式稳定锁锁定:它和共享锁很相似;这个锁的唯一目的是方式模式修改锁,因为在该对象上已有其他查询(或CREATE、ALTER、DROP语句)的锁。它与其他所有的锁定相兼容。
6、批量更新锁
批量更新锁(BU)只是一种略有不同的表锁定变体形式。批量更新锁允许并行加载数据。也就是说,对于其他任何普通操作(T-SQL)都会将表锁定,但可以同时执行多个BULK INSERT或bcp操作。
锁的兼容性
锁的资源锁定模式的兼容性表格,现有锁以列显示,要兼容的锁以行显示。
锁的类型 意向共享锁(IS) 共享锁(S) 更新锁(U) 意向排他锁(IX) 共享意向排它锁(SIX) 排他锁(X) 意向共享锁(IS) 是 是 是 是 是 否 共享锁(S) 是 是 是 否 否 否 更新锁(U) 是 是 否 否 否 否 意向排他锁(IX) 是 否 否 是 否 否 共享意向排它锁(SIX) 是 否 否 否 否 否 排他锁(X) 否 否 否 否 否 否 另外:
- Sch-S与出Sch-M以外的所有锁定模式相兼容。
- Sch-M和所有的锁定模式不兼容。
- BU只与模式稳定性锁以及其他的批量更新锁相兼容。
有时想要在查询中或在整个事务中对锁定有更多的控制。可以通过使用优化器提示(optimizer hints)来实现这一点。
优化器提示明确告诉SQL Server将一个锁升级为特有的层次。这些提示信息包含在将要影响的表的名称之后。
优化器提示是一个高级主题,有经验的SQL Server开发人员会经常使用它,并且他们相当重视它。
使用Management Studio确定锁
查看锁的最好方式是使用Management Studio。通过使用Activity Monitor,Management Studio会以两种方式显示锁-通过processId或object。
为了使用Management Studio显示锁,只要导航到<Server>的Activity Monitor节点,其中的<Server>是监控其活动的服务器的顶级节点。
展开感兴趣的节点(Overview部分默认展开),可以通过滚动条查看大量度量值-包括当前系统中有效的锁。

显示界面如下:

设置隔离级别
事务和锁之间的联系是很紧密的。默认情况下,一旦创建了任何与数据修改相关的锁,该锁定就会在整个事务期间存在。如果有一个大型事务,就意味着将在很长一段时间内阻止其他进程访问锁定的对象。这明显是有问题的。
事务有5种隔离级别:
- READ COMMITTED
- READ UNCOMMITTED
- REPEATABLE READ
- SERIALIZABLE
- SNAPSHOT
在这些隔离级别之间进行切换的语法也相当直观:
SET TRANSACTION ISOLATION LEVEL < READ COMMITTED | READ UNCOMMITTED | REPEATABLE READ | SERIALIZABLE | SNAPSHOT >
对隔离级别的修改只会影响到当前的连接-所以不必担心会影响到其他的用户。其他用户也影响不了你。
1、READ COMMITTED
默认情况就是这个,通过READ COMMITTED,任何创建的共享锁将在创建它们的语句完成后自动释放。也就是说,如果启动了一个事务,运行了一些语句,然后运行SELECT语句,再运行一些其他的语句,那么当SELECT语句完成的时候,与SELECT语句相关联的锁就会释放 - SQL Server并不会等到事务结束。
动作查询(UPDATE、DELETE、INSERT)有点不同。如果事务执行了修改数据的查询,则这些锁将会在事务期间保持有效。
通过设置READ COMMITTED这一默认隔离级别,可以确定有足够的数据完整性来防止脏读。然而,仍会发生非重复性读取和幻读。
2、READ UNCOMMITTED
READ UNCOMMITTED是所有隔离级别中最危险的,但是它在速度方面有最好的性能。
设置隔离级别为READ UNCOMMITTED将告诉SQL Server不要设置任何锁,也不要事先任何锁。
锁既是你的保护者,同时也是你的敌人。锁可以防止数据完整性问题,但是锁也经常妨碍或阻止你访问需要的数据。由于此锁存在脏读的危险,因此此锁只能应用于并非十分精确的环境中。3、REPEATABLE READ
REPEATABLE READ会稍微地将隔离级别升级,并提供一个额外的并发保护层,这不仅能防止脏读,而且能防止非重复性读取。
防止非重复性读取是很大的优势,但是直到事务结束还保持共享锁会阻止用户访问对象,因此会影响效率。推荐使用其他的数据完整性选项,例如CHECK约束,而不是采用这个选择。
与REPEATABLE READ隔离级别等价的优化器提示是REPEATABLEREAD(除了一个空格,两者并无不同)。4、SERIALIZABLE
SERIALIZABLE是堡垒级的隔离级别。除了丢失更新以外,它防止所有形式的并发问题。甚至能防止幻读。
如果设置隔离级别为SERIALIZABLE,就意味着对事物使用的表进行的任何UPDATE、DELETE、INSERT操作绝对不满足该事务中任何语句的WHERE子句的条件。从本质上说,如果用户想执行一些事务感兴趣的事情,那么必须等到该事务完成的时候。
SERIALIZABLE隔离级别也可以通过查询中使用SERIALIZABLE或HOLDLOCK优化器提示模拟。再次申明,类似于READ UNCOMMITTED和NOLOCK,前者不需要每次都设置,而后者需要把隔离级别设置回来。
5、SNAPSHOT
SNAPSHOT是最新的一种隔离级别,非常想READ COMMITTED和READ UNCOMMITTED的组合。要注意的是,SNAPSHOT默认是不可用的-只有为数据库打开了ALLOW_SNAPSHOT_ISOLATION特殊选项时,SNAPSHOT才可用。
和READ UNCOMMITED一样,SNAPSHOT并不创建任何锁,也不实现人和所。两者的主要区别是它们识别数据库中不同时段发生的更改。数据库中的更改,不管何时或是否提交,都会被运行READ UNCOMMITTED隔离级别的查询看到。而使用SNAPSHOT,只能看到在SNAPSHOT事务开始之前提交的更改。从SNAPSHOT事务一开始执行,所有查看到的数据就和在时间开始时提交的一样。处理死锁
死锁的错误号是1205。
如果一个锁由于另一个锁占有资源而不能完成应该做的清除资源工作,就会导致死锁;反之亦然。当发生死锁时,需要其中的一方赢得这场斗争,所以SQL Server选择一个死锁牺牲者,对死锁牺牲者的事务进行回滚,并且通过1205错误来通知发生了死锁。另外一个事务将继续正常地运行。
1、判断死锁的方式
每隔5秒钟,SQL Server就会检查所有当前的事务,了解他们在等待什么还未被授予的锁。然后再一次重新检查所有打开的锁请求的状态,如果先前请求中有一个还没有被授予,则它会递归地检查所有打开的事务,寻找锁定请求的循环链。如果SQL Server找到这样的村换连,则将会选择一个或更多的死锁牺牲者。
2、选择死锁牺牲者的方式
默认情况下,基于相关事务的"代价",选择死锁牺牲者。SQL Server将会选择回滚代价最低的事务。在一定程度上,可以使用SQL Server中的DEADLOCK_PRIORITY SET选项来重写它。
3、避免死锁
避免死锁的常用规则
- 按相同的顺序使用对象
- 使事务尽可能简短并且在一个批处理中。
- 尽可能使用最低的事务隔离级别。
- 在同一事务中不允许无限度的中断。
- 在控制环境中,使用绑定连接。
1、按相同的顺序使用对象
例如有两个表:Suppliers和Products。假设有两个进程将使用这两个表。进程1接受库存输入,用手头新的产品总量更新Products表,接下来用已经购买的产品总量来更新Suppliers表。进程2记录销售数据,它在Supperlier表中更新销售产品的总量,然后在Product中减少库存数量。
如果同时运行这两个进程,那么就有可能碰到麻烦。进程1试图获取Product表上的一个排他锁。进程2将在Suppliers表上获取一个排他锁。然后进程1将试图获取Suppliers表上的一个锁,但是进程1必须等到进程2清除了现有的锁。同时进程2也在等待进程1清除现有锁。
上面的例子是,两个进程用相反的顺序,锁住两个表,这样就很容易发生死锁。
如果我们将进程2改成首先在Products减少库存数量,接着在Suppliers表中更新销售产品的总数量。两个进程以相同的顺序访问两张表,这样就能够减少死锁的发生。
2、使事务尽可能简短
保持事务的简短将不会让你付出任何的代价。在事务中放入想要的内容,把不需要的内容拿出来,就这么简单。它的原理并不复杂-事务打开的时间越长,它触及的内容就越多,那么其他一些进程想要得到正在使用的一个或者多个对象的可能性就越大。如果要保持事务简短,那么就将最小化可能引起死锁的对象的数量,还将减少锁定对象的时间。原理就如此简单。
3、尽可能使用最低的事务隔离级别
使用较低的隔离级别和较高的隔离级别相比,共享锁持续的时间更短,因此会减少锁的竞争。
4、不要采用允许无限中断的事务
当开始执行某种开放式进程时间,不要创建将一直占有资源的锁。通常,指的是用户交互,但它也可能是允许无限等待的任何进程。
-
软件架构之 23种设计模式
创建型模式
1、FACTORY—追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说“来四个鸡翅”就行了。麦当劳和肯德基就是生产鸡翅的Factory
工厂模式:客户类和工厂类分开。消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。缺点是当产品修改时,工厂类也要做相应的修改。如:如何创建及如何向客户端提供。
2、 BUILDER—MM最爱听的就是“我爱你”这句话了,见到不同地方的MM,要能够用她们的方言跟她说这句话哦,我有一个多种语言翻译机,上面每种语言都 有一个按键,见到MM我只要按对应的键,它就能够用相应的语言说出“我爱你”这句话了,国外的MM也可以轻松搞掂,这就是我的“我爱你”builder。 (这一定比美军在伊拉克用的翻译机好卖)
建造模式:将产品的内部表象和产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。建造模式使得产品内部表象可以独立的变化,客户不必知道产品内部组成的细节。建造模式可以强制实行一种分步骤进行的建造过程。
3、FACTORY METHOD—请MM去麦当劳吃汉堡,不同的MM有不同的口味,要每个都记住是一件烦人的事情,我一般采用Factory Method模式,带着MM到服务员那儿,说“要一个汉堡”,具体要什么样的汉堡呢,让MM直接跟服务员说就行了。
工厂方法模式:核心工厂类不再负责所有产品的创建,而是将具体创建的工作交给子类去做,成为一个抽象工厂角色,仅负责给出具体工厂类必须实现的接口,而不接触哪一个产品类应当被实例化这种细节。
4、PROTOTYPE—跟MM用QQ聊天,一定要说些深情的话语了,我搜集了好多肉麻的情话,需要时只要copy出来放到QQ里面就行了,这就是我的情话prototype了。(100块钱一份,你要不要)
原 始模型模式:通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的方法创建出更多同类型的对象。原始模型模式允许动态的增加或减少 产品类,产品类不需要非得有任何事先确定的等级结构,原始模型模式适用于任何的等级结构。缺点是每一个类都必须配备一个克隆方法。
5、SINGLETON—俺有6个漂亮的老婆,她们的老公都是我,我就是我们家里的老公Sigleton,她们只要说道“老公”,都是指的同一个人,那就是我(刚才做了个梦啦,哪有这么好的事)
单例模式:单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例单例模式。单例模式只应在有真正的“单一实例”的需求时才可使用。
结构型模式
6、ADAPTER—在朋友聚会上碰到了一个美女Sarah,从香港来的,可我不会说粤语,她不会说普通话,只好求助于我的朋友kent了,他作为我和Sarah之间的Adapter,让我和Sarah可以相互交谈了(也不知道他会不会耍我)
适配器(变压器)模式:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口原因不匹配而无法一起工作的两个类能够一起工作。适配类可以根据参数返还一个合适的实例给客户端。
7、BRIDGE—早上碰到MM,要说早上好,晚上碰到MM,要说晚上好;碰到MM穿了件新衣服,要说你的衣服好漂亮哦,碰到MM新做的发型,要说你的头发好漂亮哦。不要问我“早上碰到MM新做了个发型怎么说”这种问题,自己用BRIDGE组合一下不就行了
桥梁模式:将抽象化与实现化脱耦,使得二者可以独立的变化,也就是说将他们之间的强关联变成弱关联,也就是指在一个软件系统的抽象化和实现化之间使用组合/聚合关系而不是继承关系,从而使两者可以独立的变化。
8、 COMPOSITE—Mary今天过生日。“我过生日,你要送我一件礼物。”“嗯,好吧,去商店,你自己挑。”“这件T恤挺漂亮,买,这条裙子好看,买, 这个包也不错,买。”“喂,买了三件了呀,我只答应送一件礼物的哦。”“什么呀,T恤加裙子加包包,正好配成一套呀,小姐,麻烦你包起 来。”“……”,MM都会用Composite模式了,你会了没有?
合成模式:合成模式将对象组织到树结构中,可以用来描述整体与部分的关系。合成模式就是一个处理对象的树结构的模式。合成模式把部分与整体的关系用树结构表示出来。合成模式使得客户端把一个个单独的成分对象和由他们复合而成的合成对象同等看待。
9、 DECORATOR—Mary过完轮到Sarly过生日,还是不要叫她自己挑了,不然这个月伙食费肯定玩完,拿出我去年在华山顶上照的照片,在背面写上 “最好的的礼物,就是爱你的Fita”,再到街上礼品店买了个像框(卖礼品的MM也很漂亮哦),再找隔壁搞美术设计的Mike设计了一个漂亮的盒子装起 来……,我们都是Decorator,最终都在修饰我这个人呀,怎么样,看懂了吗?
装饰模式:装饰模式以对客户端透明的方式扩展对象的功能,是继承关系的一个替代方案,提供比继承更多的灵活性。动态给一个对象增加功能,这些功能可以再动态的撤消。增加由一些基本功能的排列组合而产生的非常大量的功能。
10、FACADE—我有一个专业的Nikon相机,我就喜欢自己手动调光圈、快门,这样照出来的照片才专业,但MM可不懂这些,教了半天也不会。幸好相机有Facade设计模式 ,把相机调整到自动档,只要对准目标按快门就行了,一切由相机自动调整,这样MM也可以用这个相机给我拍张照片了。
门面模式:外部与一个子系统的通信必须通过一个统一的门面对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。每一个子系统只有一个门面类,而且此门面类只有一个实例,也就是说它是一个单例模式。但整个系统可以有多个门面类。
11、 FLYWEIGHT—每天跟MM发短信,手指都累死了,最近买了个新手机,可以把一些常用的句子存在手机里,要用的时候,直接拿出来,在前面加上MM的名 字就可以发送了,再不用一个字一个字敲了。共享的句子就是Flyweight,MM的名字就是提取出来的外部特征,根据上下文情况使用。
享 元模式:FLYWEIGHT在拳击比赛中指最轻量级。享元模式以共享的方式高效的支持大量的细粒度对象。享元模式能做到共享的关键是区分内蕴状态和外蕴状 态。内蕴状态存储在享元内部,不会随环境的改变而有所不同。外蕴状态是随环境的改变而改变的。外蕴状态不能影响内蕴状态,它们是相互独立的。将可以共享的 状态和不可以共享的状态从常规类中区分开来,将不可以共享的状态从类里剔除出去。客户端不可以直接创建被共享的对象,而应当使用一个工厂对象负责创建被共 享的对象。享元模式大幅度的降低内存中对象的数量。
12、PROXY—跟MM在网上聊天,一开头总是“hi,你好”,“你从哪儿来呀?”“你多大了?”“身高多少呀?”这些话,真烦人,写个程序做为我的Proxy吧,凡是接收到这些话都设置好了自动的回答,接收到其他的话时再通知我回答,怎么样,酷吧。
代 理模式:代理模式给某一个对象提供一个代理对象,并由代理对象控制对源对象的引用。代理就是一个人或一个机构代表另一个人或者一个机构采取行动。某些情况 下,客户不想或者不能够直接引用一个对象,代理对象可以在客户和目标对象直接起到中介的作用。客户端分辨不出代理主题对象与真实主题对象。代理模式可以并 不知道真正的被代理对象,而仅仅持有一个被代理对象的接口,这时候代理对象不能够创建被代理对象,被代理对象必须有系统的其他角色代为创建并传入。
行为模式
13、 CHAIN OF RESPONSIBLEITY—晚上去上英语课,为了好开溜坐到了最后一排,哇,前面坐了好几个漂亮的MM哎,找张纸条,写上“Hi,可以做我的女朋友 吗?如果不愿意请向前传”,纸条就一个接一个的传上去了,糟糕,传到第一排的MM把纸条传给老师了,听说是个老处女呀,快跑!
责任链模式:在责任链模式中,很多对象由每一个对象对其下家的引用而接
起 来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。客户并不知道链上的哪一个对象最终处理这个请求,系统可以在不影响客户端的情况 下动态的重新组织链和分配责任。处理者有两个选择:承担责任或者把责任推给下家。一个请求可以最终不被任何接收端对象所接受。
14、 COMMAND—俺有一个MM家里管得特别严,没法见面,只好借助于她弟弟在我们俩之间传送信息,她对我有什么指示,就写一张纸条让她弟弟带给我。这不, 她弟弟又传送过来一个COMMAND,为了感谢他,我请他吃了碗杂酱面,哪知道他说:“我同时给我姐姐三个男朋友送COMMAND,就数你最小气,才请我 吃面。”,:-(
命 令模式:命令模式把一个请求或者操作封装到一个对象中。命令模式把发出命令的责任和执行命令的责任分割开,委派给不同的对象。命令模式允许请求的一方和发 送的一方独立开来,使得请求的一方不必知道接收请求的一方的接口,更不必知道请求是怎么被接收,以及操作是否执行,何时被执行以及是怎么被执行的。系统支 持命令的撤消。
15、INTERPRETER—俺有一个《泡MM真经》,上面有各种泡MM的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟MM约会时,只要做一个Interpreter,照着上面的脚本执行就可以了。
解 释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式 将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定 义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何 排列组合都是一个语言。
16、ITERATOR—我爱上了Mary,不顾一切的向她求婚。
Mary:“想要我跟你结婚,得答应我的条件”
我:“什么条件我都答应,你说吧”
Mary:“我看上了那个一克拉的钻石”
我:“我买,我买,还有吗?”
Mary:“我看上了湖边的那栋别墅”
我:“我买,我买,还有吗?”
Mary:“你的小弟弟必须要有50cm长”
我脑袋嗡的一声,坐在椅子上,一咬牙:“我剪,我剪,还有吗?”
……
迭 代子模式:迭代子模式可以顺序访问一个聚集中的元素而不必暴露聚集的内部表象。多个对象聚在一起形成的总体称之为聚集,聚集对象是能够包容一组对象的容器 对象。迭代子模式将迭代逻辑封装到一个独立的子对象中,从而与聚集本身隔开。迭代子模式简化了聚集的界面。每一个聚集对象都可以有一个或一个以上的迭代子 对象,每一个迭代子的迭代状态可以是彼此独立的。迭代算法可以独立于聚集角色变化。
17、MEDIATOR—四个MM打麻将,相互之间谁应该给谁多少钱算不清楚了,幸亏当时我在旁边,按照各自的筹码数算钱,赚了钱的从我这里拿,赔了钱的也付给我,一切就OK啦,俺得到了四个MM的电话。
调 停者模式:调停者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显作用。从而使他们可以松散偶合。当某些对象之间的作用发生改变时,不会立 即影响其他的一些对象之间的作用。保证这些作用可以彼此独立的变化。调停者模式将多对多的相互作用转化为一对多的相互作用。调停者模式将对象的行为和协作 抽象化,把对象在小尺度的行为上与其他对象的相互作用分开处理。
18、MEMENTO—同时跟几个MM聊天时,一定要记清楚刚才跟MM说了些什么话,不然MM发现了会不高兴的哦,幸亏我有个备忘录,刚才与哪个MM说了什么话我都拷贝一份放到备忘录里面保存,这样可以随时察看以前的记录啦。
备忘录模式:备忘录对象是一个用来存储另外一个对象内部状态的快照的对象。备忘录模式的用意是在不破坏封装的条件下,将一个对象的状态捉住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。
19、OBSERVER—想知道咱们公司最新MM情报吗?加入公司的MM情报邮件组就行了,tom负责搜集情报,他发现的新情报不用一个一个通知我们,直接发布给邮件组,我们作为订阅者(观察者)就可以及时收到情报啦
观察者模式:观察者模式定义了一种一队多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自动更新自己。
20、 STATE—跟MM交往时,一定要注意她的状态哦,在不同的状态时她的行为会有不同,比如你约她今天晚上去看电影,对你没兴趣的MM就会说“有事情啦”, 对你不讨厌但还没喜欢上的MM就会说“好啊,不过可以带上我同事么?”,已经喜欢上你的MM就会说“几点钟?看完电影再去泡吧怎么样?”,当然你看电影过 程中表现良好的话,也可以把MM的状态从不讨厌不喜欢变成喜欢哦。
状 态模式:状态模式允许一个对象在其内部状态改变的时候改变行为。这个对象看上去象是改变了它的类一样。状态模式把所研究的对象的行为包装在不同的状态对象 里,每一个状态对象都属于一个抽象状态类的一个子类。状态模式的意图是让一个对象在其内部状态改变的时候,其行为也随之改变。状态模式需要对每一个系统可 能取得的状态创立一个状态类的子类。当系统的状态变化时,系统便改变所选的子类。
21、STRATEGY—跟不同类型的MM约会,要用不同的策略,有的请电影比较好,有的则去吃小吃效果不错,有的去海边浪漫最合适,单目的都是为了得到MM的芳心,我的追MM锦囊中有好多Strategy哦。
策 略模式:策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下 发生变化。策略模式把行为和环境分开。环境类负责维持和查询行为类,各种算法在具体的策略类中提供。由于算法和环境独立开来,算法的增减,修改都不会影响 到环境和客户端。
22、 TEMPLATE METHOD——看过《如何说服女生上床》这部经典文章吗?女生从认识到上床的不变的步骤分为巧遇、打破僵局、展开追求、接吻、前戏、动手、爱抚、进去八 大步骤(Template method),但每个步骤针对不同的情况,都有不一样的做法,这就要看你随机应变啦(具体实现);
模 板方法模式:模板方法模式准备一个抽象类,将部分逻辑以具体方法以及具体构造子的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可 以以不同的方式实现这些抽象方法,从而对剩余的逻辑有不同的实现。先制定一个顶级逻辑框架,而将逻辑的细节留给具体的子类去实现。
23、 VISITOR—情人节到了,要给每个MM送一束鲜花和一张卡片,可是每个MM送的花都要针对她个人的特点,每张卡片也要根据个人的特点来挑,我一个人哪 搞得清楚,还是找花店老板和礼品店老板做一下Visitor,让花店老板根据MM的特点选一束花,让礼品店老板也根据每个人特点选一张卡,这样就轻松多 了;
访 问者模式:访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构可以保持不变。访问者模式适 用于数据结构相对未定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,使得操作集合可以相对自由的演化。访问者模式使得增加新的操作变的很容 易,就是增加一个新的访问者类。访问者模式将有关的行为集中到一个访问者对象中,而不是分散到一个个的节点类中。当使用访问者模式时,要将尽可能多的对象 浏览逻辑放在访问者类中,而不是放到它的子类中。访问者模式可以跨过几个类的等级结构访问属于不同的等级结构的成员类。
-
Oracle与Sqlserver:Order by NULL值介绍
针对页面传参到in的子集中去进行查询操作的话,就会有in(xxx,null),这样就会导致查询的结果中其实直接过滤掉了null,根本就查不出来null的值。之前对于null的操作都是进行不同数据库的null函数来进行选择nvl、isnull、ifnull等,直接将字段的null进行转换后再操作。
只知道要对数据库中的null进行转换的操作,但是不知所云,所以今天就大致了解下。针对oracle的null的基本操作:
一、null值的介绍
NULL 是数据库中特有的数据类型,当一条记录的某个列为 NULL ,则表示这个列的值是未知的、是不确定的。既然是未知的,就有无数种的可能性。因此, NULL 并不是一个确定的值。 这是 NULL 的由来、也是 NULL的基础,所有和 NULL 相关的操作的结果都可以从 NULL 的概念推导出来。
二、oracle中的null值介绍
在不知道具体有什么数据的时候,即未知,可以用NULL, 称它为空,ORACLE中,含有空值的表列长度为零。允许任何一种数据类型的字段为空,除了以下两种情况:
a、主键字段(primary key);
b、定义时已经加了NOT NULL限制条件的字段
三、Oracle中null值说明:
a、等价于没有任何值、是未知数。
b、NULL与0、空字符串、空格都不同。
c、对空值做加、减、乘、除等运算操作,结果 仍为空。
d、NULL的处理使用NVL函数。
e、比较时使用关键字用“is null”和“is not null”。
f、空值不能被索引,所以查询时有些符合条件的数据可能查不出来, count(expr)中,用nvl(列名,0)处理后再查。
g、排序时比其他数据都大(索引默认是降序排列,小→大), 所以NULL值总是排在最后。
IS NULL 和IS NOT NULL 是不可分割的整体,改为IS 或IS NOT都是错误的,从上面我们看到了NULL 和空字符串的区别。
任何和NULL 的比较操作,如<>、=、<=等都返回UNKNOWN(这里的unknown就是null,它单独使用和布尔值false类似).判断和比较规则总结如下:

四、null做一些算术运算
比如+,-,*,/等,结果 还是null,但是对于连接操作符||,null忽略,concat函数也忽略null
五、null相关函数规则
Oracle有nvl、nvl2、nullif、coalesce等函数专门处理null
nvl(expr1,expr2):如果expr1是null,那么用expr2作为返回值,不是null则返回expr1.expr1与expr2一般是类型相同的,如果类型不同则会采用自动转换,转换失败则报错。
nvl2(expr1,expr2,expr3):expr1如果是null,则返回expr3,否则返回expr2,expr2和expr3类型不同,expr3类型转换为expr2类型
nullif(expr1,expr2):判断expr1和expr2是否相等,若相等则返回null,否则返回expr1.要求expr1与expr2类型必须相同
coalesce(expr1,expr2,…,exprn):从左到右返回第一个为非null的值,若所有的列表元素都为null,则返回null。要求所有都必须为同一类型。
六、null与索引
Oracle中的B*Tree索引,并不存储全为null的列,虽然在表中建立了符合UNIQUE 索引,但是全为null的行还是可以插入的,而不是全为null的重复行则不可以插入。因为在UNIQUE约束中,(null,null)和(null,null)是不同的,当然在其他一些情况,比如说分组、集合操作中都认为全是null是相等的
七、null的排序
order by默认升序(asc),这时候null是排在最后的,如果指定降序那么null是排在最前面的,认为null最大。
但是可以用nulls first和nulls last进行调整。order by comm asc nulls first/last
八、null与性能的关系
Not null约束,定义约束是要付出消耗性能的代价的,由下面的测试可以看出虽然约束检查的很快,但是有时候还是很消耗资源的,至少在这个例子上是这样的,不需要not null约束,除非必要,不要乱定义约束。
九、动态语句中的绑定变量与null
在PL/SQL中动态SQL和动态PL/SQL经常使用绑定变量,这个绑定变量有个要求,就是不能直接传入字面量null值,因为PL/SQL中动态语句要求传入的绑定变量必须是SQL类型,而字面量null是无类型的,null字面量传入是不可以的。
当然可以采用多种方法,如果一定要传入null,则可以将null改为空字符串、TO_NUMBER,TO_CHAR,TO_DATE等函数进行转换,或定义一个未初始化的变量、直接传入变量等。即不能定义一参数赋值null,必须先给予其他的赋值结果。
针对sqlserver的null的基本操作:
一、使用 =null / <>null 默认情况下的确不能使用 =null / <> null 来判断 null 值如此。实际上 SQL Server 可以 使用 SET ANSI_NULLS { ON | OFF } 设定来控制 =null / <>null 的行为。
当 SET ANSI_NULLS 为 ON 时,即使 column_name 中包含空值,使用 WHERE column_name = NULL的 SELECT 语句仍返回零行。
即使 column_name 中包含非空值,使用 WHERE column_name <> NULL 的 SELECT 语句仍会返回零行
但是当 SET ANSI_NULLS 为 OFF 时,等于 (=) 和不等于 (<>) 比较运算符不遵守 ISO 标准。
使用 WHERE column_name = NULL 的 SELECT 语句返回 column_name 中包含空值的行。
使用 WHERE column_name <> NULL 的 SELECT 语句返回列中包含非空值的行。
此外,使用 WHERE column_name <> XYZ_value 的 SELECT 语句返回所有不为 XYZ_value 也不为 NULL的行。
二、 改变 null 值的连接行为 SQL Server 提供 SET CONCAT_NULL_YIELDS_NULL { ON | OFF } 来控制null 与其它字符串连接的行为。
当 SET CONCAT_NULL_YIELDS_NULL 为 ON 时,串联空值与字符串将产生 NULL 结果。例如, SELECT 'abc' + NULL 将生成 NULL 。
当 SET CONCAT_NULL_YIELDS_NULL 为 OFF 时,串联空值与字符串将产生字符串本身(空值作为空字符串处理)。例如, SELECT 'abc' + NULL 将生成 abc 。
如果未指定 SET CONCAT_NULL_YIELDS ,则应用 CONCAT_NULL_YIELDS_NULL 数据库选项的设置。
注:在 SQL Server 的未来版本中, CONCAT_NULL_YIELDS_NULL 将始终为 ON ,而且将该选项显式设置为 OFF 的任何应用程序都将产生一个错误。
三、变量的默认值与 null 值
命名一个变量后,如果没有给它赋初始值,它的值就是 null 。有时候需要注意初始 null 值和通过 select 语句给变量后期赋 null 的区别。因为此 ‘null’ 非彼 ‘null’ 。
1. 子查询中的 null
子查询中出现的 null 值经常会被我们忽视。
2. Case 语句中的 null
Case 中的 when 语句注意不要写成 when null, 否则得不到想要的结果。
四、 与 null 相关的函数
ISNULL ISNULL 检测表达式是否为 NULL ,如果是的话替换 NULL 值为另外一个值 COALESCE COALESCE函数返回指定表达式列表的第一个非 NULL 值 NULLIF 当指定的两个表达式有相同值的时候 NULLIF 返回 NULL值,否则返回第一个表达式的值
针对Sqlserver与Oracle中null值的不同:
一、在SQL Server中与oracle正相反,NULL值会被认为是一个无穷小的值,所以如果按照升序排列的话,则会被排在最前面
二、SQL Server和Oracle中对插入数据值包含空的处理有所差异,在SQL Server中,我们可以把表字段设计为非空,但我们仍然可以通过下面语句执行插入操作:
INSERT INTO Table (TestCol) VALUES(‘’)
其中的TestCol字段,在设计的时候,已经被设计为NOT NULL在sql server中,null和空格是不同的,也就是说,上面的语句插入的是一个空,但并不是NULL,只有当我们的插入语句中没有该字段的时候,才会被认为违反非空的条件约束,如果把NULL翻译成“空”的话,可能就会很容易搞混了。此外,如果我们的字段是INT类型的话,如果我们插入空的话,会得到一个0,也就是说,Sql server会自动帮我们处理对空格的转化。
但是在Oracle中,这个便利便不存在了,必须严格按照规则来进行插入,也就是说,我们再想视图通过插入空来满足NOT NULL的设计约束,已经不能成功了,必须插入实实在在的内容才能符合NOT NULL的约束。
注:这里没有将举例copy过来,例子都是比较显而易见的。了解了null的基本操作之后,就好尴尬啊。如果字段值中存储了null值在oracle中我们有想通过in的方式来查询出来这个null值就基本不可能了。只有将字段进行函数处理nvl(column_name,’_NA_’) in(xxxx, ’_NA_’)来实现了,或者column_name in (xxxx) or column_name is null。
不过针对这些存储了null的字段并且在查询过程中使用了in,多字段的查询针对性的建立索引也是没有什么用的。null值也会给索引增加负担,报表中的多条件查询也不会同时都走上索引。只能乖乖的使用nvl来进行转化后的筛选条件下的全扫描。
sql server 中order by 中关于null值处理
sqlserver 认为 null 最小。
升序排列:null 值默认排在最前。
要想排后面,则:order by case when col is null then 1 else 0 end ,col
降序排列:null 值默认排在最后。
要想排在前面,则:order by case when col is null then 0 else 1 end , col desc1、on 、where、having中把unknown当作FALSE处理,使用筛选器为unknown的行会排除在外,
而check约束中的unknown的值被当做true,假设一个check约束中要求salary大于0,插入salary为null
的行可以被接受 NUll > 0 的结果为unknown
2、unique约束、排序、分组认为两个NULL是相等的
如果表的一列被定义为unique约束,将不能插入两个为NULL值得行
group by 把所有null分为一组
order by 把所有的null值排列在一起select distinct top col from t order by col
先执行distinct –》order by –》top -
asp.net MVC漏油配置总结
URL构造
命名参数规范+匿名对象
routes.MapRoute(name:"Default",url:"{controller}/{action}/{id}", defaults:new{ controller ="Home", action ="Index", id = UrlParameter.Optional } );构造路由然后添加
Route myRoute =newRoute("{controller}/{action}",newMvcRouteHandler());routes.Add("MyRoute", myRoute);直接方法重载+匿名对象
1routes.MapRoute("ShopSchema","Shop/{action}",new{ controller ="Home"});个人觉得第一种比较易懂,第二种方便调试,第三种写起来比较效率吧。各取所需吧。本文行文偏向于第三种。
路由规则
1.默认路由(MVC自带)
routes.MapRoute("Default",// 路由名称"{controller}/{action}/{id}",// 带有参数的 URLnew{ controller ="Home", action ="Index", id = UrlParameter.Optional }// 参数默认值 (UrlParameter.Optional-可选的意思) );2.静态URL段
routes.MapRoute("ShopSchema2","Shop/OldAction",new{ controller ="Home", action ="Index"});routes.MapRoute("ShopSchema","Shop/{action}",new{ controller ="Home"});routes.MapRoute("ShopSchema2","Shop/OldAction.js",new{ controller ="Home", action ="Index"});没有占位符路由就是现成的写死的。
比如这样写然后去访问http://localhost:XXX/Shop/OldAction.js,response也是完全没问题的。 controller , action , area这三个保留字就别设静态变量里面了。
3.自定义常规变量URL段(好吧这翻译暴露智商了)
routes.MapRoute("MyRoute2","{controller}/{action}/{id}",new{ controller ="Home", action ="Index", id ="DefaultId"});这种情况如果访问 /Home/Index 的话,因为第三段(id)没有值,根据路由规则这个参数会被设为DefaultId
这个用viewbag给title赋值就能很明显看出
ViewBag.Title = RouteData.Values["id"];图不贴了,结果是标题显示为DefaultId。 注意要在控制器里面赋值,在视图赋值没法编译的。
4.再述默认路由
然后再回到默认路由。 UrlParameter.Optional这个叫可选URL段.路由里没有这个参数的话id为null。 照原文大致说法,这个可选URL段能用来实现一个关注点的分离。刚才在路由里直接设定参数默认值其实不是很好。照我的理解,实际参数是用户发来的,我们做的只是定义形式参数名。但是,如果硬要给参数赋默认值的话,建议用语法糖写到action参数里面。比如:
1publicActionResult Index(stringid ="abcd"){ViewBag.Title = RouteData.Values["id"];returnView();}5.可变长度路由。
1routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional });在这里id和最后一段都是可变的,所以 /Home/Index/dabdafdaf 等效于 /Home/Index//abcdefdjldfiaeahfoeiho 等效于 /Home/Index/All/Delete/Perm/.....
6.跨命名空间路由
这个提醒一下记得引用命名空间,开启IIS网站不然就是404。这个非常非主流,不建议瞎搞。
1routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new[] {"URLsAndRoutes.AdditionalControllers","UrlsAndRoutes.Controllers"});但是这样写的话数组排名不分先后的,如果有多个匹配的路由会报错。 然后作者提出了一种改进写法。
routes.MapRoute("AddContollerRoute","Home/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new[] {"URLsAndRoutes.AdditionalControllers"});routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new[] {"URLsAndRoutes.Controllers"});这样第一个URL段不是Home的都交给第二个处理 最后还可以设定这个路由找不到的话就不给后面的路由留后路啦,也就不再往下找啦。
1234Route myRoute = routes.MapRoute("AddContollerRoute","Home/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new[] {"URLsAndRoutes.AdditionalControllers"}); myRoute.DataTokens["UseNamespaceFallback"] =false;7.正则表达式匹配路由
1234routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new{ controller ="^H.*"},new[] {"URLsAndRoutes.Controllers"});约束多个URL
1234routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new{ controller ="^H.*", action ="^Index$|^About$"},new[] {"URLsAndRoutes.Controllers"});8.指定请求方法
1234567routes.MapRoute("MyRoute","{controller}/{action}/{id}/{*catchall}",new{ controller ="Home", action ="Index", id = UrlParameter.Optional },new{ controller ="^H.*", action ="Index|About", httpMethod =newHttpMethodConstraint("GET") },new[] {"URLsAndRoutes.Controllers"});9. WebForm支持
1234567routes.MapPageRoute("","","~/Default.aspx");routes.MapPageRoute("list","Items/{action}","~/Items/list.aspx",false,newRouteValueDictionary { {"action","all"} });routes.MapPageRoute("show","Show/{action}","~/show.aspx",false,newRouteValueDictionary { {"action","all"} });routes.MapPageRoute("edit","Edit/{id}","~/edit.aspx",false,newRouteValueDictionary { {"id","1"} },newRouteValueDictionary { {"id",@"\d+"} });具体的可以看
使用Asp.Net4新特性路由创建WebForm应用
或者官方msdn
10.MVC5的RouteAttribute
首先要在路由注册方法那里
12//启用路由特性映射routes.MapMvcAttributeRoutes();这样
1[Route("Login")]route特性才有效.该特性有好几个重载.还有路由约束啊,顺序啊,路由名之类的.
其他的还有路由前缀,路由默认值
1[RoutePrefix("reviews")]<br>[Route("{action=index}")]<br>publicclassReviewsController : Controller<br>{<br>}路由构造
1234567// eg: /users/5[Route("users/{id:int}"]publicActionResult GetUserById(intid) { ... }// eg: users/ken[Route("users/{name}"]publicActionResult GetUserByName(stringname) { ... }参数限制
12345// eg: /users/5// but not /users/10000000000 because it is larger than int.MaxValue,// and not /users/0 because of the min(1) constraint.[Route("users/{id:int:min(1)}")]publicActionResult GetUserById(intid) { ... }Constraint Description Example alpha Matches uppercase or lowercase Latin alphabet characters (a-z, A-Z) {x:alpha} bool Matches a Boolean value. {x:bool} datetime Matches a DateTime value. {x:datetime} decimal Matches a decimal value. {x:decimal} double Matches a 64-bit floating-point value. {x:double} float Matches a 32-bit floating-point value. {x:float} guid Matches a GUID value. {x:guid} int Matches a 32-bit integer value. {x:int} length Matches a string with the specified length or within a specified range of lengths. {x:length(6)} {x:length(1,20)} long Matches a 64-bit integer value. {x:long} max Matches an integer with a maximum value. {x:max(10)} maxlength Matches a string with a maximum length. {x:maxlength(10)} min Matches an integer with a minimum value. {x:min(10)} minlength Matches a string with a minimum length. {x:minlength(10)} range Matches an integer within a range of values. {x:range(10,50)} regex Matches a regular expression. {x:regex(^\d{3}-\d{3}-\d{4}$)} 具体的可以参考
Attribute Routing in ASP.NET MVC 5
对我来说,这样的好处是分散了路由规则的定义.有人喜欢集中,我个人比较喜欢这种灵活的处理.因为这个action定义好后,我不需要跑到配置那里定义对应的路由规则
11.最后还是不爽的话自己写个类实现 IRouteConstraint的匹配方法。
1234567891011121314151617181920212223usingSystem;usingSystem.Collections.Generic;usingSystem.Linq;usingSystem.Web;usingSystem.Web.Routing;/// <summary>/// If the standard constraints are not sufficient for your needs, you can define your own custom constraints by implementing the IRouteConstraint interface./// </summary>publicclassUserAgentConstraint : IRouteConstraint{privatestringrequiredUserAgent;publicUserAgentConstraint(stringagentParam){requiredUserAgent = agentParam;}publicboolMatch(HttpContextBase httpContext, Route route,stringparameterName,RouteValueDictionary values, RouteDirection routeDirection){returnhttpContext.Request.UserAgent !=null&&httpContext.Request.UserAgent.Contains(requiredUserAgent);}}1234567routes.MapRoute("ChromeRoute","{*catchall}",new{ controller ="Home", action ="Index"},new{ customConstraint =newUserAgentConstraint("Chrome") },new[] {"UrlsAndRoutes.AdditionalControllers"});比如这个就用来匹配是否是用谷歌浏览器访问网页的。
12.访问本地文档
123routes.RouteExistingFiles =true;routes.MapRoute("DiskFile","Content/StaticContent.html",new{ controller ="Customer", action ="List", });浏览网站,以开启 IIS Express,然后点显示所有应用程序-点击网站名称-配置(applicationhost.config)-搜索UrlRoutingModule节点
1<add name="UrlRoutingModule-4.0"type="System.Web.Routing.UrlRoutingModule"preCondition="managedHandler,runtimeVersionv4.0"/>把这个节点里的preCondition删除,变成
1<add name="UrlRoutingModule-4.0"type="System.Web.Routing.UrlRoutingModule"preCondition=""/>13.直接访问本地资源,绕过了路由系统
1routes.IgnoreRoute("Content/{filename}.html");文件名还可以用 {filename}占位符。
IgnoreRoute方法是RouteCollection里面StopRoutingHandler类的一个实例。路由系统通过硬-编码识别这个Handler。如果这个规则匹配的话,后面的规则都无效了。 这也就是默认的路由里面routes.IgnoreRoute("{resource}.axd/{*pathInfo}");写最前面的原因。
路由测试(在测试项目的基础上,要装moq)
1PM> Install-Package Moq123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899usingSystem;usingMicrosoft.VisualStudio.TestTools.UnitTesting;usingSystem.Web;usingMoq;usingSystem.Web.Routing;usingSystem.Reflection;[TestClass]publicclassRoutesTest{privateHttpContextBase CreateHttpContext(stringtargetUrl =null,stringHttpMethod ="GET"){// create the mock requestMock<HttpRequestBase> mockRequest =newMock<HttpRequestBase>();mockRequest.Setup(m => m.AppRelativeCurrentExecutionFilePath).Returns(targetUrl);mockRequest.Setup(m => m.HttpMethod).Returns(HttpMethod);// create the mock responseMock<HttpResponseBase> mockResponse =newMock<HttpResponseBase>();mockResponse.Setup(m => m.ApplyAppPathModifier(It.IsAny<string>())).Returns<string>(s => s);// create the mock context, using the request and responseMock<HttpContextBase> mockContext =newMock<HttpContextBase>();mockContext.Setup(m => m.Request).Returns(mockRequest.Object);mockContext.Setup(m => m.Response).Returns(mockResponse.Object);// return the mocked contextreturnmockContext.Object;}privatevoidTestRouteMatch(stringurl,stringcontroller,stringaction,objectrouteProperties =null,stringhttpMethod ="GET"){// ArrangeRouteCollection routes =newRouteCollection();RouteConfig.RegisterRoutes(routes);// Act - process the routeRouteData result = routes.GetRouteData(CreateHttpContext(url, httpMethod));// AssertAssert.IsNotNull(result);Assert.IsTrue(TestIncomingRouteResult(result, controller, action, routeProperties));}privateboolTestIncomingRouteResult(RouteData routeResult,stringcontroller,stringaction,objectpropertySet =null){Func<object,object,bool> valCompare = (v1, v2) =>{returnStringComparer.InvariantCultureIgnoreCase.Compare(v1, v2) == 0;};boolresult = valCompare(routeResult.Values["controller"], controller)&& valCompare(routeResult.Values["action"], action);if(propertySet !=null){PropertyInfo[] propInfo = propertySet.GetType().GetProperties();foreach(PropertyInfo piinpropInfo){if(!(routeResult.Values.ContainsKey(pi.Name)&& valCompare(routeResult.Values[pi.Name],pi.GetValue(propertySet,null)))){result =false;break;}}}returnresult;}privatevoidTestRouteFail(stringurl){// ArrangeRouteCollection routes =newRouteCollection();RouteConfig.RegisterRoutes(routes);// Act - process the routeRouteData result = routes.GetRouteData(CreateHttpContext(url));// AssertAssert.IsTrue(result ==null|| result.Route ==null);}[TestMethod]publicvoidTestIncomingRoutes(){// check for the URL that we hope to receiveTestRouteMatch("~/Admin/Index","Admin","Index");// check that the values are being obtained from the segmentsTestRouteMatch("~/One/Two","One","Two");// ensure that too many or too few segments fails to matchTestRouteFail("~/Admin/Index/Segment");//失败TestRouteFail("~/Admin");//失败TestRouteMatch("~/","Home","Index");TestRouteMatch("~/Customer","Customer","Index");TestRouteMatch("~/Customer/List","Customer","List");TestRouteFail("~/Customer/List/All");//失败TestRouteMatch("~/Customer/List/All","Customer","List",new{ id ="All"});TestRouteMatch("~/Customer/List/All/Delete","Customer","List",new{ id ="All", catchall ="Delete"});TestRouteMatch("~/Customer/List/All/Delete/Perm","Customer","List",new{ id ="All", catchall ="Delete/Perm"});}}最后还是再推荐一下Adam Freeman写的apress.pro.asp.net.mvc.4这本书。
-
-

