
"Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network" 解读
简介:这是一篇17年的CVPR,作者提出使用现有的人脸识别深度神经网络Resnet101来得到一个具有鲁棒性的人脸模型。
原文链接:https://www.researchgate.net/publication/311668561_Regressing_Robust_and_Discriminative_3D_Morphable_Models_with_a_very_Deep_Neural_Network
摘要
主要说了两个部分:第一部分,三维人脸模型还没有广泛应用到人脸识别等领域,主要原因是同一个对象的不同照片生成的人脸模型差异较大,也就是不够鲁棒;或者不同对象生成的人脸模型又太接近,也就是人脸模型太泛化,没有区分度。第二部分,就是作者的主要贡献,其一是解决了训练数据匮乏的问题,其二,用CNN做三维人脸重建,提高了人脸识别的准确率。
介绍
主要还是围绕前面提到的两个问题,一是人脸模型没有区分度,二是人脸模型不够鲁棒。

如图所示,3DDFA得到的就是一张大众脸,没有特色,作者的方法就比较接近潘大大了。
针对上述问题,作者就说了,我们能解决上面的两个问题。我们用一个深度卷积神经网络去回归3DMM形状参数(Note:只是形状!),然后就可以得到3维人脸形状了,至于纹理参数是直接从照片中得来的,这不是作者关注的重点。另外,作者还解决了训练数据集不够的问题,用多张照片去生成3维人脸模型,作为Ground Truth,这个后面会提到。
相关工作
此处略去n个字~,论文里阐述了以往做3维人脸建模的一些方法。一句话总结:俱往矣~。
Regressing 3DMM parameters with a CNN
作者认为,之前没有将CNN用在三维人脸建模方面,主要是因为从二维图像重建三维人脸模型,我们需要回归高维的形状参数,这就要求非常深的网络,而训练非常深的网络又需要大量的训练数据,很尴尬,已知的三维人脸模型的训练集小的可怜。那怎么办呢?追古溯今,作者淘到了一个好方法,利用一个对象的多姿态人脸图片可以生成准确率相当高的三维人脸形状[30],然后把生成的模型作为训练集,ko一个问题;那鲁棒性和区别性的人脸形状怎么解决呢?借鉴二维空间中的深度卷积神经网络模型,而且模型还是现成的~。
Generating training data
首先,利用中科院的CASIA WebFace dataset,借鉴[30]的方法。500k的单张图片,每一个都估计一个3DMM,后续还会继续进行处理。估计方法如下:
利用BFM,使用Vetter等人的三维人脸重建公式:
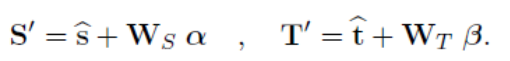
参数说明请看原文,我们要求的其实就是α和β。对[8][33]的方法做了一点改变,给定一张图片,用他们的方法可以得到一个近似的形状参数α*和纹理参数β*,这里作者用了CLNF来做人脸检测,得到68个人脸关键点,求得该张图片的置信度(后面会用到),将得到的关键点用来初始化估计人脸模型的姿态,该姿态用六个自由度表示:
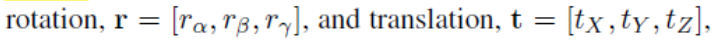
然后再优化3DMM的形状,纹理,姿态,光照和颜色,利用[33]的方法解决定位误差。 一旦损失函数收敛,就得到的形状参数和纹理参数,这就是图像I得到的3DMM估计,虽然这个过程计算量大,但它只是用在生成数据中,不会影响算法效率。
根据最近的工作[30],我们将每个对象的多个3DMM(包含形状和纹理)估计进行池化,也就是每个对象的多张照片对应得到的3DMM估计,进行加权求和,最后一个对象只有一个3DMM估计,池化公式如下:
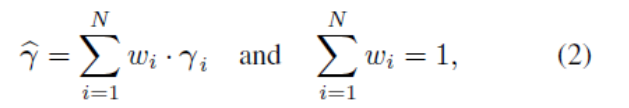
ωi是前面CLNF求到的置信度。
Learning to regress pooled 3DMM
上一个步骤结束之后,一个对象会有多个不同角度的照片,但只有一个3DMM估计。现在我们要用这些数据去学习一个函数,使同一个对象的不同照片得到的3DMM特征向量是相同的。为此,我们引入了一个深度神经网络ResNet,修改了它的最后一层全连接层,使输出为198维的3DMM特征向量γ,用池化的3DMM估计作为真实标注,让网络去学习。
The asymmetric Euclidean loss
由构造函数可知,3DMM向量属于多元高斯分布,均值在原点处,代表了均值人脸,就是那个人脸形状和纹理重建公式,因此,在训练期间,如果使用标准的欧拉损失函数来最小化距离,会使得到的人脸模型太泛化,没有区别性。
作者就提出了一个非对称欧拉损失,使模型学习到更多的细节特征,使三维人脸模型具有更多的区别性,公式如下:
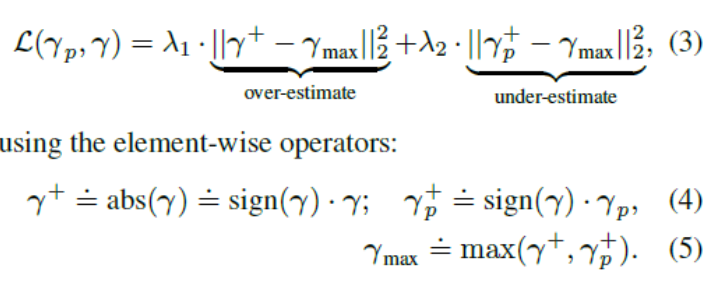
效果还不错:

Network hyperparameters
就是介绍一下训练的时候,一些超参数的设置,具体参看原文。下面这个图是对整个流程的总结,分三个部分,每一部分,上面都已经做了解释:

Discussion: Render-free 3DMM estimator
3DMM参数直接通过对输入图像的回归得到,没有进行纹理渲染的优化,我们主要是得到准确的形状,因此在估计3DMM时也更快。
Parameter based 3D-3D recognition
对得到的3维人脸模型进行评价,看它是否是属于同一个对象。
3D-3D recognition with a single image(???)
用3DMM参数γp作为人脸特征的描述子。因为不同的关键点常常表示不同的人脸外观,应用PCA方法,从上面的训练数据集(得到68个关键点的那个)中学习,使估计的参数接近人脸关键点。最后用余弦相似度量判断两个人脸三维模型是否相似。(没搞懂,还望指教。。。)
3D-3D recognition with multiple-image
对于多图像,首先使用上面的等式2对3DMM参数进行池化,此时权重都是相等的。对于每个对象的视频,我们会池化得到一个3DMM,然后他们的多张图像,也是池化得到一个3DMM,再对这些3DMM进行一次池化,反正最后一个对象,一个3DMM。
Face alignment
作者说了,我们就用了二维图像的人脸标准框,其他的特征点检测,人脸对齐都没用。但我们方法对未对齐的人脸也很鲁棒??,也很省时。。。
Experimental results
自由发挥了,溜了~~~
初来乍到,还望各位大佬多多指教!
参考:
知乎:https://zhuanlan.zhihu.com/p/24316690
[30]M. Piotraschke and V. Blanz. Automated 3D face reconstruction from multiple images using quality measures. In Proc. Conf. Comput. Vision Pattern Recognition, June 2016.
[33]S. Romdhani and T. Vetter. Estimating 3D shape and texture using pixel intensity, edges, specular highlights, texture constraints and a prior. In Proc. Conf. Comput. Vision Pattern Recognition, volume 2, pages 986–993, 2005.
[8]V. Blanz and T. Vetter. Face recognition based on fitting a 3d morphable model. Trans. Pattern Anal. Mach. Intell., 25(9):1063–1074, Sept 2003.

