re模块与正则表达式
一、正则表达式概念
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
1、正则表达式之表示字符
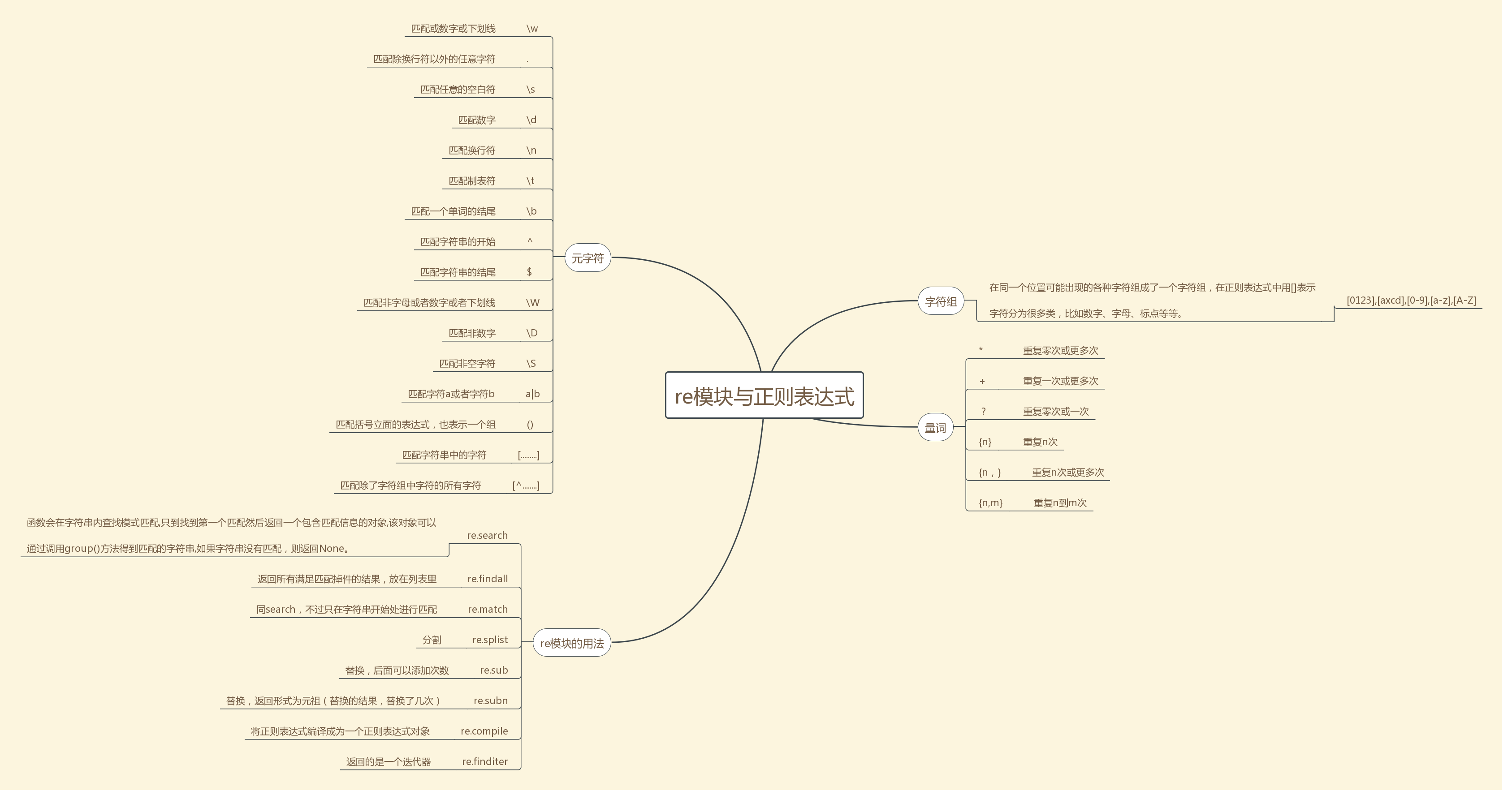
| 字符 | 功能 |
| . | 匹配任意1个字符(除了\n) |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s |
匹配空白,即空格、tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9 |
| \W | 匹配非单词字符 |
简单实例:


import re ret = re.findall(".","agdhsaghgewj1233") # 匹配任意字符串 ret1 = re.findall("H","Hello,python") #只匹配H字符 ret2 = re.findall("\d","gdhgf1554hgsfhdg") #只匹配数字
2.正则表达式之表示数量
| 符号 | 功能 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
简单实例:
ret = re.findall("\w*","Aabcdef") # ret = re.findall("\d+","dfdfdsfs14fgf24fd4f5") #打印结果为14,24,4,5 ret1 = re.findall("[]a-zA-Z0-9_]{8,20}","hdfhgf1545gfd") # 打印8-20位的字符
3.正则表达式之表示边界
| 字符 | 功能 |
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
简单实例:
import re ret = re.findall(r"^[a-z0-9]{4,20}@163.com$","caoyf1992@163.com") # 以a-z字符和0-9数字开头,长度为4-20位 ret1 = re.findall(r"c\b","ddfdsfc lfdfdcc dfjhgjfhgfjgccc") #显示以c为边界的字符
4.正则表达式之匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
\num |
引用分组num匹配到的字符串 |
(?P<name>) |
分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
二、re模块的使用
1、findall
import re ret=re.findall(r'\d+',"商品:辣条,数量:5,价格:5") print(ret)
2、findall优先级
import re ret = re.findall(r'(数量:\d+),价格:\d+',"商品:辣条,数量:5,价格:5") print(ret) #取消优先级 ret = re.findall(r'(?:数量:\d+),价格:\d+',"商品:辣条,数量:5,价格:5") print(ret)
3、search
函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
import re ret = re.search(r"\d+", "阅读次数为 9999") ret.group() #结果9999
4、split
split的优先级查询
import re ret=re.split(r'\d+',"小米3小花4小松5") print(ret) #结果: # ['小米', '小花', '小松', ''] ret=re.split(r'(\d+)',"小米3小花4小松5") print(ret) #结果: # ['小米', '3', '小花', '4', '小松', '5', ''] #取消优先级 ret=re.split(r'(?:\d+)',"小米3小花4小松5") print(ret) # 结果 # ['小米', '小花', '小松', '']
本文来自博客园,作者:曹艳飞,转载请注明原文链接:https://www.cnblogs.com/caoyf1992/p/8252439.html

