
还是上次的那个网站,就是它.现在尝试用另一种办法——直接请求json文件,来获取要抓取的信息。
第一步,检查元素,看图如下:
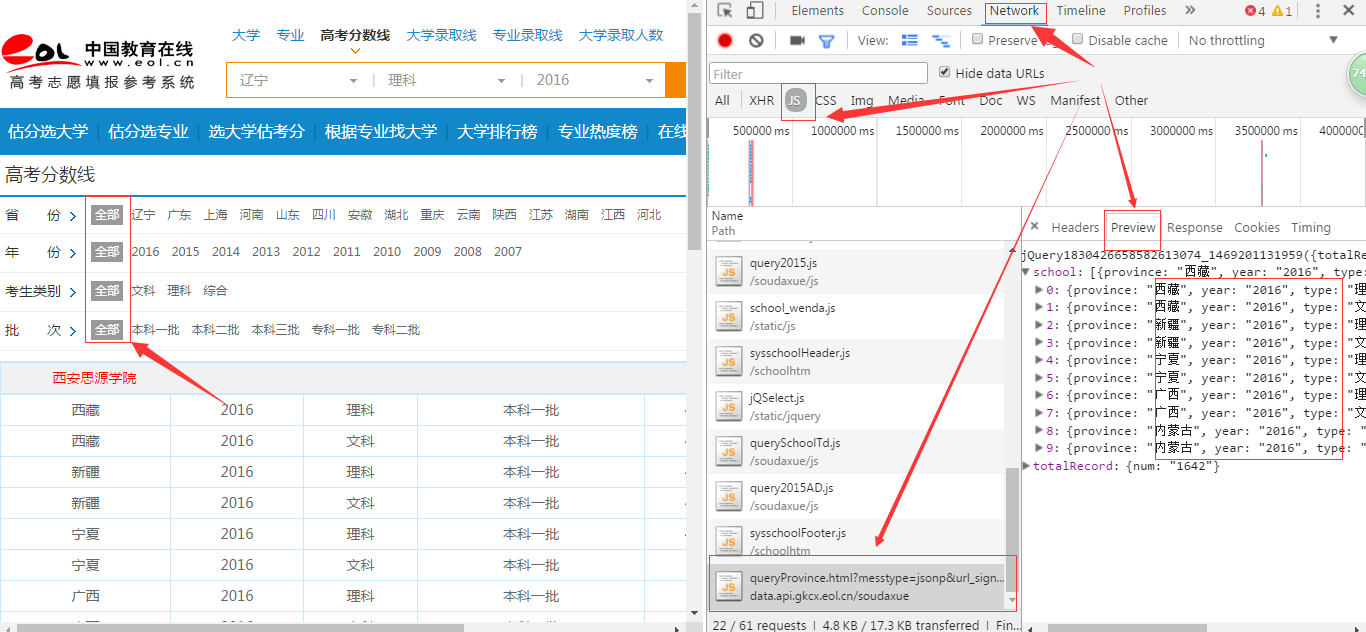
过滤出JS文件,并找出包含要抓取信息的js文件,之后就是构造requests请求对象,然后解析json文件啦。源码如下:
import requests
def save(school_datas):
for data in school_datas:
# print(data)
year = data['year']
province = data['province']
type = data['type']
bath = data['bath']
score = data['score']
print(province, year, type, bath,score )
for i in range(1, 34):
print("第%s页====================="%str(i))
# url = "http://data.api.gkcx.eol.cn/soudaxue/queryProvince.html?messtype=jsonp&url_sign=queryprovince&province3=&year3=&page=1&size=100&luqutype3=&luqupici3=&schoolsort=&suiji=&callback=jQuery1830426658582613074_1469201131959&_=1469201133189"
data = requests.get("http://data.api.gkcx.eol.cn/soudaxue/queryProvince.html", params={"messtype":"json","url_sign":"queryprovince","page":str(i),"size":"50","callback":"jQuery1830426658582613074_1469201131959","_":"1469201133189"}).json()
print("每一页信息条数——>", len(data['school']))
print("全部信息条数——>", data["totalRecord"]['num'])
school_datas = data["school"]
save(school_datas)
简单说明一下params部分,大部分是从json文件网址中截取信息构造,其中size参数是一个页面返回的信息数量,可调节大小,网站一般有限制,这里是50(就算size超出50的话也是返回50条);page,就是字面意思啦,这里从1请求到33为止,33由int(1640/50) + 1)得到,1640是信息总条数。此外,params还可以设置其他参数来具体指定省份时间等。
最重要的,在同样的网速下,这个程序不仅简单,而且,3s左右就可以输出全部结果(这里只是输出,没有保存),效率高出模拟登陆不是一点啊。。。
关于动态加载网页的抓取先到这里告一段落,之后打算简单学习一下JS相关的知识再来总结一下。
最后感谢群里面两位大牛的指点,@南京-天台@四川-Irony。

